







论文题目:Multi-Modal Face Anti-Spoofing Based on Central Difference Networks
代码地址:GitHub - ZitongYu/CDCN: Central Difference Convolutional Networks (CVPR'20)
文章创新点
第一个将 CDCN 用于基于 FAS 的深度和红外模态输入,并分析了 CDCN 在这两种模态下的表现。
Multi-Modal CDCN
CDC 卷积算子如下图所示:
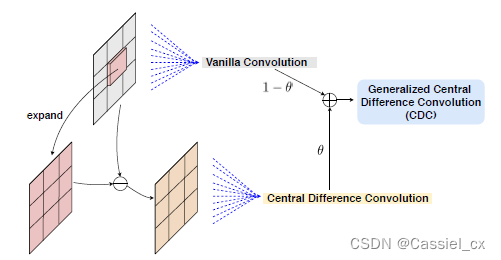
作者使用 CDCN 作为每个模态分支的主干网络,每个模态分支的网络是不共享的。因此,每个分支都能够独立地学习模态感知特征,每个模态分支的多级特征通过级联进行融合,网络架构如下图所示:
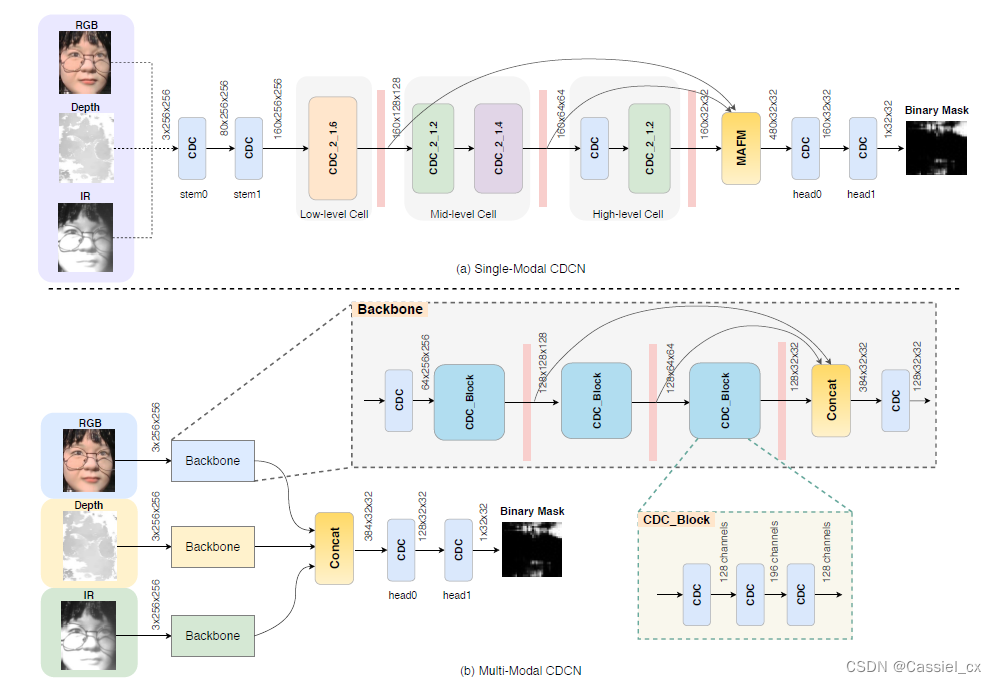
由于特征级融合策略并非对测试集的所有协议都是最优的,作者尝试了另外两种融合策略:(1)通过将三模态输入直接拼接成 256×256×9 的输入级融合;(2)分数级融合,通过加权每个模态的预测分数以获得最终得分。
监督信号
相比于二分类,像素级监督能使模型学到更具判别力的特征表示方法。作者对每张图片生成了一个二值 mask,人脸区域内的像素值为 1,非人脸区域的像素值为 0。
损失函数
损失函数由均方误差和对比深度损失组成,公式如下:
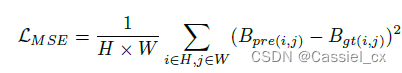
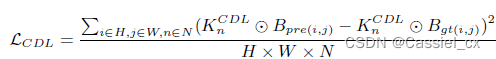
其中, 表示第 n 个对比卷积算子,卷积权值如下:

对应代码如下:
def contrast_depth_conv(input):
''' compute contrast depth in both of (out, label) '''
'''
input 32x32
output 8x32x32
'''
kernel_filter_list =[
[[1,0,0],[0,-1,0],[0,0,0]], [[0,1,0],[0,-1,0],[0,0,0]], [[0,0,1],[0,-1,0],[0,0,0]],
[[0,0,0],[1,-1,0],[0,0,0]], [[0,0,0],[0,-1,1],[0,0,0]],
[[0,0,0],[0,-1,0],[1,0,0]], [[0,0,0],[0,-1,0],[0,1,0]], [[0,0,0],[0,-1,0],[0,0,1]]
]
kernel_filter = np.array(kernel_filter_list, np.float32)
kernel_filter = torch.from_numpy(kernel_filter.astype(np.float)).float().cuda()
# weights (in_channel, out_channel, kernel, kernel)
kernel_filter = kernel_filter.unsqueeze(dim=1)
input = input.unsqueeze(dim=1).expand(input.shape[0], 8, input.shape[1],input.shape[2])
contrast_depth = F.conv2d(input, weight=kernel_filter, groups=8) # depthwise conv
return contrast_depth
class Contrast_depth_loss(nn.Module):
def __init__(self):
super(Contrast_depth_loss,self).__init__()
return
def forward(self, out, label):
'''
compute contrast depth in both of (out, label),
then get the loss of them
tf.atrous_convd match tf-versions: 1.4
'''
contrast_out = contrast_depth_conv(out)
contrast_label = contrast_depth_conv(label)
criterion_MSE = nn.MSELoss().cuda()
loss = criterion_MSE(contrast_out, contrast_label)
#loss = torch.pow(contrast_out - contrast_label, 2)
#loss = torch.mean(loss)
return loss实验
对比实验结果与消融实验结果如下:
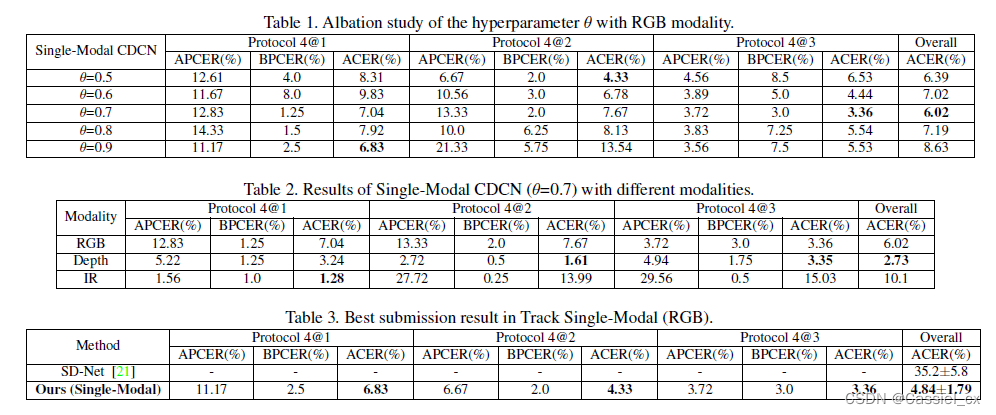
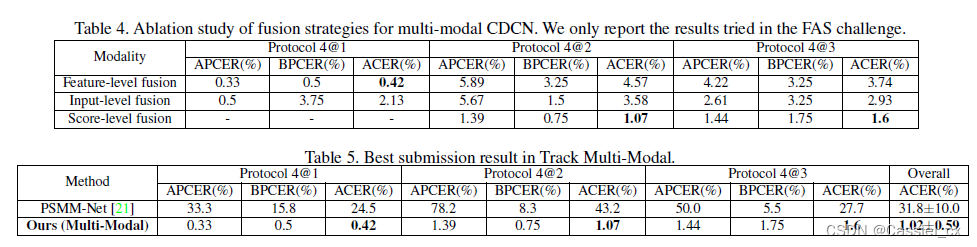 结论
结论
在本文中,作者详细研究了 CDCN 在 FAS 任务中的多种模态输入中的应用。 实验结果表明CDCN对单模态和多模态 FAS 任务的有效性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











