







VTimeLLM介绍
文章链接 https://arxiv.org/abs/2311.18445
VTimeLLM是一个识别视频中,事件发生事件的大模型
文章的创新点分三部分:
1,使用图片数据集训练clip到大模型的全连接层,使得clip提取的特征和大模型的输入对齐。
2,使用 InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation 提供的数据集和部分其他数据集训练LoRA,使得大模型能捕捉事件。
3,使用精选(?)的数据集训练一个LoRA,使得大模型可以回答除事件外的其他问题(我的理解是,降低 创新点2 中的过拟合现象)。
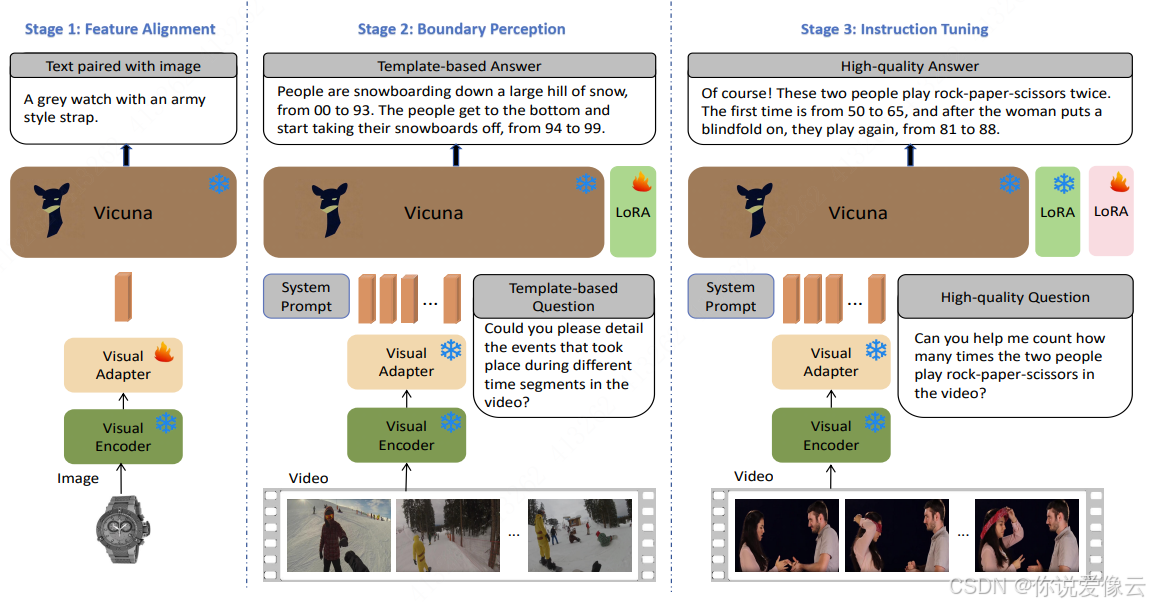
论文复现
本人是大模型新手,近期打算发表一个视频大模型相关的文章,于是在公司服务器上从头复现文章折腾中。
代码的 github https://github.com/huangb23/VTimeLLM
1,环境安装
1,cuda版本
nvcc --version
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









