







1、select(选择)
select * from 表名;
select distinct 列名 from 表名; //distinct 去重
select top number 列名 from 表名;
select top percentage 列名 from 表名;
select 列名 from 表名 limit 数字;
select min(列名) from 表名;
select max(列名) from 表名;
2、where(筛选)
select 列名1, 列名2, ... from 表名 where 条件;
select 列名1, 列名2, ... from 表名 where 列名 like 名;
where 列名 in (...);
where 列名 between 值1 and 值2;
条件操作符:=, >, <, >=, <=, between, like, in, and, or, not
3、order by(排序)
select 列名, 列名, ... from 表名 order by 列名, 列名, ... asc/desc;
4、insert into(插入行)
insert into 表名 (列名1, 列名2, 列名3, ...) values (值1, 值2, 值3, ...);
insert into 表名 values (值1, 值2, 值3, ...);
5、update(修改)
update 表名 set 列名1=值1, 列名2=值2, ... where 条件;
6、delete(删除)
delete from 表名 where 条件;
where语句是可选的,不选则为删除所有
7、join
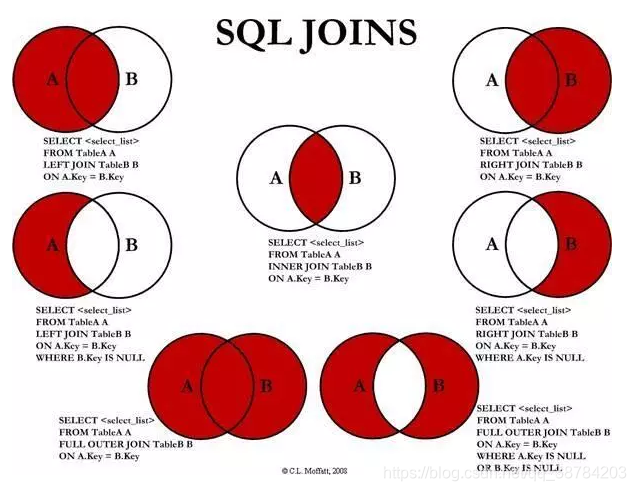
8、self join(通常用于同一个表不同行之间的关系)
select 列名 from 表名1 tb_1, 表名2 tb_2 where 条件;
9、union(用于合并两个或多个 SELECT 语句的结果集,默认去重,不去重用union all)
select 列名 from 表名1 union select 列名 from 表名2;
10、group by(根据一个或多个列对结果集进行分组)
select count(列名1), 列名2 from 表名 group by 列名2;
11、.having:having和where均引导条件语句,但是区别是having是:在查询返回结果集以后对查询结果进行的过滤操作,支持聚合操作(avg,count等),where约束来自数据库的数据
# 筛选平均工资高于3000的部门
select deparment, avg(salary) as average from salary_info group by deparment having average > 3000
12、null的处理
#eg:ifnull是mysql的用法,对应还有isnull(sql server)
select 列名1 * ifnull(列名2, 0) from 表名
















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











