







Book 构造函数
Book 对象分为两种场景:
- 直接从电子书文件中解析出
Book对象 - 从
data对象中生成Book对象
class Book {
constructor(file, data) {
if (file) {
this.createBookFromFile(file)
} else {
this.createBookFromData(data)
}
}
createBookFromFile(file) {
console.log('createBookFromFile', file)
}
createBookFromData(data) {
console.log('createBookFromData', data)
}
}
module.exports = Book
从文件创建 Book 对象
在 utils\constant.js 增加如下三个常量:
MimeType可能是application/epub或application/epub+zip,这里我使用字符串的StartWith方法进行判断
const { env } = require('./env')
const UPLOAD_PATH =
env === 'dev' ? 'E:/upload/admin-upload-ebook' : '/root/upload/admin-upload-ebook'
const UPLOAD_URL = env === 'dev' ? 'http://127.0.0.1:8089/admin-upload-ebook' : 'http://www.book.llmysnow.top/admin-upload-ebook'
module.exports = {
// ...
UPLOAD_PATH,
MIME_TYPE_EPUB: 'application/epub',
UPLOAD_URL
}
从文件读取电子书后,初始化 Book 对象
const { MIME_TYPE_EPUB, UPLOAD_URL, UPLOAD_PATH } = require('../utils/constant')
const fs = require('fs')
class Book {
// ...
createBookFromFile(file) {
const {
destination: des, // 文件本地存储目录
filename, //文件名称
path, // 文件路径
mimetype = MIME_TYPE_EPUB, // 文件资源类型
originalname // 文件原始名称
} = file
// 电子书的文件后缀名
const suffix = mimetype.startsWith(MIME_TYPE_EPUB) ? '.epub' : ''
// 电子书原有路径
const oldBookPath = path
// 电子书的新路径
const bookPath = `${des}/${filename}${suffix}`
// 电子书下载URL链接
const url = `${UPLOAD_URL}/book/${filename}${suffix}`
// 电子书解压后的文件夹路径
const unzipPath = `${UPLOAD_PATH}/unzip/${filename}`
// 电子书解压后的文件夹URL
const unzipUrl = `${UPLOAD_URL}/unzip/${filename}`
if (!fs.existsSync(unzipPath)) {
fs.mkdirSync(unzipPath, { recursive: true }) // 迭代创建解压文件夹
}
if (fs.existsSync(oldBookPath) && !fs.existsSync(bookPath)) {
fs.renameSync(oldBookPath, bookPath) // 重命名文件
}
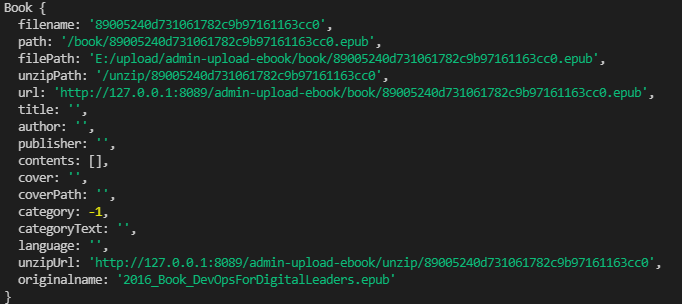
this.fileName = filename // 文件名
this.path = `/book/${filename}${suffix}` // epub文件夹相对路径
this.filePath = this.path // epub文件夹相对路径
this.unzipPath = `/unzip/${filename}` // epub解压后相对路径
this.url = url // epub文件下载链接
this.title = '' // 书名
this.author = '' // 作者
this.publisher = '' // 出版社
this.contents = [] // 目录
this.cover = '' // 封面图片URL
this.coverPath = '' // 封面图片路径
this.category = -1 // 分类ID
this.categoryText = '' // 分类名称
this.language = '' // 语种
this.unzipUrl = unzipUrl // 解压后文件夹链接
this.originalName = originalname // 电子书原名
}
}
电子书解析
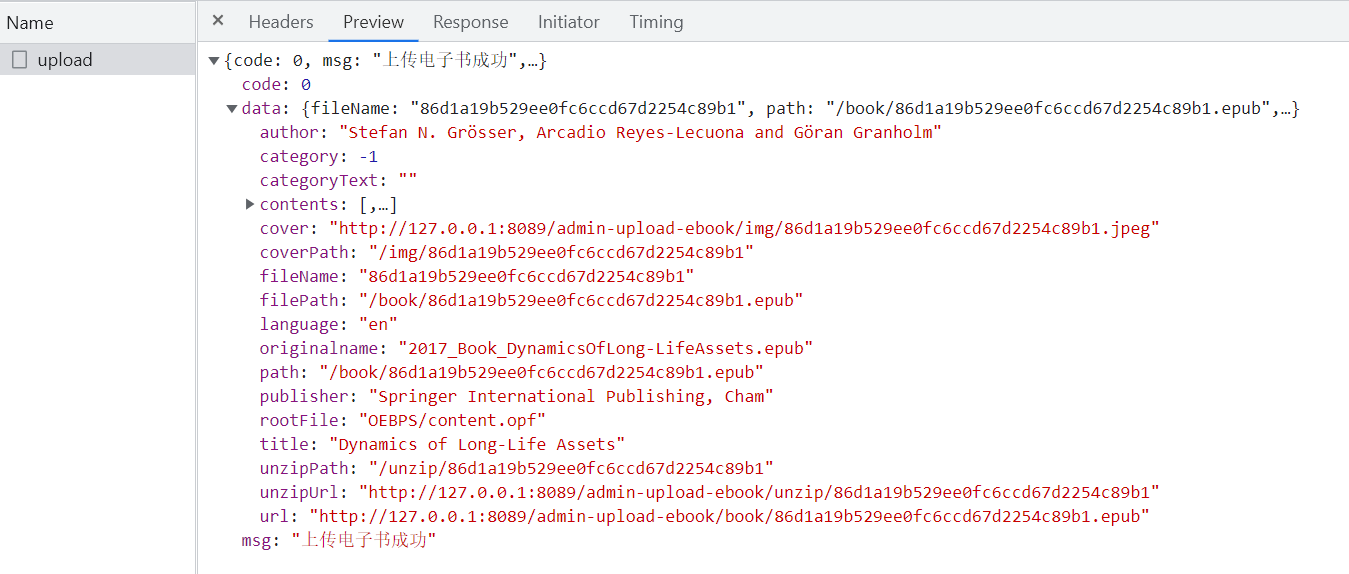
初始化后,可以调用 Book 实例的 parse 方法解析电子书
- 这里我们使用了
epub库 源码:,我们直接将epub.js拷贝到utils\epub.js
安装 epub.js 所依赖的两个库:
npm i xml2js adm-zip
使用 epub 库解析电子书
在 models\Book.js 的 Book 类中新增 parse 方法
- 解析
epub.metadata中的数据赋值给this上

const Epub = require('../utils/epub')
class Book {
// ....
parse() {
return new Promise((resolve, reject) => {
const bookPath = `${UPLOAD_PATH}${this.path}`
if (!fs.existsSync(bookPath)) reject(new Error('电子书不存在'))
const epub = new Epub(bookPath)
epub.on('error', err => reject(err))
epub.on('end', err => {
if (err) reject(err)
const { title, creator, creatorFileAs, language, publisher, cover } = epub.metadata
if (!title) reject(new Error('图书标题为空'))
this.title = title
this.language = language || 'en'
this.author = creator || creatorFileAs || 'unknown'
this.publisher = publisher || 'unknown'
this.rootFile = epub.rootFile
const handleGetImage = (err, file, mimeType) => {
if (err) reject(err)
const suffix = mimeType && mimeType.split('/')[1]
const coverPath = `${UPLOAD_PATH}/img/${this.fileName}.${suffix}`
const coverUrl = `${UPLOAD_URL}/img/${this.fileName}.${suffix}`
fs.writeFileSync(coverPath, file, 'binary')
this.coverPath = `/img/${this.fileName}.${suffix}`
this.cover = coverUrl
resolve(this)
}
try {
this.unzip() // 解压电子书
this.parseContents(epub)
.then(({ chapters, chapterTree }) => {
this.contents = chapters
this.contentsTree = chapterTree
epub.getImage(cover, handleGetImage) // 获取封面图片
})
.catch(err => reject(err))
} catch (e) {
reject(e)
}
})
epub.parse()
})
}
}
使用 epub 库获取图片
epub 格式内容可以复习一下这篇文章: 项目技术架构 中的 ePub 电子书
content.opf(可能有的不叫这个,文件指向可以查看container.xml这个文件。一般情况下找opf格式的文件就对了)内容大概有五部分,其中有一个部分叫manifest文件列表,里面有封面cover的信息
<meta name="cover" content="cover-image"/>
<item id="cover-image" href="images/cover.jpg" media-type="image/jpeg"/>
<!-- 另一种是没有meta标签为cover的,通过properties获取 -->
<item id="Aimages_978-3-319-64337-3_CoverFigure" href="images/978-3-319-64337-3_CoverFigure.jpg" media-type="image/jpeg" properties="cover-image"/>
修改获取 utils\epub.js 中获取封面图片的源码
- 如果还遇到其他格式,后期可以在这里继续完善
getImage(id, callback) {
if (this.manifest[id]) {
if ((this.manifest[id]['media-type'] || "").toLowerCase().trim().substr(0, 6) != "image/") {
return callback(new Error("Invalid mime type for image"));
}
this.getFile(id, callback);
} else {
const coverId = Object.keys(this.manifest).find(key =>
this.manifest[key].properties === 'cover-image'
)
if (coverId) {
this.getFile(coverId, callback)
} else {
callback(new Error("File not found"));
}
}
};
电子书目录解析
电子书解析过程中我们需要定义电子书目录解析,第一步需要解压电子书
class Book {
//...
unzip() {
const AdmZip = require('adm-zip')
const zip = new AdmZip(Book.genPath(this.path)) // 解析文件路径
zip.extractAllTo(Book.genPath(this.unzipPath), true)
}
}
genPath 是 Book 的一个属性方法,可以使用 static 属性来声明
class Book {
//...
static genPath(path) {
if (!path.startsWith('/')) path = `/${path}`
return `${UPLOAD_PATH}${path}`
}
}
电子书解析算法
-
首先获取
epub实例spine中的toc的href(如果没有则通过manifest获取),之后根据这个地址读取对应ncx文件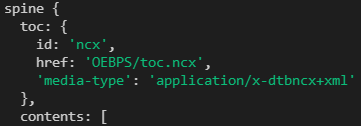
-
由于
ncx是xml文件,需要结合xml2js(获取json.ncx.navMap)将其转换成json
-
epub.flow数组里面是电子书目录的展示顺序,不过这个不一定是实际的目录,最好还是结合json.ncx.navMap.navPoint去找到目录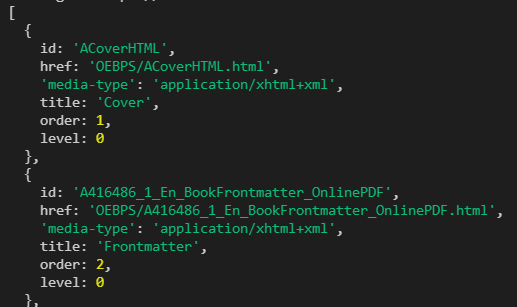
-
最后将一些有用的信息添加到
chapter最后 push 到数组中,内容如下: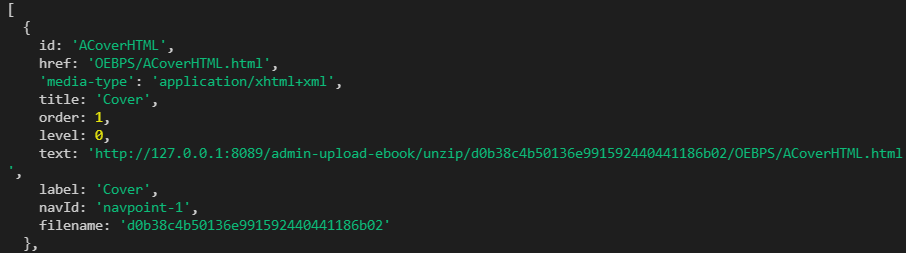
-
目录也是有层级的,比如第一章里有第一节,第一节里有第一小节,所以需要用
flatten方法将其拍平。按照这个思路我们可以手写 ES10 的flat方法,再附带一个reduce版本(也可以使用三目运算符,那样就只有一行了)const arr = [1, [2, [3, [4, [5]], [6]], [7]]] console.log(arr.flat(Infinity)) // [1, 2, 3, 4, 5, 6, 7] function flatten(arr) { return [].concat( ...arr.map(item => { if (Array.isArray(item)) return [].concat(...flatten(item)) return item }) ) } console.log(flatten(arr)) // [1, 2, 3, 4, 5, 6, 7] function flattenReduce(arr) { return arr.reduce((acc, cur) => { if (Array.isArray(cur)) return acc.concat(flattenReduce(cur)) return acc.concat(cur) }, []) } console.log(flattenReduce(arr)) // [1, 2, 3, 4, 5, 6, 7] -
处理一下目录,格式按照
el-tree数据格式来处理
const xml2js = require('xml2js').parseString
class Book {
//...
parseContents(epub) {
function getNcxFilePath() {
const spine = epub && epub.spine
const manifest = epub && epub.manifest
const ncx = spine.toc && spine.toc.href
const id = spine.toc && spine.toc.id
if (ncx) return ncx
return manifest[id].href
}
function findParent(array, level = 0, pid = '') {
return array.map(item => {
item.level = level
item.pid = pid
if (item.navPoint && item.navPoint.length > 0) {
item.navPoint = findParent(item.navPoint, level + 1, item['$'].id)
} else if (item.navPoint) {
item.navPoint.level = level + 1
item.navPoint.pid = item['$'].id
}
return item
})
}
function flatten(array) {
return [].concat(
...array.map(item => {
if (item.navPoint && item.navPoint.length > 0) {
return [].concat(item, ...flatten(item.navPoint))
} else if (item.navPoint) {
return [].concat(item, item.navPoint)
}
return item
})
)
}
const ncxFilePath = Book.genPath(`${this.unzipPath}/${getNcxFilePath()}`) // 获取ncx文件路径
if (fs.existsSync(ncxFilePath)) {
return new Promise((resolve, reject) => {
const xml = fs.readFileSync(ncxFilePath, 'utf-8') // 读取ncx文件
const filename = this.fileName
// 将ncx文件从xml转为json
xml2js(
xml,
{
explicitArray: false, // 设置为false时,解析结果不会包裹array
ignoreAttrs: false, // 解析属性
},
(err, json) => {
if (err) reject(err)
const navMap = json.ncx.navMap
if (navMap.navPoint && navMap.navPoint.length > 0) {
navMap.navPoint = findParent(navMap.navPoint)
const newNavMap = flatten(navMap.navPoint) // 将目录拆分为扁平结构
const chapters = []
newNavMap.forEach((chapter, index) => {
const src = chapter.content['$'].src
chapter.id = `${src}`
chapter.href = `${dir}/${src}`.replace(this.unzipPath, '')
chapter.text = `${UPLOAD_URL}${dir}/${src}`
chapter.label = chapter.navLabel.text || ''
chapter.navId = chapter['$'].id
chapter.fileName = filename
chapter.order = index + 1
chapters.push(chapter)
})
const chapterTree = []
chapters.forEach(c => {
c.children = []
if (c.pid === '') {
chapterTree.push(c)
} else {
const parent = chapters.find(_ => _.navId === c.pid)
parent.children.push(c)
}
})
resolve({ chapters, chapterTree })
} else {
reject(new Error('目录解析失败,目录数为0'))
}
}
)
})
} else {
throw new Error('目录文件不存在')
}
}
}















 2099
2099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









