







一、代码
先看代码,不想理解可以直接抄
public class Demo {
public static int getIndexOf(String s1, String s2) {
// 如果两个字符串为空,或者要匹配的字符串比原字符串还长,一定找不到
if (s1 == null || s2 == null || s2.length() < 1 || s1.length() < s2.length()) {
return -1;
}
char[] str1 = s1.toCharArray();
char[] str2 = s2.toCharArray();
// x、y代表s1和s2当前比较的位置
int x = 0;
int y = 0;
// 生成s2(要匹配的字符串)的前缀数组
int[] next = getNextArray(str2);
// 比较
while (x < str1.length && y < str2.length) {
if (str1[x] == str2[y]) {
// 如果当前值相同,分别后移
x++;
y++;
} else if (next[y] == -1) { // y == 0
// 如果当前值不同,且前缀数组中y已经没有相同的前缀
// x+1,重新开始比
x++;
} else {
// 如果当前值不同,且next数组中y还有相同的前缀
// y跳到前缀的位置,继续和x比
y = next[y];
}
}
// 如果上面循环结束之后y越界,一定是找到了匹配的字段
return y == str2.length ? x - y : -1;
}
public static int[] getNextArray(char[] str2) {
// 如果字符串长度为1,不需要求,没有相同的前缀组合
if (str2.length == 1) {
return new int[] { -1 };
}
// 长度>=2的时候
int[] next = new int[str2.length];
// 0和1下标的值一定是-1和0
next[0] = -1;
next[1] = 0;
// 从2位置开始算每个位置前面有多少的前缀
int i = 2;
// 比较的下标
int preIndex = 0;
// 如果i没有越界
while (i < next.length) {
if (str2[i - 1] == str2[preIndex]) {
// 如果i-1和pre相同,那么i的位置的前缀就取决于i-1的前缀
// 而i-1的前缀长度一定是pre
// 立即推:如果i-1和pre相同,i位置前面必有pre+1个相同的前缀
next[i++] = ++preIndex;
} else if (preIndex > 0) {
// 如果i-1和pre不同,那么i位置的前缀就不取决于i-1的前缀
// 因为i和pre是一步一步推过来的,如果i-1和pre不一样,那么前缀只能存在于pre之前
// 前缀索引跳到pre为止,继续比对
preIndex = next[preIndex];
} else {
// 如果跳到前缀索引已经没有前缀了,说明没有一个符合的长度,直接为0
next[i++] = 0;
}
}
return next;
}
}
二、Next数组流程详解
前言:如果不会动态规划,请你退出,学完动态规划再来,因为获取前缀数组本身就是一个一维的动态规划
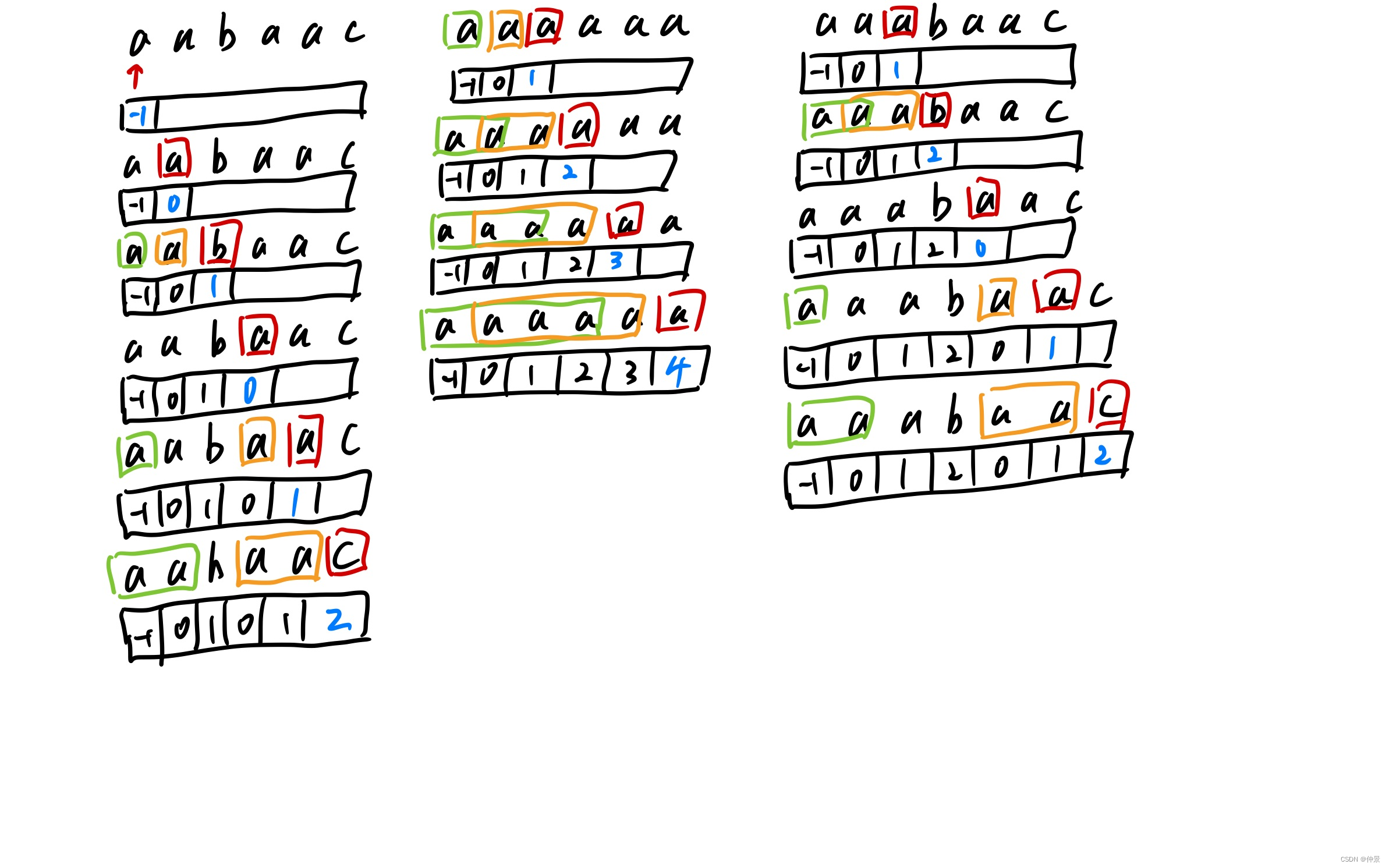
前缀数组的定义:
char数组中,当前位置之前,最大的前缀长度是多少,长度不超过index
通俗的理解就是当前下标之前,如果存在一个从头开始和从尾结束的子字符串并且二者是完全相同的,他的长度是多少,如下图所示
public static int[] getNextArray(char[] str2) {
// 如果字符串长度为1,不需要求,没有相同的前缀组合
if (str2.length == 1) {
return new int[] { -1 };
}
// 长度>=2的时候
int[] next = new int[str2.length];
// 0和1下标的值一定是-1和0
next[0] = -1;
next[1] = 0;
// 从2位置开始算每个位置前面有多少的前缀
int i = 2;
// 比较的下标
int preIndex = 0;
// 如果i没有越界
while (i < next.length) {
if (str2[i - 1] == str2[preIndex]) {
// 如果i-1和pre相同,那么i的位置的前缀就取决于i-1的前缀
// 而i-1的前缀长度一定是pre
// 立即推:如果i-1和pre相同,i位置前面必有pre+1个相同的前缀
next[i++] = ++preIndex;
} else if (preIndex > 0) {
// 如果i-1和pre不同,那么i位置的前缀就不取决于i-1的前缀
// 因为i和pre是一步一步推过来的,如果i-1和pre不一样,那么前缀只能存在于pre之前
// 前缀索引跳到pre为止,继续比对
preIndex = next[preIndex];
} else {
// 如果跳到前缀索引已经没有前缀了,说明没有一个符合的长度,直接为0
next[i++] = 0;
}
}
return next;
}
要点讲解1
if (str2[i - 1] == str2[preIndex]) {
// 如果i-1和pre相同,那么i的位置的前缀就取决于i-1的前缀
// 而i-1的前缀长度一定是pre
// 立即推:如果i-1和pre相同,i位置前面必有pre+1个相同的前缀
next[i++] = ++preIndex;
}
这是一个非常简单的动态规划推倒,因为我们对前缀数组的定义是除开本身的位置,所以是用i-1来比
假设之前的比较过程都是一个黑盒,那么如果我们当前比较的位置是相同的话,那么当前位置的前缀值一定是和前一位的前缀值挂钩的,而且正好比较位置相同,
所以当前位置的前缀值就是前一个位置的前缀值+1
i++和++preIndex:因为要依次求i位置的前缀值,所以i要自增,且当前比较相同,所以preIndex也要向后移动,用来继续比较
而且preIndex记录的是前一个比较成功的索引,如果前一个也相等,那么前一个的前缀值个数一定是preIndex个,而现在的前缀值就是preIndex+1个
上面的逻辑可以合并,就成了i++和++preIndex
要点讲解2
else if (preIndex > 0) {
// 如果i-1和pre不同,那么i位置的前缀就不取决于i-1的前缀
// 因为i和pre是一步一步推过来的,如果i-1和pre不一样,那么前缀只能存在于pre之前
// 前缀索引跳到pre为止,继续比对
preIndex = next[preIndex];
}
首先需要明确一个事情,就是preIndex指向的位置,一定是上一个比较相同的位置
所以如果当前的比较不成功的话,可能会出现的范围会在哪里?
一定是在前一个比较成功的索引范围上找,前一个比较成功的范围是什么?就是前缀数组中preIndex指向的位置,如果指向0或者-1,代表没有
所以如果比较不成功的话,直接跳转到前缀数组中preIndex所表示下标的位置,实现对代码的加速
要点讲解3
else {
// 如果跳到前缀索引已经没有前缀了,说明没有一个符合的长度,直接为0
next[i++] = 0;
}
当前面的两个条件都不成立,也就是跳到了开头都没有匹配成功的前缀,那么当前位置的前缀一定是0
三、KMP流程详解
public static int getIndexOf(String s1, String s2) {
// 如果两个字符串为空,或者要匹配的字符串比原字符串还长,一定找不到
if (s1 == null || s2 == null || s2.length() < 1 || s1.length() < s2.length()) {
return -1;
}
char[] str1 = s1.toCharArray();
char[] str2 = s2.toCharArray();
// x、y代表s1和s2当前比较的位置
int x = 0;
int y = 0;
// 生成s2(要匹配的字符串)的前缀数组
int[] next = getNextArray(str2);
// 比较
while (x < str1.length && y < str2.length) {
if (str1[x] == str2[y]) {
// 如果当前值相同,分别后移
x++;
y++;
} else if (next[y] == -1) { // y == 0
// 如果当前值不同,且前缀数组中y已经没有相同的前缀
// x+1,重新开始比
x++;
} else {
// 如果当前值不同,且next数组中y还有相同的前缀
// y跳到前缀的位置,继续和x比
y = next[y];
}
}
// 如果上面循环结束之后y越界,一定是找到了匹配的字段
return y == str2.length ? x - y : -1;
}
要点讲解1
while (x < str1.length && y < str2.length)
如果比较过程中,x已经越界或者y已经越界,说明已经没得比了,这就是base case
要点讲解2
if (str1[x] == str2[y]) {
// 如果当前值相同,分别后移
x++;
y++;
}
当前比较相同,比较下一个,没什么说的
要点讲解3
else {
// 如果当前值不同,且next数组中y还有相同的前缀
// y跳到前缀的位置,继续和x比
y = next[y];
}
首先我们要明白前缀数组的意义,就是说如果当前索引的前缀数组的值为i,当前索引位置为index,那么必有[0,i-1]和[index-i,index-1]可以组成完全相同的字符串
那么!当我们x和y不相同的时候,前面是不是相等的吧,因为前面相等,我们才能比到现在的位置吧
前面相等可以得出什么结论?
我们可以跳过前缀数组中y位置值的个数的位置
也就是说y的前缀数组值为i,那么[0,i]和[y-i,y-1]组成的字符串是相同的
又因为x和y之前的比较都是相同的,所以在x字符数组中必然有[0,i]和[x-i,x-1]组成的数组是相同的
经过坐标换算,所以[0,i]和[y-i,y-1和[x-i,x-1是相同的
那我们还需要再比x字符数组上[0,i]的位置和y字符数组上[0,i]吗,没必要!
所以!立即推:y直接跳到前缀数组中y对应值的下标,继续和x比
要点讲解4
else if (next[y] == -1) { // y == 0
// 如果当前值不同,且前缀数组中y已经没有相同的前缀
// x+1,重新开始比
x++;
}
这里取决于上面要点3的流程,如果x和y数组没有一个前缀能匹配的上,那还是老老实实的x后移,重新和y开始比吧
为什么不对y重置?因为前缀数组中只有y=0的时候,值才会是-1,所以此时x和y都是归零的!
要点讲解5
// 如果上面循环结束之后y越界,一定是找到了匹配的字段
return y == str2.length ? x - y : -1;
首先要明白,当循环结束的时候,要么是x越界了,要么是y越界了
只存在以下可能
- x和y同时越界,正好比完了,找到了匹配的值
- x越界了,y没越界,x比完了y还没比完,没找到
- x没越界,越界了,y比完了,找到了
所以判断找没找到的一句就是y有没有越界
为什么y没越界返回x-y的值?
首先我们一定是找到了匹配的值对吧,在y位置时候和x的某一段全部匹配上了
当时的情况应该是什么样呢?
x,不知道在哪,哪里都有可能,要么越界要么每越界
但是x和y比到最后相同,y越界的话,那么匹配到的开始位置,一定是最后x的位置减去y数组的长度
因为y一定会越界,所以在x中开始位置就是x-y


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









