







好的加快检索速度,坏的索引再数据量较大时使性能急剧下降(与磁盘的读写有关)。
索引类型
索引实在存储引擎层实现的,所以没有统一的索引标准,依据不同的存储引擎的索引的工作方式并不一样。
BTree索引
一般默认的便是这个索引。
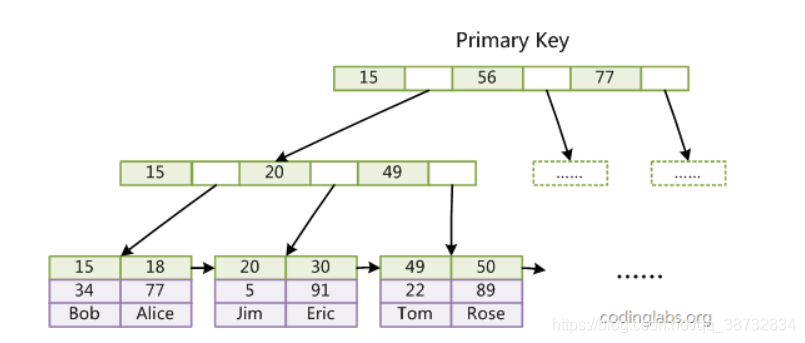
底层实现是基于BTree实现的(大多是B+Tree),它的优势在于它本身是多路查找树,查找的速度会很快,劣势是插入时由于需要维护树,所以会多消耗一些时间。MyISAM是非聚簇索引,就是索引里没有之间存储数据,而是通过数据的物理位置引用被索引的行。
(注意24下的索引值错了,该为0X56)
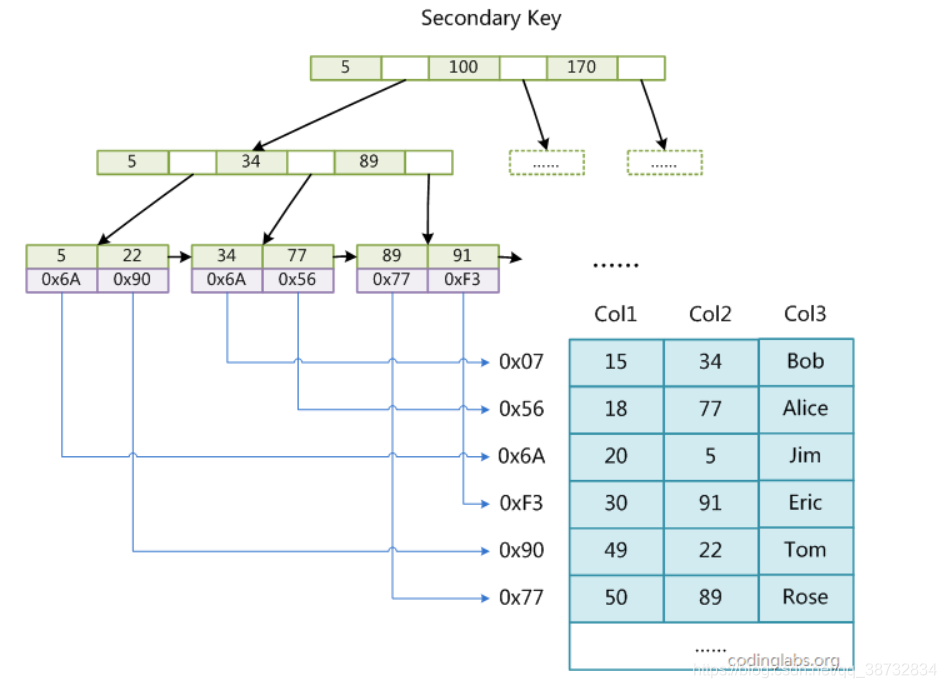
而InnoDB是聚簇索引,按照原数据格式进行存储,索引大小就会比MyISAM大。
用途
BTree索引适用于全键值、键值范围或键前缀查找。
全值匹配
对索引中的所有列进行匹配
匹配前缀
匹配前缀,比如匹配aaab,就是匹配索引字段开头为aaab的所有行
这就是不要在开头使用通配符的原因
不过注意索引的使用必须从左到右。且无法跳过某列,所以是复合索引的话,顺序的指定就相当重要。
匹配范围值
由于B+树的结构所以支持范围查找。
如果中间某列使用了范围查找,则其他列的索引就无法使用了,
hash索引
基于Hash表的实现,只有精确匹配索引所有列的查询才有效。对于每一行数据都会计算一个hashcode,目前只有Memory引擎和NDB引擎支持Hash。在InnoDB中会产生一种自适应Hash,如果某个索引值被频繁使用,它会在内存中基于BTree索引之上再创建一个Hash索引,如果有必要可关闭此功能。
限制
- hash索引只包含hashcode和行指针,所以无法避免读取行。不过在内存中读取速度很快,所以影响不算明显
- 无法用于排序
- 不支持部分匹配,如果对(A,B)建Hash索引,则无法只对A使用索引。
- 不支持范围查找
- 如果出现hash冲突了,查询速度会在该桶内变为O(n)(遍历链表)
- 冲突多时,维护代缴比较大
自定义Hash
InnoDB或者MyISAM中是不支持Hash的,可自定义一个Hash函数或者调用库函数,来将一串内容比较长的字段转换为Hash值,通过BTree搜索如果某个索引是热门索引,Innodb会自建一个Hash值,间接使用Hash算法。不过需要注意自建Hash函数的冲突的问题。
首先建表,由于不想每次都自己手动算hash值,所以创建了两个触发器来自动维护hash值。
CREATE TABLE `testm` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`url` varchar(255) NOT NULL DEFAULT '',
`url_crc` int(10) unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `url_crc` (`url_crc`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE TRIGGER `pseudohash_crc_ins` BEFORE INSERT ON `testM` FOR EACH ROW BEGIN SET NEW.url_crc = CRC32(NEW.url);
END;
CREATE TRIGGER `pseudohash_crc_upd` BEFORE UPDATE ON `testM` FOR EACH ROW BEGIN SET NEW.url_crc = CRC32(NEW.url);
END;
查询
EXPLAIN SELECT id FROM testm WHERE url_crc=CRC32('www.bytedance.com') AND url='www.bytedance.com' ;

空间索引(R-Tree)
MyISAM支持空间索引,可用于地理数据存储。不常用
全文索引
它查找的是文中的关键词,类似于搜索引擎。是一个较为特殊的索引在同一列可以同时创建全文索引和BTree索引,适用于MATCH AGAINST操作。














 4826
4826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









