




AI时代的新SEO玩法:使用SERP API构建排名追踪系统
前言
在数字化营销的时代,搜索引擎优化(SEO)已经成为网站获得流量和用户的关键策略。然而,仅仅创建优质内容并优化网站是远远不够的——你需要持续监控和追踪你的网站在搜索引擎中的排名表现。
想象一下:你投入了大量时间和精力优化网站,发布了高质量内容,做了外链建设,却不知道这些努力是否真的有效果。你的网站在关键词搜索中排在第几位?竞争对手的表现如何?不同国家和地区的排名是否有差异?移动端和桌面端的搜索结果是否一致?
这就是排名追踪的价值所在。本文我将使用SERP API构建一个 SEO排名追踪系统。
Bright Data SERP API 优势
SERP API是一种程序化接口,允许开发者通过 API 调用获取搜索引擎结果页面数据,而无需手动访问搜索引擎或编写复杂的爬虫程序。Bright Data SERP API可以为你提供高精度、全球覆盖、结构化、稳定的 SERP(搜索结果页)数据采集服务、全面解决跨区域、跨设备排名追踪、分析与监控难题,助力用户帐号业务与行业洞察能力的持续提升。
- 多引擎全球覆盖:支持 Google、Bing、DuckDuckGo、百度、Yandex,195 国/地区,精准至城市级,支持移动/桌面等多设备维度
- 高可用·高并发:99.9%在线 SLA,无并发请求限制,采集速度<1 秒,登记高峰或促销季节也稳定
- 结构化输出:标准 JSON、HTML、Markdown 格式,直接对接报表/分析系统,极大降低数据处理/二次开发成本
- 按成功付费,成本可控:只为成功采集的数据付费,公开透明
- 支持 AI 搜索引擎(ChatGPT、Perplexity 等)采集:覆盖主流和新兴 AI SERP,为 AEO 优化、 AI 智能洞察等前沿应用场景赋能,产品详见
- 专业客户支持+行业敏锐度:API/服务随行业生态和算法变动快速响应升级,保障客户永远第一时间获得最新最全 SERP 数据
- 行业实践验证:大量 SaaS 平台、SEO 工具、全球电商和品牌管理方在高频使用 Bright Data SERP API,支撑业务高速迭代
这也是我选择Bright Data SERP API作为数据主要来源的原因。
构建排名追踪系统
1、系统演示
首演示一下系统最终实现的主要功能。
主页
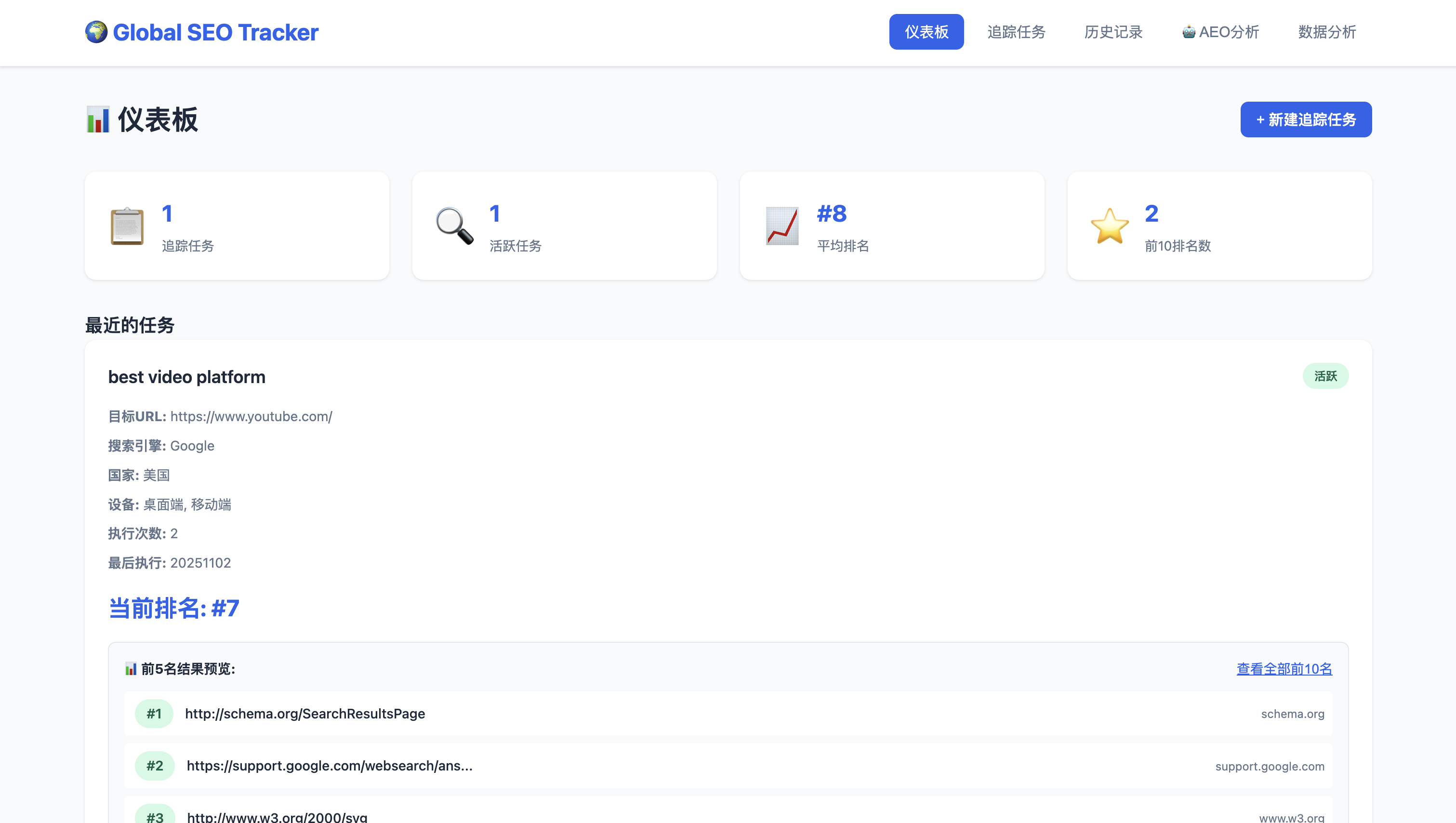
新建追踪任务,设置关键字、目标URL、搜索引擎、地区、设备类型、追踪频率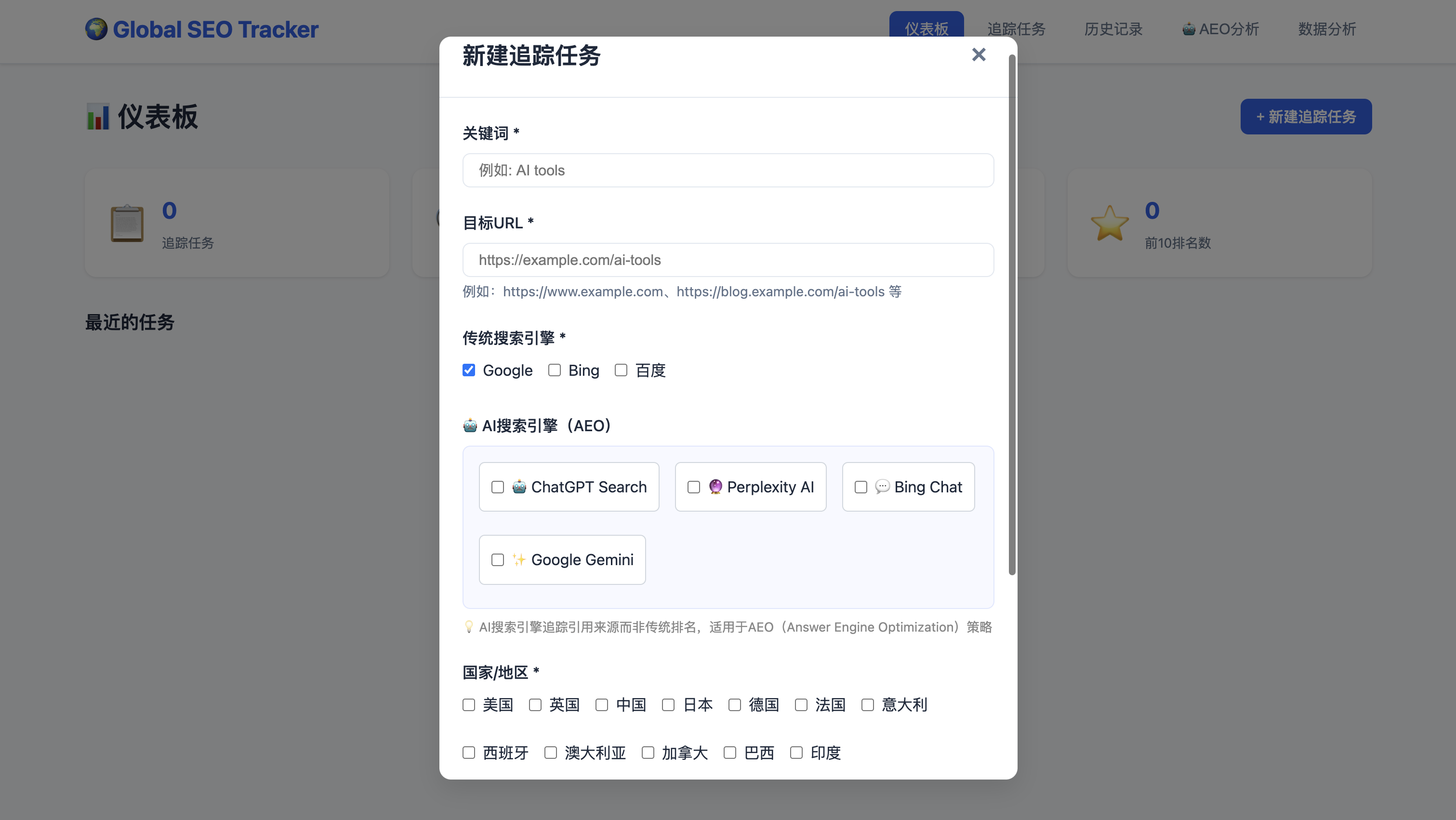
单个任务
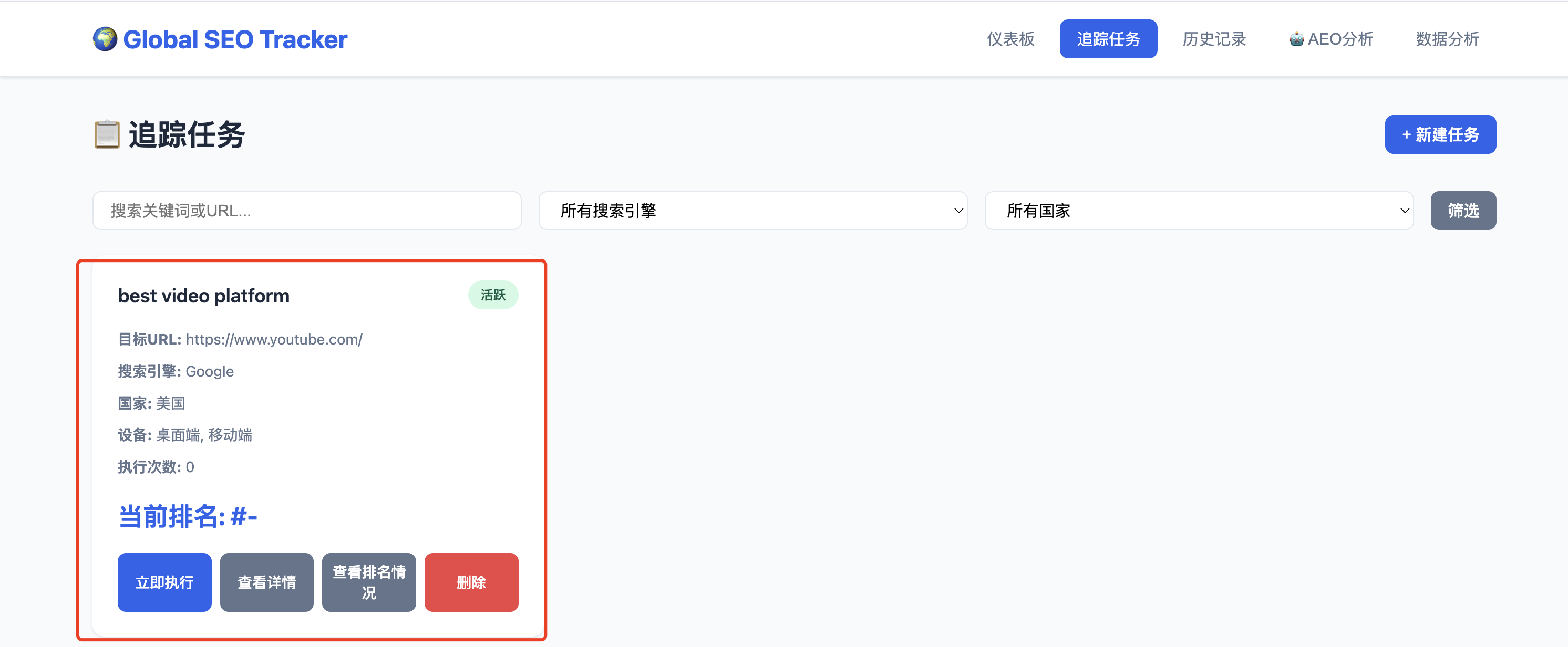
任务完成详情
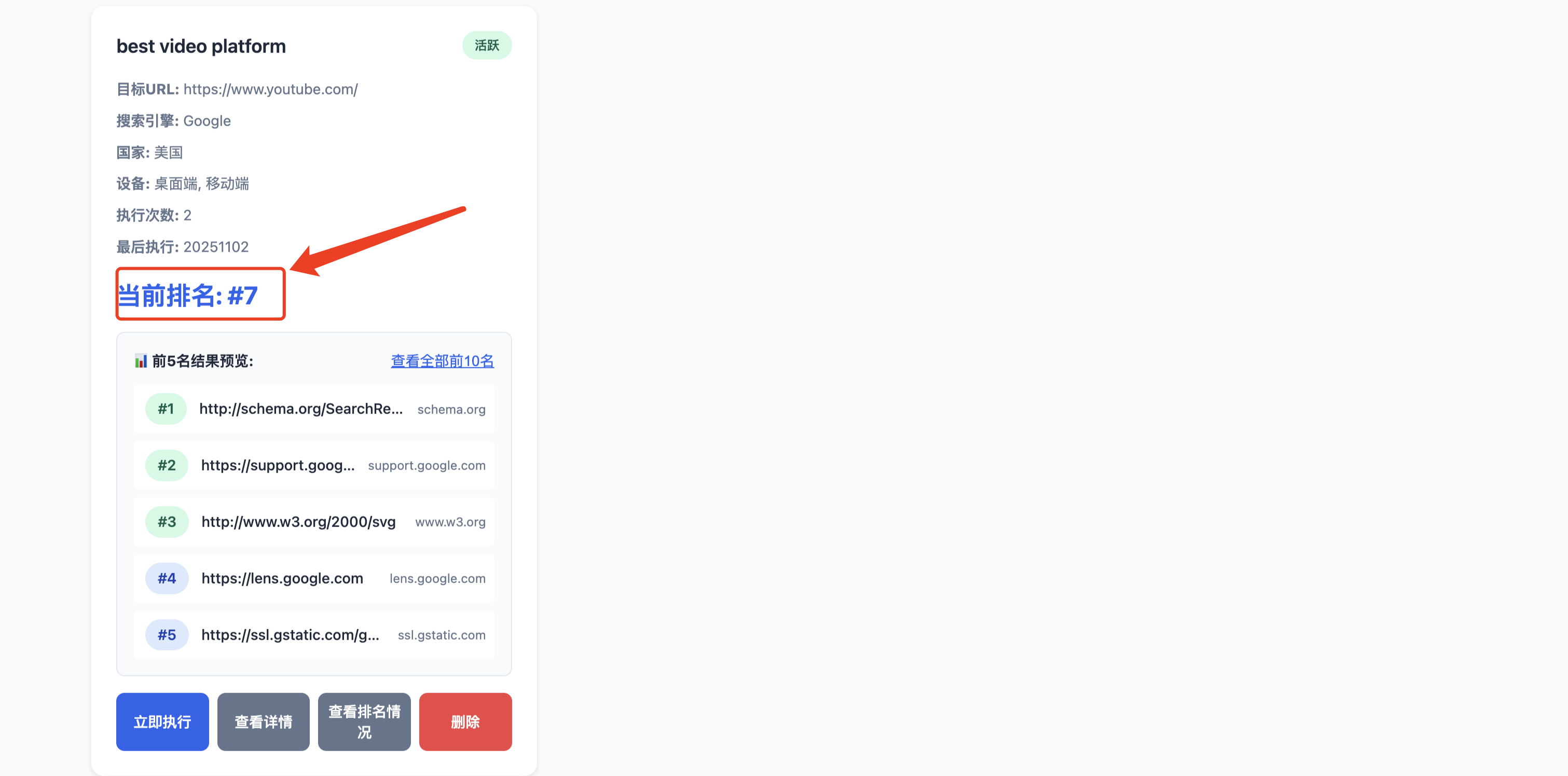
排名数据
2、系统实现
(1)创建SERP API
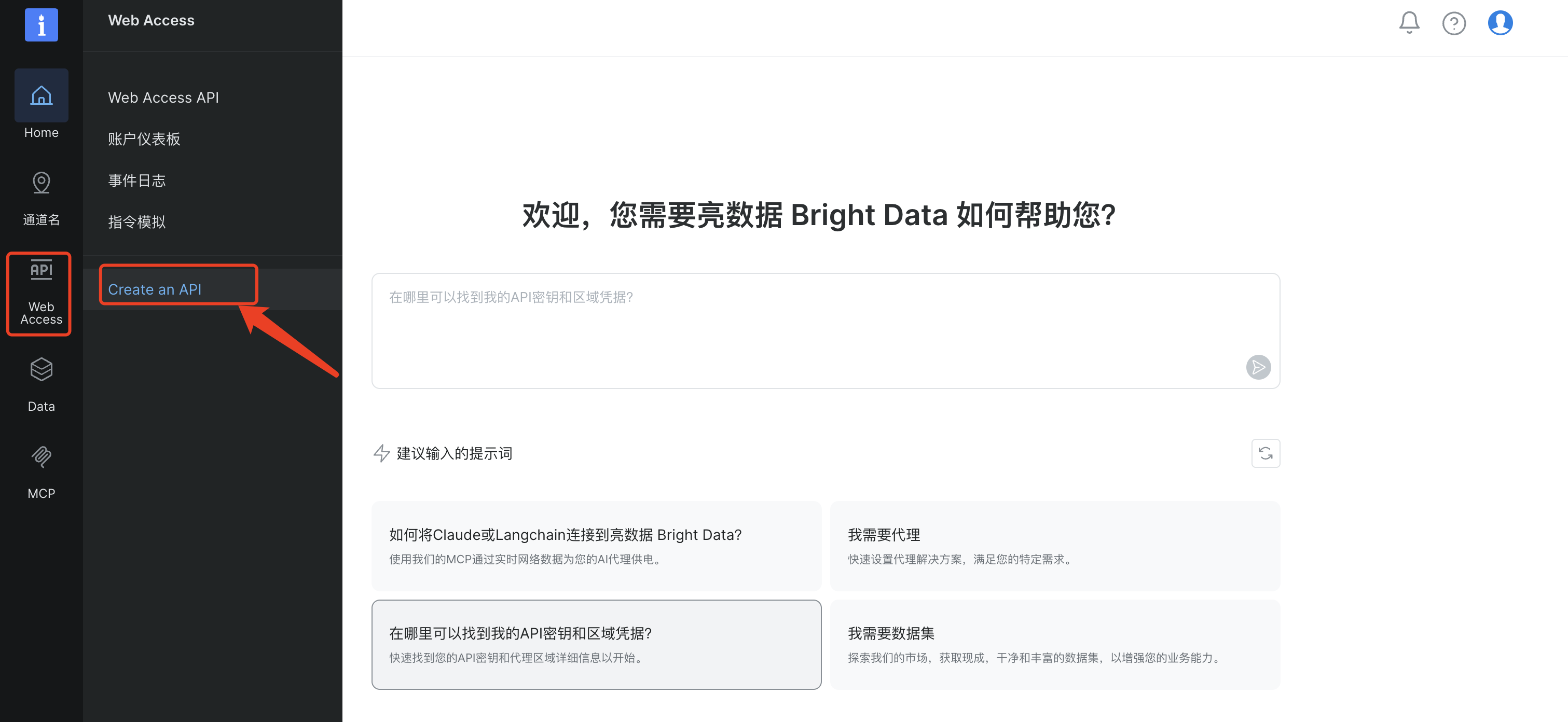
首先我们登录到Bright Data 平台之后,选择“Web Access”菜单中的“Create an API”,
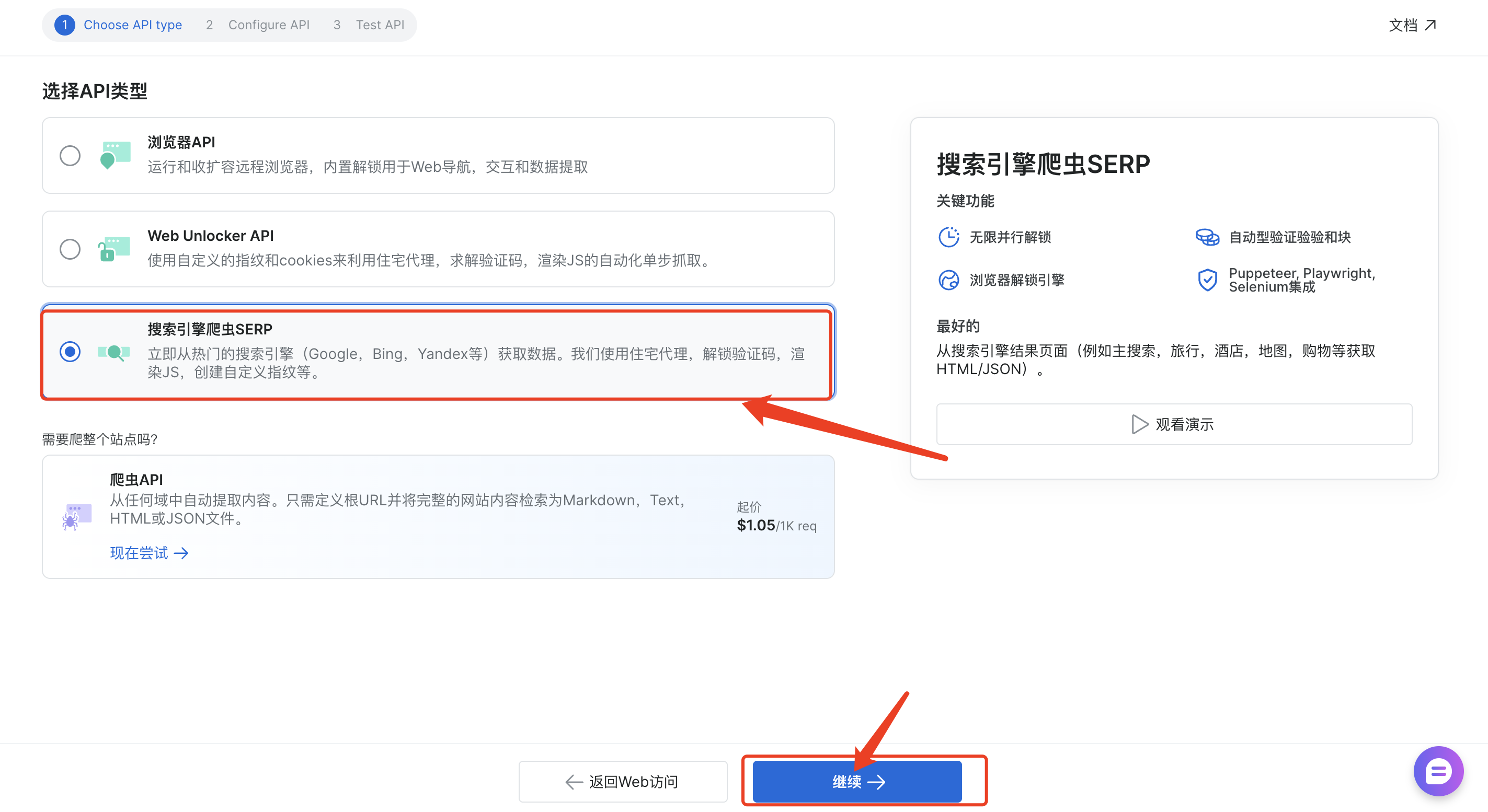
选择API类型为“搜索引擎爬虫SERP”,然后点击“继续”
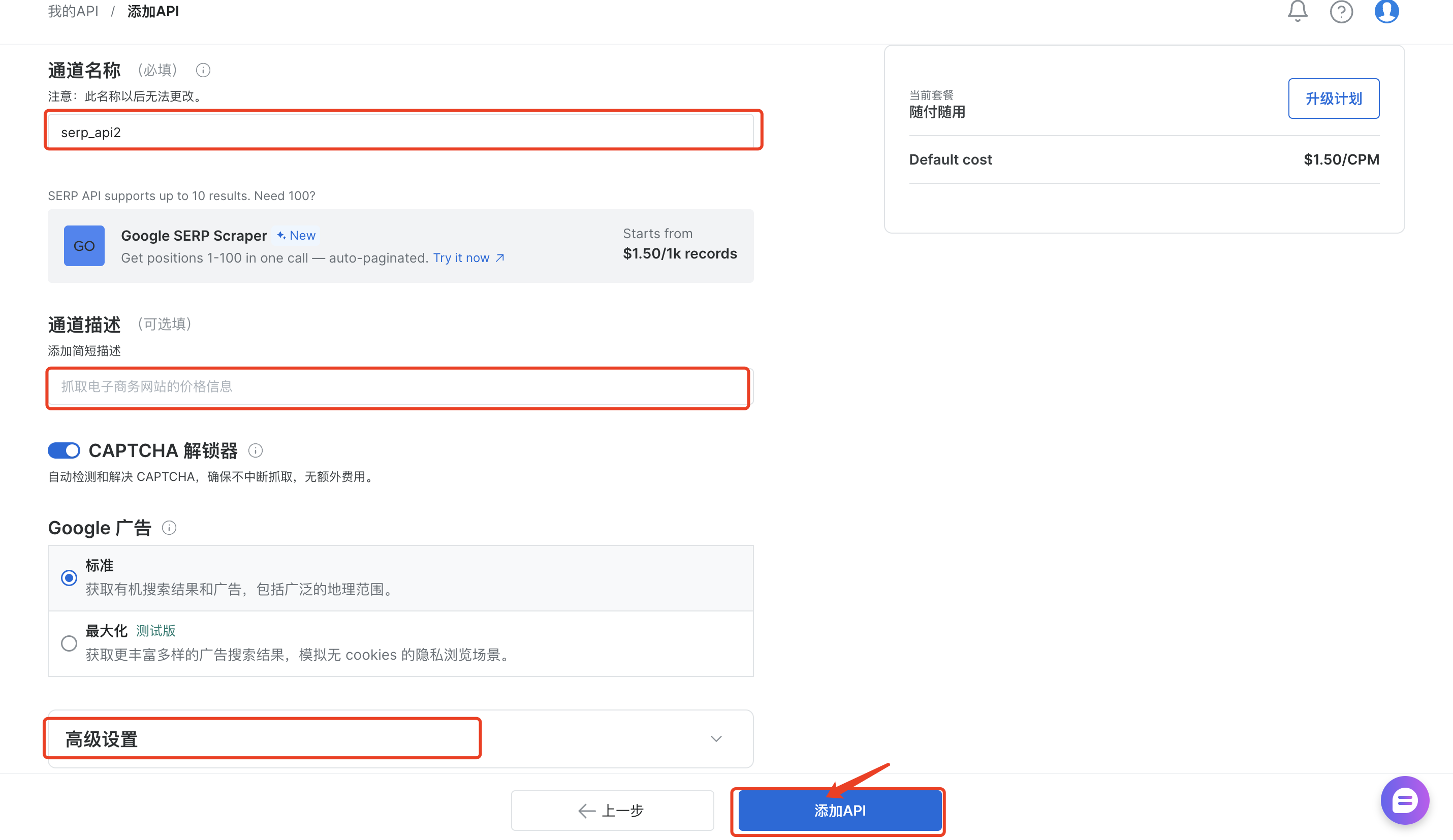
接着修改“通道名称”,添加“通道描述”,也可进行高级设置(自定义头&cookies)、异步请求,设置完成之后,点击下面按钮“添加API”
创建完成之后,直接通过API访问,这里我选择NodeJS语言
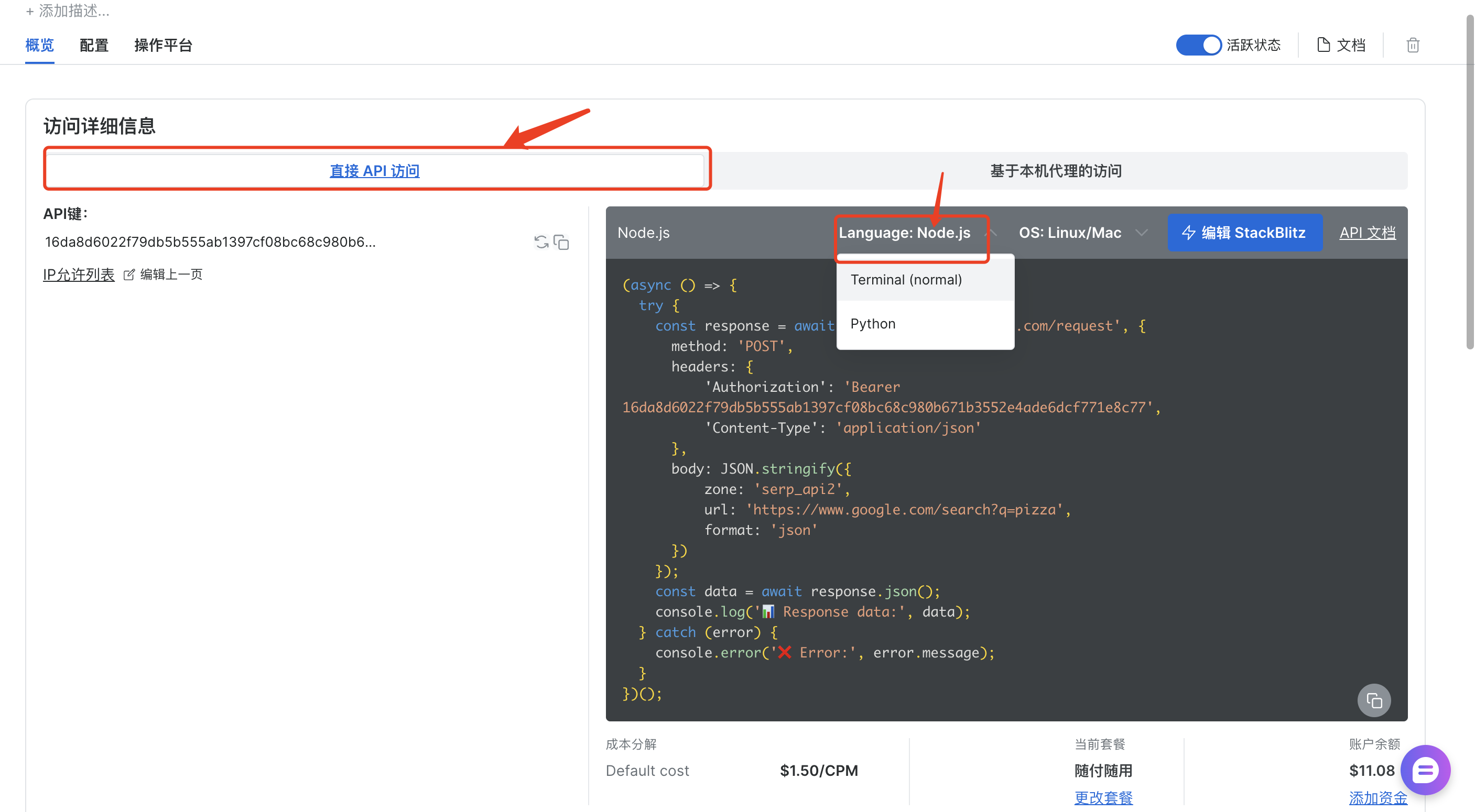
其中https://www.google.com/search?q=pizza&hl=en&gl=us,中的q为关键字、hl为语言、us为地区,另外也可以参考官方的NodeJS案例:
bright-data-serp-api-nodejs-project
在开发工具执行代码,看看是否会执行成功
node ceshii.js最终看到执行成功,说明测试案例是没问题的
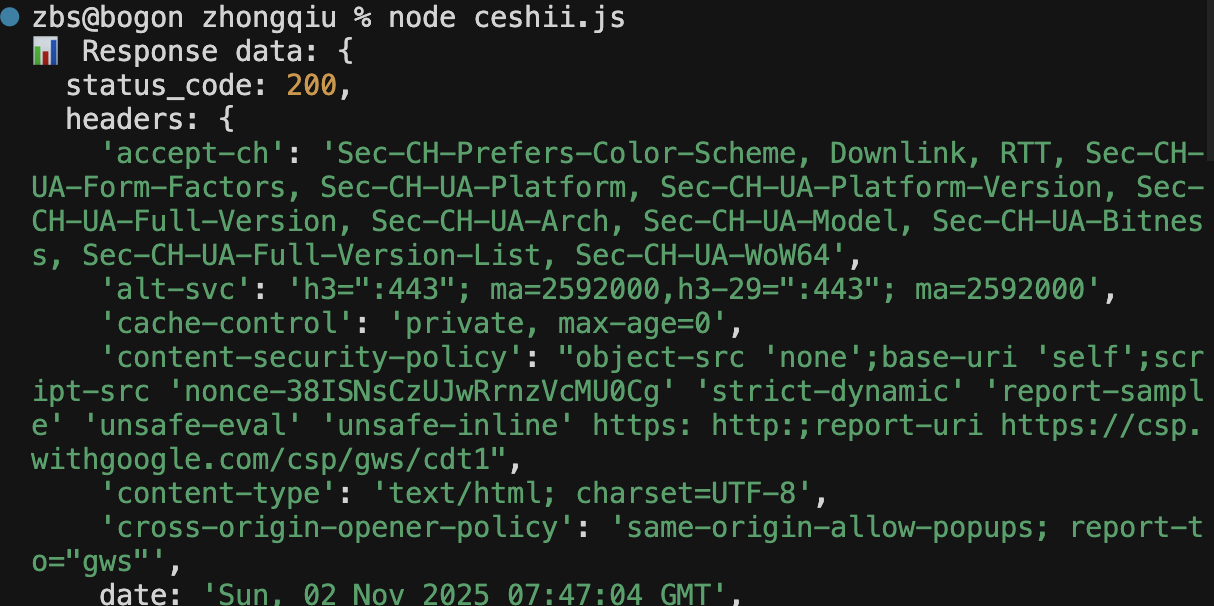
最终看到输出结果,说明脚本是没有问题的。
(2)构建系统
搜索引擎设置,包括传统的Google、百度、Bing以及AI搜索引擎(ChatGPT Search、Perplexity AI、 Bing Chat (Copilot)、Google Gemini)
搜索引擎
// 支持的搜索引擎配置
const SEARCH_ENGINES = {
google: {
name: 'Google',
type: 'traditional',
baseUrl: 'https://www.google.com',
searchUrl: (keyword, country, city, device, language) => {
let url = `https://www.google.com/search?q=${encodeURIComponent(keyword)}`;
if (country) url += `&gl=${country}`;
if (language) url += `&hl=${language}`;
return url;
},
extractResults: extractGoogleResults,
supportedCountries: ['us', 'uk', 'cn', 'jp', 'de', 'fr', 'it', 'es', 'au', 'ca', 'br', 'in']
},
bing: {
name: 'Bing',
type: 'traditional',
baseUrl: 'https://www.bing.com',
searchUrl: (keyword, country, city, device, language) => {
let url = `https://www.bing.com/search?q=${encodeURIComponent(keyword)}`;
if (country) url += `&cc=${country}`;
if (language) url += `&setlang=${language}`;
if (device === 'mobile') url += `&mobile=1`;
return url;
},
extractResults: extractBingResults,
supportedCountries: ['us', 'uk', 'cn', 'jp', 'de', 'fr', 'it', 'es', 'au', 'ca', 'br', 'in']
},
baidu: {
name: '百度',
type: 'traditional',
baseUrl: 'https://www.baidu.com',
searchUrl: (keyword, country, city, device, language) => {
let url = `https://www.baidu.com/s?wd=${encodeURIComponent(keyword)}`;
if (city) url += `&city=${encodeURIComponent(city)}`;
if (device === 'mobile') url += `&from=mob`;
return url;
},
extractResults: extractBaiduResults,
supportedCountries: ['cn']
},
// AI搜索引擎
chatgpt: {
name: 'ChatGPT Search',
type: 'ai',
icon: '🤖',
baseUrl: 'https://chat.openai.com',
searchUrl: (keyword, country, city, device, language) => {
// ChatGPT Search API endpoint (需要实际API)
return `https://chat.openai.com/search?q=${encodeURIComponent(keyword)}`;
},
extractResults: extractAISearchResults,
supportedCountries: ['us', 'uk', 'de', 'fr', 'jp'],
features: {
citationTracking: true, // 引用追踪
answerAnalysis: true, // 答案分析
sourceAttribution: true // 来源归属
}
},
perplexity: {
name: 'Perpleicon: '💬',
baseUrl: 'https://www.bing.com/chat',
searchUrl: (keyword, country, city, device, language) => {
return `https://www.bing.com/chat?q=${encodeURIComponent(keyword)}`;
},
extractResults: extractAISearchResults,
supportedCountries: ['us', 'uk', 'de', 'fr', 'jp', 'cn'],
features: {
citationTracking: true,
answerAnalysis: true,
sourceAttribution: true,
conversationMode: true // 对话模式
}
},
gemini: {
name: 'Google Gemini',
type: 'ai',
icon: '✨',
baseUrl: 'https://gemini.google.com',
searchUrl: (keyword, country, city, device, language) => {
return `https://gemini.google.com/search?q=${encodeURIComponent(keyword)}`;
},
extractResults: extractAISearchResults,
supportedCountries: ['us', 'uk', 'de', 'fr', 'jp'],
features: {
citationTracking: true,
answerAnalysis: true,
sourceAttribution: true,
multimodal: true // 多模态支持
}
}
};
地区设置
// 国家/城市配置
const LOCATIONS = {
us: { name: '美国', language: 'en', cities: ['New York', 'Los Angeles', 'Chicago', 'San Francisco'] },
uk: { name: '英国', language: 'en', cities: ['London', 'Manchester', 'Birmingham', 'Liverpool'] },
cn: { name: '中国', language: 'zh', cities: ['北京', '上海', '广州', '深圳', '杭州'] },
jp: { name: '日本', language: 'ja', cities: ['东京', '大阪', '京都', '横滨'] },
de: { name: '德国', language: 'de', cities: ['Berlin', 'Munich', 'Frankfurt', 'Hamburg'] },
fr: { name: '法国', language: 'fr', cities: ['Paris', 'Lyon', 'Marseille', 'Toulouse'] },
it: { name: '意大利', language: 'it', cities: ['Rome', 'Milan', 'Naples', 'Turin'] },
es: { name: '西班牙', language: 'es', cities: ['Madrid', 'Barcelona', 'Valencia', 'Seville'] },
au: { name: '澳大利亚', language: 'en', cities: ['Sydney', 'Melbourne', 'Brisbane', 'Perth'] },
ca: { name: '加拿大', language: 'en', cities: ['Toronto', 'Vancouver', 'Montreal', 'Calgary'] },
br: { name: '巴西', language: 'pt', cities: ['São Paulo', 'Rio de Janeiro', 'Brasília', 'Salvador'] },
in: { name: '印度', language: 'en', cities: ['Mumbai', 'Delhi', 'Bangalore', 'Hyderabad'] }
};设备类型
// 设备类型
const DEVICES = {
desktop: { name: '桌面端', userAgent: 'desktop' },
mobile: { name: '移动端', userAgent: 'mobile' },
tablet: { name: '平板', userAgent: 'tablet' }
};通过SERP获取搜索结果数据
// 获取搜索结果
async fetchSearchResults(engine, keyword, country, city, device, language) {
try {
// 搜索引擎URL已经包含了设备参数(如Google的&tbm=mbl,Bing的&mobile=1等)
const url = engine.searchUrl(keyword, country, city, device, language);
// Bright Data API 只支持基本参数:zone, url, format
const response = await fetch('https://api.brightdata.com/request', {
method: 'POST',
headers: {
'Authorization': BRIGHT_DATA_API_KEY,
'Content-Type': 'application/json'
},
body: JSON.stringify({
zone: 'serp_api1',
url: url,
format: 'json'
})
});
if (!response.ok) {
throw new Error(`HTTP ${response.status}: ${response.statusText}`);
}
const data = await response.json();
if (!data.body || typeof data.body !== 'string') {
throw new Error('无效的响应格式');
}
return engine.extractResults(data.body, keyword);
} catch (error) {
console.error(`获取搜索结果失败: ${error.message}`);
return null;
}
}
获取排名
const searchResults = await this.fetchSearchResults(
engine,
task.keyword,
country,
null,
device,
location.language
);
if (searchResults) {
const rank = this.findUrlRank(searchResults, task.targetUrl);
const result = {
taskId: task.id,
engine: engineKey,
country: country,
city: null,
device: device,
keyword: task.keyword,
targetUrl: task.targetUrl,
rank: rank,
totalResults: searchResults.length,
timestamp: new Date().toISOString(),
top10: searchResults.slice(0, 10).map(r => ({
rank: r.rank,
title: r.title,
url: r.url,
domain: r.domain
}))
};
results.push(result);
(3)系统操作
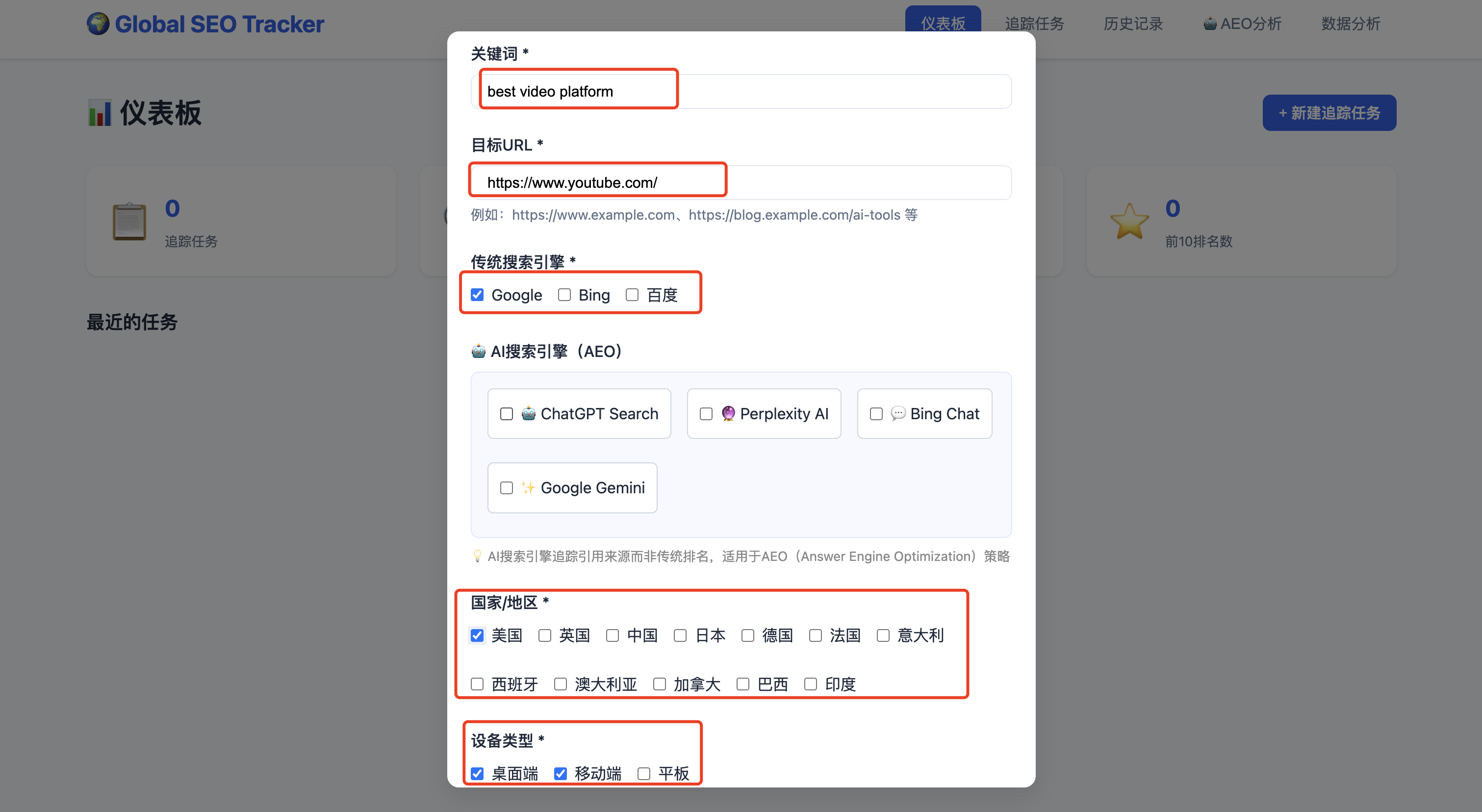
新建追踪任务,填写弹框中的信息
关键字:best video platform
目标URL:https://www.youtube.com/
搜索引擎:Google
地区:美国
设备:桌面端
随后点击确定,新建任务
任务创建成功之后,生成任务记录
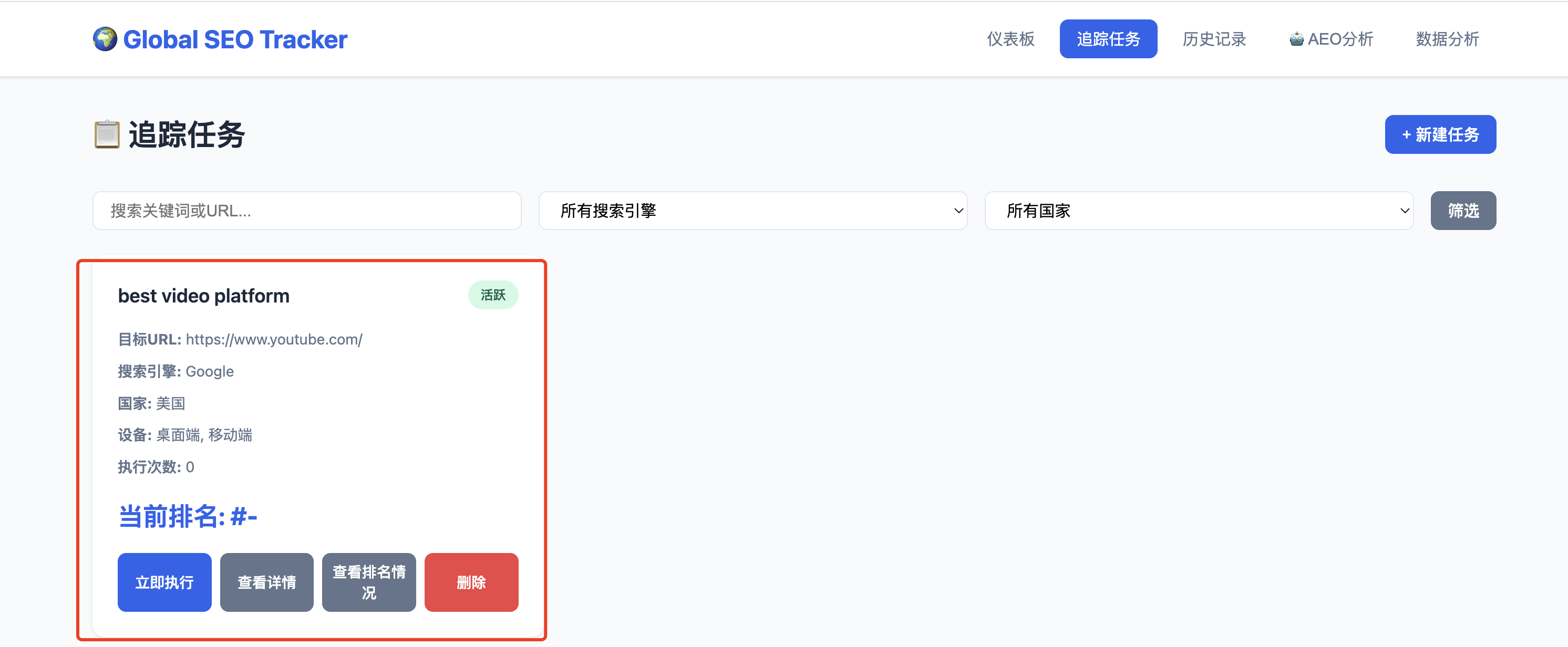
点击“立即执行”之后,获取到排名结果,任务执行完成之后会有下面提示
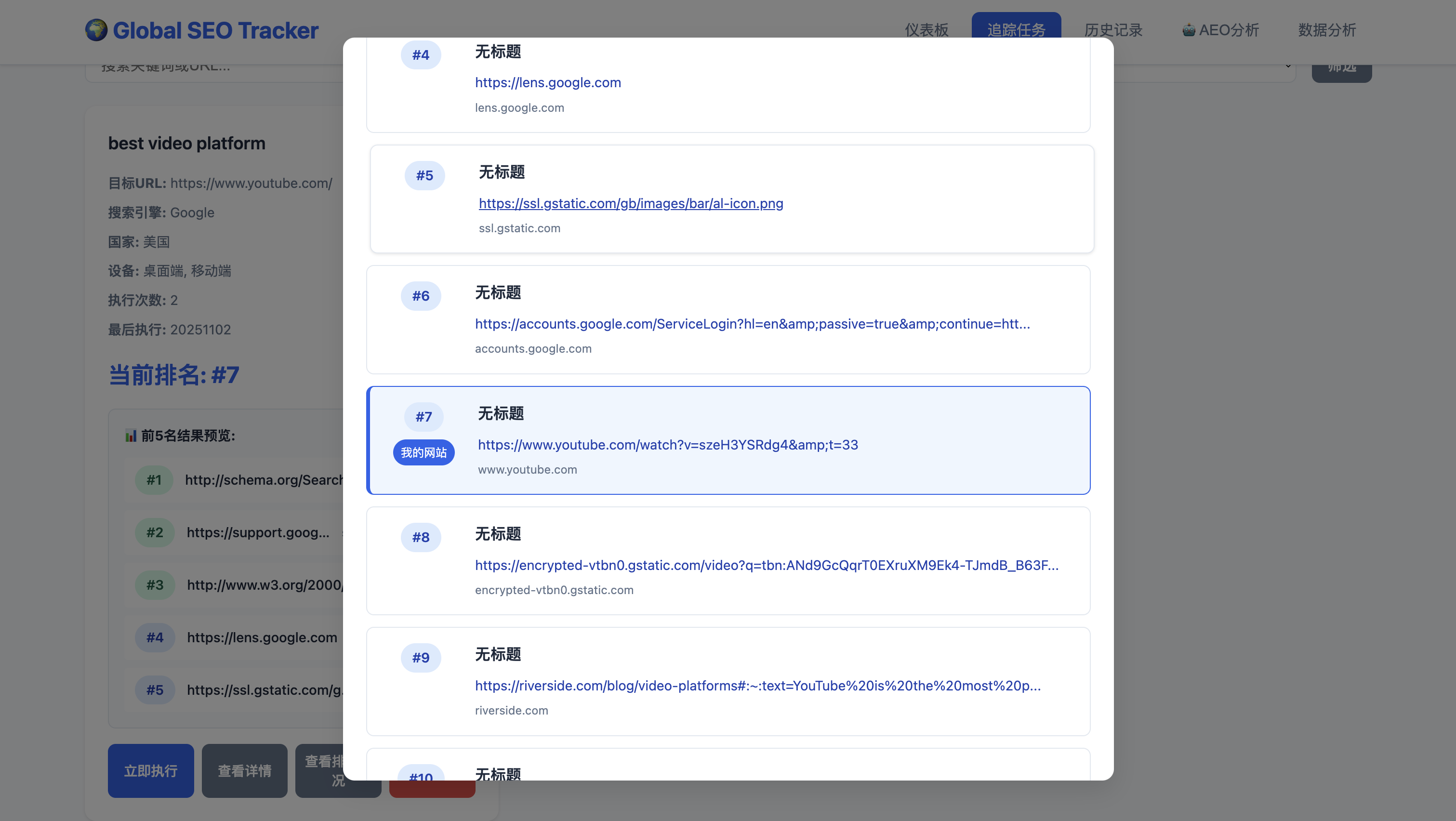
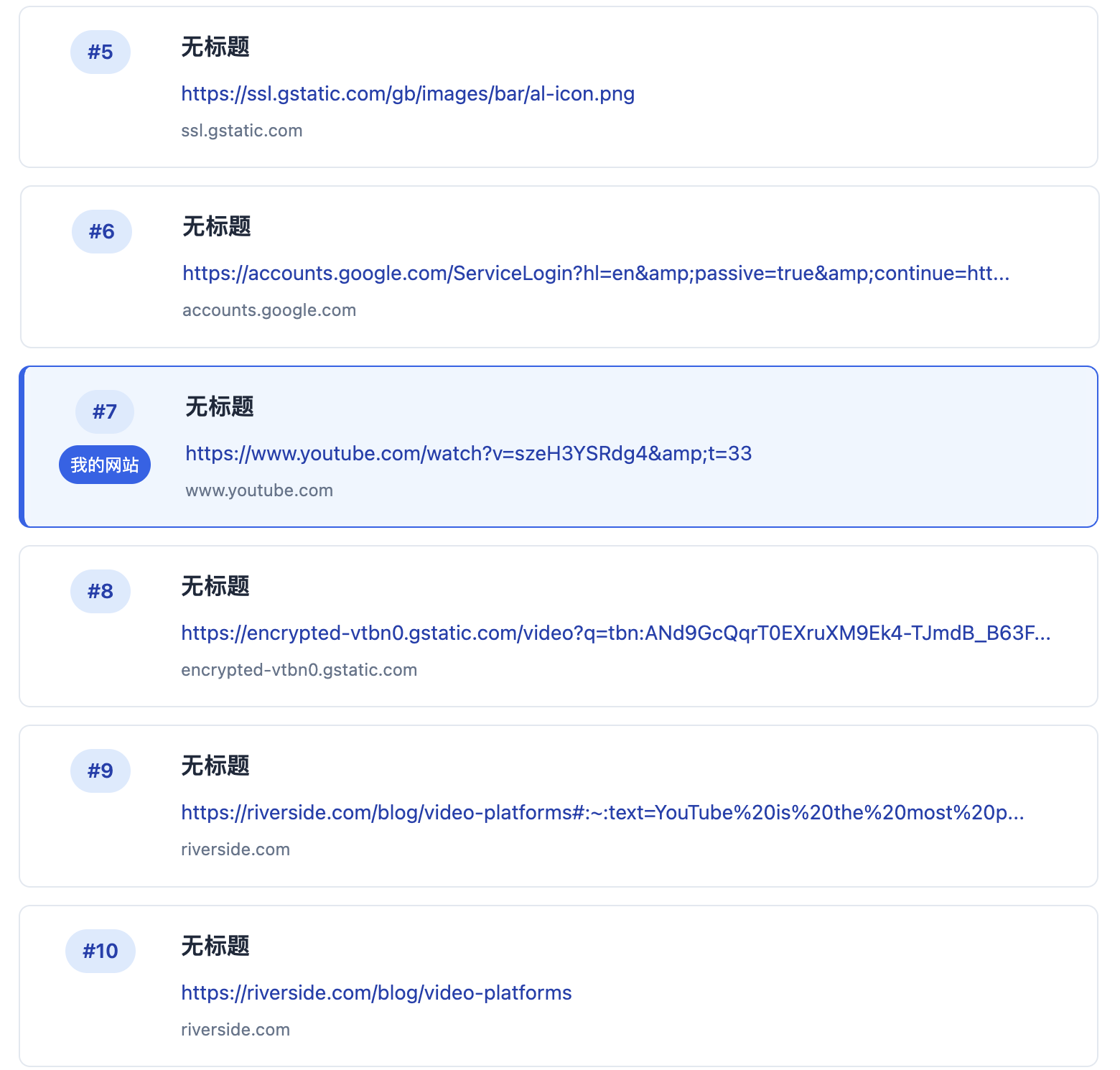
可以看到目标URL在美国地区通过关键字best video platform搜索在Google搜索引擎中排名第7
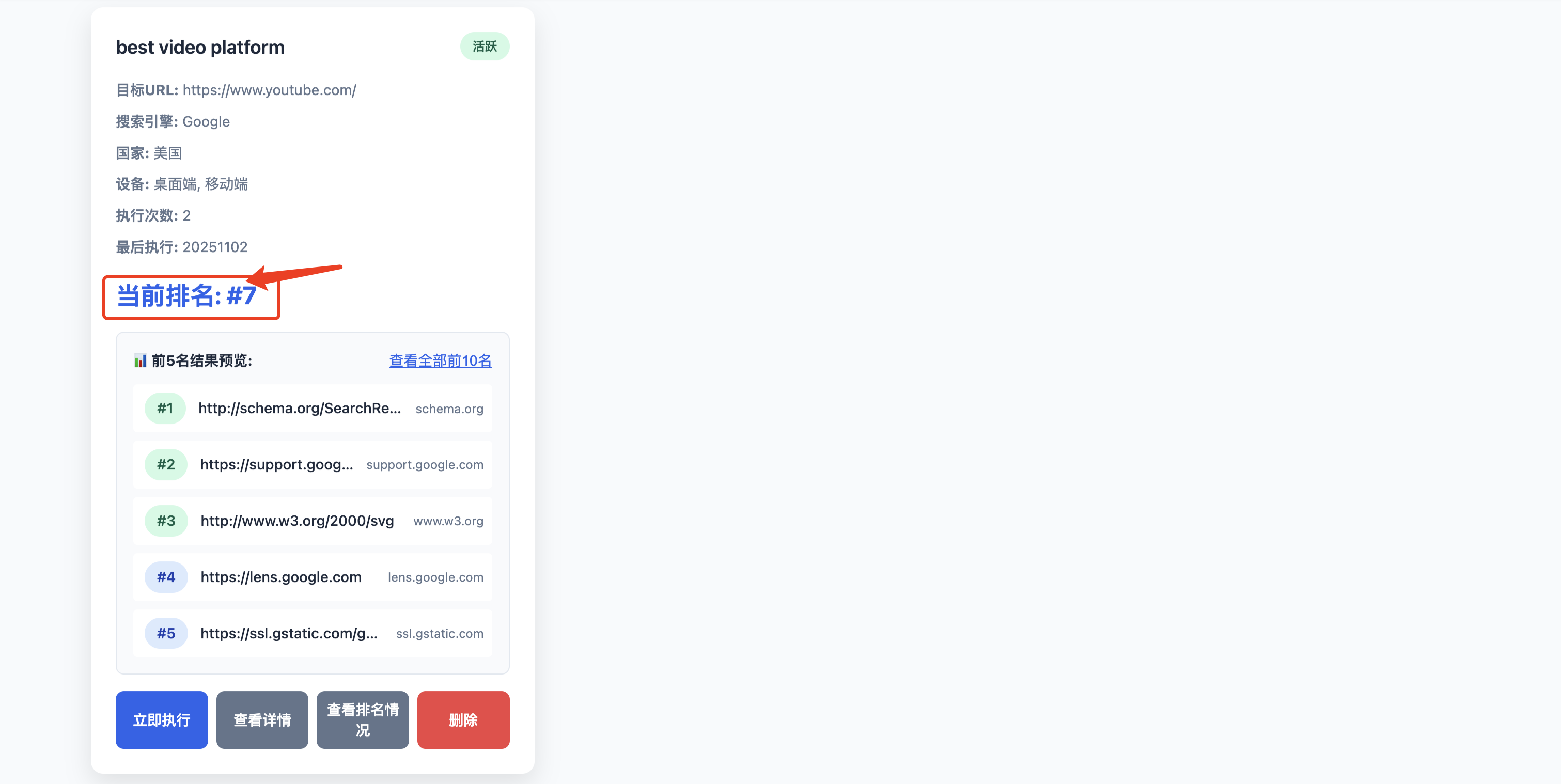
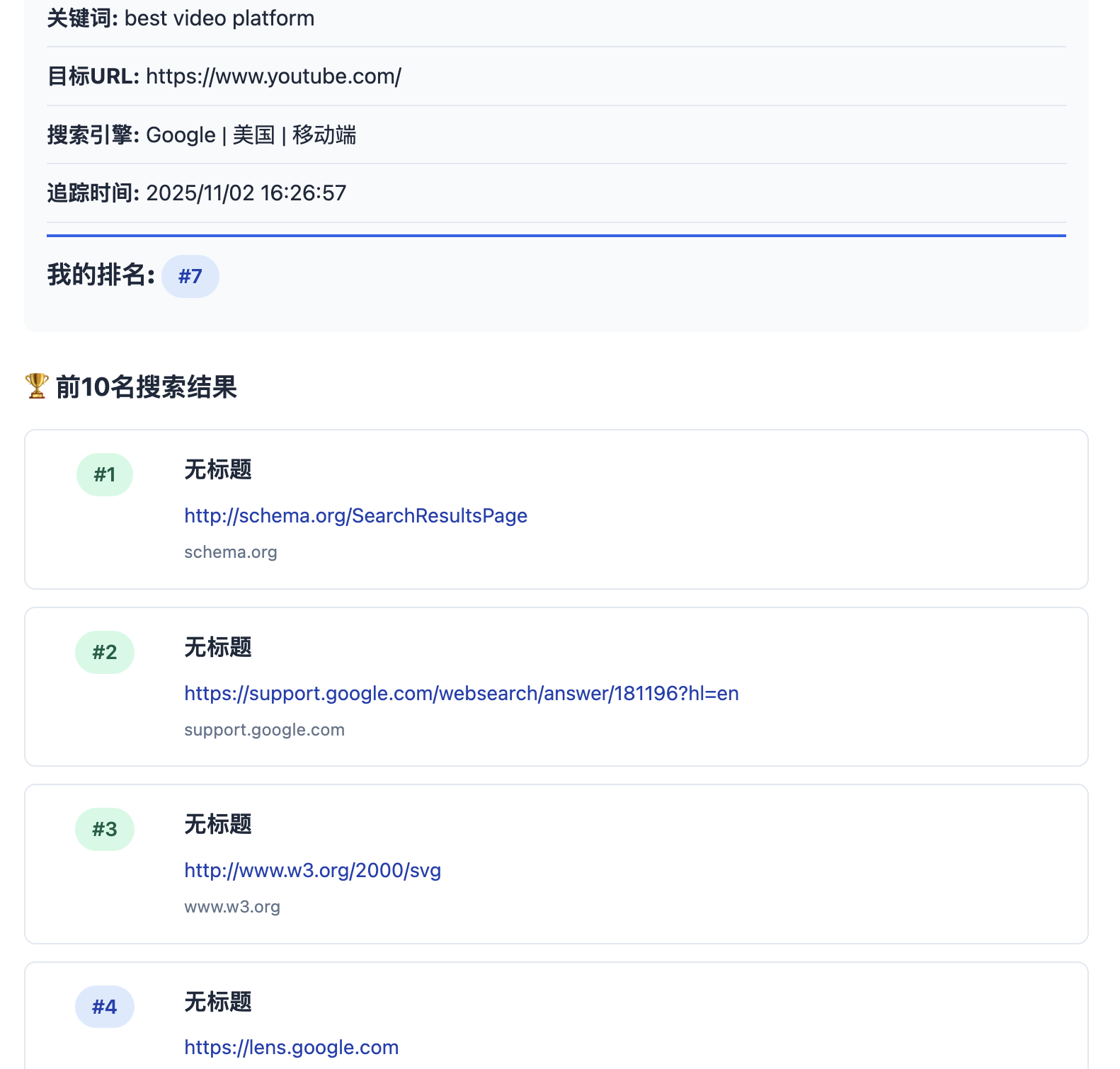
查看一下前10的URL有哪些网站
Bright Data SERP API解决哪些问题
在构建系统过程中,Bright Data表现出其强大的功能
- 全球多地区、多设备的排名数据采集,对地理定位和设备识别非常精确
- 数据采集过程中非常稳定、抗封禁能力也很强,保障大规模持续采集的高可用性
- 支持多个搜索引擎,设置包括 AI 搜索引擎
- 高并发场景下也能快速采集数据,并不会受到很大影响

最后
SEO排名追踪是SEO策略的重要组成部分。通过系统化的追踪、准确了解优化成果识别问题和改进方向、掌握市场动态、基于真实数据优化。通过使用Bright Data SERP API可以追踪全球地区,多种设备类型以及多种搜索引擎,还能进行持续监控。当然SEO排名追踪不是目的,而是手段。真正的目标是通过追踪数据,持续优化你的网站,提升搜索排名,获得更多流量和用户。
源码
githup地址:https://github.com/zbsguilai/seo-tracker.git
注意:代码中的BRIGHT_DATA_API_KEY、DEEPSEEK_API_KEY需要替换成自己的key。
const BRIGHT_DATA_API_KEY = 'Bearer xxxxx';
const DEEPSEEK_API_KEY = 'sk-xxxx';

















 619
619


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










