







 本文探讨了线性代数中的基本概念,如标量、向量、矩阵和张量,以及它们的运算性质,如长度、维度、转置、范数和微分。重点介绍了微分中的导数、偏导数、梯度和链式法则,以及自动求导在深度学习优化中的应用。涵盖了关键概念和实例演示,为理解深度学习模型的训练打下基础。
本文探讨了线性代数中的基本概念,如标量、向量、矩阵和张量,以及它们的运算性质,如长度、维度、转置、范数和微分。重点介绍了微分中的导数、偏导数、梯度和链式法则,以及自动求导在深度学习优化中的应用。涵盖了关键概念和实例演示,为理解深度学习模型的训练打下基础。
一、线性代数
1.1 标量
- 标量:仅包含一个数值的叫做标量
- 标量由只有一个元素的张量表示。在下面的代码中,我们实例化两个标量,并使用它们执行一些熟悉的算术运算,即加法,乘法,除法和指数。

1.2 向量
- 可以将向量视为标量值组成的列表。我们将这些标量值称为向量的 元素(elements)或分量(components)。
- 我们通过一维张量处理向量。一般来说,张量可以具有任意长度,取决于机器的内存限制。

- 我们可以使用下标来引用向量的任一元素,认为列向量是向量的默认方向。我们可以通过张量的索引来访问任一元素。

1.2.1 长度、维度和形状
- 向量的长度通常称为向量的 维度(dimension)。与普通的 Python 数组一样,我们可以通过调用 Python 的内置
len()函数来访问张量的长度。

- 当用张量表示一个向量(只有一个轴)时,我们也可以通过
.shape属性访问向量的长度。形状(shape)是一个元组,列出了张量沿每个轴的长度(维数)。对于只有一个轴的张量,形状只有一个元素。

- 维度(dimension)这个词在不同上下文时往往会有不同的含义,这经常会使人感到困惑。为了清楚起见,我们在此明确一下。向量或轴的维度被用来表示向量或轴的长度,即向量或轴的元素数量。然而,张量的维度用来表示张量具有的轴数。在这个意义上,张量的某个轴的维数就是这个轴的长度。
1.3 矩阵
- 当调用函数来实例化张量时,我们可以通过指定两个分量𝑚m 和 𝑛n来创建一个形状为𝑚×𝑛m×n 的矩阵。

- 有时候,我们想翻转轴。当我们交换矩阵的行和列时,结果称为矩阵的转置(transpose)。我们用
来表示矩阵的转置,如果
,则对于任意𝑖和𝑗,都有
。因此,上面的转置是一个形状为𝑛×𝑚的矩阵:

- 现在我们在代码中访问矩阵的转置

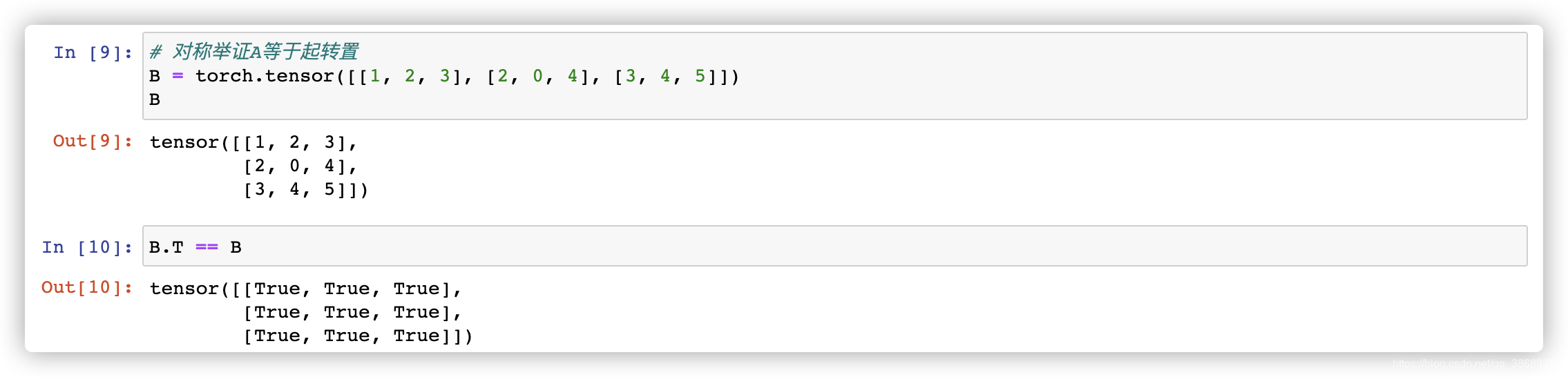
- 对于对称矩阵其转置等于本身
1.4 张量
- 当我们开始处理图像时,张量将变得更加重要,图像以𝑛维数组形式出现,其中3个轴对应于高度、宽度,以及一个通道(channel)轴,用于堆叠颜色通道(红色、绿色和蓝色)。现在,我们将跳过高阶张量,集中在基础知识上。

1.5 张量算法的基本性质
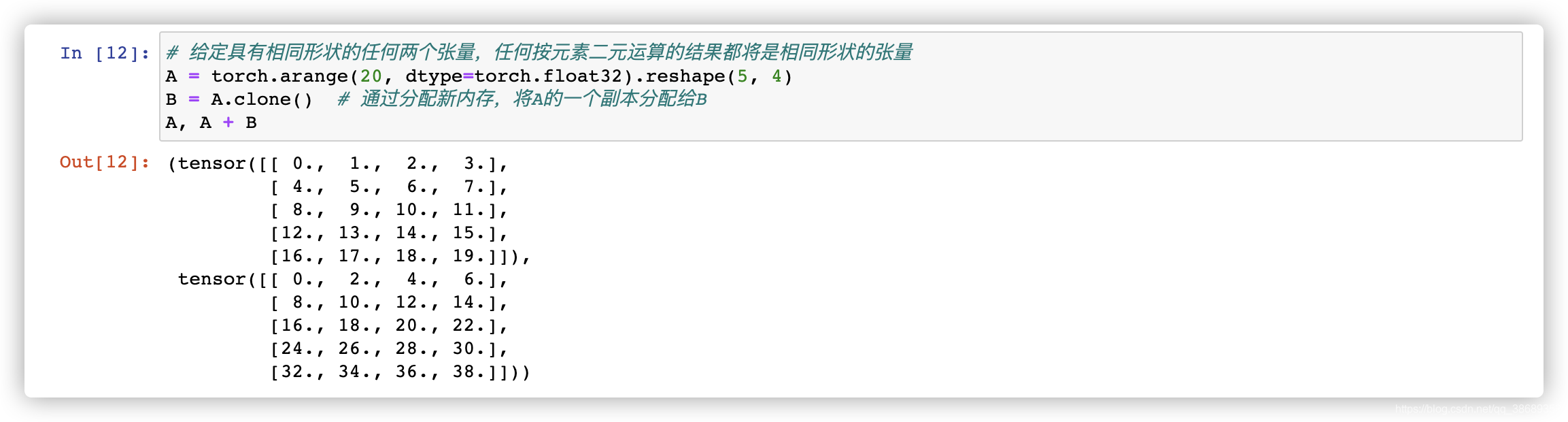
- 给定具有相同形状的任何两个张量,任何按元素二元运算的结果都将是相同形状的张量。
- 两个矩阵的按元素乘法称为 哈达玛积(Hadamard product)

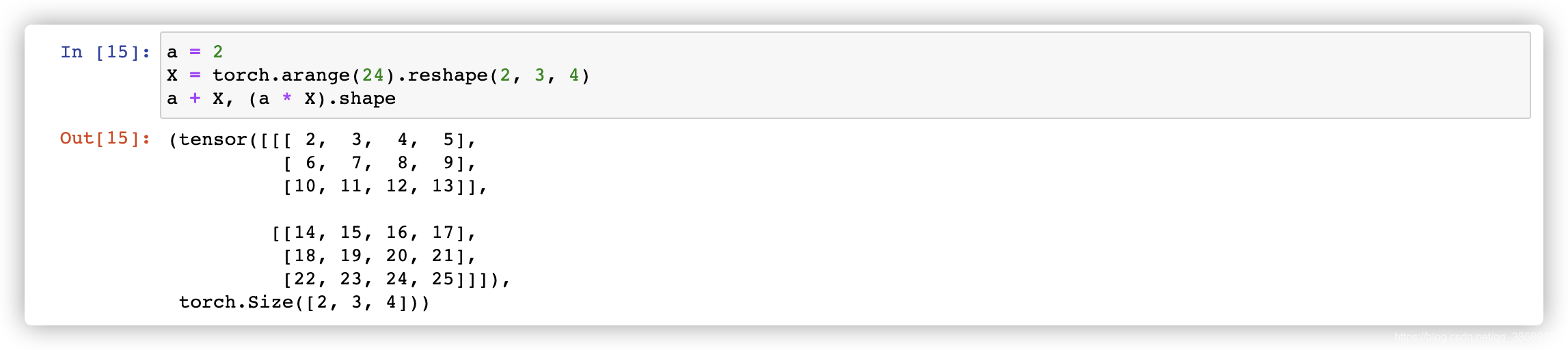
- 将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
1.6 汇总
- 我们可以对任意张量进行的一个有用的操作是计算其元素的和。在代码中,我们可以调用计算求和的函数:

- 我们可以表示任意形状张量的元素和。

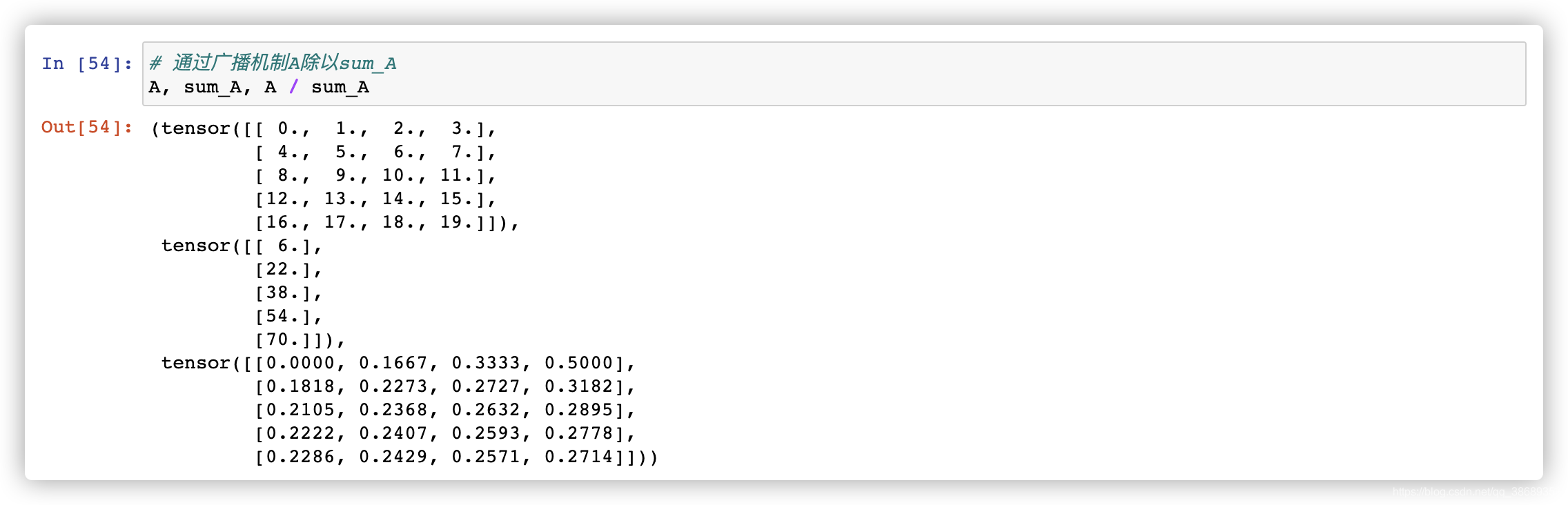
- 默认情况下,调用求和函数会将一个张量沿所有轴汇总为一个标量。 我们还可以指定张量求和汇总所沿的轴。以矩阵为例,为了通过求和所有行的元素来汇总行维度(轴0),我们可以在调用函数时指定
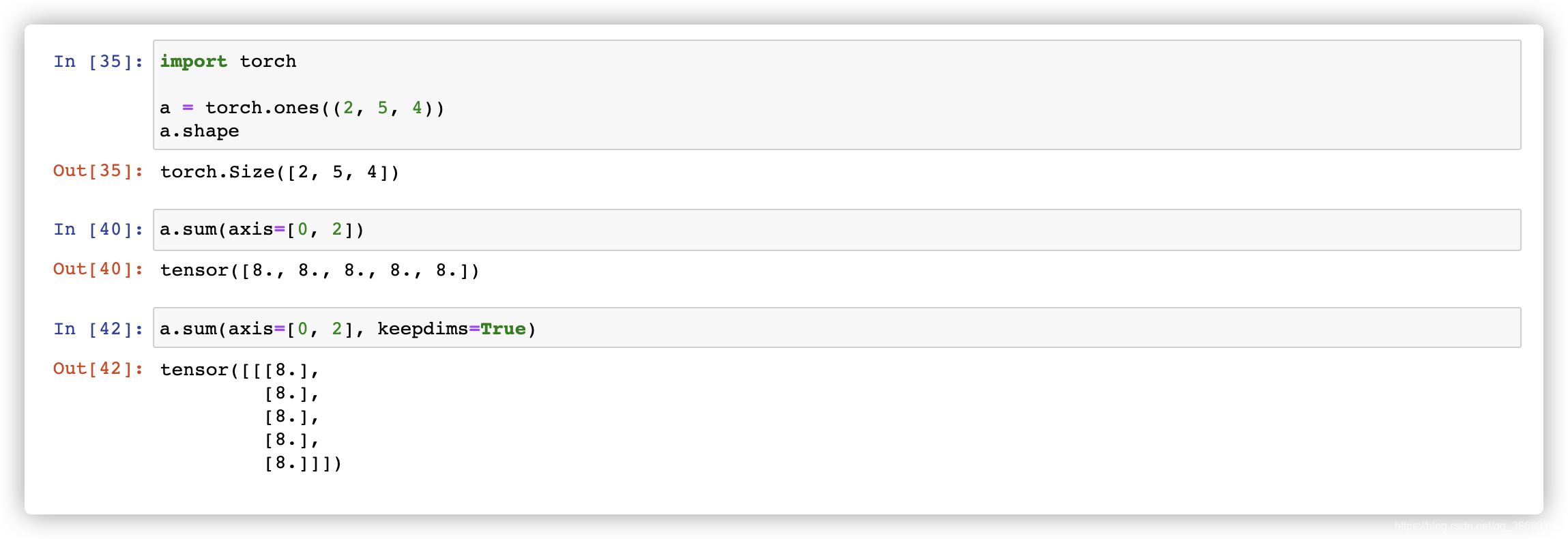
axis=0。 由于输入矩阵沿0轴汇总以生成输出向量,因此输入的轴0的维数在输出形状中丢失。- 这边指定哪个维度汇总哪个维度就会消失,除非指定keepdims=True保留维度。假设我们有一个维度为(2, 5, 4)的张量,我们指定axis=1时,他会按照5这个维度求和,2这个维度会消失。或者向下面一样我们指定axis=[0, 2],这样2, 4这两个维度就会消失,会按照这两个维度的方向进行计算。保留5这个维度。如果我们指定keepdims=True会保留所有维度。
- 计算平均值

- 保留维度的一个作用,就是可以使用广播机制
1.6 点积
- 两个向量相同位置的按元素乘积的和

- 我们也可以通过执行按元素乘法,然后进行求和来表示两个向量的点积

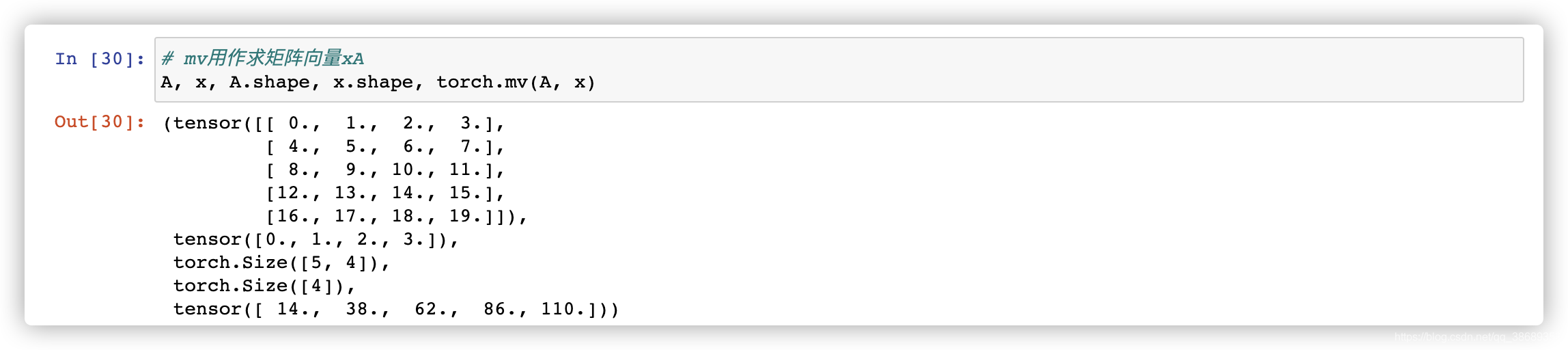
1.7 矩阵-向量积
- 就是正常的矩阵的乘法运算。在代码中使用张量表示矩阵-向量积,我们使用与点积相同的
dot函数。当我们为矩阵A和向量x调用np.dot(A, x)时,会执行矩阵-向量积。注意,A的列维数(沿轴1的长度)必须与x的维数(其长度)相同。
1.8 矩阵-矩阵乘法
- 就是正常的矩阵乘法,不是按元素的那种

1.9 范数
- 线性代数中最有用的一些运算符是 范数(norms)。非正式地说,一个向量的范数告诉我们一个向量有多大。 这里考虑的 大小(size) 概念不涉及维度,而是分量的大小。
- 在线性代数中,向量的范数是将向量映射到标量的函数f。向量范数满足一定属性。给定任意向量x,有下面性质。
- 如果我们按常数因子 𝛼 缩放向量的所有元素,其范数也会按相同常数因子的 绝对值 缩放:
- 三角不等式:
- 非负性:
- 如果我们按常数因子 𝛼 缩放向量的所有元素,其范数也会按相同常数因子的 绝对值 缩放:
- 欧几里得距离是一个范数,它是
范数。
,下面我们使用代码求

- 与
范数受异常值的影响较小。
,下面我们使用代码求

范数的特例:
- 类似于向量的
,f范数满足向量范数的所有性质。他就是像是矩阵的

1.10 范数和目标
- 在深度学习中,我们经常试图解决优化问题: 最大化 分配给观测数据的概率; 最小化 预测和真实观测之间的距离。 用向量表示物品(如单词、产品或新闻文章),以便最小化相似项目之间的距离,最大化不同项目之间的距离。 通常,目标,或许是深度学习算法最重要的组成部分(除了数据),被表达为范数。
二、微分
- 在深度学习中,我们“训练”模型,不断更新它们,使它们在看到越来越多的数据时变得越来越好。通常情况下,变得更好意味着最小化一个 损失函数(loss function),即一个衡量“我们的模型有多糟糕”这个问题的分数。这个问题比看上去要微妙得多。最终,我们真正关心的是生成一个能够在我们从未见过的数据上表现良好的模型。但我们只能将模型与我们实际能看到的数据相拟合。因此,我们可以将拟合模型的任务分解为两个关键问题:(1)优化(optimization):用模型拟合观测数据的过程;(2)泛化(generalization):数学原理和实践者的智慧,能够指导我们生成出有效性超出用于训练的数据集本身的模型。
2.1 导数和微分
- 首先讨论导数的计算,这是几乎所有深度学习优化算法的关键步骤。在深度学习中,我们通常选择对于模型参数可微的损失函数。简而言之,这意味着,对于每个参数, 如果我们把这个参数增加或减少一个无穷小的量,我们可以知道损失会以多快的速度增加或减少。假设我们有一个函数:
,其输入和输出都是标量。f的导数被定义为:
。如果
存在,则称f在a处可微。如果 𝑓f 在一个区间内的每个数上都是可微的,则此函数在此区间中是可微的。我们可以将导数 𝑓′(𝑥)解释为𝑓(𝑥)相对于 𝑥 的 瞬时(instantaneous) 变化率。所谓的瞬时变化率是基于𝑥中的变化ℎ,且ℎ接近0。
- 定义

- 通过令x = 1并让h接近0,则
的值接近2.

- 几个等价符号。给定
,其中x和y分别是函数f的因变量和自变量。下面表达式是等价的:
- 下面有一些常见的函数求微分:
,C是一个常数
(幂函数,n是任意实数)
- 微分法则,这里我们假设f和g可微,C是一个常数
- 常数相乘法则:
- 加法法则:
- 乘法法则:
- 除法法则:
- 常数相乘法则:
2.2 偏导数
- 在深度学习中,函数通常依赖于许多变量。因此,我们需要将微分的思想推广到这些 多元函数 (multivariate function)上。
- 设
是一个具有n个变量的函数。y关于第i个参数
的偏导数为:
,此时我们将其与的变量看作常数
- 对于偏导数的表示以下是等价的:
2.3 梯度
- 我们可以连结一个多元函数对其所有变量的偏导数,以得到该函数的梯度(gradient)向量。设函数
,并且输出是一个标量。函数
相对于x的梯度是一个包含n个偏导数的向量:
,其中
通常在没有歧义时被
取代。
- 假设x为n维向量,在微分多元函数时经常使用以下规则:
- 对于所有
,都有
- 对于所有
- 对于所有
- 对于所有
- 同样对于任何矩阵X,我们都有
。
2.4 链式法则
- 然而,上面方法可能很难找到梯度。 这是因为在深度学习中,多元函数通常是 复合(composite)的,所以我们可能没法应用上述任何规则来微分这些函数。 幸运的是,链式法则使我们能够微分复合函数。
- 让我们先考虑单变量函数。假设函数 𝑦=𝑓(𝑢) 和 𝑢=𝑔(𝑥)都是可微的,根据链式法则:
- 函数具有任意数量的变量的情况。假设可微分函数 𝑦有变量
,其中每个可微分函数
都有变量
。注意,𝑦是
三、自动求导
- 深度学习框架通过自动计算导数,即 自动求导 (automatic differentiation),来加快这项工作。实际中,根据我们设计的模型,系统会构建一个 计算图 (computational graph),来跟踪计算是哪些数据通过哪些操作组合起来产生输出。自动求导使系统能够随后反向传播梯度。 这里,反向传播(backpropagate)只是意味着跟踪整个计算图,填充关于每个参数的偏导数。
- 想要了解反向传播要先构造一个正向的有向图,反向传播就是通过正向的图来填充偏导数,对哪个求偏导求完之后把正向图中已知的给带入进去
3.1 例一
- 假设我们想对函数
关于列向量
求导。首先,我们创建变量
x并为其分配一个初始值。

- 在我们计算𝑦关于𝐱的梯度之前,我们需要一个地方来存储梯度。 重要的是,我们不会在每次对一个参数求导时都分配新的内存。因为我们经常会成千上万次地更新相同的参数,每次都分配新的内存可能很快就会将内存耗尽。注意,标量函数关于向量𝐱x的梯度是向量,并且与𝐱具有相同的形状。

- 现在让我们计算 𝑦

x是一个长度为 4 的向量,计算x和x的内积,得到了我们赋值给y的标量输出。接下来,我们可以通过调用反向传播函数来自动计算y关于x每个分量的梯度,并打印这些梯度。

- 函数
关于

- 现在让我们计算
x的另一个函数

3.2 非标量变量的反向传播
- 当
y不是标量时,向量y关于向量x的导数的最自然解释是一个矩阵。对于高阶和高维的y和x,求导的结果可以是一个高阶张量。然而,虽然这些更奇特的对象确实出现在高级机器学习中(包括深度学习中),但当我们调用向量的反向计算时,我们通常会试图计算一批训练样本中每个组成部分的损失函数的导数。这里,我们的目的不是计算微分矩阵,而是批量中每个样本单独计算的偏导数之和。

3.3 分离计算
- 我们希望将某些计算移动到记录的计算图之外。 例如,假设
y是作为x的函数计算的,而z则是作为y和x的函数计算的。 现在,想象一下,我们想计算z关于x的梯度,但由于某种原因,我们希望将y视为一个常数,并且只考虑到x在y被计算后发挥的作用。 - 在这里,我们可以分离
y来返回一个新变量u,该变量与y具有相同的值,但丢弃计算图中如何计算y的任何信息。换句话说,梯度不会向后流经u到x。因此,下面的反向传播函数计算z = u * x关于x的偏导数,同时将u作为常数处理,而不是z = x * x * x关于x的偏导数。

- 由于记录了y的计算结果,我们可以随后在y上调用反响传播,得到y = x * x关于x的导数2*x

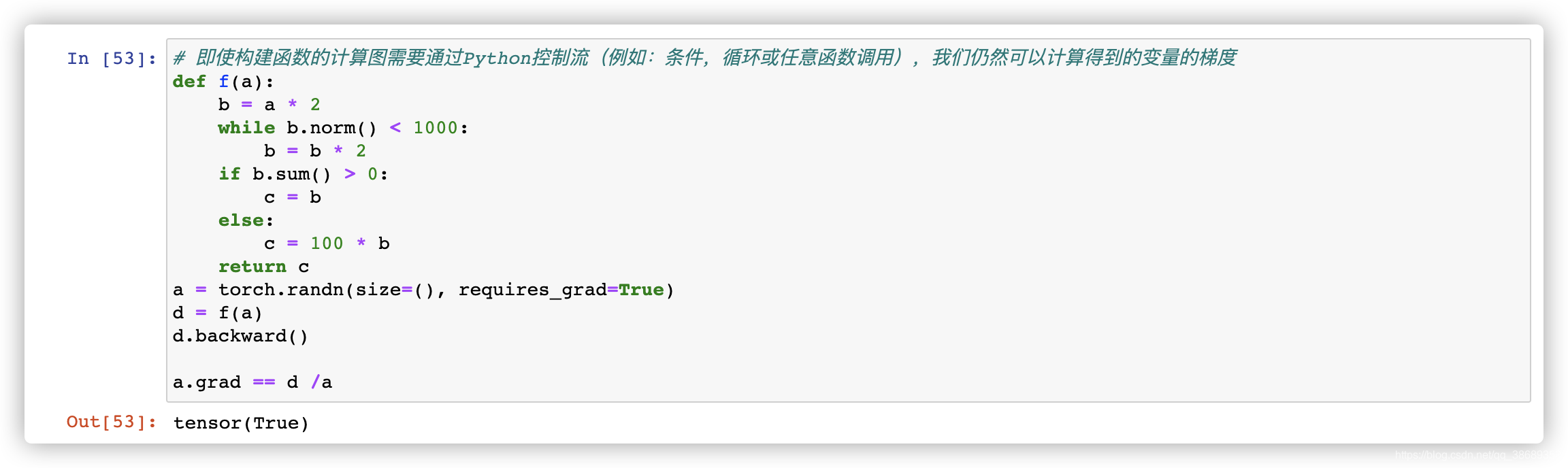
3.4 Python控制流的梯度计算
- 使用自动求道的一个好处就是,即使构建函数的计算图需要通过 Python控制流(例如,条件、循环或任意函数调用),我们仍然可以计算得到的变量的梯度。在下面的代码中,
while循环的迭代次数和if语句的结果都取决于输入a的值。

















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









