









 本文介绍了如何在已搭建的Hadoop伪分布集群上安装配置Flume,包括环境变量设置、flume-env.sh文件修改,以及Avro和Spooling Directory Source的使用示例,展示了如何监听端口、监控目录并将数据传输到HDFS。
本文介绍了如何在已搭建的Hadoop伪分布集群上安装配置Flume,包括环境变量设置、flume-env.sh文件修改,以及Avro和Spooling Directory Source的使用示例,展示了如何监听端口、监控目录并将数据传输到HDFS。
1.准备工作
在Flume的安装及简单的使用(一) 的基础上系统环境之上添加hadoop-2.7.3 ,并创建hadoop伪分布集群并创建。
hadoop伪分布集群的搭建,请参考:http://blog.csdn.net/qq_38799155/article/details/77748831
2.配置 Flume环境变量
在hadoop用户下配置:
$ vi .bashrc添加如下内容
export FLUME_HOME=/home/hadoop/flume
export PATH=$PATH:$FLUME_HOME/bin之后source一下,使其生效
$ source .bashrc3.修改配置flume-env.sh文件
$ cd /home/hadoop/flume/conf
$ cp flume-env.sh.template flume-env.sh
$ vi flume-env.sh添加如下内容
export JAVA_HOME=/usr/java/jdk1.8.0_121
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3如图所示:

验证版本信息
$ flume-ng version如图所示:

4.Flume部署示例
4.1 Avro
Flume可以通过Avro监听某个端口并捕获传输的数据,具体示例如下:
//创建一个Flume配置文件
$ cd /home/hadoop/flume/
$ mkdir example
$ cp conf/flume-conf.properties.template example/netcat.conf进入到/home/hadoop/flume/example/ 下的netcat.conf 文件进行修改
$ cd /home/hadoop/flume/example/
$ vi netcat.conf修改如下( 配置netcat.conf用于实时获取另一终端输入的数据):
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel that buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1运行FlumeAgent,监听本机的44444端口
flume-ng agent -c conf -f netcat.conf -n a1 -Dflume.root.logger=INFO,console效果如图所示:

打开另一终端,通过telnet登录localhost的44444,输入测试数据
$ telnet localhost 44444如图所示,证明启动成功

查看flume收集数据情况

4.2 Spool
Spool用于监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点:拷贝到spool目录下的文件不可以再打开编辑、spool目录下不可包含相应的子目录。具体示例如下:
1.创建两个Flume配置文件
$ cd /home/hadoop/flume/
$ cp conf/flume-conf.properties.template example/spool1.conf
$ cp conf/flume-conf.properties.template example/spool2.conf2.配置spool1.conf用于监控目录avro_data的文件,将文件内容发送到本地60000端口
$ cd /home/hadoop/flume/example/
$ vi spool1.conf修改内容如下
# Namethe components
local1.sources= r1
local1.sinks= k1
local1.channels= c1
# Source
local1.sources.r1.type= spooldir
local1.sources.r1.spoolDir= /home/hadoop/avro_data
# Sink
local1.sinks.k1.type= avro
local1.sinks.k1.hostname= localhost
local1.sinks.k1.port= 60000
#Channel
local1.channels.c1.type= memory
# Bindthe source and sink to the channel
local1.sources.r1.channels= c1
local1.sinks.k1.channel= c13.配置spool2.conf用于从本地60000端口获取数据并写入HDFS
$ cd /home/hadoop/flume/example/
$ vi spool2.conf修改内容如下
# Namethe components
a1.sources= r1
a1.sinks= k1
a1.channels= c1
# Source
a1.sources.r1.type= avro
a1.sources.r1.channels= c1
a1.sources.r1.bind= localhost
a1.sources.r1.port= 60000
# Sink
a1.sinks.k1.type= hdfs
a1.sinks.k1.hdfs.path= hdfs://hadoop:9000/home/hadoop/hadoop-2.7.3/flumeData
a1.sinks.k1.rollInterval= 0
a1.sinks.k1.hdfs.writeFormat= Text
a1.sinks.k1.hdfs.fileType= DataStream
# Channel
a1.channels.c1.type= memory
a1.channels.c1.capacity= 10000
# Bind the source and sink to the channel
a1.sources.r1.channels= c1
a1.sinks.k1.channel= c14.分别打开两个终端,运行如下命令启动两个Flume Agent
都在/home/hadoop/flume/example/ 运行
$ flume-ng agent -c conf -f spool2.conf -n a1
$ flume-ng agent -c conf -f spool1.conf -n local15.查看本地文件系统中需要监控的avro_data目录内容
在hadoop用户的根目录下创建avro_data文件夹
$ cd /home/hadoop/
$ mkdir avro_data
$ cd avro_data
$ vi avro_data.txt添加内容如下(内容随便写):
1,first_name,age,address
2,James,55,6649 N Blue Gum St
3,Art,62,8 W Cerritos Ave #54
4,Lenna,56,639 Main St
5,Donette,2,34 Center St
6,YuKi,35,1 State Route 27
7,Ammy,28,322 New Horizon Blvd
8,Abel,26,37275 SSt Rt 17m M
9,Leota,52,7 W Jackson Blvd
10,Kris,36,228 Runamuck P1 #2808
11,Kiley,32,25 E 75th St #69
12,Simona,32,3 Mcauley Dr
13,Sage,25,5 Boston Ave #88
14,Mitsue,23,7 Eads St
15,Mattile, 12,73 State Road 434 E
之后
$ cd /home/hadoop/avro_data/
$ cat avro_data.txt如图所示:

6.查看写HDFS的Agent,检查是否捕获了数据别写入HDFS

17/09/19 02:37:15 INFO hdfs.BucketWriter: Creating hdfs://hadoop:9000/home/hadoop/hadoop-2.7.3/flumeData/FlumeData.1505759834441.tmp
17/09/19 02:37:20 INFO hdfs.BucketWriter: Closing hdfs://hadoop:9000/home/hadoop/hadoop-2.7.3/flumeData/FlumeData.1505759834441.tmp
17/09/19 02:37:20 INFO hdfs.BucketWriter: Renaming hdfs://hadoop:9000/home/hadoop/hadoop-2.7.3/flumeData/FlumeData.1505759834441.tmp to hdfs://hadoop:9000/home/hadoop/hadoop-2.7.3/flumeData/FlumeData.1505759834441
17/09/19 02:37:20 INFO hdfs.BucketWriter: Creating hdfs://hadoop:9000/home/hadoop/hadoop-2.7.3/flumeData/FlumeData.1505759834442.tmp
17/09/19 02:37:50 INFO hdfs.BucketWriter: Closing hdfs://hadoop:9000/home/hadoop/hadoop-2.7.3/flumeData/FlumeData.1505759834442.tmp
17/09/19 02:37:50 INFO hdfs.BucketWriter: Renaming hdfs://hadoop:9000/home/hadoop/hadoop-2.7.3/flumeData/FlumeData.1505759834442.tmp to hdfs://hadoop:9000/home/hadoop/hadoop-2.7.3/flumeData/FlumeData.1505759834442
7.通过WEB UI查看HDFS中的文件

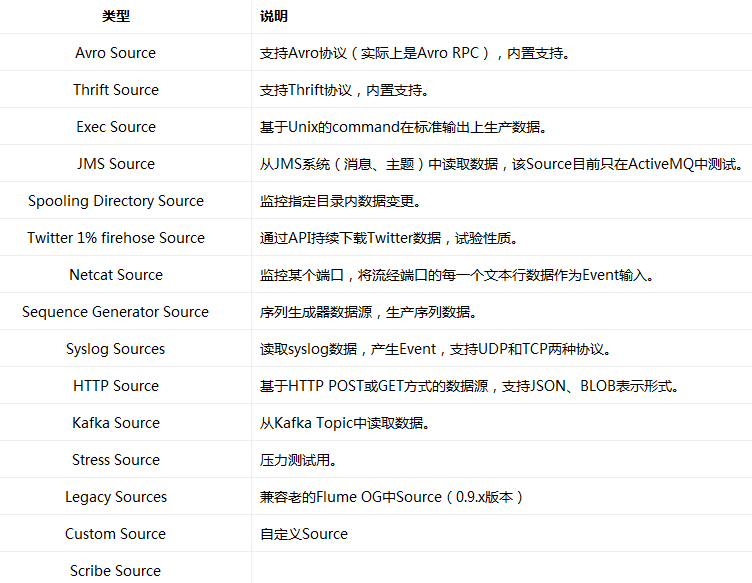
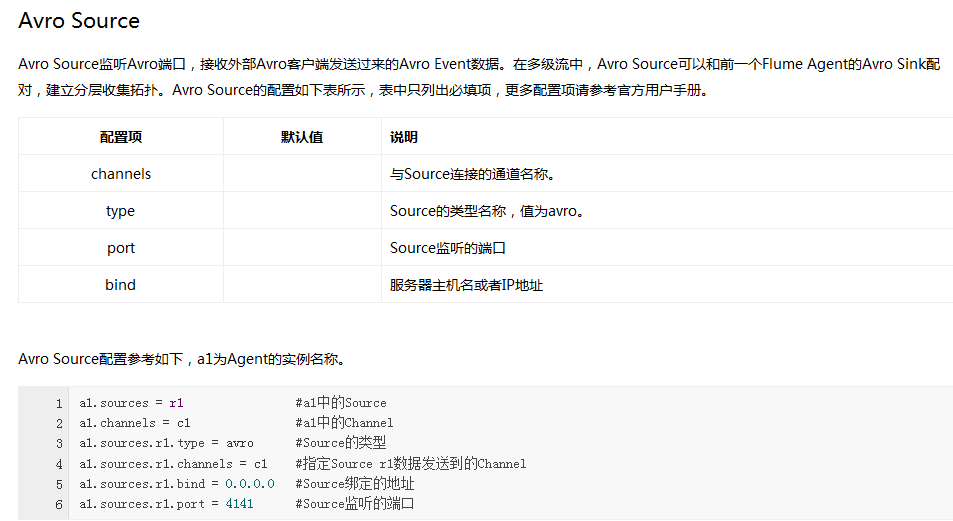
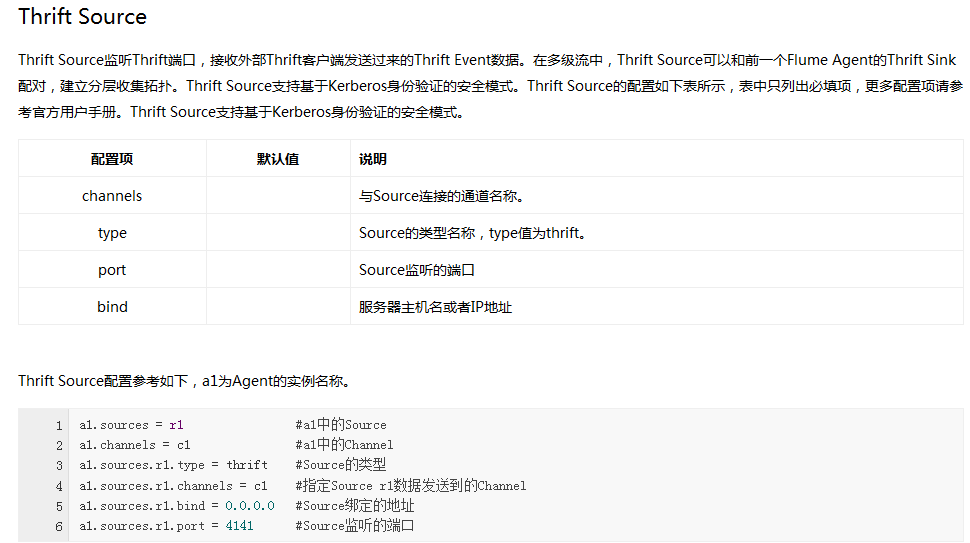
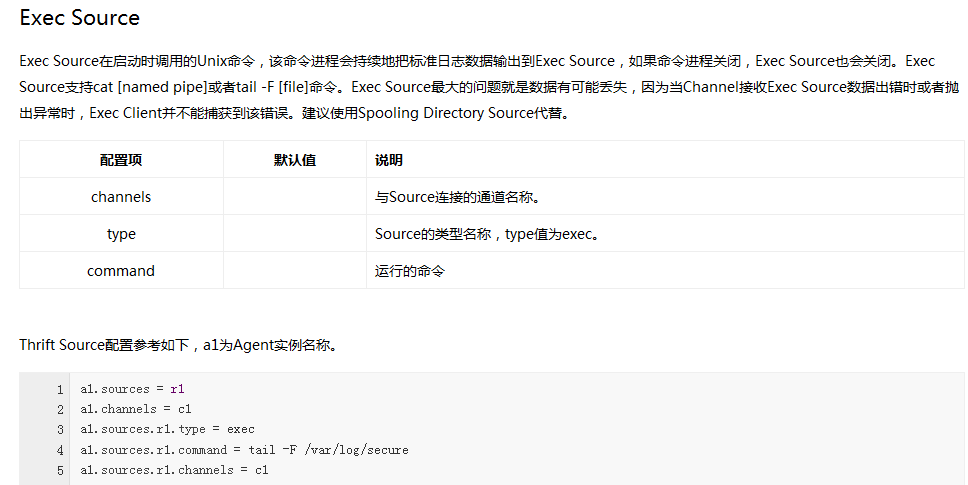
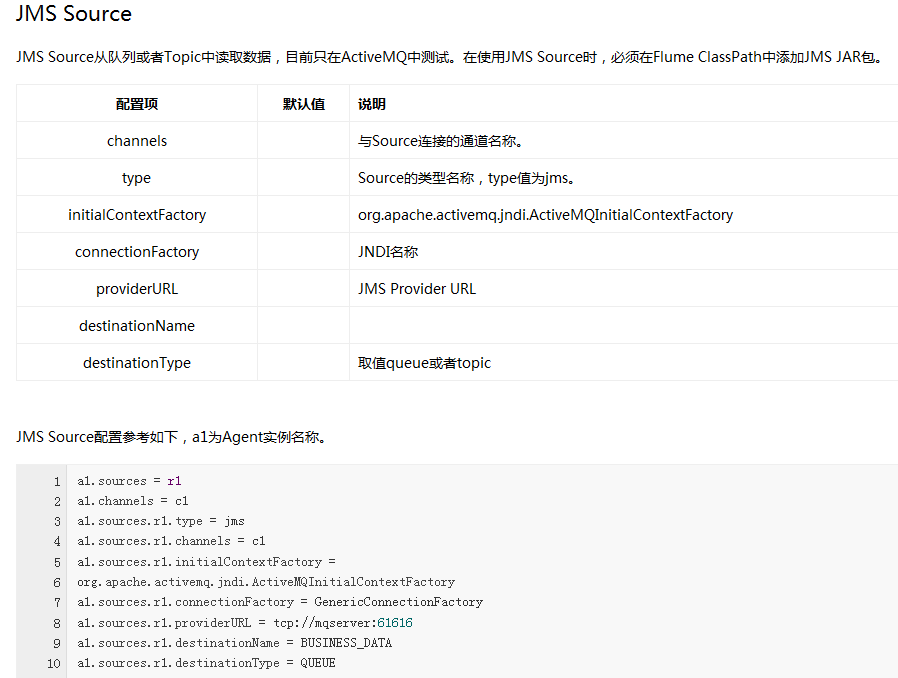
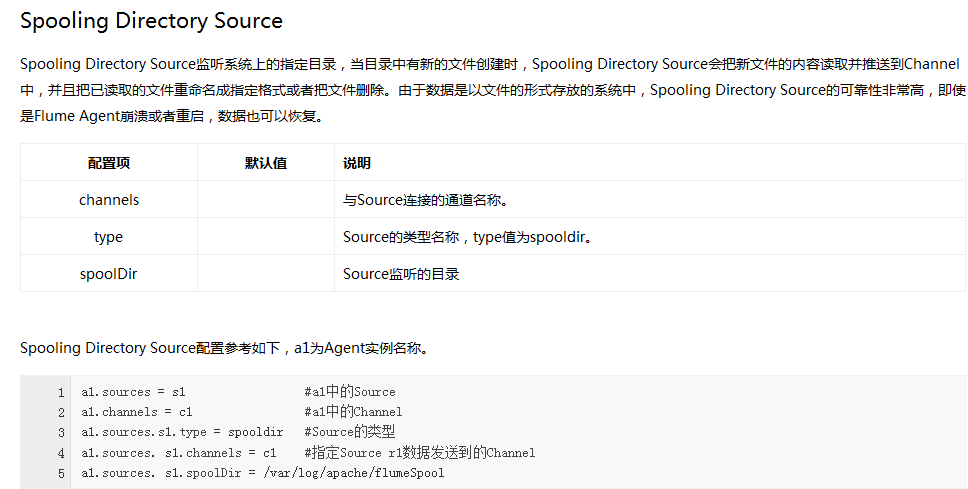
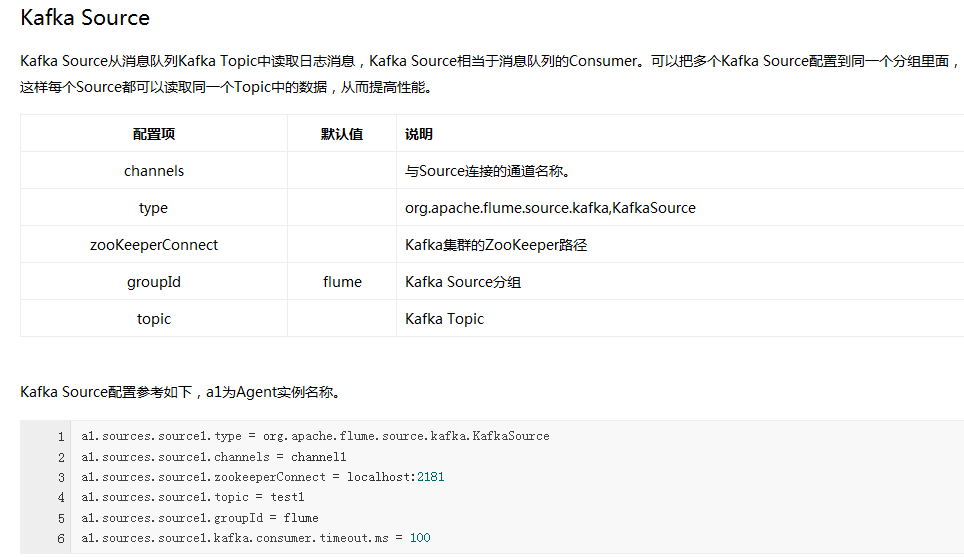
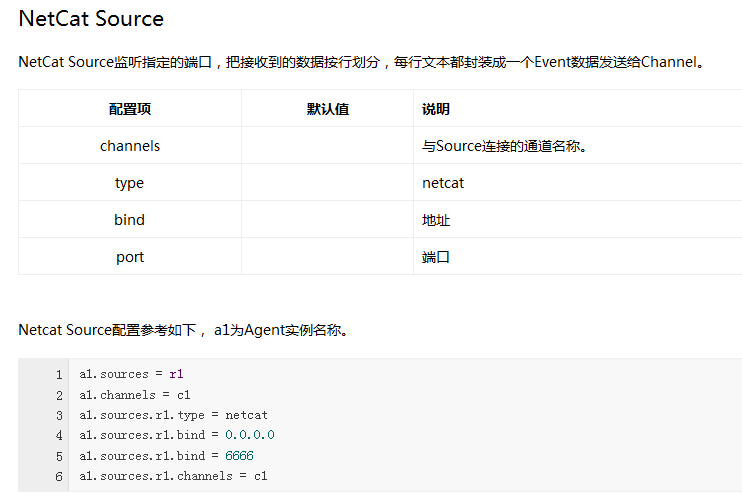
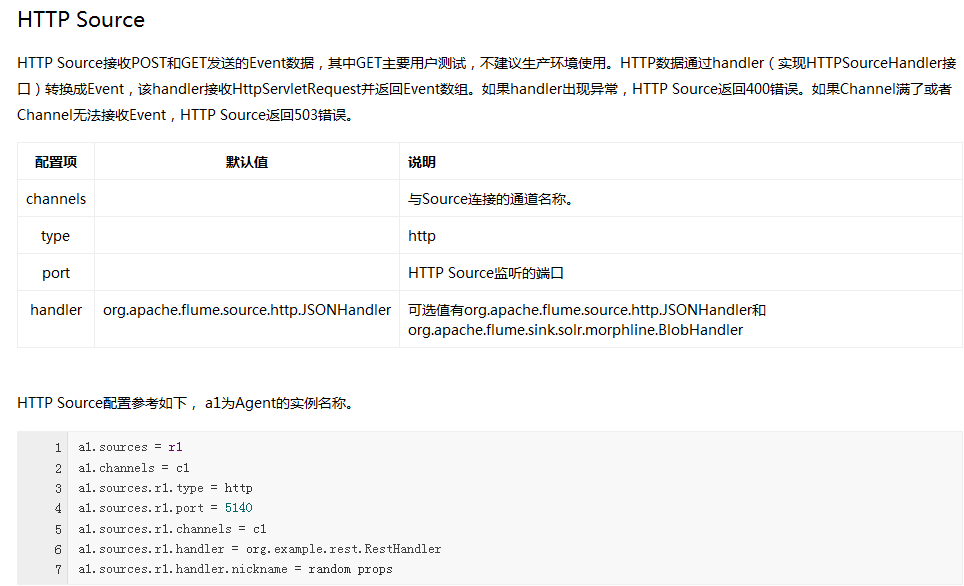
Flume内置了大量的Source,其中Avro Source、Thrift Source、Spooling Directory Source、Kafka Source具有较好的性能和较广泛的使用场景。下面是Source的一些参考资料:















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









