







 本文详细指导如何下载并配置Hadoop, Scala, Spark及Maven环境,包括创建Scala插件和Maven项目,以及每次新建Spark项目时的必要步骤,如添加依赖、设置源代码结构和配置仓库。
本文详细指导如何下载并配置Hadoop, Scala, Spark及Maven环境,包括创建Scala插件和Maven项目,以及每次新建Spark项目时的必要步骤,如添加依赖、设置源代码结构和配置仓库。
一,只做一次的事情hadoop,spark,scala,maven,scala插件
,
1,下载hadoop,scala,spark,jdk。版本要适配,下面为一组搭配。下载后解压,然后配置环境变量
hadoop-2.7.0
scala-2.11.12
spark-2.4.0
JDK 1.8.0
配置scala 环境变量 和 配置JDK环境变量 一样
系统变量新增 : SCALA_HOME 值 C:\Program Files (x86)\scala (scala安装路径)
编辑Path变量: 在后追加 ;%SCALA_HOME%\bin;%SCALA_HOME%\jre\bin
cmd 下 输入 scala -version 查看是否安装成功,三者都配置一下环境变量
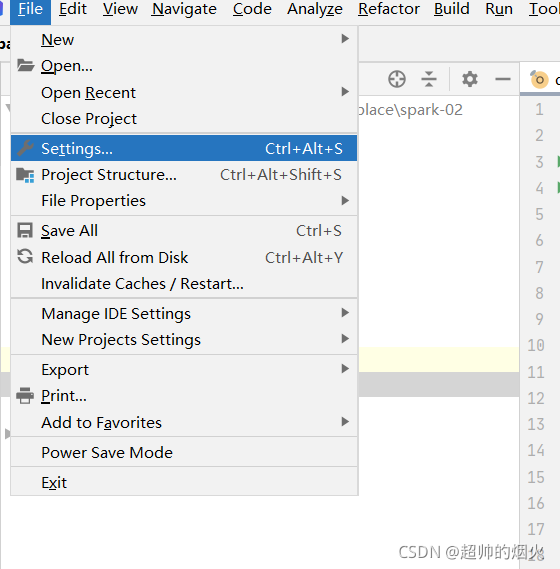
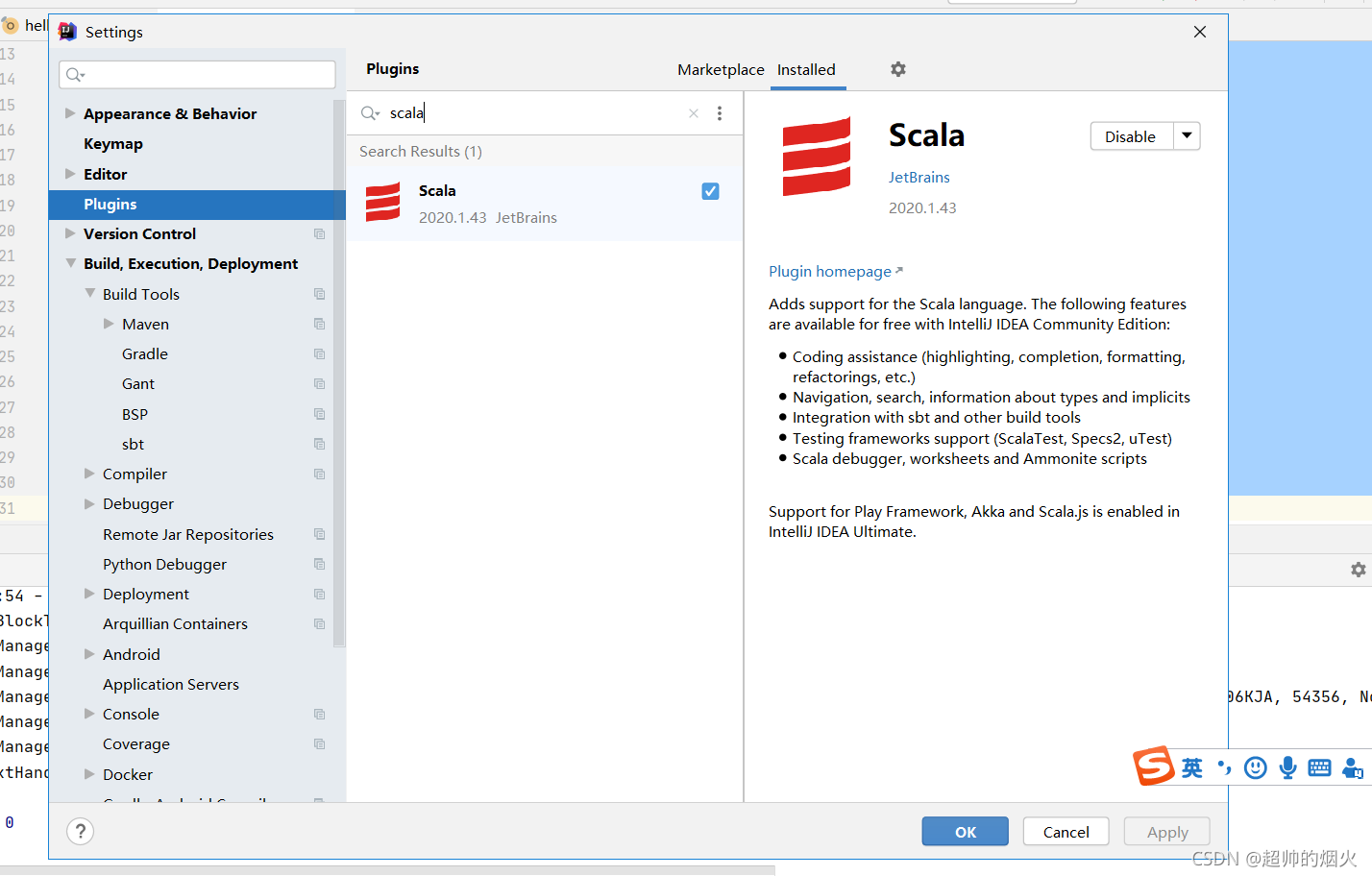
2,安装scala插件(从idea下载scala插件或者自己从官网下载scala然后配置环境变量二选一。但是建议都弄一下)
file->settings->plugins 然后左上搜索框搜索scala,然后安装就可
3,安装maven
maven不放在第一步是因为除了下载和配置环境变量之外更多一些步骤,具体不再展开。
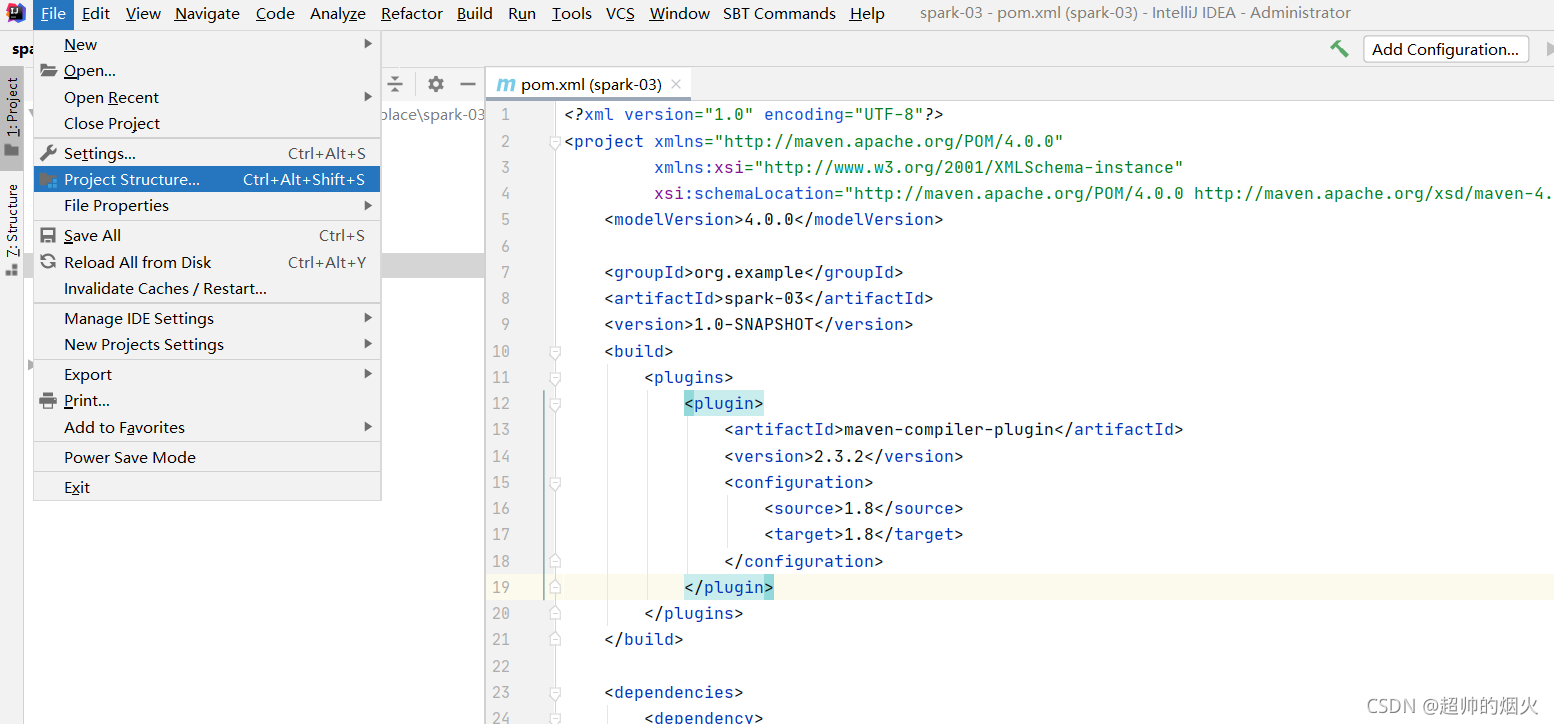
二,每次新建一个spark项目都要做的事情
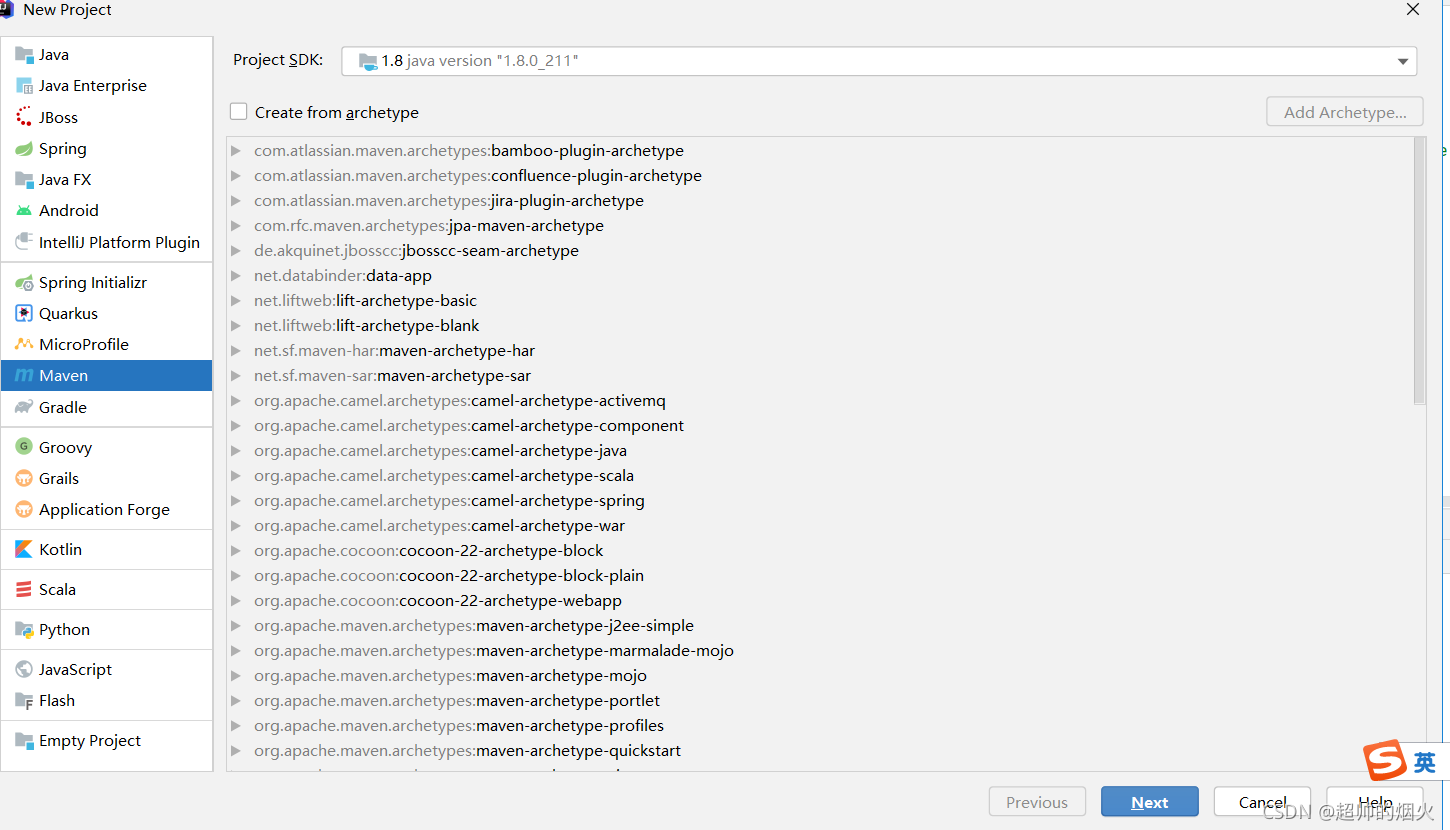
1,创建一个空maven项目,在project SDK 要选jdk版本。选自己下载的jdk
file->new->project->maven->next->finish
不勾选create from archetype 这个样自己需要什么再在pom添加,或者导入jar包
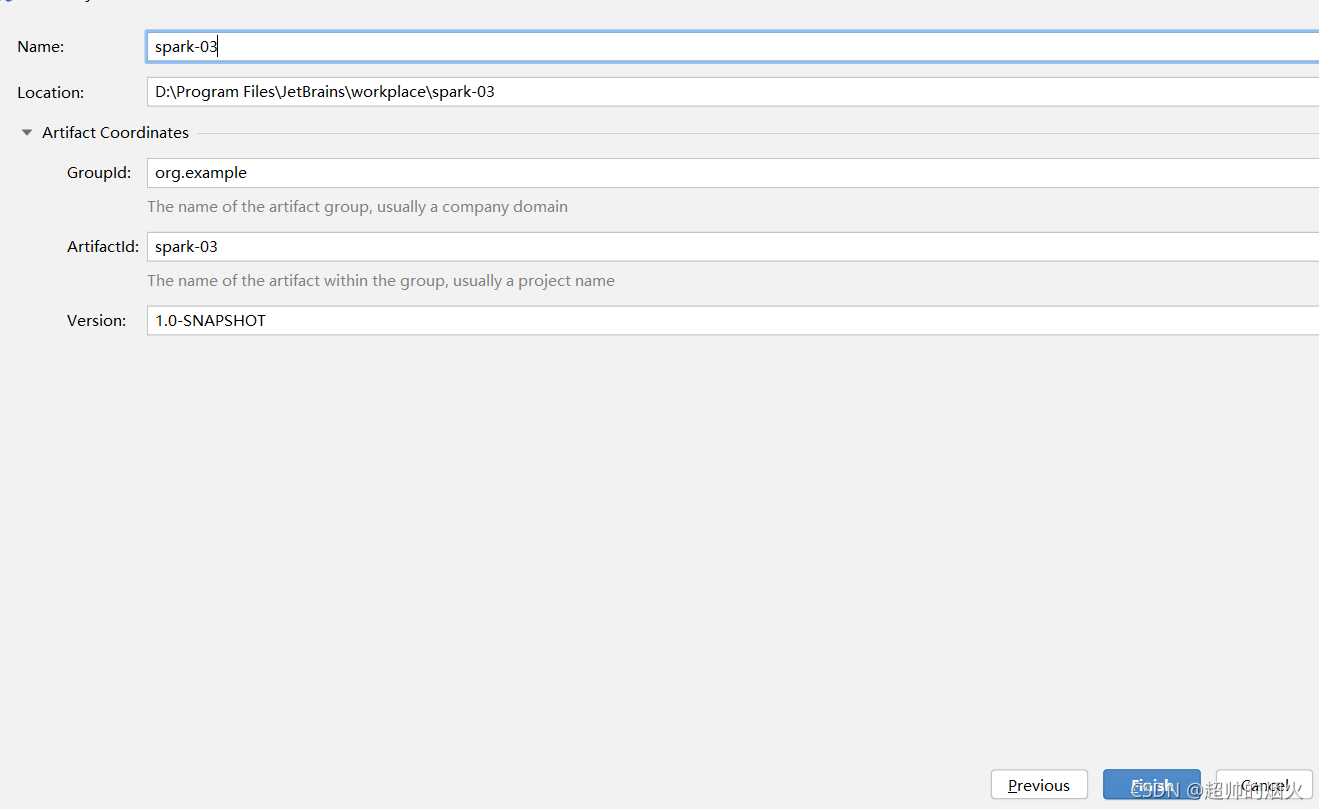
next之后就是在name处填自己项目的名字,location就是项目的绝对位置,建议在idea建立一个workplace文件夹,然后所有的代码放里面。artufict coordinates下面的就不用管了
2,在pom.xml文件加上两条依赖
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.0</version>
</dependency>
</dependencies>然后点击右上角更新的图标 load maven 就会加载依赖
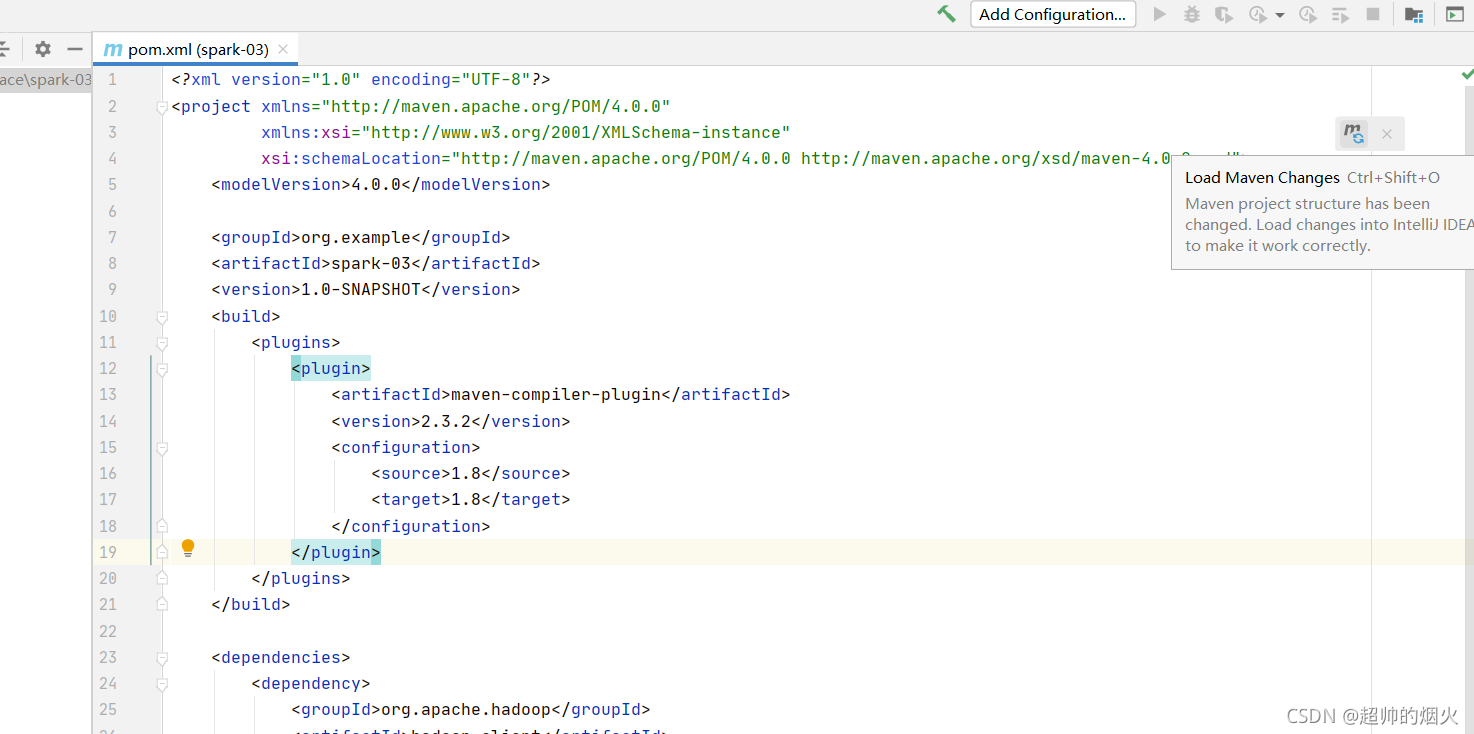
3,在src下main文件夹下创建scala文件夹,并设置为根目录
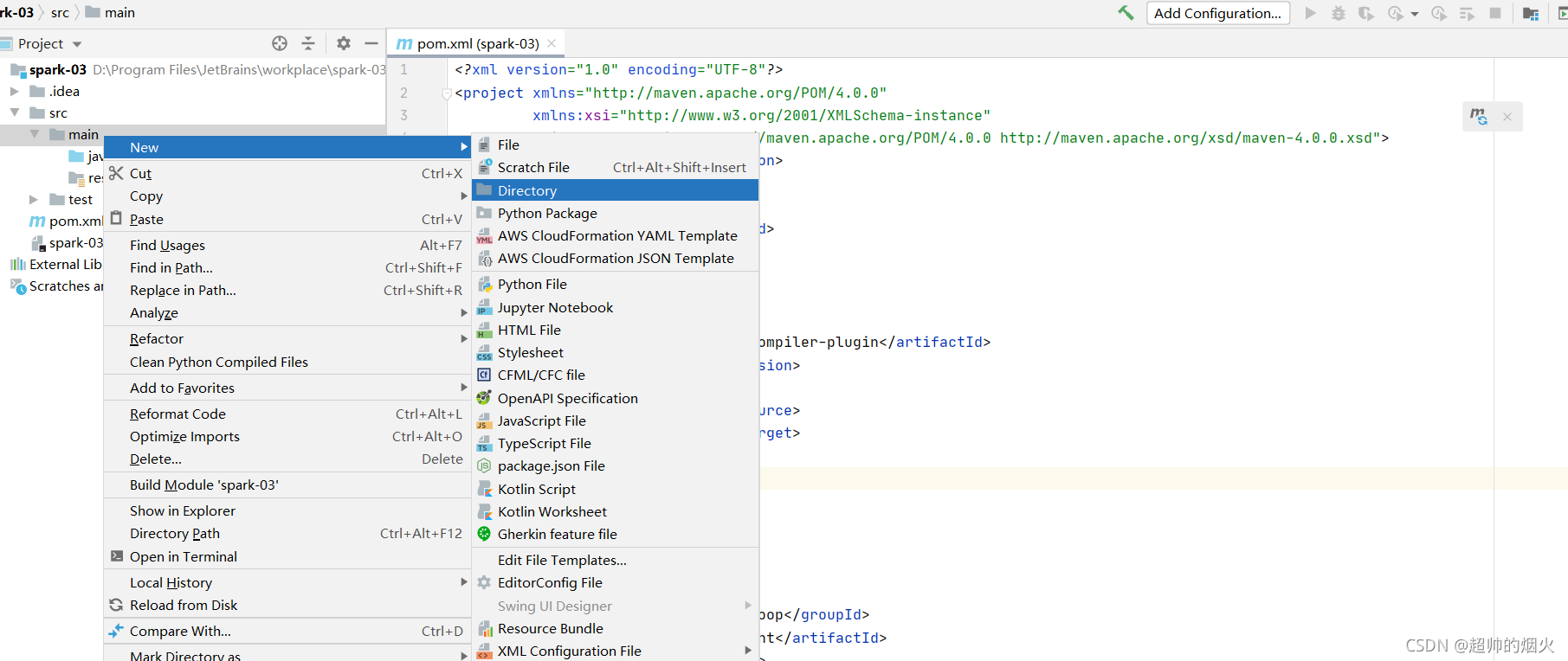
右击暗色的scala文件夹,->Make Directory->sources Root
然后scala就变为蓝色的文件夹了,然后就可以在里面创建文件了
设置为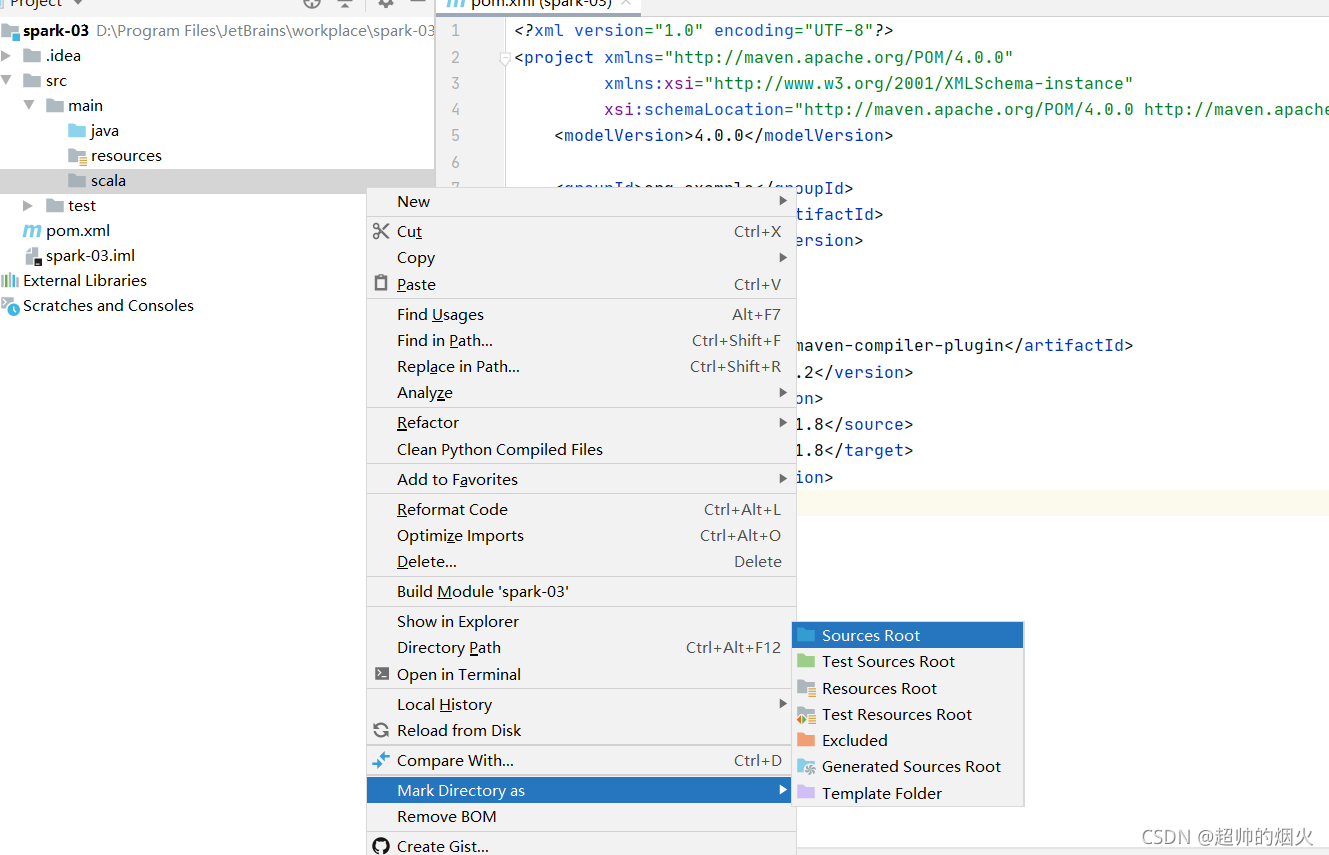
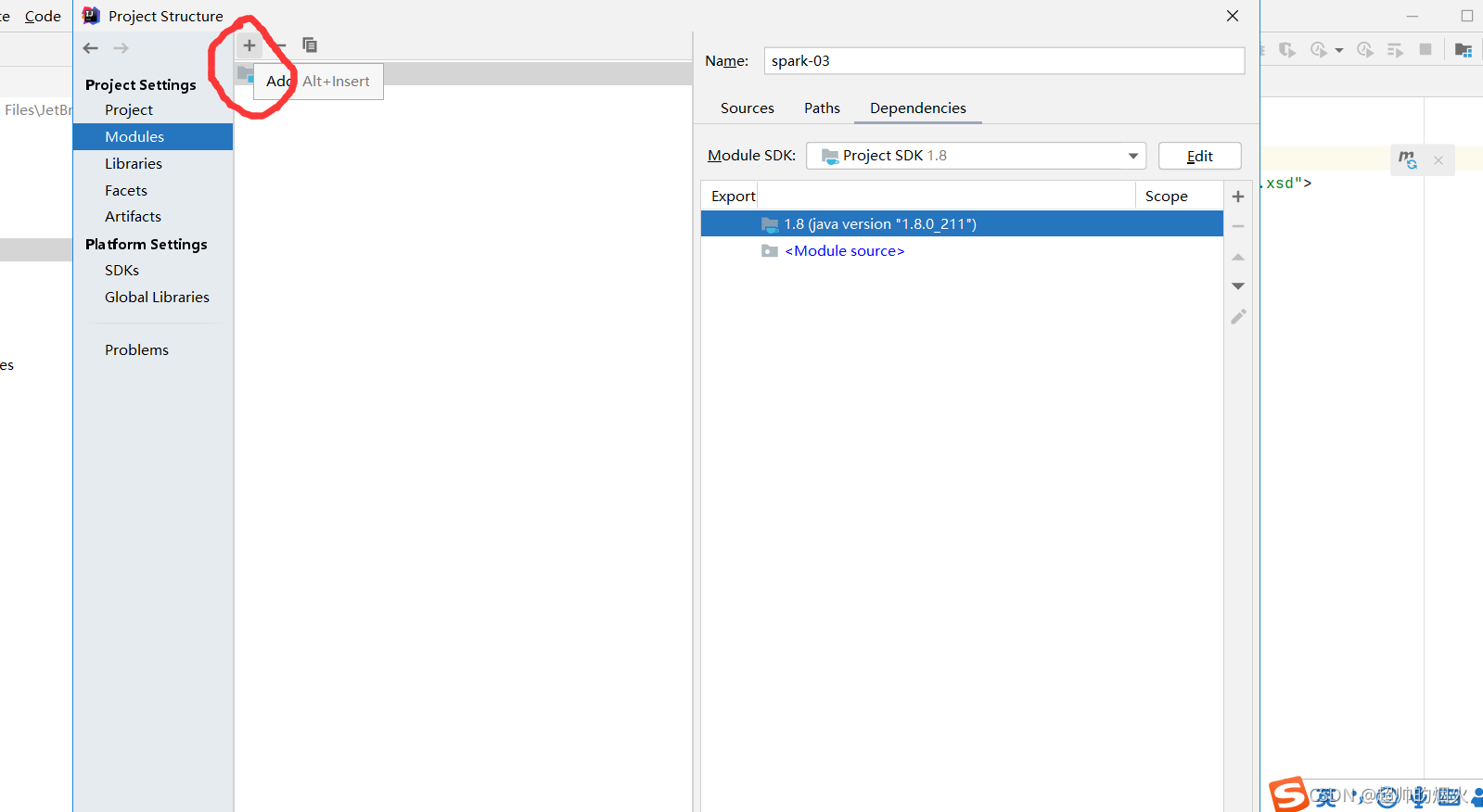
4,导入scala依赖
在scala文件夹建立scala文件时,发现没有,那是因为没有导入scala依赖
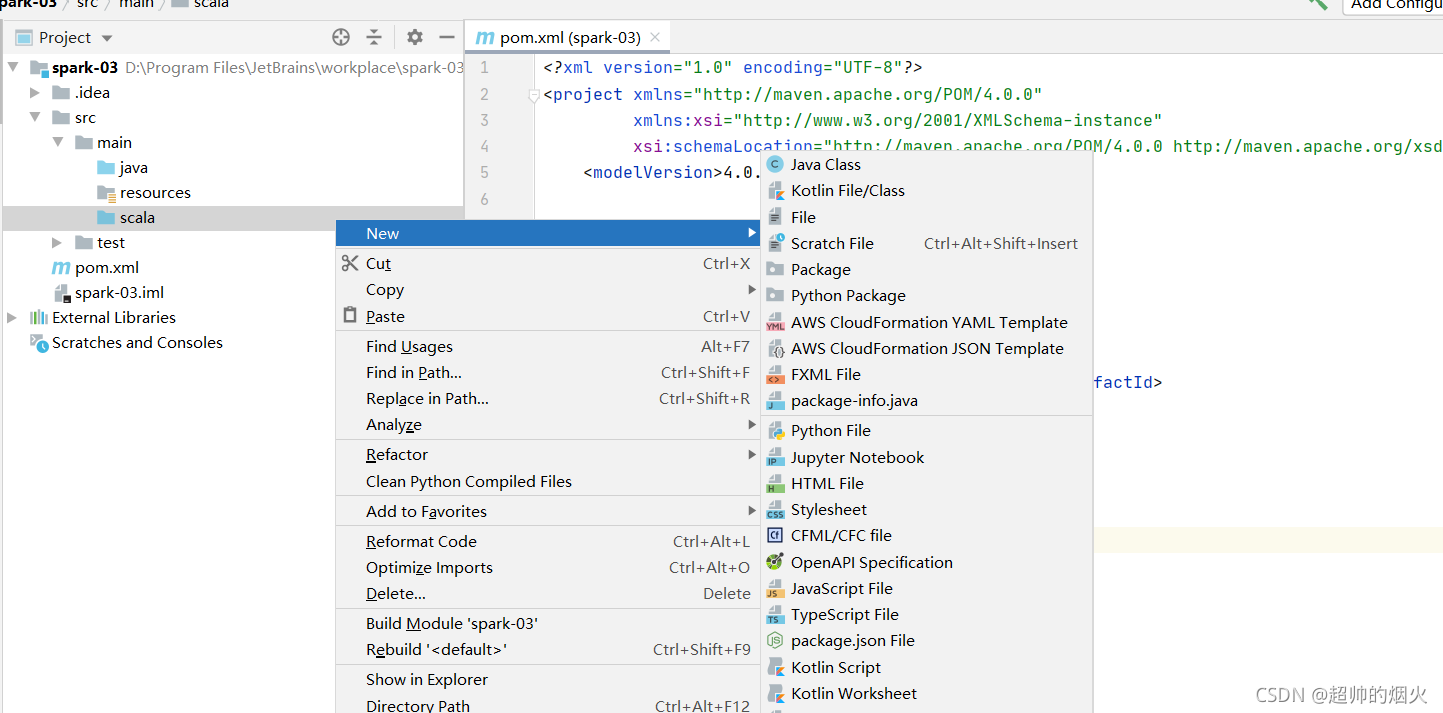
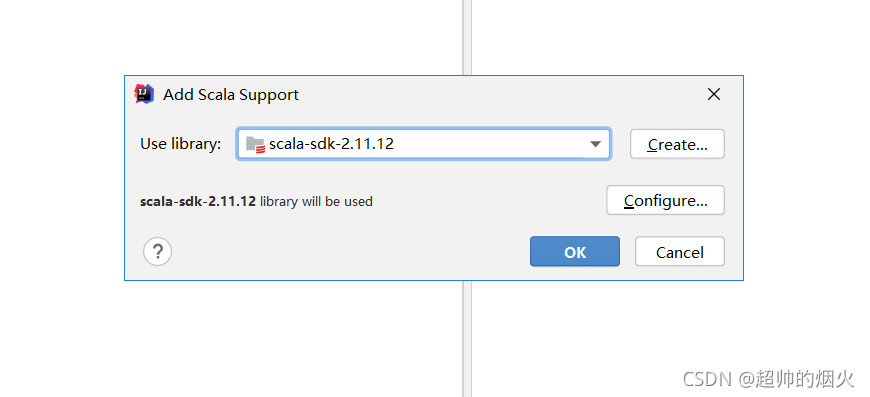
右击fille->project Structure->modules->点击中间列的+号->选择scala->选择版本号2.11.12,再ok
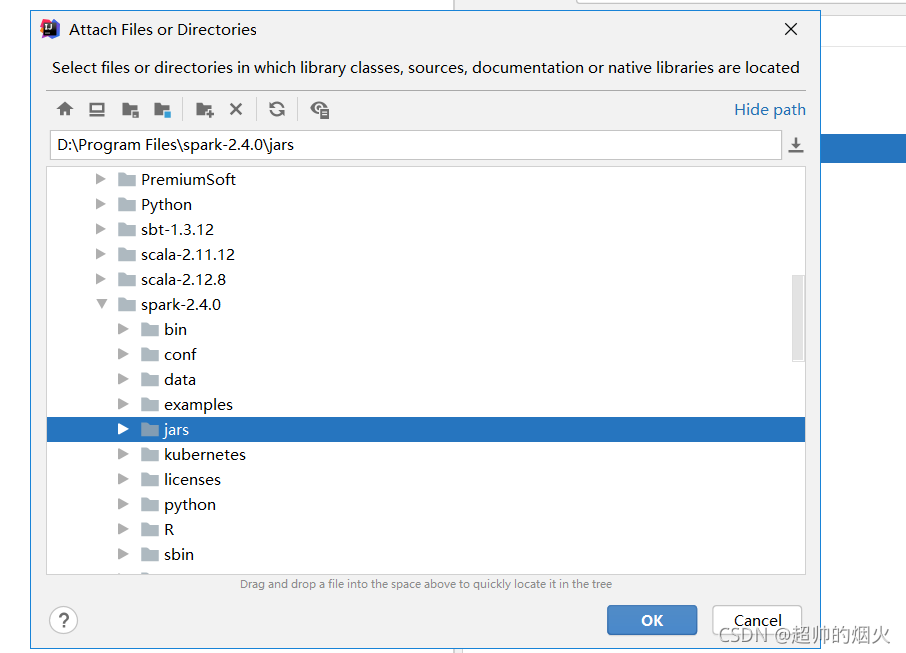
5,导入hadoop,spark的jar包
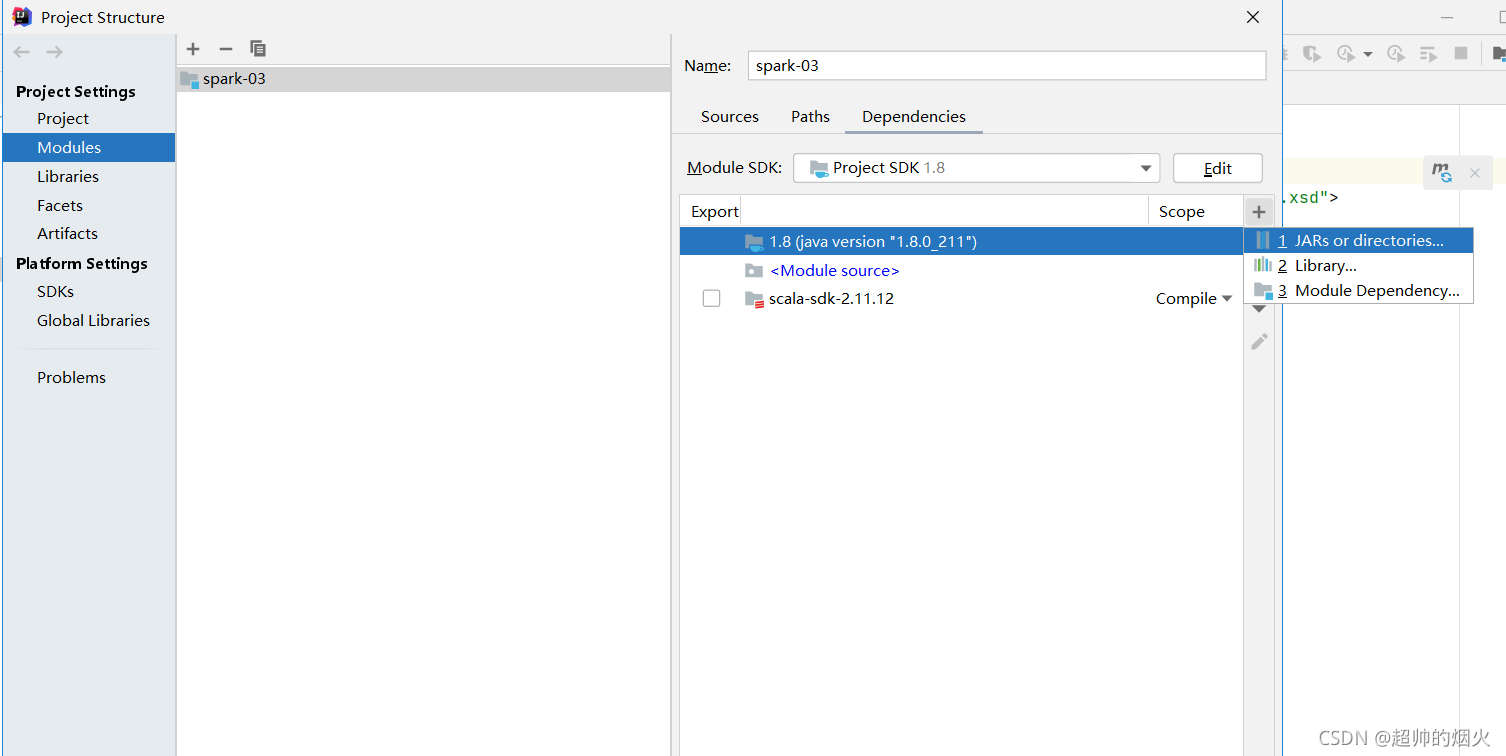
也是刚刚位置
右击fille->project Structure->modules->点击右列的+号->jars or diections->找到hadoop-2.7.0->ok
>点击右列的+号->jars or diections->找到spark-2.4.0下的jars->ok

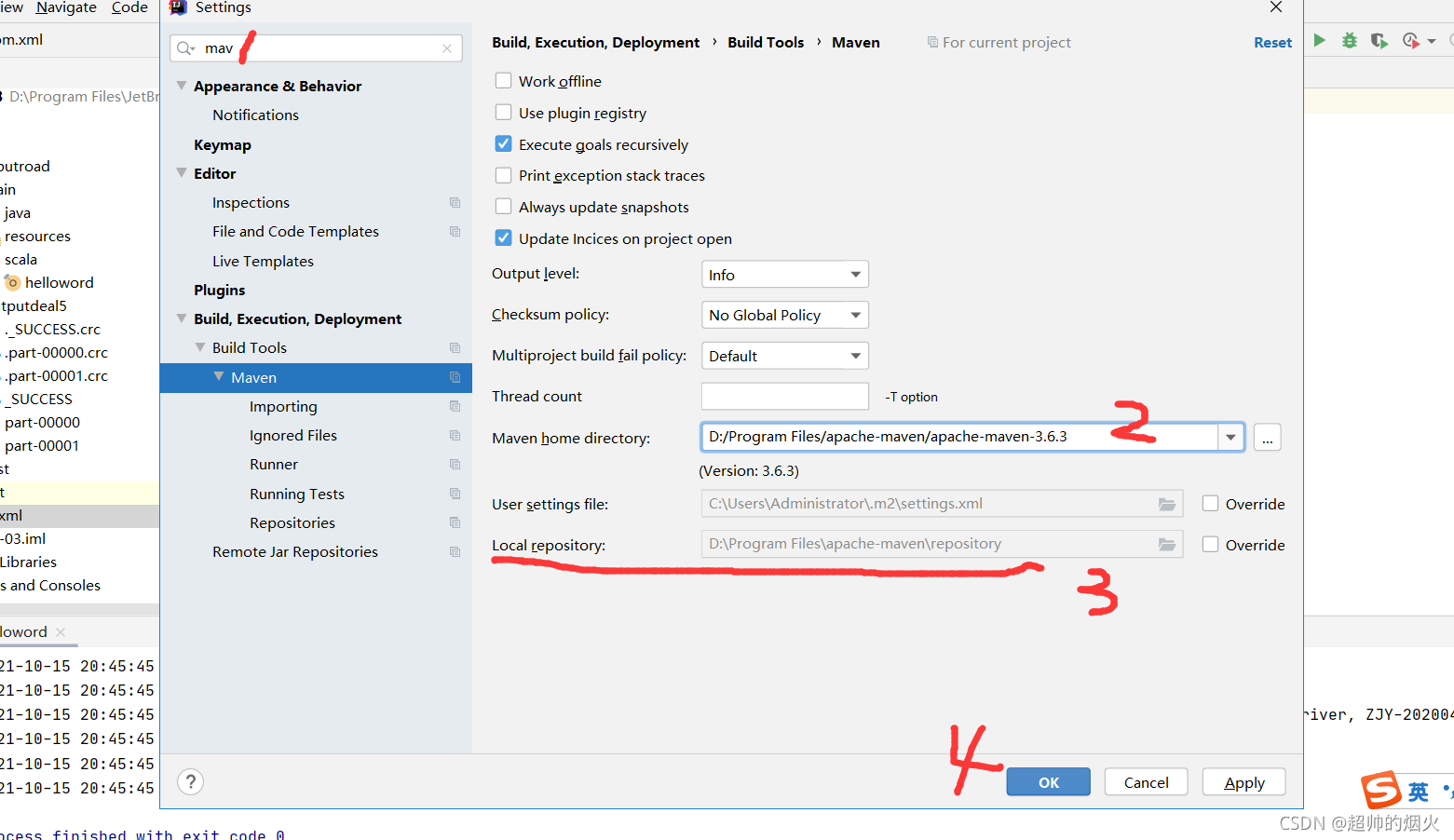
6,更新maven仓库的位置
左击file->左击setting->搜索maven后选中点击maven-> maven home directory:选择自己下载maven的文件夹。->user setting file不动,local repository点击override然后选择自己下载的maven的repository处
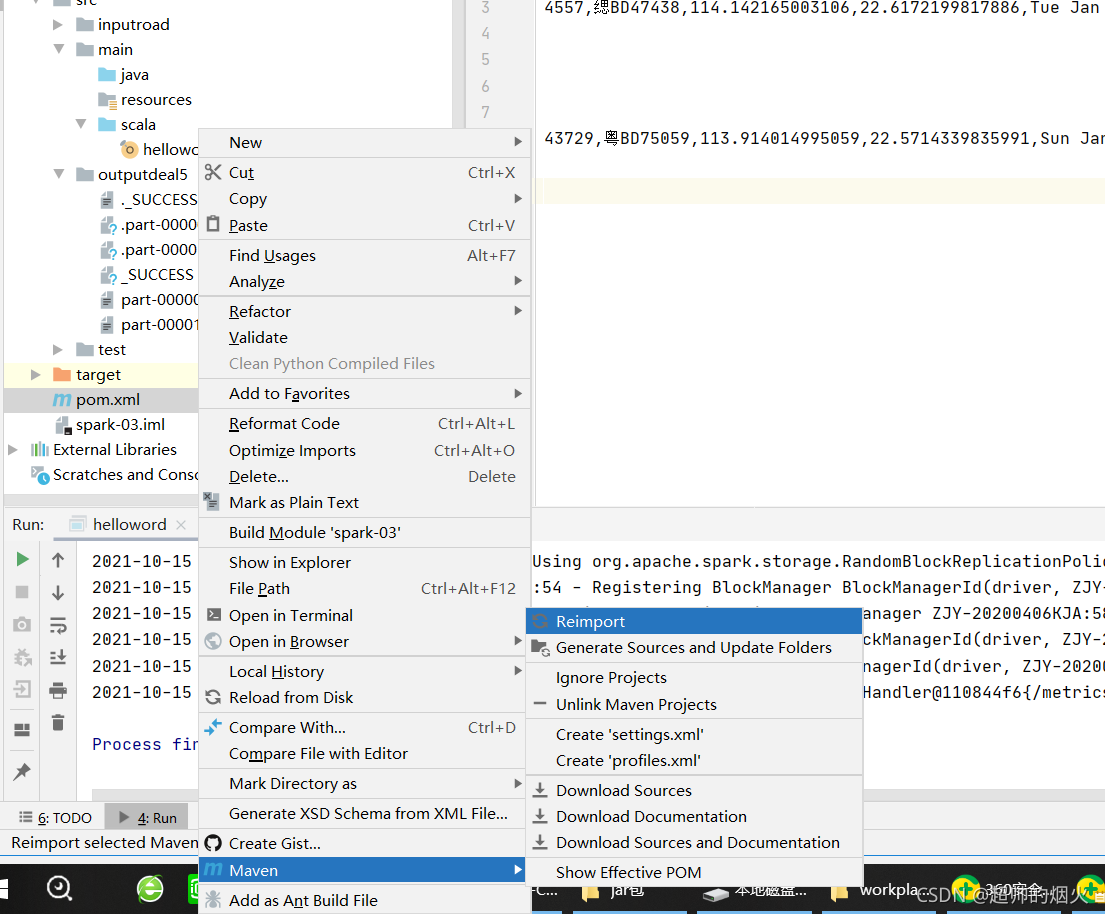
7, 更新pom,右击pom.xml-> maven->reimport
这样就更新重载了。这样环境就弄完了
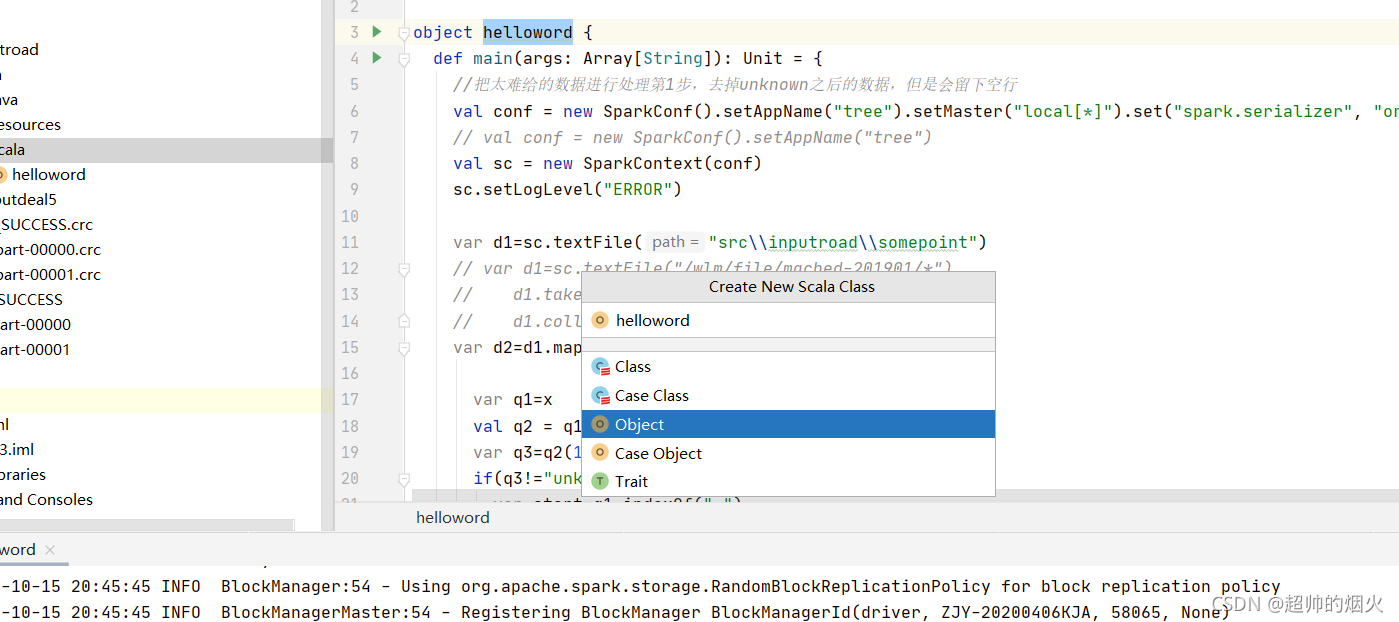
 8,在scala文件夹创建scala文件,文件名helloword,选择object,相当于java main入口函数想运行就的选这个
8,在scala文件夹创建scala文件,文件名helloword,选择object,相当于java main入口函数想运行就的选这个
9,spark项目必备文件头
1,是main 写main就会弹出,点击就可,主函数执行入口
2,本地模式写法,1绿是必备,2绿是名字,随意写,3绿是分配几个core,这样写是有多少core就分配多少core,4绿是序列化用上的,代码出现继承就会用上,先写上。
3,必备
4,可选,可以减少程序运行时候出现一大堆英文。
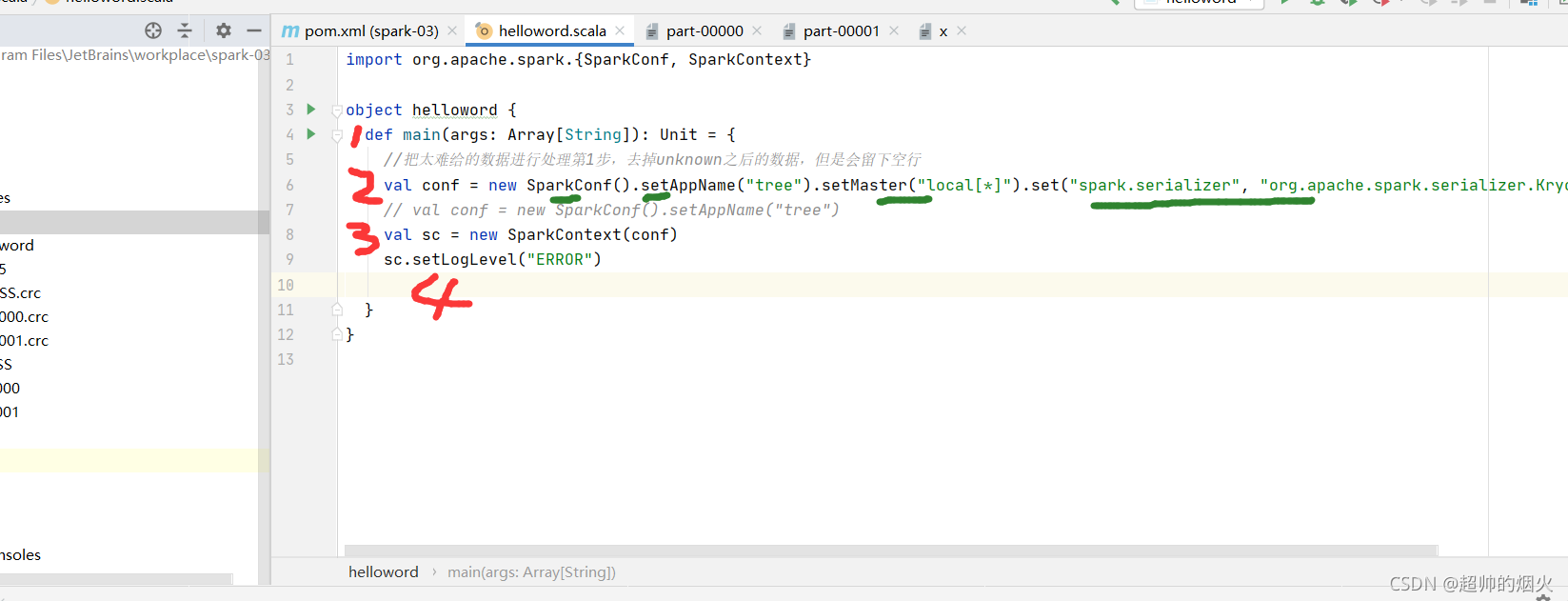
如果在集群上打包运行,这4行就换成
val conf = new SparkConf().setAppName("tree")
val sc = new SparkContext(conf)
就是不指定core数。(外部指定),不指出序列化,不需要管输出太多英文
如果在spark-shell,这两行都不需要,spark-shell已经有了sc对象,不需要再自己创建


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









