







hibernate的快速入门
一:hibernate_day01
入门案列&搭建环境
- 导入hibernate所需jar包,注意hibernate本身没有日志输出的jar包,所以要导入日志的jar包和mysql驱动jar
- 创建hibernate的核心配置文件,位置和名称是固定的,在src下创建一个名为hibernate.cfg.xml
- 创建实体类,并为实体写一份映射文件,记得引入到核心配置文件,hibernate只读核心配置文件
- 然后使用hibernate来实现添加操作
1.1:导入jar包

1.2:在src下创建一个名为hibernate.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 第一部分: 配置数据库四大参数 必须的 -->
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql://127.0.0.1:3306/exam?useSSL=false&serverTimezone=UTC</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">123456</property>
<!-- 第二部分: 配置hibernate信息 可选的-->
<!-- 输出底层sql语句 -->
<property name="hibernate.show_sql">true</property>
<!-- 输出底层sql语句格式 -->
<property name="hibernate.format_sql">true</property>
<!-- hibernate帮创建表,需要配置之后
update: 如果已经有表,更新,如果没有,创建
-->
<property name="hibernate.hbm2ddl.auto">update</property>
<!-- 配置数据库方言
在mysql里面实现分页 关键字 limit,只能使用mysql里面
在oracle数据库,实现分页rownum
让hibernate框架识别不同数据库的自己特有的语句
-->
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<!-- 第三部分: 把映射文件放到核心配置文件中 必须的-->
<!--
class属性:是引入持久化类的全路径(使用注解的方式)
resource属性:是引入实体类对应的映射文件(使用xml配置的方式)
-->
<mapping class=""/>
<mapping resource=""/>
</session-factory>
</hibernate-configuration>
1.3:创建实体类,并为实体写一份映射文件,映射文件名一般为:实体类.hbm.xml
User.java
public class Person {
private Integer pid;
private String username;
private double salary;
// 提供getter/setter
}
User.hbm.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<!--配置类和表对应
class标签
name属性:实体类全路径
table属性:数据库表名称,不写表名默认就是类名
-->
<class name="cn.itcast.entity.User" table="t_user">
<!--
配置实体类id和表id对应
hibernate要求实体类有一个属性唯一值
hibernate要求表有字段作为唯一值
-->
<!--
id标签
name属性:实体类里面id属性名称
column属性:生成的表字段名称,不写列名默认就是属性名
-->
<id name="uid" column="uid">
<!--
设置数据库表id增长策略
native:生成表id值就是主键自动增长,必须是int类型
uuid: 必须是String类型
-->
<generator class="native"></generator>
</id>
<!--
配置其他属性和表字段对应
name属性:实体类属性名称
column属性:生成表字段名称,不写列名默认就是属性名
type属性: 指定属性的类型,hibernate会默认自动转换
-->
<property name="username"></property>
<property name="salary"></property>
</class>
</hibernate-mapping>
注:映射文件中的name属性都是填实体类中属性的名字,column不给的话,默认生成的列名和属性名一致
1.4:然后使用hibernate来实现添加操作
public class Demo {
@Test
public void insertUser() {
//1.加载hibernate核心配置文件
Configuration cfg = new Configuration().configure();
//2.创建SessionFactory对象
SessionFactory sessionFactory = cfg.buildSessionFactory();
//3.使用SessionFactory创建Session
Session session = sessionFactory.openSession();
//4.开启事务
Transaction tx = session.beginTransaction();
//5.写crud操作
Person person = new Person();
person.setUsername("wzj");
person.setSalary(1000000.0);
session.save(person);
//6.提交事务
tx.commit();
//7.关闭资源(倒关)
session.close();
sessionFactory.close();
}
}
1.5: hibernate输出语句
Hibernate:
insert
into
t_person
(username, salary)
values
(?, ?)
1.6: 使用hibernate生成的表结构: show create table 表名
CREATE TABLE `t_person` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(255) DEFAULT NULL,
`salary` double DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
注:它这里将实体类的double类型的salary,映射成了一个表里面的salary列,类型是一样的,我还以为是decimal哦
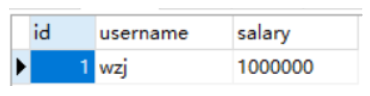
1.7: 表中的数据:
1.8: 我遇到的异常:
hibernate.service.spi.ServiceException: Unable to create requested service [org.hibernate.engine.jdbc.env.spi.JdbcEnvironment]
原因:我之前是mysql-connector-java-5.0.4-bin.jar,跟jdbcURL这里有点关系,我后面换成mysql-connector-java-8.0.18.jar了
org.hibernate.exception.GenericJDBCException: could not execute statement
原因:我使用hibernate创建表t_person想往数据库插入,但是数据库中已经存在了t_person表,所以报了这个错误,把之前的表删了就行,还有一种可能是没在实体类中的主键上加上@column(name =“xxx”) 并指定列名!(这一点是针对注解的,xml也类似!!)
二:Hibernate_day02
- 实体类的编写规则
- hibernate主键生成策略
- 对实体类crud操作
- 实体类对象的状态
- hibernate的缓存
- hibernate的Api使用
2.1:实体类的编写规则
a.实体类中的属性应该私有,并且提供getter/setter方法
b.实体类中应该有属性作为唯一值
c.基本类型的属性,建议使用对应的包装类
注:int score = 0; 如果这样表示分数为0,那么没考试的怎么表示呢?
Integer score = 0; 这样表示分数为0,
Integer score = null; 这样表示没有参加考试。
2.2:hibernate主键生成策略
hibernate的主键生成策略很多,这里介绍两种:native和uuid
注:使用native,类型必须是整型,使用uuid, 必须是字符串
2.3:对实体类crud操作
public class PersonCrud {
private SessionFactory sessionFactory;
private Session session;
private Transaction tx;
@Before
public void before() {
Configuration cfg = new Configuration().configure();
sessionFactory = cfg.buildSessionFactory();
session = sessionFactory.openSession();
tx = session.beginTransaction();
}
@After
public void after() {
tx.commit();
session.close();
sessionFactory.close();
}
@Test
public void insertPerson() {
Person person = new Person();
person.setUsername("wzj");
person.setSalary(1000000.0);
session.save(person);
//Hibernate: insert into t_person(username, salary) values (?, ?)
}
@Test
public void selectPerson() {
//根据id查询
Person person = session.get(Person.class, 1);
System.out.println(person);
//类似Hibernate: select p.id,p.usernmae,p.salary from t_person as p where p.id = ?
}
@Test
public void updatePerson() {
//需求:将id=1的username改为"daShuaibi";
//1.根据id查询
Person person = session.get(Person.class, 1);
//2.设置值
person.setUsername("daShuaibi");
//3.执行update方法,执行过程:去user对象里面找到uid值,根据uid进行修改
session.update(person);
//在步骤一的时候:类似Hibernate: select p.id,p.usernmae,p.salary from t_person as p where p.id = ?
//在步骤三之后: 类似Hibernate: update t_person set username=?, salary=? where id=?
}
@Test
public void deletePerson() {
//1.根据id查询出来
Person person = session.get(Person.class, 1);
//2.然后调用delete方法
session.delete(person);
//在步骤一之后: 类似Hibernate: select p.id,p.usernmae,p.salary from t_person as p where p.id = ?
//在步骤二之后: 类似Hibernate: delete from t_person where id=?
}
}
2.4:hibernate的实体类对象状态
- hibernate中的实体类的状态一共有三种,分别是瞬时态,持久态,脱管态
Person person = new Person(); //瞬时态:对象里面没有id值,没有和session关联
Person person = Session.get(Person.class,1); //持久态:对象里面有id值,对象和session关联
Person person = new Person();//脱管态:对象里面有id,对象和session没有关联
person.setPid(2);
注:介绍一个方法: session.saveOrUpdate(Object obj); 对瞬时态是作添加操作,对持久态和脱管态是作修改操作
2.5:Hibernate的缓存
- 为什么需要缓存?
由于数据库本身是文件系统,数据存到数据库里面,如果频繁的使用IO进行操作,效率不是很高!
所以我们可以把数据存到内存中,读取内存中的数据,效率非常高!
- hibernate中的缓存分为一级缓存和二级缓存
- 一级缓存默认是打开的,使用的范围是Session级别的范围
- 二级缓存默认是关闭的,需要配置,使用的范围是SessionFactory级别的范围,但是目前基本不使用,使用redis替代
验证一级缓存的存在
@Test
public void firstLevelCache() {
Person p1 = session.get(Person.class, 1);//类似Hibernate: select p.id,p.usernmae,p.salary from t_person as p where p.id = ?
Person p2 = session.get(Person.class, 1);//没有发送sql,因为查询的数据在缓存中存在
System.out.println(p1==p2);//true
}
一级缓存的原理
Hibernate一级缓存执行过程,特别像我上厕所没纸,去买纸的过程!
首先我肯定打开我的柜子看有没有纸(查询一级缓冲),如果有我就直接用了,
如果没有我就去下面的商店去买(查询数据库),买完之后,我肯定还是放在我的柜子里,
下次我上厕所肯定还是先找柜子里有没有纸!
2.6:hibernate中查询的API
2.6.1:Query对象(HQL):
使用它,不需要写SQL语句,但需要写HQL,语法和SQL很相似,只不过SQL操作的是表和列,而HQL操作的是实体类和里面的属性!!
public class QueryMode1 {
private SessionFactory sessionFactory;
private Session session;
private Transaction tx;
@Before
public void before() {
Configuration cfg = new Configuration().configure();
sessionFactory = cfg.buildSessionFactory();
session = sessionFactory.openSession();
tx = session.beginTransaction();
}
@After
public void after() {
tx.commit();
session.close();
sessionFactory.close();
}
//投影查询:查询不是所有字段值,而是部分字段的值,不能跟*号
@Test
public void projectionQuery() {
Query query = session.createQuery("select username, salary from Person");
System.out.println(query.list().size());;
//hibernate语句类似:select p.username, p.salary from t_person;
}
//查询所有: HQL有点特殊,跟想象的不太一样
@Test
public void queryAll() {
Query query = session.createQuery("from Person");
List<Person> list = query.list();
System.out.println(list.size());
//hibernate语句类似: select p.id, p.username, p.salary from t_person as p;
}
//条件查询
@Test
public void conditionalQuery() {
Query query = session.createQuery("from Person where pid = ?").setParameter(0, 1);
Object object = query.uniqueResult();
System.out.println(object);
//hibernate语句类似: select p.id, p.username, p.salary from t_person as p where p.id = ?;
}
//模糊查询
@Test
public void FuzzyQuery() {
Query query = session.createQuery("from Person where username like ?");
query.setParameter(0, "%w%"); //它的返回值其实还是Query,可以继续调用setParameter(),链式编程
List<Person> list = query.list();
System.out.println(list.size());
//hibernate语句类似: select p.id, p.username, p.salary from t_person as p where p.username like ?;
}
//排序查询
@Test
public void sortQuery() {
Query query = session.createQuery("from Person order by pid desc");
List<Person> list = query.list();
System.out.println(list.size());
//hibernate语句类似: select p.id, p.username, p.salary from t_person as p order by p.id;
}
//分页查询sql: select * from Department limit 0,3; HQL语句有点特殊:跟想象中的不一样!!
@Test
public void pagingQuery() {
Query query = session.createQuery("from Person limit");
query.setFirstResult(0);
query.setMaxResults(3);
System.out.println(query.list().size());;
//hibernate语句类似:select p.id, p.username, p.salary from t_person limit ?
}
@Test
public void groupFunction() {
Query query = session.createQuery("select count(*) from Person");
Object uniqueResult = query.uniqueResult();//因为组函数最终的结果集都是单行单列的!!
Number num = (Number)uniqueResult;
System.out.println(num.intValue());
//hibernate语句类似:select count(*) from t_person;
}
}
注:这里面跟我想象中不一样的HQL语句,只有查询所有和分页查询的语法,其他都跟以前是一样的!!!
2.6.2:Criteria对象,QBC(Query By Criteria)语句)
//criteria(标准): 也称为QBC(Query By Criteria)语句
public class QueryMode2 {
private SessionFactory sessionFactory;
private Session session;
private Transaction tx;
@Before
public void before() {
Configuration cfg = new Configuration().configure();
sessionFactory = cfg.buildSessionFactory();
session = sessionFactory.openSession();
tx = session.beginTransaction();
}
@After
public void after() {
tx.commit();
session.close();
sessionFactory.close();
}
//查询所有: HQL有点特殊,跟想象的不太一样
@Test
public void queryAll() {
Criteria criteria = session.createCriteria(Person.class);
List<Person> list = criteria.list();
//hibernate语句类似: select p.id, p.username, p.salary from t_person as p;
}
//条件查询
@Test
public void conditionalQuery() {
Criteria criteria = session.createCriteria(Person.class);
//Restrictions:限制的意思, Restrictions调用的静态方法返回的是一个Criteria,
//而Criteria.add()方法参数就是需要Criteria对象,并且返回值还是Criteria,牛逼的设计
criteria.add(Restrictions.eq("id", 1));
System.out.println(criteria.list().size());
//hibernate语句类似: select p.id, p.username, p.salary from t_person as p where p.id = ?;
}
//排序查询
@Test
public void sortQuery() {
Criteria criteria = session.createCriteria(Person.class);
criteria.addOrder(Order.desc("id"));//它可以既可以根据实体类中的属性查询(pid),还可以根据表中的列查询(id)!!!
System.out.println(criteria.list().size());
//hibernate语句类似: select p.id, p.username, p.salary from t_person as p order by p.id desc;
}
//分页查询sql: select * from Department limit 0,3;
@Test
public void pagingQuery() {
Criteria criteria = session.createCriteria(Person.class);
criteria.setFirstResult(0);
criteria.setMaxResults(3);
System.out.println(criteria.list().size());;
//hibernate语句类似:select p.id, p.username, p.salary from t_person limit ?
}
//组函数
@Test
public void groupFunction() {
Criteria criteria = session.createCriteria(Person.class);
criteria.setProjection(Projections.rowCount());
Object obj = criteria.uniqueResult();
Number num = (Number)obj;
int val = num.intValue();
System.out.println(val);
//hibernate语句类似:select count(*) from t_person;
}
}
QBC语句的特点:完全面向对象,真的不需要写SQL语句,调用对应的方法就行
注意:条件查询的时候,使用QBC时不管是用实体类中的属性还是表中的列名,都是ok的!
2.6.3:SQLQuery对象
//SQl Query查询
public class QueryMode3 {
private SessionFactory sessionFactory;
private Session session;
private Transaction tx;
@Before
public void before() {
Configuration cfg = new Configuration().configure();
sessionFactory = cfg.buildSessionFactory();
session = sessionFactory.openSession();
tx = session.beginTransaction();
}
@After
public void after() {
tx.commit();
session.close();
sessionFactory.close();
}
//查询所有1
@Test
public void queryAll() {
//注:不管是查询实体类名,还是表名都可以成功!!
SQLQuery query = session.createSQLQuery("select * from t_person");
//这里不会直接帮你封装到对应的对象中,它返回的是一个List<Object[]>,可以断点调试一下
List<Object[]> list = query.list();
System.out.println(list);
}
//查询所有2
@Test
public void queryAll2() {
//注:不管是查询实体类名,还是表名都可以成功!!
SQLQuery query = session.createSQLQuery("select * from t_person");
//加上这个方法,就会封装到Person对象中
query.addEntity(Person.class);
List list = query.list();
System.out.println(list);
}
}
查询所有1:

查询所有2:

注:SQLQuery不管是查询实体类还是表都行
三:Hibernate_day03
3.1:表与表之间的关系
- 一对一关系
- 夫妻关系:一个男人只能有一个老婆,反过来一个女人也只能有一个老公
- 一对多关系
- 部门和员工的关系:一个部门有多个员工,但一个员工只所属一个部门
- 客户和联系人的关系:一个客户里有多个联系人,但一个联系人只所属一个客户
- 分类和商品的关系:一个分类里有多个商品,但一个商品只属于一个分类
- 订单和订单项的关系:一个订单里面有多个订单项,但一个订单项只所属一个订单
- 多对多的关系
- 学生和老师的关系:一个老师有多个学生,同样的一个学生也有多个老师
- 用户和角色的关系:一个用户里面可以有多个角色,一个角色里面也可以有多个用户
1.一对多关系中的客户和联系人解释下:
客户:和公司有业务来往的,比如百度,阿里
联系人:公司里面的员工,比如百度下有很多员工,阿里下也有很多员工
2.多对多关系中的用户和角色解释下:
用户:张三,李四,王五
角色:董事长,爸爸,儿子
比如:张三可以是公司的董事长,可以是它儿子的爸爸,可以是它爸妈的儿子---> 一个用户有多个角色
比如:儿子可以是张三,可以是李四,可以是王五---> 一个角色可以有多个用户
注意:
一对多的关系:一般是多的一方(员工)引用一的那方(部门),从表(Employee)引用主表(Dept),外键引用主键
多对多的关系:一般需要额外创建一张中间表,在中间表中使用两个外键,来关联其他两个表的主键
3.2:hibernate中一对多的操作(xml版)
- 以客户和联系人为例,创建实体类,并让实现类之间描述这种一对多的关系
- 为每个实体类配置映射文件,然后引入到hibernate核心配置文件中
- 编写测试代码
3.2.1:创建实体类,并描述关系
public class Customer {
private Integer cid;
private String cname;
private String loc;
//一个客户有多个联系人,hibernate中表示多,建议是Set集合
private Set<LinkMan> linkMans = new HashSet<LinkMan>();
//省了getter/setter
}
public class LinkMan {
private Integer lid;
private String name;
//一个联系人所属一个客户
private Customer customer;
//省了getter/setter
}
3.2.2:配置映射文件
Customer.hbm.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="cn.itcast.mapping.Customer" table="t_customer">
<!--主键属性 -->
<id name="cid">
<generator class="native"></generator>
</id>
<!--普通属性 -->
<property name="cname"></property>
<property name="loc"></property>
<set name="linkMans">
<!--
一多对是有外键关联的,
hibernate机制:双向维护外键,在一方和多方都配置外键!
column属性:指定外键的名称!
-->
<key column="linkman_fk"></key>
<one-to-many class="cn.itcast.mapping.LinkMan"/>
</set>
</class>
</hibernate-mapping>
LinkMan.hbm.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="cn.itcast.mapping.LinkMan" table="t_linkMan">
<id name="lid">
<generator class="native"></generator>
</id>
<property name="name"></property>
<!--
从联系人的角度来看就是多对一
name: 就是一方的name,也就是customer属性名
class: 一方的全路径
column:
必须和Customer映射文件中的外键名一致,
如果column属性值省了不写的话,那么生成的t_linkMan表
会有两个外键: customer和linkman_fk, 指向t_customer表的主键!
-->
<many-to-one name="customer" class="cn.itcast.mapping.Customer" column="linkman_fk"></many-to-one>
</class>
</hibernate-mapping>
<mapping resource="cn/itcast/mapping/Customer.hbm.xml"/>
<mapping resource="cn/itcast/mapping/LinkMan.hbm.xml"/>
3.2.3:编写测试代码
@Test
public void testOneToMany() {
//1.创建客户对象
Customer customer = new Customer();
customer.setCname("阿里");
customer.setLoc("杭州");
//2.创建联系人对象
LinkMan linkMan1 = new LinkMan();
linkMan1.setName("wzj");
LinkMan linkMan2 = new LinkMan();
linkMan2.setName("sbt");
//3.将联系人添加到客户中
customer.getLinkMans().add(linkMan1);
customer.getLinkMans().add(linkMan2);
//4.保存客户
session.save(customer);
}
执行上面的时候出现异常
org.hibernate.TransientObjectException: object references an unsaved transient instance - save the transient instance before flushing: cn.itcast.mapping.LinkMan
大概意思是:对象依赖一个未保存的实体,保存这个实体在刷新之前。实体为“LinkMan”。
解决方案是:
- 在进行save操作之前先将关联的对象save一下
- 使用级联操作(这种方式在一对多的级联保存中演示)
使用第一种方案解决(复杂写法)
@Test
public void testOneToMany2() {
//1.创建客户对象
Customer customer = new Customer();
customer.setCname("阿里");
customer.setLoc("杭州");
//2.创建联系人对象
LinkMan linkMan1 = new LinkMan();
linkMan1.setName("wzj");
LinkMan linkMan2 = new LinkMan();
linkMan2.setName("sbt");
//3.表示实体之间的关系
//3.1: 一个客户有多个联系人
customer.getLinkMans().add(linkMan1);
customer.getLinkMans().add(linkMan2);
//3.2: 一个联系人只所属一个客户
linkMan1.setCustomer(customer);
linkMan2.setCustomer(customer);
//4.保存客户和联系人(顺序先后没有关系)
session.save(customer);
session.save(linkMan1);
session.save(linkMan2);
}
@Test
public void testOneToMany3() {
//1.创建客户对象
Customer customer = new Customer();
customer.setCname("阿里");
customer.setLoc("杭州");
//2.创建联系人对象
LinkMan linkMan1 = new LinkMan();
linkMan1.setName("wzj");
LinkMan linkMan2 = new LinkMan();
linkMan2.setName("sbt");
//先在这里把关联实体保存一下,仅此而已
session.save(linkMan1);
session.save(linkMan2);
//3.将联系人添加到客户中
customer.getLinkMans().add(linkMan1);
customer.getLinkMans().add(linkMan2);
//4.保存客户
session.save(customer);
}
hibernate发送的SQL
insert into t_linkMan(name, linkman_fk) values(?, ?);
insert into t_linkMan(name, linkman_fk) values(?, ?);
insert into t_customer(cname, loc) values (?, ?)
update t_linkMan set linkman_fk = ? where lid = ? -- 根据联系人的id,修改自己的外键
update t_linkMan set linkman_fk = ? where lid = ?

注:两个测试方法,最终生成的表数据是一样的!!
3.2.4:一对多的级联保存
什么是级联保存? :以客户和联系人为例,添加一个客户,为这个客户添加多个联系人
还记得我们在3.2.3中那段代码吗?,按照我们的思维习惯,确实应该是那样写,但是却报错了
怎么让它不报错,同时实现级联保存呢?
答案是:在(Customer主表)映射文件中的set标签中,加上cascade="save-update“ 就设置成了级联
<set name="linkMans" cascade="save-update">
3.2.5:一对多的级联删除
什么是级联删除?:以客户和联系人为例,就是删除一个客户,即同时会删除这个客户下的联系人!
怎么完成级联删除?跟配置级联保存的位置一样,如果级联保存和级联删除都使用,中间用逗号隔开即可
<set name="linkMans" cascade="save-update,delete">
@Test
public void testCascadeDelete() {
//1.先得在Customer的映射文件中的,set标签设置cascade="delete"
//2.根据id查询客户
Customer customer = session.get(Customer.class,1);
//3.删除客户
session.delete(customer);
}
hibernate发送的sql:
select c.cid, c.cname, c.loc from t_customer as c where c.id = ? -- 根据id查询客户
select lm from t_linkMan as lm where lm.linkman_fk = ? -- 根据外键id查询联系人
update t_linkMan set linkman_fk = null where linkman_fk = ? -- 将联系人(从表)的外键设置为空
delete from t_linkMan where lid = ? -- 根据id,删除联系人表(从表),再根据id删除客户表(主表)
delete from t_linkMan where lid = ?
delete from t_customer where cid = ?
3.2.6:一对多的修改操作

@Test
public void testUpdate() {
//1.先根据id查询联系人,再根据id查询客户
LinkMan wzj = session.get(LinkMan.class, 1);
Customer tengxun = session.get(Customer.class, 2);
//2.互相关联
//2.1 把联系人放到客户中
tengxun.getLinkMans().add(wzj);
//2.1 把客户放到联系人中
wzj.setCustomer(tengxun);
//因为联系人和客户是持久态对象,会自动更新,不需要调用session.update()
}
以上可以完成需求,但是性能不是很好!!我们来看一下执行上面代码,hibernate最后发送的两条SQL语句
update t_linkMan set name=?,linkman_fk=? where lid=?
update t_linkMan set name=?,linkman_fk=? where lid=?
注:因为hibernate是双向维护外键,修改客户的时候修改了一次外键,修改联系人的时候修改了一次外键,造成效率问题
那如何解决上面出现的问题呢?让一的那方不维护外键:一对多里面,让一方放弃外键维护
举例:一个国家的主席和人民是一对多的关系,让主席记住每个人民的名字显然不现实,但让人民们记得主席的名字这就很容易,
怎么实现呢?
在放弃关系维护映射文件中(主表中),进行配置,在set标签上使用inverse属性
<!--
inverse属性默认值是false:
false不放弃关系维护
true放弃关系维护
-->
<set name="linkMans" inverse="true">
3.3:hibernate中多对多的操作(xml版)
- 以老师和学生为例,创建实体类,并让实现类之间描述这种多对多的关系
- 为每个实体类配置映射文件,然后引入到hibernate核心配置文件中
- 编写测试代码
3.3.1:创建实体类,并描述关系
public class Teacher {
private Integer tid;
private String name;
//一个老师有多个学生
private Set<Student> students = new HashSet<Student>();
//省了getter/setter
}
public class Student {
private Integer sid;
private String name;
//一个学生有多个老师
private Set<Teacher> teachers = new HashSet<Teacher>();
//省了getter/setter
}
3.3.2:配置映射文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="cn.itcast.mapping2.Teacher" table="t_teacher">
<id name="tid">
<generator class="native"></generator>
</id>
<property name="name"></property>
<!--
table: 配置中间表的名称
-->
<set name="students" table="teach_stu_middle">
<!--
column:是配置当前映射文件在第三张表中的外键名称
-->
<key column="teacher_id"></key>
<!--
从老师(当前映射文件)的角度来看和学生的关系是多对多
column:是配置关联的实体在第三张表中的外键名称
-->
<many-to-many class="cn.itcast.mapping2.Student" column="stu_id"></many-to-many>
</set>
</class>
</hibernate-mapping>
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="cn.itcast.mapping2.Student" table="t_student">
<id name="sid">
<generator class="native"></generator>
</id>
<property name="name"></property>
<!--
table:要和老师表中指定为一致的!,下面的外键也应该一一对应
-->
<set name="teachers" table="teach_stu_middle">
<key column="stu_id"></key>
<!--从学生(当前映射文件)的角度来看,和老师的关系也是多对多 -->
<many-to-many class="cn.itcast.mapping2.Teacher" column="teacher_id"></many-to-many>
</set>
</class>
</hibernate-mapping>
3.3.3:一对多的级联保存
根据老师保存学生,在老师的映射文件中的set标签上进行配置cascade="save-update"
<set name="students" table="teach_stu_middle" cascade="save-update">
测试代码
@Test
public void testManyToMany() {
//1.创建老师对象
Teacher teacher = new Teacher();
teacher.setName("wzj");
//2.创建学生对象
Student s1 = new Student();
s1.setName("马化腾");
Student s2 = new Student();
s2.setName("雷军");
//3.把学生添加到老师中
teacher.getStudents().add(s1);
teacher.getStudents().add(s2);
//4.最终保存老师
session.save(teacher);
}
(1)hibernate发送的SQL:
insert into t_teacher(name) values(?) //往t_teacher表中插入
insert into t_student(name) values(?) //往t_student表中插入
insert into t_student(name) values(?)
insert into teach_stu_middle(teacher_id, stu_id) values(?,?)//往中间表中插入
insert into teach_stu_middle(teacher_id, stu_id) values(?,?)
(2)生成的中间表的表结构的SQL:
CREATE TABLE `teach_stu_middle` (
`teacher_id` int(11) NOT NULL,
`stu_id` int(11) NOT NULL,
PRIMARY KEY (`stu_id`,`teacher_id`),
KEY `FKe0yx8vg7lmix2qjek46w46wv1` (`teacher_id`),
CONSTRAINT `FKcxyry7s1gcctf546qphmsl7fh` FOREIGN KEY (`stu_id`) REFERENCES `t_student` (`sid`),
CONSTRAINT `FKe0yx8vg7lmix2qjek46w46wv1` FOREIGN KEY (`teacher_id`) REFERENCES `t_teacher` (`tid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
注:可以看到teacher_id, stu_id 既是主键又是外键
(3)生成的表记录:

3.3.4:一对多的级联删除(了解)
(1)跟一对多的级联删除类似,根据老师删除它教的全部学生,在老师的映射文件中cascade="delete"
<set name="students" table="teach_stu_middle" cascade="delete">
(2)代码演示
@Test
public void testManyToMany2() {
//根据id为1的老师,删除它下面教过的全部学生!
Teacher teacher = session.get(Teacher.class, 1);
session.delete(teacher);
}
(3)hibernate发送的SQL:
-- 1.
select t.tid, t.tname from t_teacher t where t.tid = ?
-- 2.
select
middle.teacher_id,teacher_id.stu_id,s.sid, s.sname
from
teach_stu_middle middle
inner join
t_student s
on
middle.stu_id = s.sid
where
middle.teacher_id = ?
-- 3.
delete from teach_stu_middle where teacher_id=?
delete from teach_stu_middle where stu_id=?
delete from teach_stu_middle where stu_id=?
-- 4.
delete from t_student where sid=?
delete from t_student where sid=?
delete from t_teacher where tid=?
-- 到了后面大致还是先删从表(有外键的表),再删主表
3.4:HQL多表查询
3.4.1:回忆Mysql中的多表查询
注: 在学习HQL多表查询之前,我们先来复习一下Mysql中多表查询,以客户和联系人为例
- 内连接
-- 方言
select
l.*, c.*
from
t_linkMan l, t_customer c
where
l.linkman_fk = c.cid
-- 标准
select
l.*, c.*
from
t_linkMan l
inner join
t_customer c
on
l.linkman_fk = c.cid;
- 左外连接
-- 左外连接: 把左表(t_linkman)的数据全部表示出来, 右边的话只表示关联的数据
select
l.*, c.*
from
t_linkman l
left outer join
t_customer c
on
l.linkman_fk = c.cid;
- 右外连接
-- 右外连接:把右表的数据全部表示出来,左边的话只表示关联的数据
select
l.*, c.*
from
t_linkman l
right outer join
t_customer c
on
l.linkman_fk = c.cid;
3.4.2:HQL中的多表查询(以客户和联系人为例)
/**
* HQL中的多表查询
* 1.内连接,迫切内连接:
* 区别:一个返回的list是Object[], 一个返回的list里面是帮你封装好的对象
* 还有迫切内连接比内连接多了个fetch
* 相同点:
* 发送的sql其实都是一样的 !!
* 2.左外连接,迫切左外连接(注:和内连接的区别,相同点类似)
* 3.右外连接,迫切右外连接(注:和内连接的区别,相同点类似)
* @author wzj
*
*/
public class QueryMode4 {
private SessionFactory sessionFactory;
private Session session;
private Transaction tx;
@Before
public void before() {
Configuration cfg = new Configuration().configure();
sessionFactory = cfg.buildSessionFactory();
session = sessionFactory.openSession();
tx = session.beginTransaction();
}
@After
public void after() {
tx.commit();
session.close();
sessionFactory.close();
}
@Test
public void innerJoinQuery(){
//这里的c.linMans代表联系人表的意思
Query query = session.createQuery("from Customer c inner join c.linkMans");
List list = query.list();
System.out.println(list);
}
@Test
public void fetchInnerJoinQuery(){
Query query = session.createQuery("from Customer c inner join fetch c.linkMans");
List list = query.list();
System.out.println(list);
}
@Test
public void leftOuterJoinQuery(){
//这里的c.linMans代表联系人表的意思
Query query = session.createQuery("from Customer c left outer join c.linkMans");
List list = query.list();
System.out.println(list);
}
@Test
public void fetchLeftOuterJoinQuery(){
//这里的c.linMans代表联系人表的意思
Query query = session.createQuery("from Customer c left outer join fetch c.linkMans");
List list = query.list();
System.out.println(list);
}
@Test
public void rightOuterJoinQuery(){
//这里的c.linMans代表联系人表的意思
Query query = session.createQuery("from Customer c right outer join c.linkMans");
List list = query.list();
System.out.println(list);
}
@Test
public void fetchRightOuterJoinQuery(){
//这里的c.linMans代表联系人表的意思
Query query = session.createQuery("from Customer c right outer join fetch c.linkMans");
List list = query.list();
System.out.println(list);
}
}
总结:HQL多表查询的语法上和SQL很相似,这里使**用迫切(fetch)**的话,它会帮你封装成一个对象,否则是一个Object[]
(1)演示内连接返回的list集合中的元素是Object[]

(2)演示迫切内连接返回的list集合中的元素是对象

3.5:检索策略
hibernate中的检索策略有两种
- 立即查询
- 延迟加载
- 类级别延迟加载
- 关联级别延迟加载
3.5.1:立即查询
@Test
public void get(){
//调用get方法,根据id查询,执行完这个方法后会立马发送sql
Customer customer = session.get(Customer.class, 1);
System.out.println(customer);
}
3.5.2:延迟加载
(1)类级别延迟加载
@Test
public void load(){
//得到对象里面不是id的其他值,才会发送语句
Customer customer = session.load(Customer.class, 1);//执行完不会发送sql
System.out.println(customer.getCid());//执行完不会发送sql,只会返回id
System.out.println(customer.getCname());//执行完会发送sql,并且返回getCname()的值
}
(2)关联级别延迟加载(了解)
@Test
public void associationLevel() {
//查询某个客户根据客户查询联系人,查询客户的所有联系人这个过程是否需要延迟,这个过程称为关联级别延迟
Customer customer = session.get(Customer.class, 1); //会发送sql
Set<LinkMan> linkMans = customer.getLinkMans(); //不会发送sql
System.out.println(linkMans.size());//会发送sql
}
(3)关联级别延迟操作,在映射文件中进行配置实现,根据客户得到所有联系人,所以在客户映射文件中配置!
默认就是fetch=“select”, lazy=true
lazy属性有三种取值:false(不延迟),true(延迟,也是默认),extra(额外延迟)
<set name="linkMans" fetch="select" lazy="true">
(4)演示不延迟的代码
<set name="linkMans" fetch="select" lazy="false">
@Test
public void associationLevel() {
Customer customer = session.get(Customer.class, 1); //会发送sql,不管你现在需不需要
Set<LinkMan> linkMans = customer.getLinkMans();//不会发送sql
System.out.println(linkMans.size());//不会发送sql
}
(5)演示额外延迟的代码
<set name="linkMans" fetch="select" lazy="extra">
@Test
public void associationLevel() {
Customer customer = session.get(Customer.class, 1); //会发送sql
Set<LinkMan> linkMans = customer.getLinkMans();
//因为这里你只需要数量,只发送一条select count(*) from t_linkMan
System.out.println(linkMans.size());
}
3.6:批量抓取
需求:查询所有客户,并根据每个客户查询对应的所有联系人
@Test
public void batchFetching() {
//查询所有客户
Query query = session.createQuery("from Customer");
List<Customer> customers = query.list();
for (Customer customer : customers) {
System.out.println(customer.getCid()+"::"+customer.getCname());
//使用对象导航的方式
Set<LinkMan> linkMans = customer.getLinkMans();
for (LinkMan linkMan : linkMans) {
System.out.println(linkMan.getName());
}
}
}
但是上面发送的sql会比较多,导致效率和性能可能不是很好。怎么解决呢?
在在客户的映射文件中,set标签配置batch-size,值越大,发送的sql越少!
<set name="linkMans" batch-size="10">
最后来自:虽然帅,但是菜的cxf,创作不易,转载注明出处,谢谢
想要代码的小伙伴,可能去网盘自己下载!!
链接:https://pan.baidu.com/s/1mInpzUDz4yRur7efbGf_3g
提取码:lrgq















 5215
5215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









