







目录
浏览器的组成
1.User Interface(用户界面)-包括地址栏、后退/前进按钮、书签目录等,也就是你-所看到的除了页面显示窗口之外的其他部分
2.Browser engine(浏览器引擎)-可以在用户界面和渲染引擎之间传送指令或在客户端本地缓存中读写数据等,是浏览器中各个部分之间相互通信的核心
3.Rendering engine(渲染引擎)-解析DOM文档和CSS规则并将内容排版到浏览器中显示有样式的界面,也有人称之为排版引擎,我们常说的浏览器内核主要指的就是渲染引擎
4.Networking(网络)-用来完成网络调用或资源下载的模块
5.UI Backend(UI 后端)-用来绘制基本的浏览器窗口内控件,如输入框、按钮、单选按钮等,根据浏览器不同绘制的视觉效果也不同,但功能都是一样的。
6.JavaScript Interpreter(js解释器)-用来解释执行JS脚本的模块,如 V8 引擎、JavaScriptCore
7.Date Persistence(数据持久化存储)-浏览器在硬盘中保存 cookie、localStorage等各种数据,可通过浏览器引擎提供的API进行调用

从结构上区分,浏览器包含浏览器内核和浏览器的外壳(shell)。浏览器核心——内核分成两部分:渲染引擎和js引擎。由于js引擎越来越独立,内核就倾向于只指渲染引擎。
渲染引擎:在维基百科上是这样介绍浏览器内核的,网页浏览器的排版引擎(Layout Engine或Rendering Engine)也被称为浏览器内核、页面渲染引擎、解释引擎或模板引擎,它负责取得网页的内容(HTML、XML、图像等等)、整理消息(例如加入CSS等),以及计算网页的显示方式,然后会输出至显示器或打印机。所有网页浏览器、电子邮件客户端以及其它需要根据表示性的标记语言(Presentational markup)来显示内容的应用程序都需要排版引擎
javascript引擎:JS引擎负责解析Javascript语言,执行javascript语言来实现网页的动态效果。2008 年 Google 发布最新浏览器 Chrome,它是采用优化后的 javascript 引擎,引擎代号 V8,因能把 js 代码直接转化为机械码来执行,进而以速度快而闻名。在运行JavaScript之前,相比其它的JavaScript的引擎转换成字节码或解释执行。
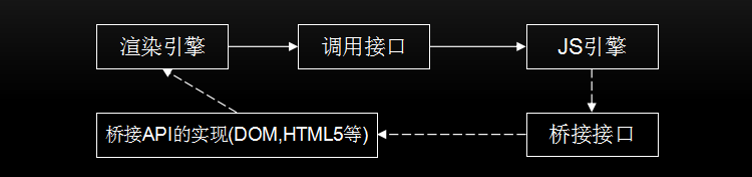
JavaScript本质上是一种解释型语言,与编译型语言不同的是它需要一遍执行一边解析,而编译型语言在执行时已经完成编译,可直接执行,有更快的执行速度(如上图所示)。JavaScript代码是在浏览器端解析和执行的,如果需要时间太长,会影响用户体验。那么提高JavaScript的解析速度就是当务之急。JavaScript引擎和渲染引擎的关系如下图所示:
预编译
Js执行三步:1 语法分析 → 2 预编译 → 3 解释执行
预编译:分为全局预编译和函数预编译两种。
全局预编译:
1、生成了一个 GO 的对象 Global Object( window 就是 GO)
2、找形参和变量声明,将变量和形参名作为 GO 属性名,值为 undefined
3、在函数体里面找函数声明,值赋予函数体
函数预编译:
1.创建 AO 对象 Activation Object(执行期上下文,作用是理解的作用域,函数产生
的执行空间库)
2.找形参和变量声明,将变量和形参名作为 AO 属性名,值为 undefined
3.将实参值和形参统一(把实参值传到形参里)
4.在函数体里面找函数声明,值赋予函数体
(先看自己的 AO,再看全局的 GO)
案例:
console.log(test);
function test(test){ //此处test命名为t1
console.log(test);
var test = 234;
console.log(test);
function test(){} //此处test命名为t2
console.log(a)
}
test(1);
var test = 123;
var a = 1
/**
打印结果如下:
ƒ test(test){ //此处test命名为t1
console.log(test);
var test = 234;
console.log(test);
function test(){} //此处test命名为t2
console.log(a)
}
index.js:3 ƒ test(){}
index.js:5 234
index.js:7 undefined
*/
/**
* 执行全过程分析:
*
* 1.GO预编译:
*
第一步:{} //生成 Global Object
第二步:{test:undefined,a:undefined}
第三步:{test:function,a:undefined}
2.执行console.log(test)
打印结果为:function test(test){
console.log(test);
var test = 234;
console.log(test);
function test(){}
console.log(a)
}
3.执行test(1),并开始test函数的预编译:
第一步:{} //生成Activation Object,函数的作用域对象
第二步:{test:undefined}
第三步:{test:1}
第四步:{test:function}
4.执行t1函数代码:
⑴console.log(test)
打印结果:function
⑵testAO: {test:234} //赋值
⑶console.log(test)
打印结果:234
⑷console.log(a)
打印结果:undefined
5.执行var test = 123; //此时GO:{test:123,a:undefined}
6.执行var a = 1; //此时GO:{test:123,a:1}
*/
事件循环
javascript是一门单线程语言,最初设计JS是用来在浏览器验证表单操控DOM元素的是一门脚本语言,如果js是多线程的,那么两个线程同时对一个DOM元素进行了相互冲突的操作,那么浏览器的解析器是无法执行的。
执行栈:call stack,一个数据结构,用于存放各种函数的执行环境,每一个函数执行之前,它的相关信息会加入到执行栈。函数调用之前,创建执行环境,然后加入到执行栈;函数调用之后,销毁执行环境。
JS引擎永远执行的是执行栈的最顶部。
异步函数:某些函数不会立即执行,需要等到某个时机到达后才会执行,这样的函数称之为异步函数。比如事件处理函数。异步函数的执行时机,会被宿主环境控制。如果js中不存在异步,只能自上而下执行,如果上一行解析时间很长,那么下面的代码就会被阻塞。 对于用户而言,阻塞就以为着“卡死”,这样就导致了很差的用户体验。比如在进行ajax请求的时候如果没有返回数据后面的代码就没办法执行
浏览器宿主环境中包含5个线程:
1. JS引擎:负责执行执行栈的最顶部代码
2. GUI线程:负责渲染页面 (与js引擎互斥)
3. 事件监听线程:负责监听各种事件
4. 计时线程:负责计时
5. 网络线程:负责网络通信
JS的事件循环(eventloop)是怎么运作的?
事件循环、eventloop\运行机制 这三个术语其实说的是同一个东西。
先执行同步操作异步操作排在事件队列里”这样的理解其实也没有任何问题但如果深入的话会引出很多其他概念,比如event table和event queue, 我们来看运行过程:
1.首先判断JS是同步还是异步,同步就进入主线程运行,异步就进入event table.
2.异步任务在event table中注册事件,当满足触发条件后,(触发条件可能是延时也可能是ajax回调),被推入event queue
3.同步任务进入主线程后一直执行,直到主线程空闲时,才会去event queue中查看是否有可执行的异步任务,如果有就推入主线程中。

在浏览器中,事件队列分为两种:
- 宏任务(队列):
macroTask,计时器结束的回调、事件回调、http回调等等绝大部分异步函数进入宏队列
- 微任务(队列):
MutationObserver,Promise产生的回调进入微队列

事件循环过程全览

案例:
setTimeout(function(){
console.log(1)
},0);
console.log(2)
function f(){
console.log(3)
}
f()
// 打印结果:2 3 1
// 分析:setTimeout的回调函数属于异步任务,进入异步队列,console.log(2)和f()是同步任务放入同步队列优先执行
setTimeout(function(){
console.log('1')
},0);
new Promise(function(resolve){
console.log('2');
resolve();
}).then(function(){
console.log('3')
});
console.log('4');
// 打印结果:2 4 3 1
// 分析:new Promise中执行的console.log(2)和console.log("4")属于同步任务.
// setTimeout的回调函数和Promise的回调then函数是属于异步任务,而then属于微任务,setTimeout的回调函数是宏任务,根据先执行微任务后执行宏任务的顺序,因此先后输出3 1尾调用
什么是尾调用?
尾调用( Tail Call) 是函数式编程的一个重要概念, 本身非常简单, 一句话就能说清楚, 就是指某个函数的最后一步是调用另一个函数。
function fn(x){
return gn(x);
}
// 上面代码中, 函数 fn 的最后一步是调用函数 gn , 这就叫尾调用。以下三种情况, 都不属于尾调用。
// 情况一
function fn(x){
const y = gn(x)
return y
}
// 情况二
function fn(x){
return gn(x) ++
}
// 情况三
function fn(x){
gn(x)
}尾递归
函数调用自身, 称为递归。 如果尾调用自身, 就称为尾递归。
递归非常耗费内存, 因为需要同时保存成千上百个调用帧, 很容易发生“栈溢出”错
误( stack overflow) 。 但对于尾递归来说, 由于只存在一个调用帧, 所以永远不会
发生“栈溢出”错误。
function Fibonacci (n) {
if ( n <= 1 ) {return 1};
return Fibonacci(n - 1) + Fibonacci(n - 2);
}
Fibonacci(10) // 89
Fibonacci(100) // 堆栈溢出
Fibonacci(500) // 堆栈溢出尾递归(尾调用)优化
尾调用之所以与其他调用不同, 就在于它的特殊的调用位置。我们知道, 函数调用会在内存形成一个“调用记录”, 又称“调用帧”( call frame) ,保存调用位置和内部变量等信息。 如果在函数 A 的内部调用函数 B , 那么在 A 的调用帧上方, 还会形成一个 B 的调用帧。 等到 B 运行结束, 将结果返回到 A , B 的调用帧才会消失。 如果函数 B 内部还调用函数 C , 那就还有一个 C 的调用帧, 以此类推。 所有的调用帧, 就形成一个“调用栈”( call stack) 。尾调用由于是函数的最后一步操作, 所以不需要保留外层函数的调用帧, 因为调用位置、 内部变量等信息都不会再用到了, 只要直接用内层函数的调用帧, 取代外层函数的调用帧就可以了。
function Fibonacci2 (n , ac1 = 1 , ac2 = 1) {
if( n <= 1 ) {return ac2};
return Fibonacci2 (n - 1, ac2, ac1 + ac2);
}
Fibonacci2(100) // 573147844013817200000
Fibonacci2(1000) // 7.0330367711422765e+208
Fibonacci2(10000) // Infinity















 121
121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









