







ELK简介
ELK是ElasticSearch Logstash Kibana三大开源框架首字母大写简称。市面上也称为Elastic Stack。Lostash是ELK的中央数据流,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地。Kibana可以将elastic的数据通过友好的页面展示出来,提供实时分析的功能。
市面上很多开发只要提到ELK能够一直说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其他任何数据分析和手机的场景,日志分析和收集知识更具有代表性。并非唯一性。
1 环境准备
1.1 ELK下载
ElasticSearch: https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
logstash: https://mirrors.huaweicloud.com/logstash/?C=N&O=D
可视化界面elasticsearch-head.https://github.com/mobz/elasticsearch-head
kibana: https://mirrors.huaweicloud.com/kibana/?C=N&O=D
ik分词器 https://github.com/medcl/elasticsearch-analysis-ik
注意:JDK必须是1.8版本以上
1.2 ElasticSearch
1.2.1 简介
Elasticsearch 是一个分布式的免费开源搜索和分析引擎,适用于包括文本 数字 地理空间 结构化和非结构化数据等在内的所有类型的数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。Elasticsearch 以其简单的 REST 风格 API 分布式特性 速度和可扩展性而闻名,是 Elastic Stack 的核心组件;
1.2.2 安装
注:安装ElasticSearch之前必须保证JDK1.8+安装完毕,并正确的配置好JDK环境变量,否则启动ElasticSearch失败。
- 下载windows版本,解压至目标目录


- 启动Es

点击bat启动程序可以看到以下日志内容

- 查看Es集群信息
注:Es默认自己也是一个集群
打开浏览器,在地址栏中输入Es本地服务地址

启动成功
1.2.3 解决Es跨域问题
# 发现连接不上,跨域问题(跨端口,跨网站等)修改配置,设置跨域
# 进入elasticsearch-7.6.2\config\elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
1.3 Elasticsearch-head
1.3.1 简介
elasticsearch-head是一个用于浏览ElasticSearch集群并与其进行交互的Web项目
注:使用elasticsearch-head需要安装Node.js
GitHub地址:https://github.com/mobz/elasticsearch-head
谷歌应用商店:https://chrome.google.com/webstore/detail/elasticsearch-head/ffmkiejjmecolpfloofpjologoblkegm/
1.3.2 安装(待补)
- 下载elasticsearch-head-master.zip解压后安装依赖
1.4 kibana
1.4.1 简介
Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索 查看交互存储在ElasticSearch索引中的数据。使用Kibana,可以通过各种如表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板实时显示Elasticsearch查询动态。
1.4.2 安装
注:版本与Elasticsearch需对应
- 下载windows版本,解压至目标目录

- 配置kibana为中文
# 进入kibana-7.6.2\config\kibana.yml
i18n.locale: "zh-CN"
- 启动kibana
进入kibana启动文件目录,启动kibana

查看日志

通过日志中描述的信息,访问5601

启动成功
2 初识Elasticsearch
elasticsearch是面向文档,关系型数据库和elasticsearch客观的对比!一切都是json
以下为例,一条Json数据就是一个文档
{
"name": "张三",
"sex":"男",
"age":18,
"tags":["渣男","夜店小神龙"]
}
2.1 与数据库对比
| DB | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types |
| 行(rows) | documents |
| 字段(columns) | fields |
物理设计:
elasticsearch在后台把每个索引划分成多个分片。每个分片可以在集群中的不同服务器间迁移
逻辑设计:
一个索引类型中,包含多个文档,当我们索引一篇文档时,可以通过这样的一个顺序找到它:索引-》类型-》文档id,通过这个组合我们就能索引到某个具体的文档。注意:ID不必是整数,实际上它是一个字符串。
2.2 文档
es是面向文档的,意味着索引和搜索数据的最小单位是文档,es中,文档有几个重要的属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value
- 可以是层次性的,一个文档中包含自文档,复杂的逻辑实体就是这么来的
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在es中,对于字段是非常灵活的。有时候,我们可以忽略字段,或者动态的添加一个新的字段
尽管我们可以随意的添加或忽略某个字段,但是,每个字段的类型非常重要。因为es会保存字段和类型之间的映射以及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在es中,类型有时候也称为映射类型。
2.3 类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为string类型.我们说文档是无模式的,他们不需要拥有映射中所定义的所有字段,当新增加一个字段时,es会自动的将新字段加入映射,但是这个字段不确定他是什么类型,所以最安全的方式是提前定义好所需要的映射。

2.4 索引
索引是映射类型的容器,es的索引是一个非常大的集合。索引寻出了映射类型的字段和其他设置。然后他们被存储到了各个分片上。
物理设计:
2.5 倒排索引(待补)
3 Analysis-分词器
3.1 简介
顾名思义,文本分析就是把全文本转换成一系列单词(term/token)的过程,也叫分词。在 ES 中,Analysis 是通过分词器(Analyzer) 来实现的,可使用 ES 内置的分析器或者按需定制化分析器。
举一个分词简单的例子:比如你输入 Mastering Elasticsearch,会自动帮你分成两个单词,一个是 mastering,另一个是 elasticsearch,可以看出单词也被转化成了小写的
关于分词的相关资料参考于:https://blog.csdn.net/qq_31960623/article/details/119811859
[
](https://blog.csdn.net/qq_31960623/article/details/119811859)
4 Rest风格命令的使用
4.1.1 命令格式
一种软件架构风格,而不是标准。更易于实现缓存等机制
| **method ** | request | desc |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有的数据 |
4.1.2 创建索引
- 创建索引** **PUT /索引名称/类型名称/文档id
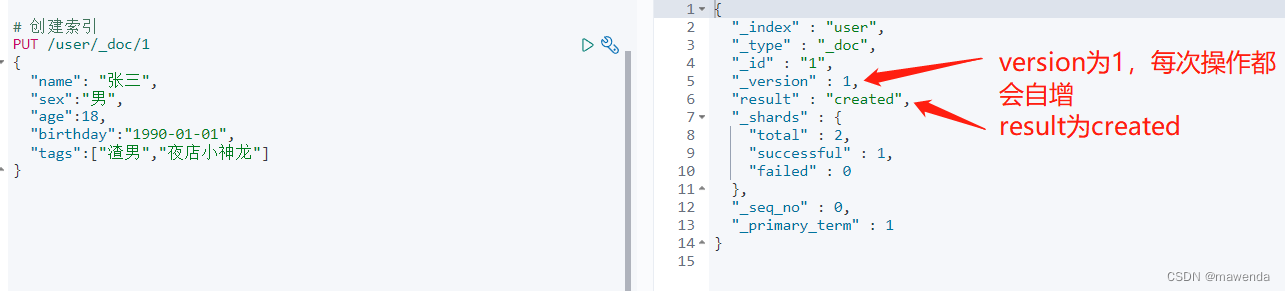
PUT /user/_doc/1 { "name": "张三", "sex":"男", "age":20, "birthday":"2002-01-01", "desc":"抽烟喝酒锡纸烫", "tags":["渣男","靓仔","夜店小神龙"] }
- 查看elasticsearch-head,可以看到我们创建了名称为user的 索引,并且数据成功插入进来了

- 查看当前索引信息 GET /索引名称,也可以增加条件获取更详细的信息

4.1.3 修改数据
- 使用 PUT /索引名称/类型名称/文档id方式对tags字段进行了修改,响应回的信息告诉我们修改成功

使用 GET /索引名称/类型名称/文档id方式查询我们修改的数据

可以看到tags中的数据由 [“渣男”,“夜店小神龙”] 变为 [“渣男”,“夜店小神龙”,“靓仔”],但是其他未作出修改的字段的数据没有了,一般我们不会通过这种方式来修改数据
- 使用 POST /索引名称/类型名称/文档id/_update方式进行修改

可以看到我们只对tags字段做了修改,但是其他字段的数据依旧存在
- 修改mapping
# 注意es7后忽略类型 _doc需删除
PUT index/_mapping
{
"properties": {
"stockType":{
"type":"integer"
}
}
}
4.1.4 删除索引
4.1.4.1 使用 DELETE /索引名称 删除索引


再次查询该索引时,提示我们 index_not_found_exception
4.1.4.12 删除索引下所有数据
POST ${索引名称}/_delete_by_query
{ "query": { "match_all": {} } }
4.1.5 条件搜索
4.1.5.1 查询
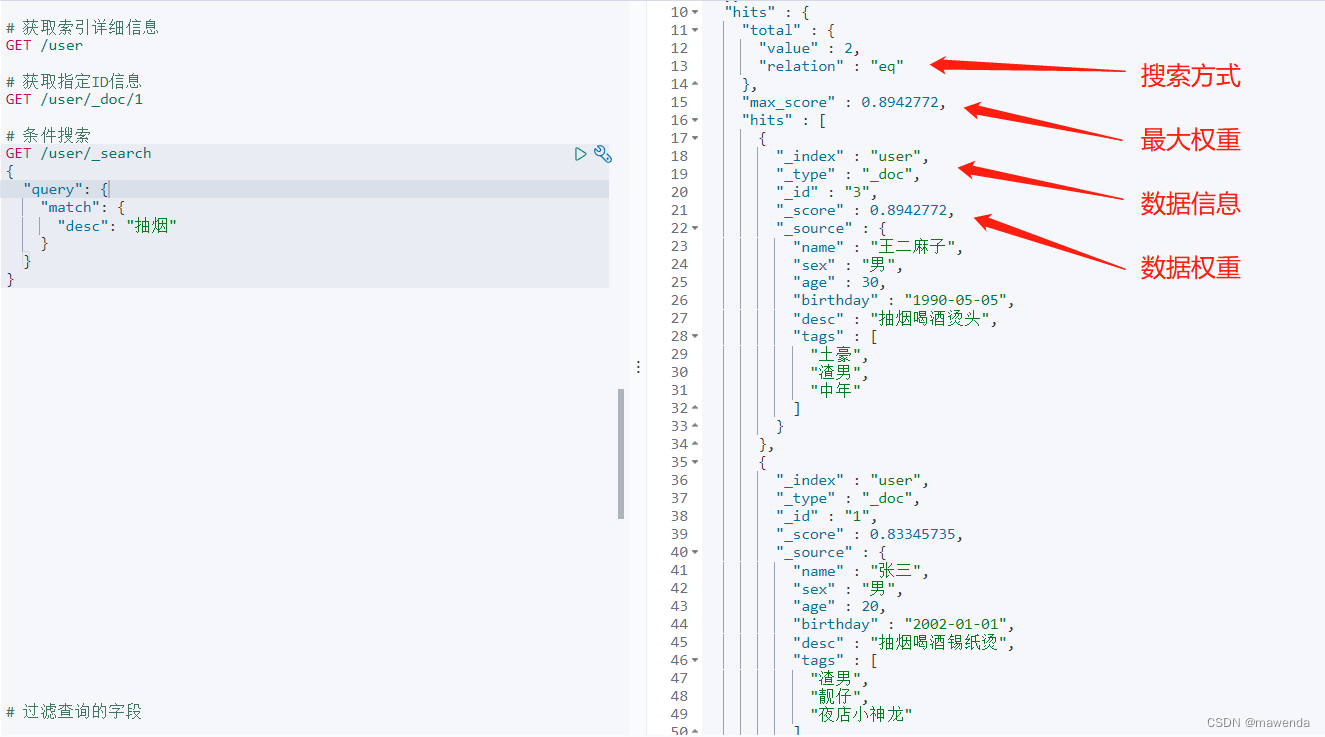
GET /user/_search { "query": { "match": { "desc": "抽烟" } } }
我们通过相同的查询语句搜索desc字段为抽烟的,会发现匹配到了两条数据,是因为desc字段类型为text类型,是对该字段分词后进行了查询,keyword则只能通过精确查询,不会进行分词处理
查询出的结果都会返回_score字段,分值越高代表权重越高,匹配度高
4.1.5.2 精确查询
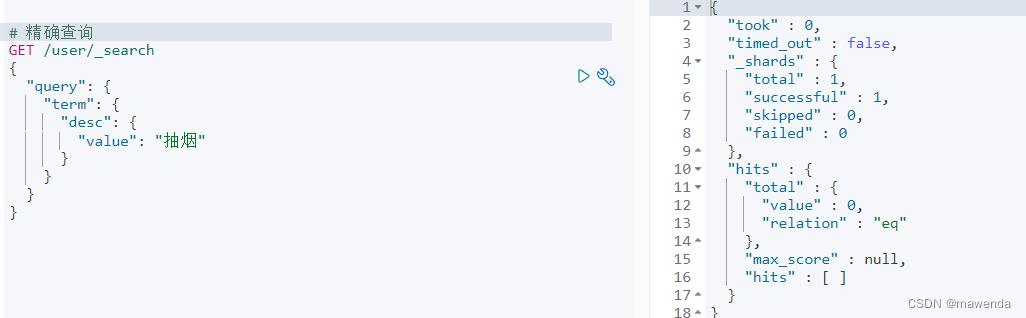
GET /user/_search { “query”: { “term”: { “desc”: { “value”: “抽烟” } } } }
term查询是直接通过倒排索引指定的词条进程精确查找的
4.1.5.3 过滤查询的字段
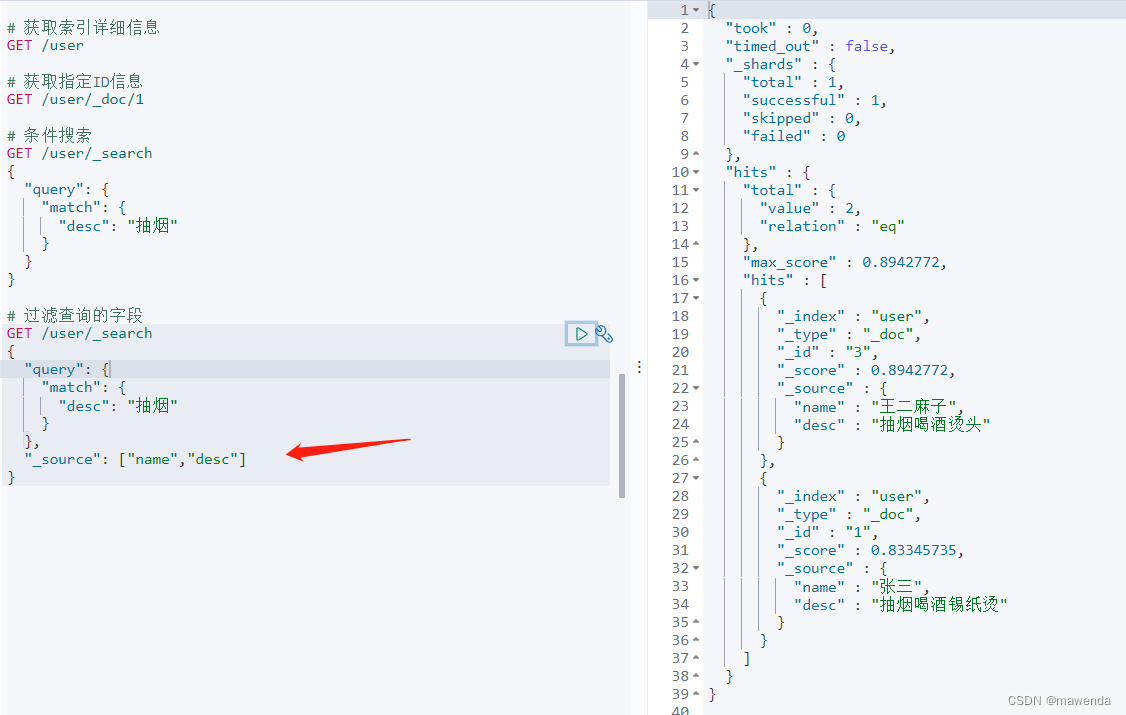
GET /user/_search { "query": { "match": { "desc": "抽烟" } }, "_source": ["name","desc"] }
查询出的数据,只返回了我们 _source中定义的字段,相当于Mysql中 select name, desc from user
4.1.5.4 包含与不包含
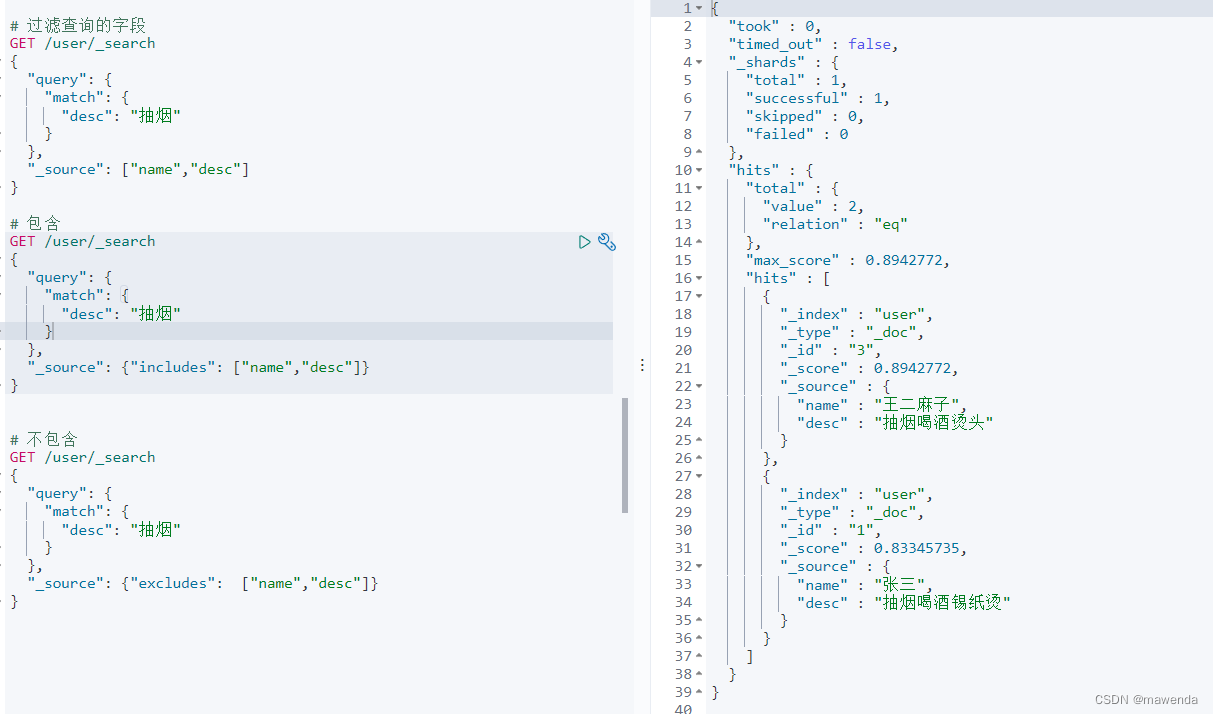
GET /user/_search { "query": { "match": { "desc": "抽烟" } }, "_source": {"includes": ["name","desc"]} }
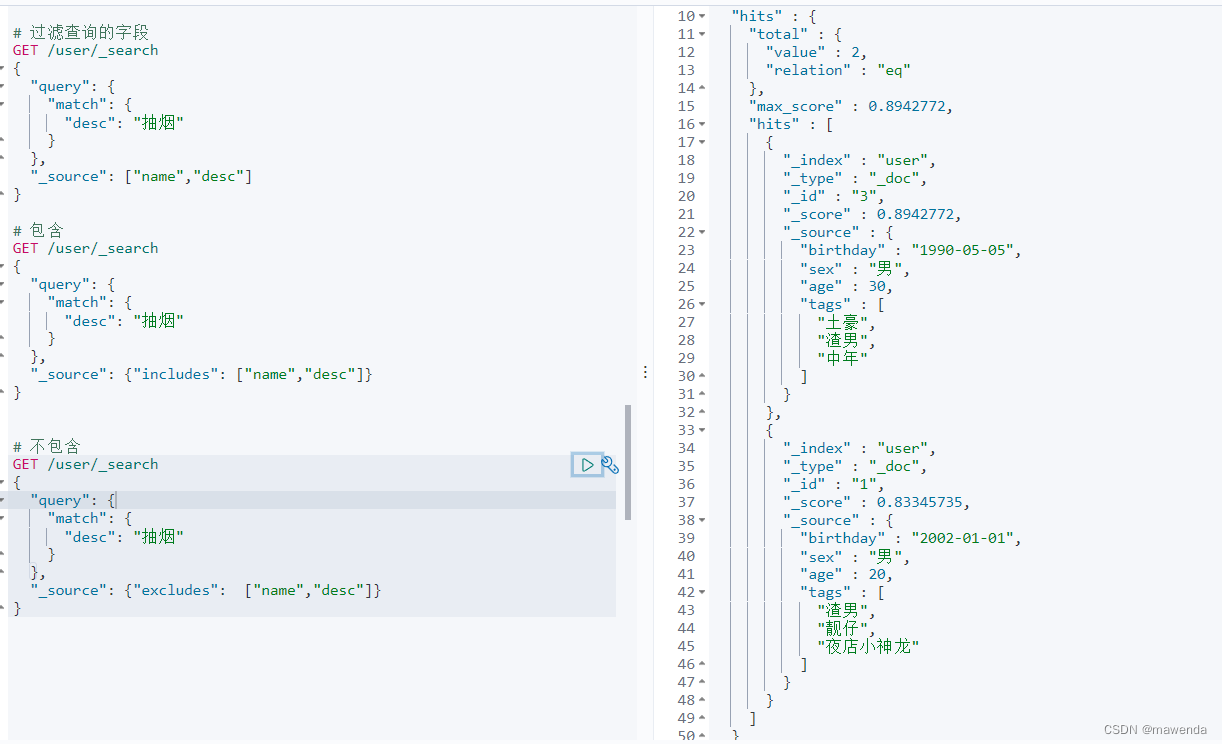
GET /user/_search { "query": { "match": { "desc": "抽烟" } }, "_source": {"excludes": ["name","desc"]} }
4.1.5.5 排序
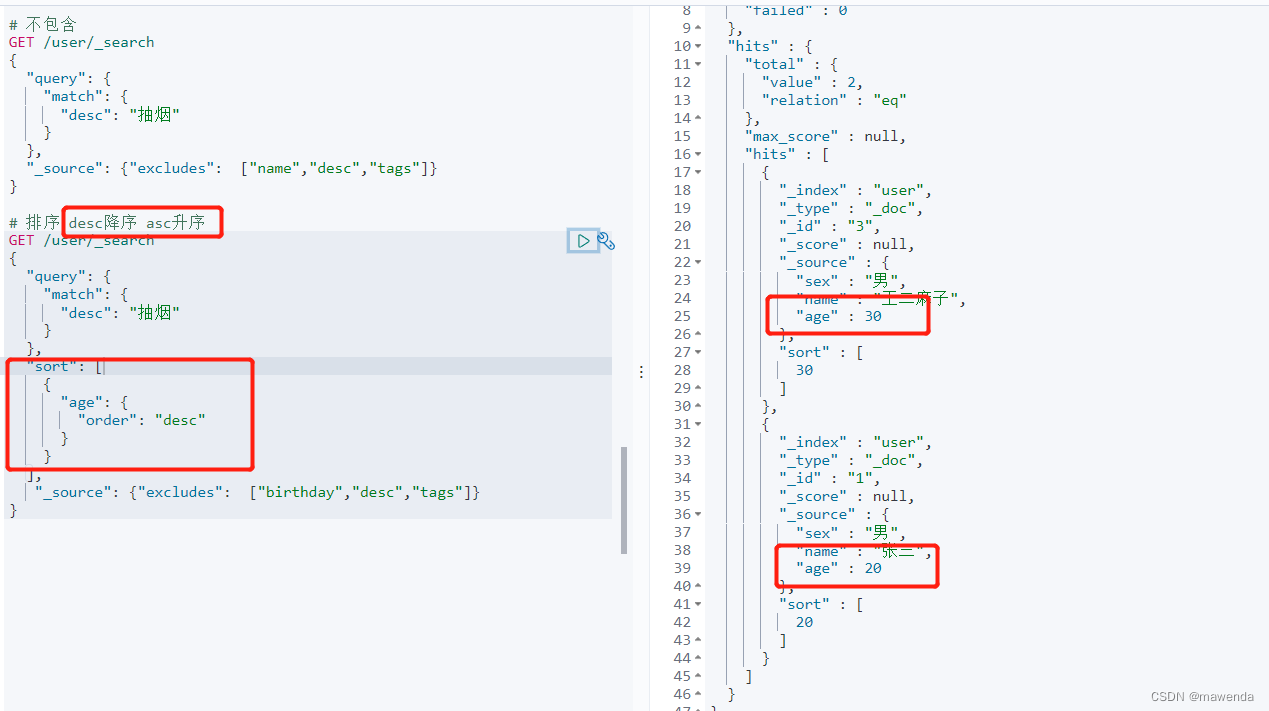
GET /user/_search { "query": { "match": { "desc": "抽烟" } }, "sort": [ { "age": { "order": "desc" } } ] }
4.1.5.6 分页
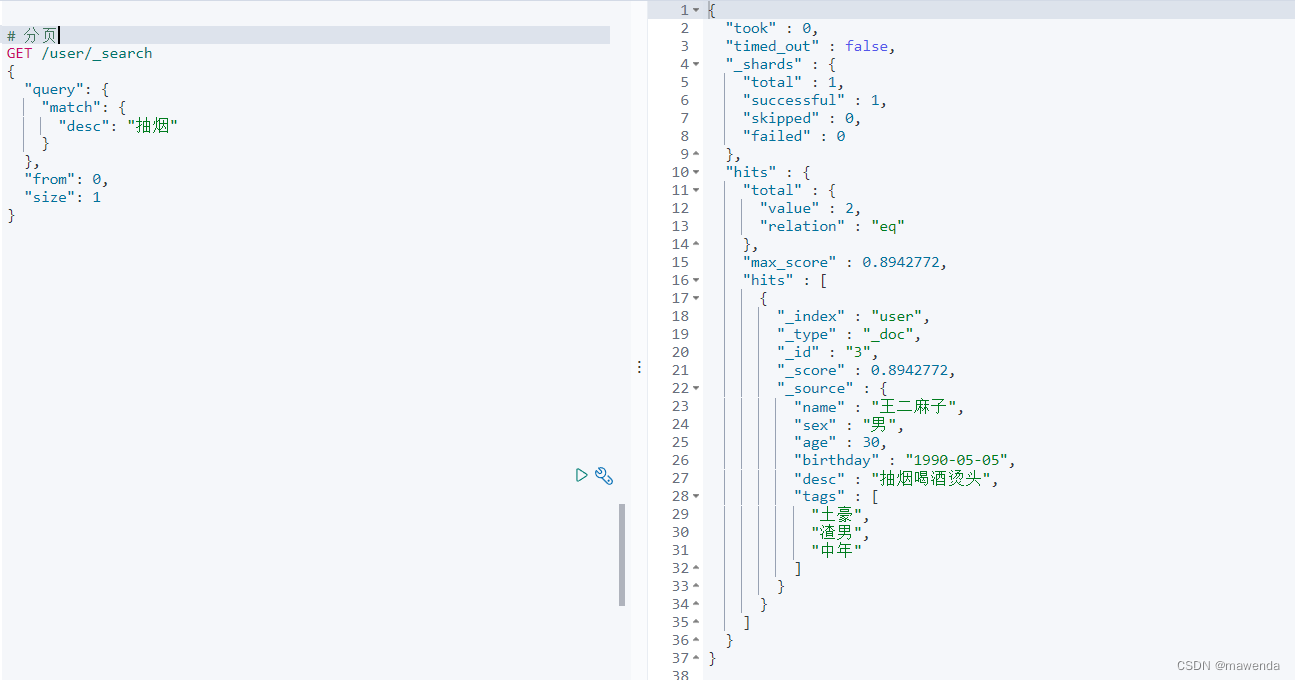
GET /user/_search { "query": { "match": { "desc": "抽烟" } }, "from": 0, "size": 1 }
4.1.5.7 数组查询
GET document_index/_search 数组中同时有两个值,所以该语句查不到记录返回
{
"query": {
"bool": {
"filter": [
{
"term": {
"teams": "AA"
}
},
{
"term": {
"teams": "DD"
}
}
]
}
}
}
GET document_index/_search 数组中值或关系,只要有AA或者DD,就可以返回
{
"query": {
"bool": {
"filter": [
{
"terms": {
"teams": [
"AA",
"DD"
]
}
}
]
}
}
}
4.4.6 布尔值查询(多条件查询)
4.4.6.1 must/and
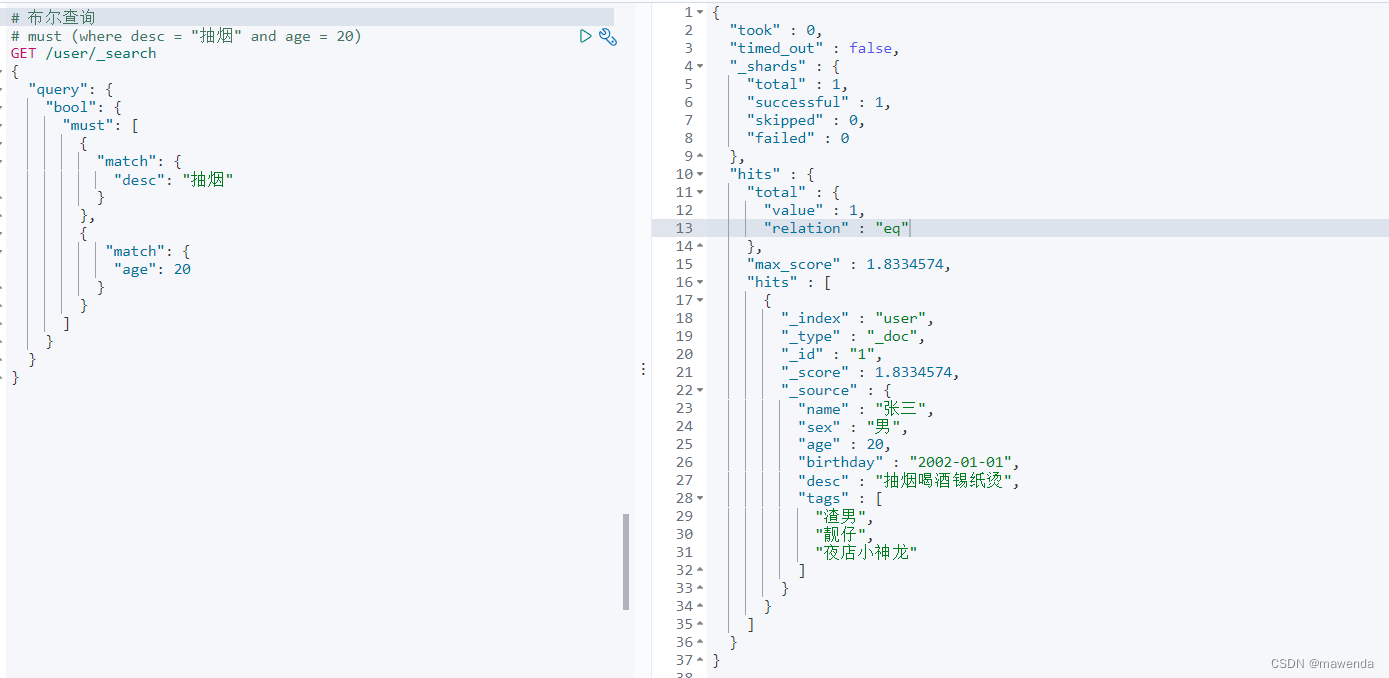
GET /user/_search { "query": { "bool": { "must": [ { "match": { "desc": "抽烟" } }, { "match": { "age": 20 } } ] } } }
4.4.6.2 should/or
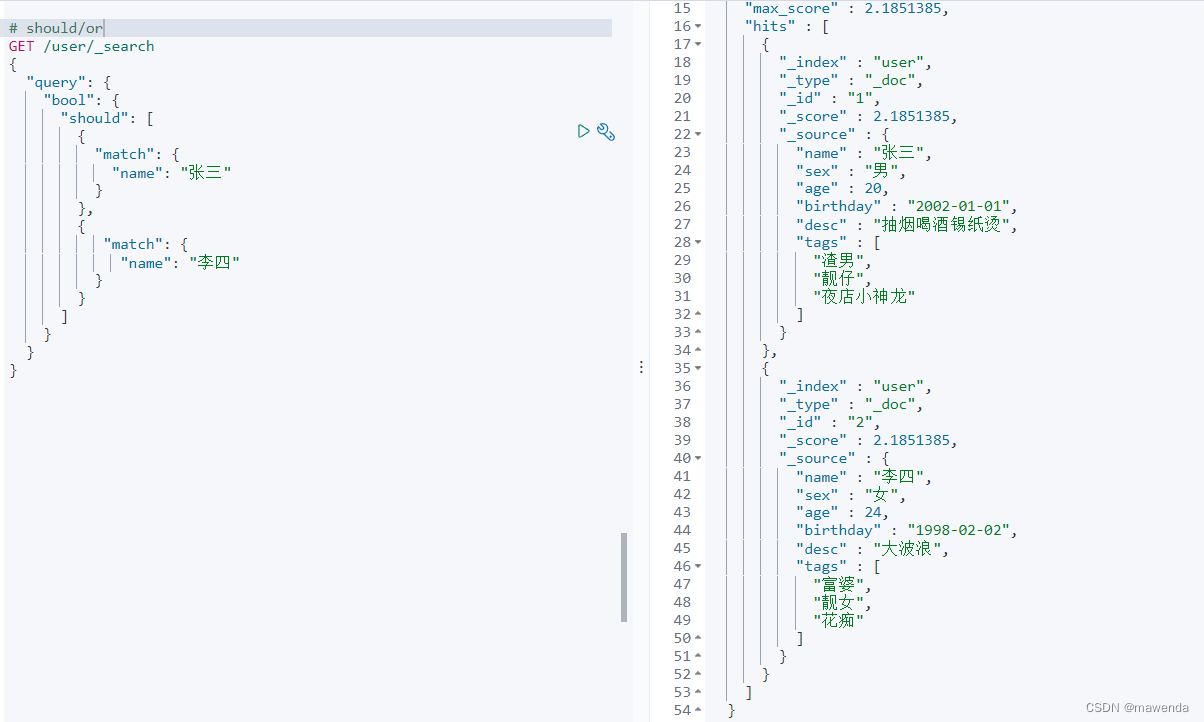
GET /user/_search { "query": { "bool": { "should": [ { "match": { "name": "张三" } }, { "match": { "name": "李四" } } ] } } }
4.4.6.3 must_not/ not
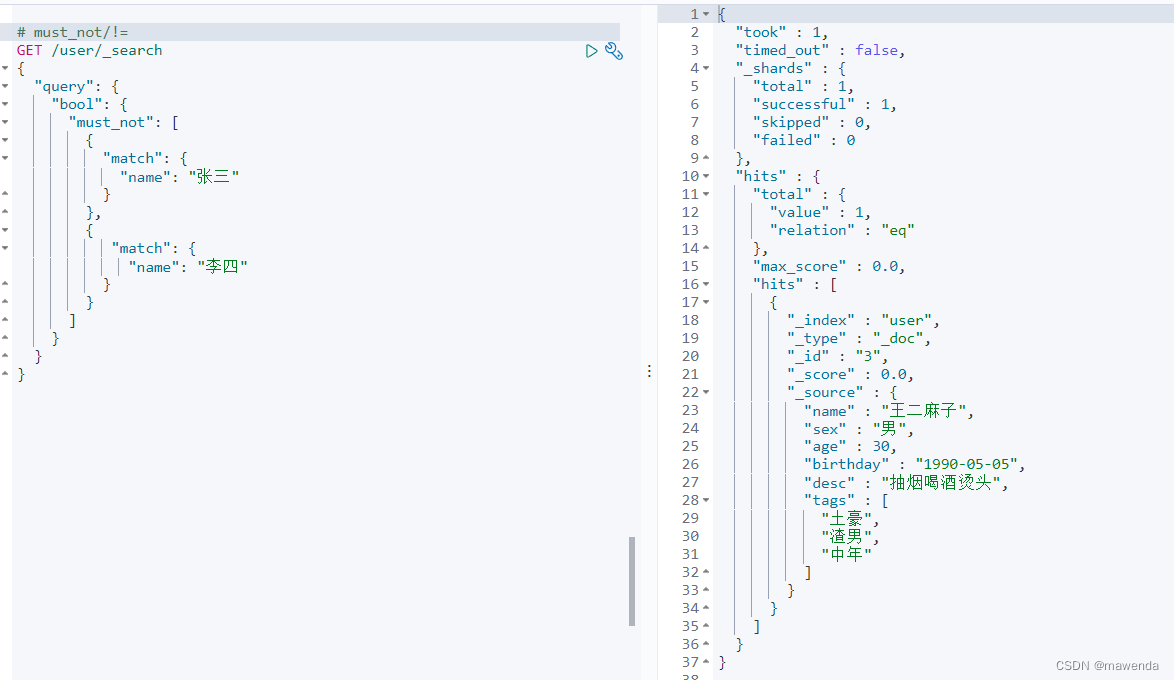
GET /user/_search { "query": { "bool": { "must_not": [ { "match": { "name": "张三" } }, { "match": { "name": "李四" } } ] } } }
4.4.6.4 条件区间
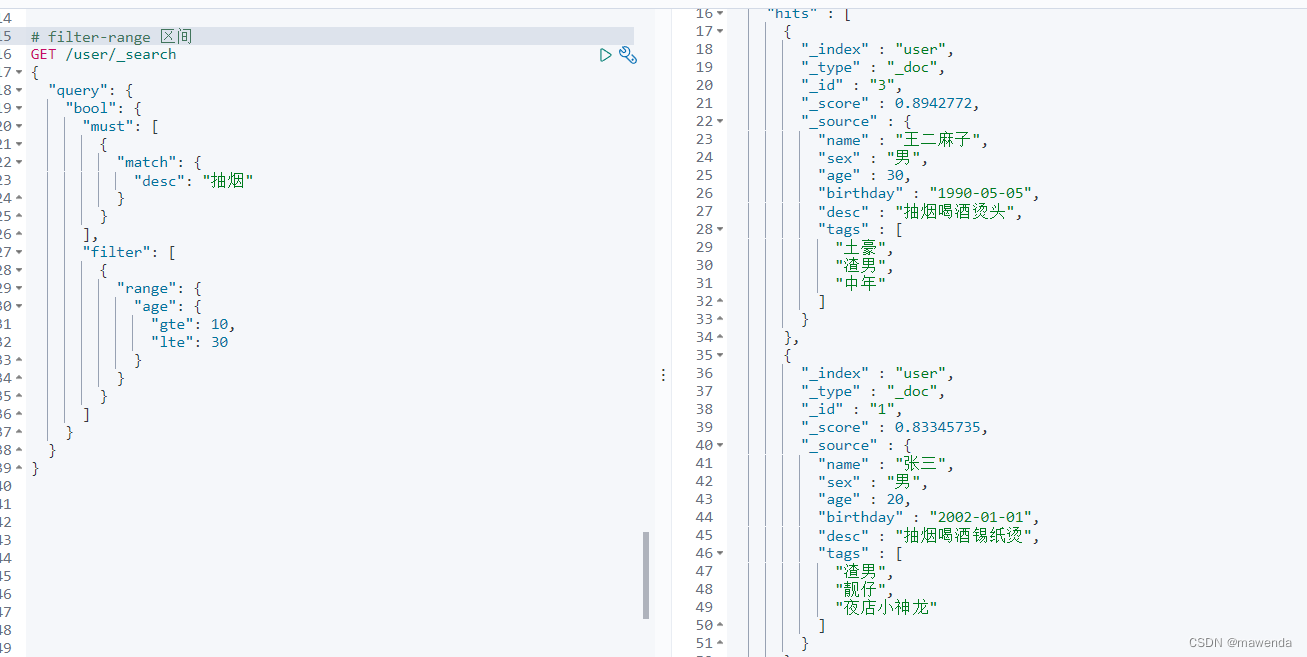
GET /user/_search { "query": { "bool": { "must": [ { "match": { "desc": "抽烟" } } ], "filter": [ { "range": { "age": { "gte": 10, "lte": 30 } } } ] } } }
- gt大于
- gte大于等于
- lte小于
- lte小于等于
4.4.6.4 匹配多个条件(数组)

4.4.7 分词(待补)
4.4.8 高亮查询
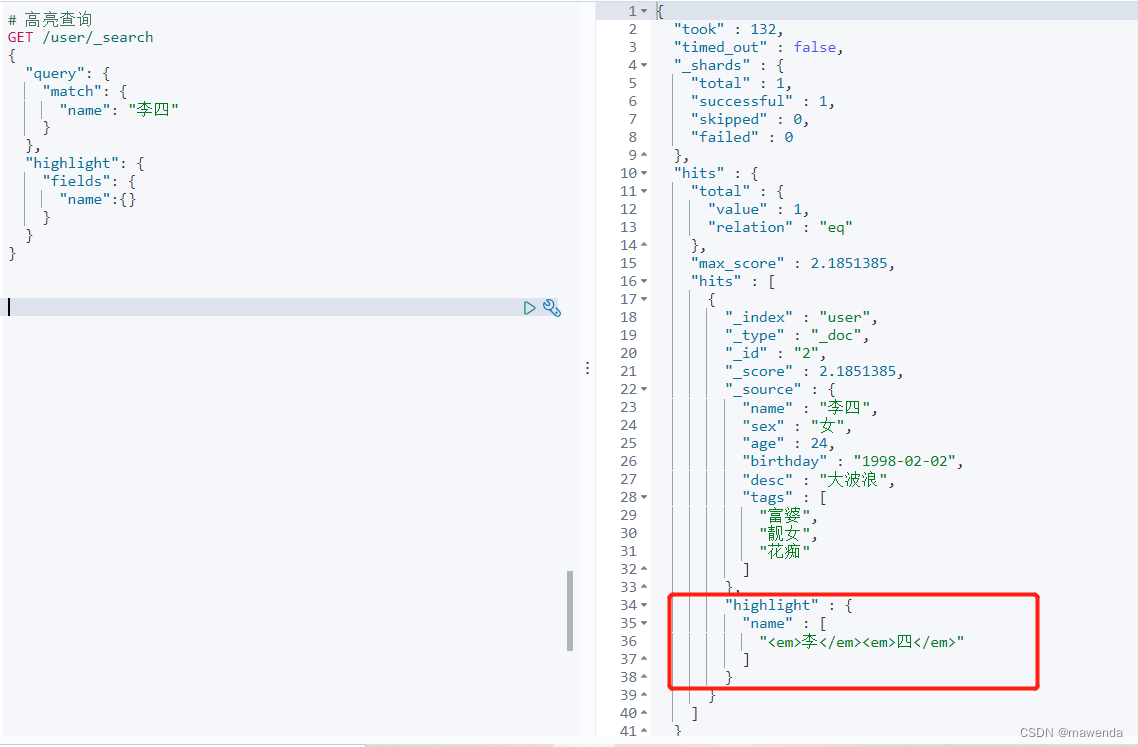
GET /user/_search { "query": { "match": { "name": "李四" } }, "highlight": { "fields": { "name":{} } } }
可以看到,我们在搜索中使用了高亮查询,在结果栏中,高亮查询的字段上增加了HTML标签,我们可以自定义一些样式,如下

5 Java操作Es
5.1 Es官方文档

5.1.1 客户端依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
客户端依赖于以下

5.1.2 客户端实例

5.2 集成SpringBoot
5.2.1 创建SpringBoot应用并选中相关依赖

5.2.2 配置环境

1、java版本为1.8以上
2、es版本为安装的版本
5.2.3 配置Es客户端
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("127.0.0.1",9200,"http"))
);
return client;
}
}
5.2.4 对索引的一些操作
@SpringBootTest
class SpringbootEsApiApplicationTests {
@Resource
RestHighLevelClient client;
static final String BOOK_INDEX = "book_index";
// 创建索引 PUT book_index
@Test
void createIndex() throws IOException {
// 1、创建索引请求
CreateIndexRequest request = new CreateIndexRequest(BOOK_INDEX);
// 2、客户端执行请求获取响应
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
}
// 判断索引是否存在
@Test
void existsIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest(BOOK_INDEX);
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
// 删除索引
@Test
void deleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest(BOOK_INDEX);
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
}
可以看到,先去创建对应的索引请求,再根据我们注入的客户端去执行请求
5.2.5 对文档的一些操作
5.2.5.1 添加文档
@Test
void addDocument() throws IOException {
// 创建对象
User user = new User("1","张三", 20, "男", "抽烟喝酒烫头");
// 创建请求
IndexRequest request = new IndexRequest(USER_INDEX);
// 指定ID
request.id(user.getId());
// 设置超时时间
request.timeout(TimeValue.timeValueSeconds(1));
// 将资源转换为json串放入请求
request.source(JSON.toJSONString(user), XContentType.JSON);
// 发起请求
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
// 响应结果:IndexResponse[index=user_index,type=_doc,id=1,version=1,result=created,seqNo=0,primaryTerm=2,shards={"total":2,"successful":1,"failed":0}]
System.out.println(response.toString());
// 响应状态:CREATED
System.out.println(response.status());
}
5.2.5.2 判断文档是否存在
@Test
void existsDocument() throws IOException {
GetRequest request = new GetRequest(USER_INDEX, "1");
boolean exists = client.exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
5.2.5.3 获取文档
@Test
void getDocument() throws IOException {
GetRequest request = new GetRequest(USER_INDEX, "1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// {"_index":"user_index","_type":"_doc","_id":"1","_version":1,"_seq_no":0,"_primary_term":2,"found":true,"_source":{"age":20,"desc":"抽烟喝酒烫头","id":"1","name":"张三","sex":"男"}}
System.out.println(response);
}
5.2.5.4 修改文档
@Test
void updateDocument() throws IOException {
User user = new User();
user.setId("1");
user.setDesc("抽烟喝酒锡纸烫");
UpdateRequest request = new UpdateRequest(USER_INDEX, user.getId());
request.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
// UpdateResponse[index=user_index,type=_doc,id=1,version=2,seqNo=1,primaryTerm=2,result=updated,shards=ShardInfo{total=2, successful=1, failures=[]}]
System.out.println(response);
}
5.2.5.5 删除文档
@Test
void deleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest(USER_INDEX, "1");
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
// DeleteResponse[index=user_index,type=_doc,id=1,version=3,result=deleted,shards=ShardInfo{total=2, successful=1, failures=[]}]
System.out.println(response);
} @Test
void addDocument() throws IOException {
// 创建对象
User user = new User("1","张三", 20, "男", "抽烟喝酒烫头");
// 创建请求
IndexRequest request = new IndexRequest(USER_INDEX);
// 指定ID
request.id(user.getId());
// 设置超时时间
request.timeout(TimeValue.timeValueSeconds(1));
// 将资源转换为json串放入请求
request.source(JSON.toJSONString(user), XContentType.JSON);
// 发起请求
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
// 响应结果:IndexResponse[index=user_index,type=_doc,id=1,version=1,result=created,seqNo=0,primaryTerm=2,shards={"total":2,"successful":1,"failed":0}]
System.out.println(response.toString());
// 响应状态:CREATED
System.out.println(response.status());
}
5.2.5.6 批量操作文档
@Test
void bulkAddDocument() throws IOException {
List<User> userList = getData();
BulkRequest request = new BulkRequest();
userList.forEach(user -> {
// 本次执行的是批量添加,如需其他操作,更换对应的请求即可
request.add(
new IndexRequest(USER_INDEX)
.id(user.getId())
.source(JSON.toJSONString(user), XContentType.JSON)
);
});
BulkResponse response = client.bulk(request, RequestOptions.DEFAULT);
// 是否失败 false为成功
System.out.println(response.hasFailures());
}
List<User> getData(){
List<User> userList = new ArrayList<>();
userList.add( new User("1","王二麻子", 20, "男", "抽烟喝酒锡纸烫"));
userList.add( new User("2","张三", 24, "女", "抽烟喝酒大波浪"));
userList.add( new User("3","李四", 22, "女", "抽烟喝酒脏脏辨"));
userList.add( new User("4","王五", 24, "男", "抽烟喝酒烫头"));
return userList;
}
5.2.6 复杂查询
@Test
void SearchDocument() throws IOException {
// 创建查询请求
SearchRequest request = new SearchRequest(USER_INDEX);
// 构建搜索条件
SearchSourceBuilder builder = new SearchSourceBuilder();
// 构建查询方式与条件
String keyword = "李";
// 精确查询
TermQueryBuilder query = QueryBuilders.termQuery("name", keyword);
// 将构建好的查询条件放入构造器
builder.query(query);
// 设置超时时间
builder.timeout(TimeValue.timeValueSeconds(60));
// 将构造器放入请求
request.source(builder);
// 使用客户端发起查询请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit documentFields : response.getHits().getHits()) {
System.out.println(documentFields.getSourceAsMap());
}
}
5.2.6.1 精确查询
TermQueryBuilder query = QueryBuilders.termQuery("name", keyword);
searchSourceBuilder.query(query);
5.2.6.2 条件查询
MatchQueryBuilder query = QueryBuilders.matchQuery("name", field).minimumShouldMatch("75%");
searchSourceBuilder.query(query);
5.2.6.3 包含相关
String[] includes = {"name","desc"};
// 多字段
searchSourceBuilder.fetchSource(includes, Strings.EMPTY_ARRAY);
// 单字段
searchSourceBuilder.fetchSource("name", "");
5.2.6.4 排序
searchSourceBuilder.sort("age", SortOrder.DESC);
5.2.6.5 分页
searchSourceBuilder.from(0);
searchSourceBuilder.size(2);
5.2.7 布尔查询
5.2.7.1 must-与
// 构建查询条件
MatchQueryBuilder descMust = QueryBuilders.matchQuery("desc", keyword).minimumShouldMatch("75%");
MatchQueryBuilder ageMust = QueryBuilders.matchQuery("age", 20);
// 构建布尔查询构造器
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
// 将查询条件放入构造器
queryBuilder.must(descMust);
queryBuilder.must(ageMust);
// 将构建好的查询条件放入构造器
searchSourceBuilder.query(queryBuilder);
5.2.7.2 should-或
// 构建查询条件
MatchQueryBuilder age1 = QueryBuilders.matchQuery("age", 24);
MatchQueryBuilder age2 = QueryBuilders.matchQuery("age", 20);
// 构建布尔查询构造器
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
// 将查询条件放入构造器
queryBuilder.should(age1);
queryBuilder.should(age2);
// 将构建好的查询条件放入构造器
searchSourceBuilder.query(queryBuilder);
5.2.7.3 mustNot-不包含
// 构建查询条件
MatchQueryBuilder age1 = QueryBuilders.matchQuery("age", 24);
MatchQueryBuilder age2 = QueryBuilders.matchQuery("age", 20);
// 构建布尔查询构造器
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
// 将查询条件放入构造器
queryBuilder.mustNot(age1);
queryBuilder.mustNot(age2);
// 将构建好的查询条件放入构造器
searchSourceBuilder.query(queryBuilder);
5.2.7.4 filter-区间查询
// 构建查询条件
RangeQueryBuilder queryBuilder = QueryBuilders.rangeQuery("age").gte(20).lte(22);
// 构建布尔查询构造器
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 将查询条件放入构造器
boolQueryBuilder.filter(queryBuilder);
// 将构建好的查询条件放入构造器
searchSourceBuilder.query(boolQueryBuilder);
5.2.8 高亮查询
@Test
void SearchDocument() throws IOException {
// 创建查询请求
SearchRequest request = new SearchRequest(USER_INDEX);
// 构建搜索条件
SearchSourceBuilder builder = new SearchSourceBuilder();
// 设置高亮字段的相关配置
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("desc");
highlightBuilder.requireFieldMatch(false); // 多个高亮显示
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
builder.highlighter(highlightBuilder);
// 构建查询方式与条件
String keyword = "大波浪";
MatchQueryBuilder query = QueryBuilders.matchQuery("desc", keyword).minimumShouldMatch("75%");
// 将构建好的查询条件放入构造器
builder.query(query);
// 设置超时时间
builder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 将构造器放入请求
request.source(builder);
// 使用客户端发起查询请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
List<Map<String, Object>> userList = new ArrayList<>();
// 解析高亮
for (SearchHit hit : response.getHits().getHits()) {
// 获取高亮字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField highlightField = highlightFields.get("desc");
// 获取原数据
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
if (highlightField != null) {
// 取出高亮字段替换原来无高亮字段
Text[] fragments = highlightField.fragments();
String field = "";
for (Text fragment : fragments) {
field += fragment;
}
// 将替换好的高亮字段放入结果中
sourceAsMap.put("desc", field); // 开始替换
}
userList.add(sourceAsMap);
}
System.out.println(userList.toString());
}















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









