










通过hive来创建一定格式的表,将相应的数据上传到hdfs相应的hive目录下,实现用spark的SQL风格进行读取里面的数据
Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所以有SparkSql的应用而生,他是将sparksql转换成RDD,然后提交到集群执行,执行效率非常快!
1:准备工作
将/hadoop-2.6.4/etc/hadoop下的core-site.xml,hdfs-site.xml,hive配置文件下的hive-site.xml复制到/spark-1.6.1-bin-hadoop2.6/conf下面

2:启动hdfs
如果配置环境变量的话直接使用:start-all.sh启动
官方不建议这样启动,但是比较方便呀,肯定要用的。
3:启动hive
如果配置了环境变量的话直接使用:hive启动
4:用Hive创建一个表

注意:在使用hive创建表的时候,我们不指定具体的数据库,而是将表创建在hive在hdfs上和hivebase.db同级关系目录上,

hivebase.db是通常是我们指定了,利用hive创建表时候创建在这个下面,但是今天我们不能创建在这下面,如果创建在hivebase.db下面的时候,使用SparkSQL时候出现

5.上传数据到表下(添加local代表的是本地文件上传到表下面)

6.启动Spark
/spark-1.6.1-bin-hadoop2.6/sbin使用./start-all.sh
7.启动Spark-shell
./spark-shell --master spark://mini77:7077 --executor-memory 512m --total-executor-cores 1 --driver-class-path 此处是数据库连接的架包地址


8.对hive下person表进行操作
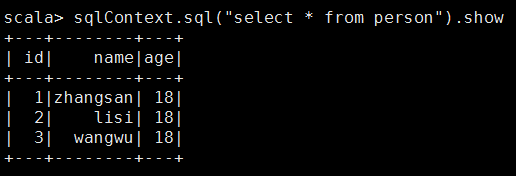
9.spark与hive进行比较,体会心得
spark处理数据的速度是真滴快啊,闪瞎双眼















 4564
4564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









