







1.全局的hash表
redis为了提高查找速度,将所有的键值对都保存到一个hash表中
结构图
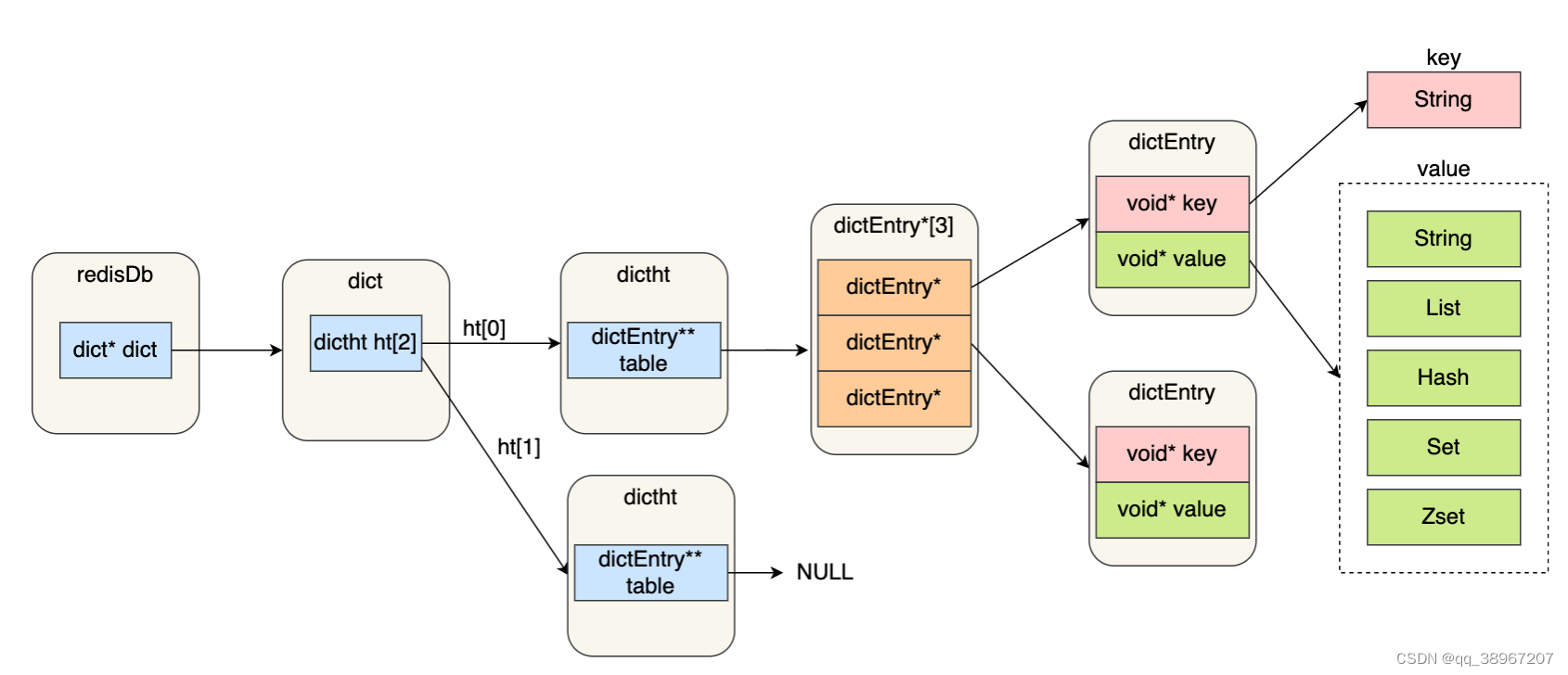
2.一次查找过程
1.根据指定的key计算出hash值,然后找到对应的桶位。
2.然后找到桶中的Entry结构,如果entry是一个链表,那么遍历链表查找
3.找到key具体的entry之后,如果value是String类型,那么entry中的value就是要查找的值。如果是其他类型,根据value指针在找到具体的数据。
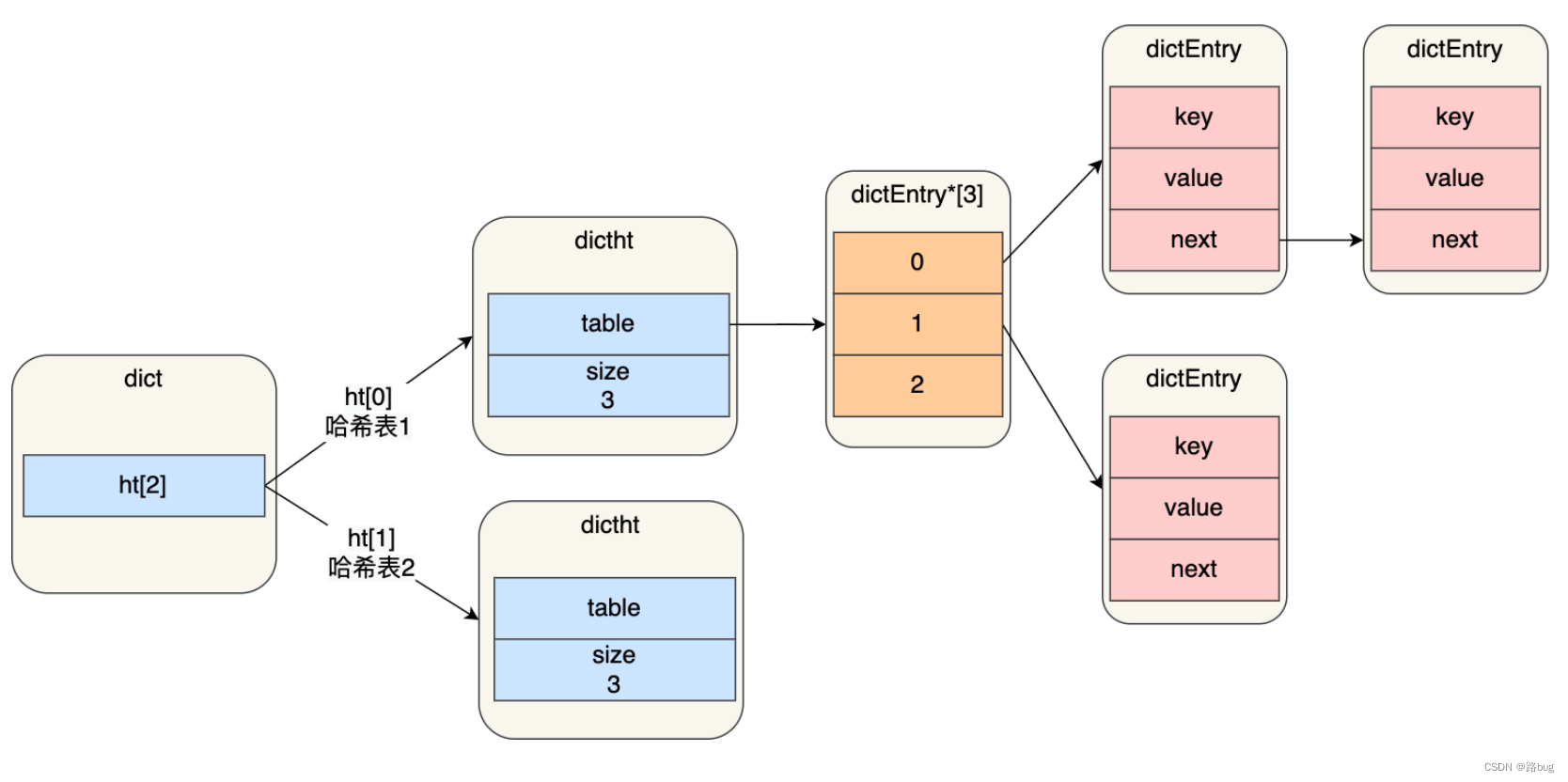
3.hash冲突
redis解决hash冲突采用的是链地址法。和hashMap类似。如果hash冲突,将会在指定桶中形成一个链表,如果链太长,将会影响查找效率。所以在元素个数达到数组长度时,会进行扩容
4.rehash
4.1初始化另一个table2。长度为原来table1长度的2倍。
4.2.rehash是一个渐进式的操作,因为单线程的原因,每处理一个客户端请求的时候,都会顺带处理一个entry链。
4.3新添加的元素都统一插入到table2中,table1中的元素总会慢慢全部迁移完成
5.触发rehash的条件
- 当负载因子大于等于 1 ,并且 Redis 没有在执行RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。
- 当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。
2.hash使用的哈希表














 1991
1991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









