






分布式调度系统设计文档
目标与需求
项目目前主要使用xxljob做分布式调度, 但是它不太适合税务的系统, 因为税务每次跑定时任务的时候,有一大批企业都需要跑, 而xxljob,只能控制触发,不能控制多个节点,各自负责哪些企业, 不能最大化利用系统资源,而且还导致必须大量加锁,所以本次需要去掉xxljob,改为自己开发
-
最大化利用系统资源
-
节点注册,主备切换,主节点死机,备节点自动升级
-
主节点分配企业偏移量,备节点执行任务
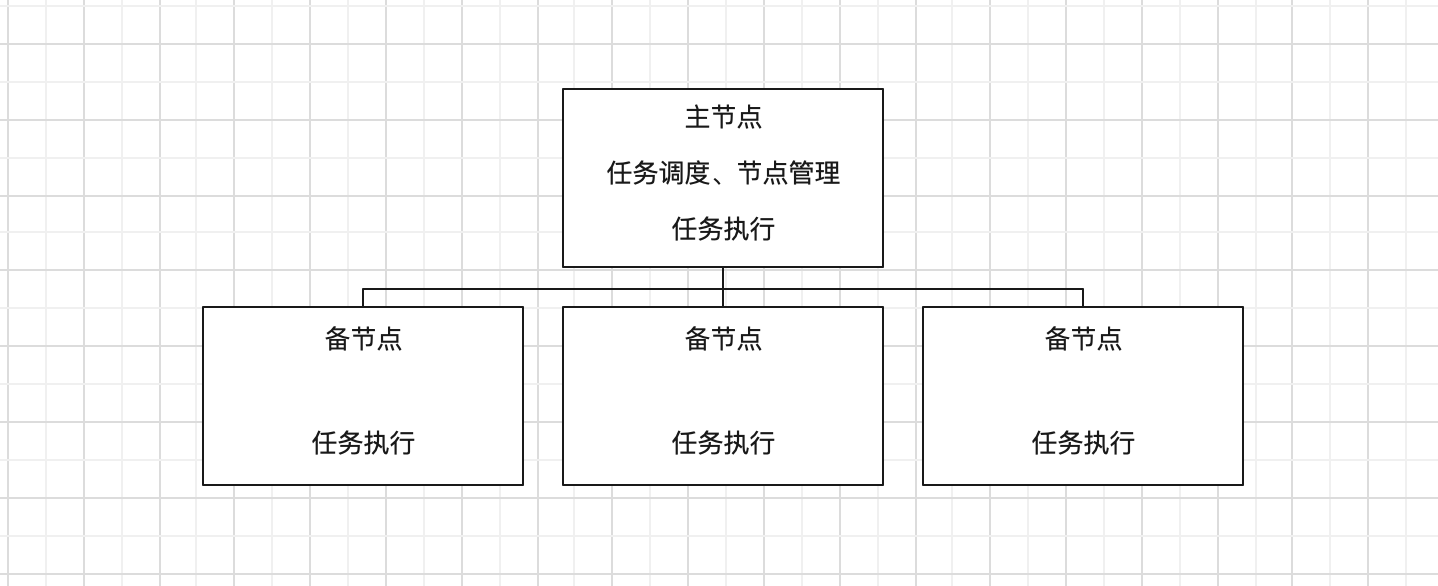
架构概述
我们采用主备架构设计,主节点负责任务的注册和分配,同时也负责执行任务,备节点只负责任务的执行。主节点和备节点之间通过心跳机制保持通信,以便实时监控节点状态。
任务分为账套表任务、税局账号信息表任务和普通任务。
定时任务最小粒度为1秒
数据库设计
job_config:定时任务配置表
字段:
| 字段 | 说明 | 类型 |
|---|---|---|
| id | 主键 | int |
| job_handler | 调度任务 | varchar |
| job_name | 任务名称 | varchar |
| schedule_type | 调度类型(1-固定速度,2-cron表达式),如果执行频繁需要使用固定速度,固定速度是秒为单位 | tinyint |
| schedule_conf | 调度配置,值含义取决于调度类型 | varchar |
| type | 任务类型(NORMAL-普通任务,SYS_COMPANY-企业表任务,BASIC_TAX_BUREAU_LOGIN-税局表任务) | varchar |
| route_policy | 路由策略(1-单点执行,2-分片广播) | tinyint |
| trigger_last_time | 上次调度时间 | datetime |
| trigger_status | 调度状态:0-停止,1-运行 | tinyint |
job_log:定时任务运行记录表
字段:
| 字段 | 说明 | 类型 |
|---|---|---|
| id | 主键 | bigint |
| job_id | 任务id | int |
| executor_time | 任务发送到节点的时间 | datetime |
| executor_node_ip | 执行任务的节点IP | varchar |
| offset_start | 偏移量开始 | int |
| offset_end | 偏移量结束 | int |
| handle_result | 任务发送结果(0-失败,1-成功) | tinyint |
| executor_result | 任务执行结果(0-失败,1-成功,2,执行中) | tinyint |
job_exe_now_config:手动执行一次配置表
| 字段 | 说明 | 类型 |
|---|---|---|
| ID | 主键 | int |
| job_id | 任务id | int |
| param | 执行时传递的参数 | text |
| status | 可执行状态(0-已执行,1-待执行) | tinyint |
流程逻辑
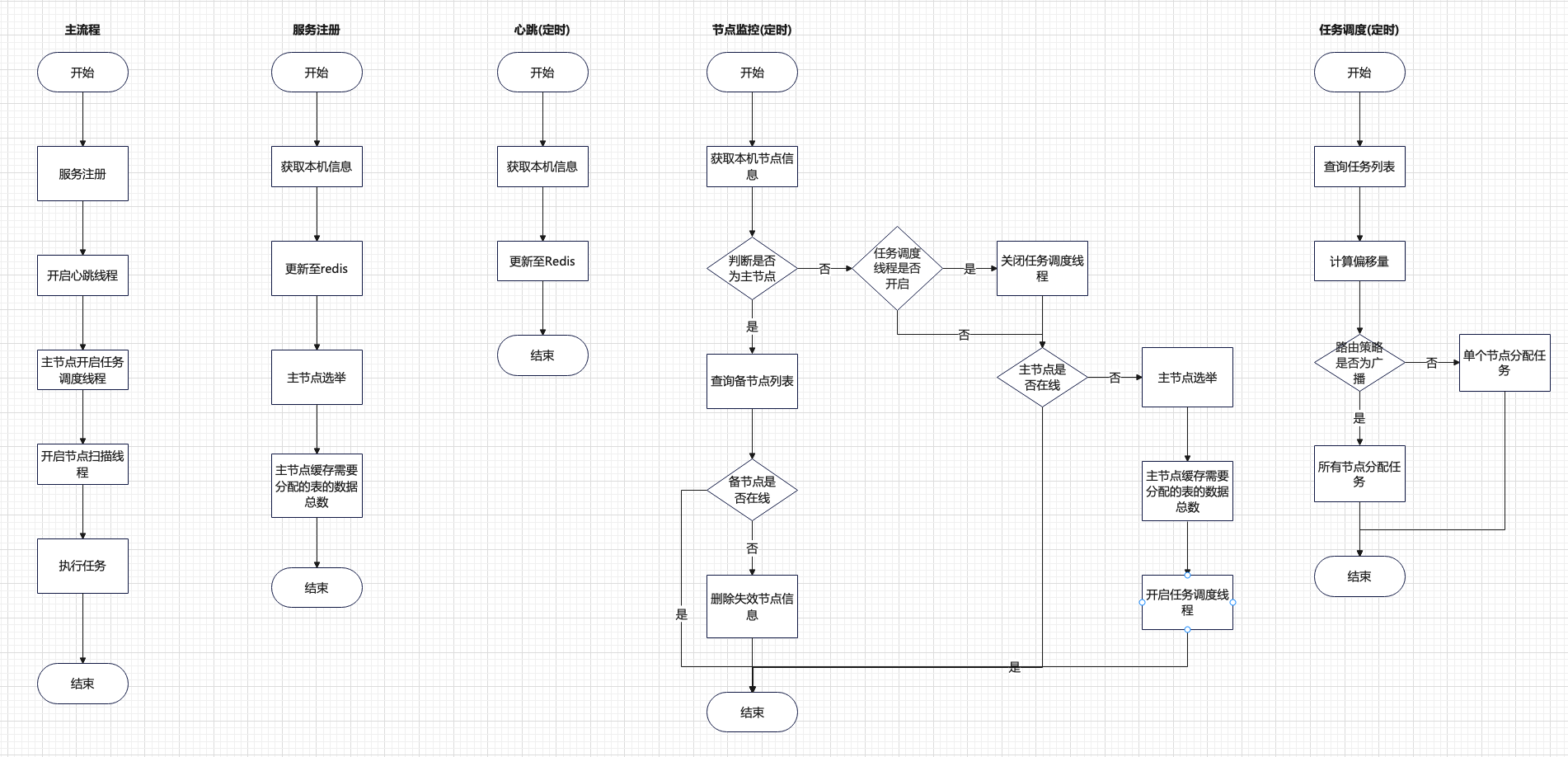
服务注册设计
节点启动后,启动一个心跳机制,每秒将自己的信息注册(更新)至redis(服务名、ip、节点类型、可用资源、最后一次心跳时间等),并尝试注册为主节点。
心跳:
-
除了每秒更新节点信息,主节点扫描每个节点的最后心跳时间,如果最后心跳时间停止更新超过1分钟,则删除节点信息。
-
备节点扫描主节点的最后心跳时间,如果主节点心跳停止时间过长则删除主节点信息,进行重新选举主节点。
-
主节点每次心跳还要判断自己还是不是主节点(因为主节点可能会因为断网时间过长导致主节点被其他节点抢走了),如果不是则停止任务调度线程
主节点选举设计
- 通过redis setnx命令实现,所有的服务启动成功后争抢同一个KEY,抢到的成为主节点,其他节点通过心跳判断主节点是否还在线,如果主节点的最后心跳时间停止过长,则认为主节点已经失效,删除主节点信息,其他节点开始争抢成为主节点。
任务调度分配设计
-
服务启动时先从数据库读取每个预设表的数据条目总数,然后缓存起来,并且监听这张表,如果有变动则进行实时更新
-
任务分配:
- 方案一:通过spring的定时任务,开启一个每秒执行一次的定时任务,每次从任务表读取符合执行条件的任务,从redis中获取所有的节点信息,分配偏移量后进行执行;
- 方案二:主节点扫描任务配置表有效的任务,将任务添加到spring本身定时任务模块中执行(ThreadPoolTaskScheduler.schedule)
-
预设任务分配:如果任务是分片广播,则获取对应表的数据总数,然后平均分配给每个节点,如果是单点执行,则获取资源最多的节点,然后执行所有的企业
-
普通任务执行:如果是分片广播则所有节点都进行执行,如果是单点执行,则获取资源最多的节点执行任务
-
任务调用:主节点确认好需要执行的节点等信息后,通过RPC调用对应的节点的添加任务方法,如果添加失败则重试3次,3次后还是失败,则换节点执行,如果所有节点都不能执行,则记录为执行失败,执行成功后更新任务配置表的最后执行时间。
-
任务执行:开启一个无界队列线程池,将任务放入执行,将主节点传来的偏移量直接传递给任务,让任务自己去数据库查询对应偏移量的数据。
Cron解析工具类
方案一:使用spring自带的
这个类在spring中已经被标记为弃用了
@Test
void springParseCron() {
String cronExpression = "0 0 12 * * ?"; // 每天中午12点触发
CronSequenceGenerator generator = new CronSequenceGenerator(cronExpression);
// 获取下一次任务执行时间
Date nextRunTime = generator.next(new Date());
SimpleDateFormat simpleDateFormat = new SimpleDateFormat(DatePattern.NORM_DATETIME_PATTERN);
System.out.println("Next run time: " + simpleDateFormat.format(nextRunTime));
}
方案二:org.quartz-scheduler
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
</dependency>
public static void main(String[] args) throws ParseException {
String cronExpression = "0 0 12 * * ?"; // 每天中午12点触发
CronExpression expression = new CronExpression(cronExpression);
SimpleDateFormat simpleDateFormat = new SimpleDateFormat(DatePattern.NORM_DATETIME_PATTERN);
Date nextRunTime = expression.getNextValidTimeAfter(new Date());
System.out.println("Next run time: " + simpleDateFormat.format(nextRunTime));
}
获取系统资源工具类
OperatingSystemMXBean osBean = ManagementFactory.getOperatingSystemMXBean();
System.out.println("cpu使用率:" + osBean.getSystemLoadAverage());
或者
OshiUtil.getMemory().getTotal()
OshiUtil.getMemory().getAvailable()
int cpuNum = OshiUtil.getCpuInfo(100).getCpuNum();
double cpuUsed = OshiUtil.getCpuInfo(2000).getUsed();
Spring手动定时任务管理
/**
* 任务调度池
* @return
*/
@Bean(name = "jobSchedulerThread")
public ThreadPoolTaskScheduler jobSchedulerThread() {
ThreadPoolTaskScheduler threadPoolTaskScheduler = new ThreadPoolTaskScheduler();
//线程池大小
threadPoolTaskScheduler.setPoolSize(jobSchedulerCorePoolSize);
//线程名称前缀
threadPoolTaskScheduler.setThreadNamePrefix("jobSchedule-");
//等待时长
threadPoolTaskScheduler.setAwaitTerminationSeconds(60);
//关闭任务线程时是否等待当前被调度的任务完成
threadPoolTaskScheduler.setWaitForTasksToCompleteOnShutdown(true);
return threadPoolTaskScheduler;
}
@Autowired
@Qualifier("jobSchedulerThread")
// 任务调度线程池
private ThreadPoolTaskScheduler jobSchedulerThread;
/**
* 启动定时任务调度
*/
private void startJobSchedule() {
List<WbJobConfigEntity> jobs = wbJobConfigMapper.selectList(new LambdaQueryWrapper<WbJobConfigEntity>()
.eq(WbJobConfigEntity::getTriggerStatus, 1)
);
for (WbJobConfigEntity job : jobs) {
addJobSchedule(job);
}
log.debug("启动定时任务调度");
}
public void addJobSchedule(WbJobConfigEntity job) {
RLock lock = redissonTemplate.getLock("wb:addJobSchedule:" + job.getJobHandler());
try {
if (lock.tryLock()) {
if (futureMap.get(job.getJobHandler()) == null || futureMap.get(job.getJobHandler()).isCancelled()) {
JobScheduleConfig bean = SpringUtil.getBean(JobScheduleConfig.class);
bean.setJob(job);
if (job.getScheduleType() == 1) {
futureMap.put(job.getJobHandler(), jobSchedulerThread.scheduleAtFixedRate(bean, 1000L * Integer.parseInt(job.getScheduleConf())));
} else {
futureMap.put(job.getJobHandler(), jobSchedulerThread.schedule(bean, new CronTrigger(job.getScheduleConf())));
}
}
}
} finally {
lock.unlock();
}
}
/**
* 停止定时任务调度
*/
private void stopJobSchedule() {
List<WbJobConfigEntity> jobs = wbJobConfigMapper.selectList(new LambdaQueryWrapper<WbJobConfigEntity>()
.eq(WbJobConfigEntity::getTriggerStatus, 1)
);
for (WbJobConfigEntity job : jobs) {
if (futureMap.get(job.getJobHandler()) != null && !futureMap.get(job.getJobHandler()).isCancelled()) {
futureMap.get(job.getJobHandler()).cancel(true);
futureMap.remove(job.getJobHandler());
}
}
log.debug("任务停止调度");
}















 1464
1464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









