






第一部分 使用总结
基本语法 不区分大小写,表名带不带双引号
一些顺序:select from where groupby having orderby limit
技巧总结
- 一般要输出哪列,就select哪列。
- 使用where 还是分组要分清
一、检索数据
-
检索列(单个/多个/所有)
select 列名/列名,列名,.../ * from 表名; -
检索不同行
select distinct 列名/列名,列名,.../ * from 表名;【注】:应用于所有列而不仅是前置它的列。
-
限制结果
select 列名/列名,列名,.../ * from 表名 limit 开始行(0是第一行),检索行数;【注】:不够检索行数 返回应该返回的行
limit y offset x 分句表示查询结果跳过 x 条数据,读取前 y 条数据 如:limit 1,1
二、排序检索数据
-
排序数据(按单列/多列)
select 列名/列名,列名,.../ * from 表名 order by 列名/列名,列名;【注】:按多列排序例子:首先按姓排序,然后在每个姓中再按名排序
-
按指定方向排序
select 列名/列名,列名,.../ * from 表名 order by 列名 desc;/列名 desc,列名 desc;【注】:DESC关键字只应用到直接位于其前面的列名
三、过滤数据
-
检查单个值
select 列名/列名,列名,.../ * from 表名 where 列名 = /< / > 值; -
不匹配检查
select 列名/列名,列名,.../ * from 表名 where 列名 != 值;【注】:或者将!= 换成<>
-
范围值检查
select 列名/列名,列名,.../ * from 表名 where 列名 between 值 and 值; -
空值检查
select 列名/列名,列名,.../ * from 表名 where 列名 is null;
四、高级数据过滤
-
结合多列进行数据过滤
select 列名/列名,列名,.../ * from 表名 where (条件一 and 条件二) or 条件三; -
对一些点过滤
select 列名/列名,列名,.../ * from 表名 where 列名 in (值1,值2,...); -
对条件的否定
select 列名/列名,列名,.../ * from 表名 where 列名 not in (值1,值2,...);
五、使用通配符过滤
-
%匹配任何字符出现任意次数,_匹配任何字符出现单次
select 列名/列名,列名,.../ * from 表名 where 列名 like '%字符串_';【注】:似乎%通配符可以匹配任何东西,但有一个例外,即NULL
六、正则表达式
. 匹配任意一个字符
[字符字符字符] 匹配单一字符之一,是[字符|字符|字符]的缩写,反[ ^字符字符字符]
[1-5]匹配范围
\ \ 特殊字符 匹配特殊字符
[:alnum:] [:alpha:] 任意字母和数字(同[a-zA-Z0-9]) 任意字符(同[a-zA-Z])
匹配多个:

匹配特定位置文本:

七、创建计算字段
我们需要直接从数据库中检索出转换、计算或格式化过的数据;而不是检索出数据,然后再在客户机应用程序或报告程序中重新格式化
这就是计算字段发挥作用的所在了。与前面各章介绍过的列不同,计算字段并不实际存在于数据库表中。计算字段是运行时在SELECT语句内创建的。
-
拼接字段, 起别名
select concat(列名,其他符号,列名) as 别名 from 表名 where 列名 in (值1,值2,...);【注】:删除空格函数 Rtrim,Ltrim()
-
执行算数计算
select 列名 +-*/ 列名 as 别名 from 表名 where 列名 in (值1,值2,...);
八、使用函数处理数据
-
文本处理函数


-
日期和时间处理函数

-
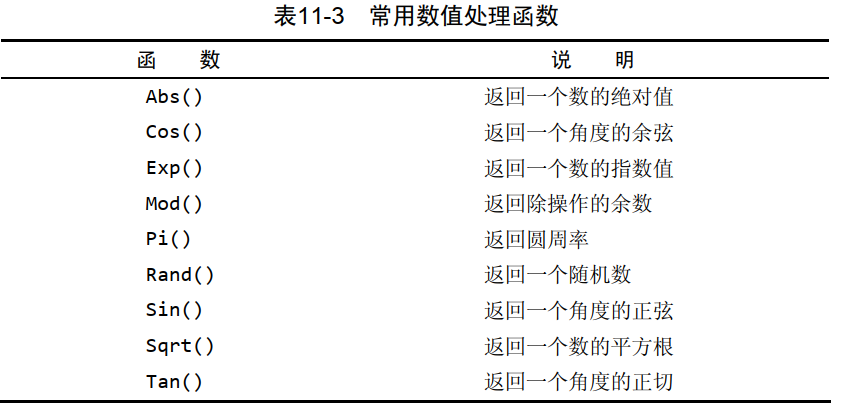
数值处理函数
九、汇总数据
-
聚集函数
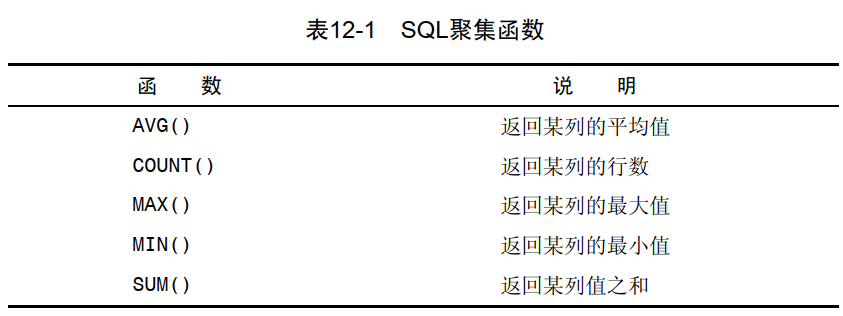
【注】:
- 使用COUNT(*)对表中行的数目进行计数, 不管表列中包含的是空值( NULL)还是非空值。
- 使用COUNT(column)对特定列中具有值的行进行计数,忽略NULL值。
-
聚集不同值
select 函数(distinct 列名) as 别名 from 表名 where 列名 in (值1,值2,...); -
组合聚集函数
select 函数(distinct 列名) as 别名, 函数(列名)as 别名, ... from 表名 where 列名 in (值1,值2,...);
十、分组函数
分组允许把数据分为多个逻辑组,以便能对每个组进行聚集计算
-
创建分组:
select 列名/列名,列名,.../ * ,函数() as 别名 from 表名 group by 列名;【注】 GROUP BY子句指示MySQL按vend_id排序并分组数据。 它有一些重要规定:
- GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。
- GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外, SELECT语句中的每个列都必须在GROUP BY子句中给出。
- 如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后, ORDER BY子句之前。
-
过滤分组:
目前为止所学过的所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是WHERE过滤行,而HAVING过滤分组。
select 列名/列名,列名,.../ * ,函数() as 别名 from 表名 group by 列名 having 函数()条件语句; -
分组和排序:
一般在使用GROUP BY子句时,应该也给出ORDER BY子句。这是保证数据正确排序的唯一方法。千万不要仅依赖GROUP BY排序数据 。
十一、使用子查询
子查询( subquery) ,即嵌套在其他查询中的查询。
-
利用子查询进行过滤
分步检索,利用返回值进行下一步检索
select 列名/列名,列名,.../ * from 表名 where 列名 in (select 列名/列名,列名,.../ * from 表名 where 列名 in (select 列名/列名,列名,.../ * from 表名 where 条件));例子
select cust_email from `Customers` where cust_id in ( select cust_id from `Orders` where order_num in ( select order_num from `OrderItems` where prod_id = "BR01" ) ) -
作为计算字段使用子查询
select 列名/列名,列名,.../ * ,(select 列名/列名,列名,.../ * from ’另一个表名‘ where 表名.列 = 另一个表名.列) from 表名
十二、联结表
主键:每一行的唯一的标识
外键为某个表中的一列,它包含另一个表的主键值,定义了两个表之间的关系。
-
创建联结
select 列名/列名,列名,.../ * from 表名1,表名2,... where 表名1.列名 = 表名2.列名 -
内部联结(等值联结)
select 列名/列名,列名,.../ * from 表名1 inner join 表名2 on 表名1.列名 = 表名2.列名【注】:SQL_ERROR_INFO: "Column ‘order_num’ in field list is ambiguous"问题
列’ID’在字段列表中重复,其实就是两张表有相同的字段,但是使用时表字段的名称前没有加表名,导致指代不明
-
联结多个表
select 列名/列名,列名,.../ * from 表名1,表名2,... where 表名1.列名 = 表名2.列名 and 表名2.列名 = 表名3.列名
十三、创建高级联结
-
使用表别名:简化书写,通常别名一个字母
select 列名/列名,列名,.../ * from 表名1 as 别名1, 表名2as 别名2... where 别名1.列名 = 别名2.列名 and 别名2.列名 = 别名3.列名 -
自联结:查询中需要的两个表实际上是相同的表
-
自然联结:事实上,迄今为止我们建立的每个内部联结都是自然联结,很可能我们永远都不会用到不是自然联结的内部联结。
-
外部联结:
与内部联结关联两个表中的行不同的是,外部联结还包括没有关联行的行。
在使用OUTER JOIN语法时,必须使用RIGHT或LEFT关键字指定包括其所有行的表( RIGHT指出的是OUTER JOIN右边的表,而LEFT指出的是OUTER JOIN左边的表)。
使用LEFT OUTER JOIN从FROM子句的左边表(customers表)中选择所有行,右边表中行可以为空。
select 列名/列名,列名,.../ * from 表名1 left join 表名2 on 表名1.列名 = 表名2.列名 -
带聚集函数的联结
十四、组合查询
-
使用union
select 函数(distinct 列名) as 别名 from 表名 where 列名 in (值1,值2,...); union select 函数(distinct 列名) as 别名 from 表名 where 列名 in (值1,值2,...); -
union规则:
- UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔
- UNION中的每个查询必须包含相同的列、表达式或聚集函数
- UNION从查询结果集中自动去除了重复的行 ,UNION all 不除重复行
- SELECT语句的输出用ORDER BY子句排序。在用UNION组合查询时,只能使用一条ORDER BY子句
十五、case when
-
几种形式
-
简单case表达式:
case<表达式> when<值1> then <结果1> when<值2> then <结果2> ... else<结果n> end -
搜索case表达式
case when<条件1> then <结果1> when<条件2> then <结果2> ... else<结果n> end例:
select x, case when x<0 then x when x>0 then -1*x else 0 end as y from 表
-
十六、强大的窗口函数
Mysql8.0开始支持
<窗口函数> over([partition by <用于分组的列>]order by <用于排序的列>)
【注】:avg()等函数也可以以这种形式使用
-
四大排名函数:
- rank函数
- dense_rank函数
- row_number函数
- ntile函数
create table scores ( id number(6) ,score number(4,2) ); insert into scores values(1,3.50); insert into scores values(2,3.65); insert into scores values(3,4.00); insert into scores values(4,3.85); insert into scores values(5,4.00); insert into scores values(6,3.65); commit; select id ,score ,rank() over(order by score desc) rank --按照成绩排名,纯排名 ,dense_rank() over(order by score desc) dense_rank --按照成绩排名,相同成绩排名一致 ,row_number() over(order by score desc) row_number --按照成绩依次排名 ,ntile(3) over (order by score desc) ntile --按照分数划分3个成绩梯队 from scores;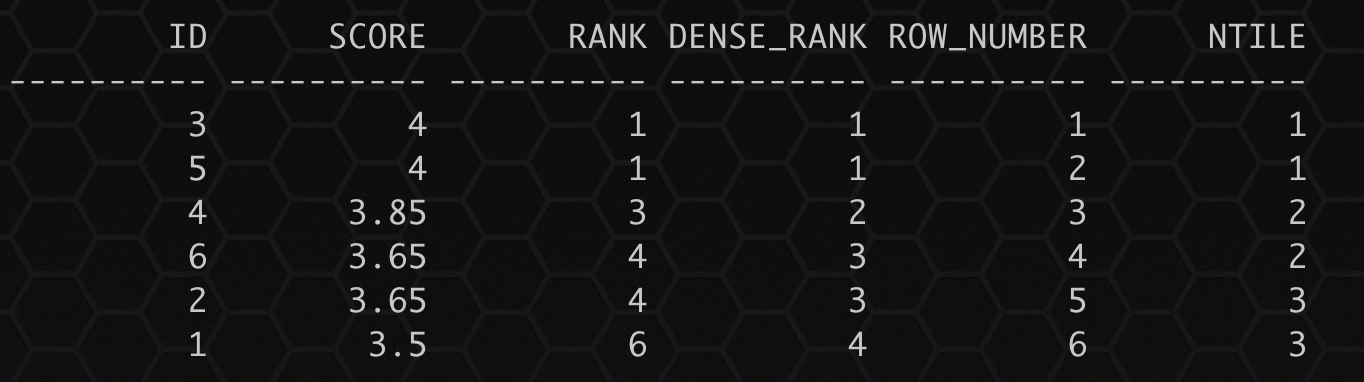
-
LAG():它提供对当前行之前的指定物理偏移量的行的访问。
-
LEAD()它提供对当前行之后的指定物理偏移量的行的访问。
第二部分 练习
牛客SQL必知必会题单:https://www.nowcoder.com/exam/oj/ta?tpId=298
sql面试50题:https://blog.csdn.net/qq_33043025/article/details/122073248
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









