







上一节课我们好不容易装好了 Scrapy,今天我们就来学习如何用好它,有些同学可能会有些疑惑,既然我们懂得了Python编写爬虫的技巧,那要这个所谓的爬虫框架又有什么用呢?其实啊,你懂得Python写爬虫的代码,好比你懂武功,会打架,但行军打仗你不行,毕竟敌人是千军万马,纵使你再强,也只能是百人敌,完成为千人敌,甚至是万人敌,你要学会的就是排兵布阵,运筹帷幄于千里之外,所以,Scrapy 就是Python爬虫的孙子兵法。
使用 Scrapy抓取一个网站一共分为四个步骤:
–创建一个Scrapy项目;
–定义Item容器;
–编写爬虫;
–存储内容。
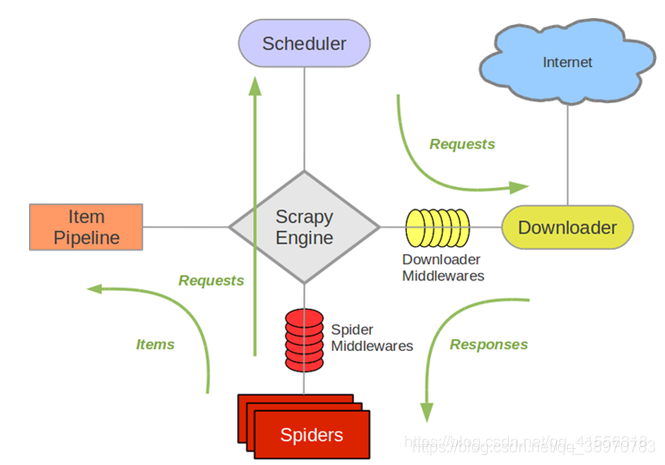
首先我们来分析它的几大组件:
Scrapy Engine:它是 Scrapy 的核心,爬虫工作的核心。负责控制数据流在系统中所有组件之间的流动,大家可以看到,无论那两个组件之间进行交流,都必须经过它。
Downloader :下载器,下载器负责获取页面的数据,然后提供给 Spiders,数据是从 Scheduler(调度器)这里获得的。
Scheduler:调度器,是从Scrapy Engine(引擎)这里接收 Requests 数据,事实上,Requests 数据需要的 request 的网页的地址是存放在 Spiders 这里,Spiders提供给Scrapy Engine ,Scrapy Engine(引擎)发送 Requests 给 Scheduler(调度器),调度器再把 Requests 传给 Downloader,Downloader 获得内容(也就是 Responses)之后,就发给Scrapy Engine,然后发给 Spiders 分析。
那么 Spiders 就是 Scrapy 用户编写用于分析下载器返回回来的 Responses,然后提取出 Items 和 需要跟进 的url 的类。
还有一个就是 Item Pipeline,负责处理被 Spiders 提取出来的 Items,Items 就是一个容器,存放我们需要的内容的一个容器,它把 Items 进行存储化,例如存到数据库,存到文件,就是由 Item Pipeline 来处理的。
接下来还有两个 中间键,一个就是 下载器的中间件,Downloader Middlewares,两个中间件事实上就是提供一个简便的机制,通过让你插入自定义的代码来扩展 Scrapy 的功能。
下载器中间件,Downloader Middlewares,是在引擎和下载器之间的 特定钩子,是处理 Downloader 发到引擎的Responses,Responses 要发给 Spiders 需要经过 引擎,下载器中间件就在中间 hook 一下。
Spiders 中间件,Spiders Middlewares,是处理Spiders 和引擎之间交互的 hook,首先它是接收来自 Downloader 的数据,接收Response 要先从Spiders中间件这里过滤一下,进行额外的操作,然后再给Spiders,然后呢,这个中间件也会接收spiders 的输出,例如 Requests和 Items。
以上就是 Scrapy 的基本框架了,了解之后,我们就来做项目了。
步骤一:创建一个Scrapy项目;
第一步要做的就是运行命令行,Scrapy 是命令行的,在爬取之前,我们要先创建一个 Scrapy 项目,我们来到桌面,运行 scrapy startproject tutorial,回车之后,在桌面就出现了 tutorial 文件夹。
#CMD窗口
Microsoft Windows [版本 10.0.17134.471]
(c) 2018 Microsoft Corporation。保留所有权利。
C:\Users\XiangyangDai>cd C:\Users\XiangyangDai\Desktop
C:\Users\XiangyangDai\Desktop>scrapy startproject tutorial
New Scrapy project 'tutorial', using template directory 'd:\\programfiles\\anaconda3\\lib\\site-packages\\scrapy\\templates\\project', created in:
C:\Users\XiangyangDai\Desktop\tutorial
You can start your first spider with:
cd tutorial
scrapy genspider example example.com
这个文件夹就是按照下面的形式存储的:

scrapy.cfg 是项目的配置文件(暂时不用,保持默认即可)
tutorial 子文件夹 存放的是模块的代码,也是我们要填充的代码
items.py 是项目中的容器
致此,完成了步骤一:创建一个Scrapy项目;
步骤二:定义 Item 容器
Item是保存爬取到的数据的容器,其使用方法和Python字典类似,并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
首先,我们需要对你想要获取的数据进行建模,
我们的任务就是 网页:http://www.dmozdir.org/Category/?SmallPath=230 ;和 http://www.dmozdir.org/Category/?SmallPath=411 ;这是两个个导航网页,我们的目标就是爬取各个标题以及其超链接和描述。我们就根据这三部分进行建模就可以了。
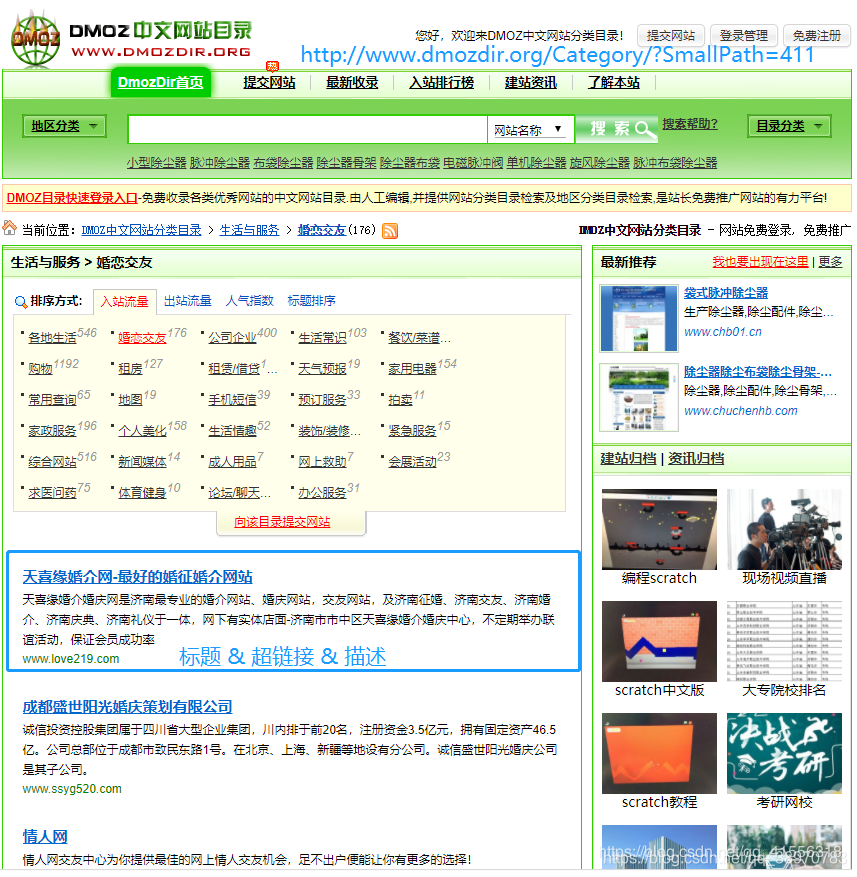
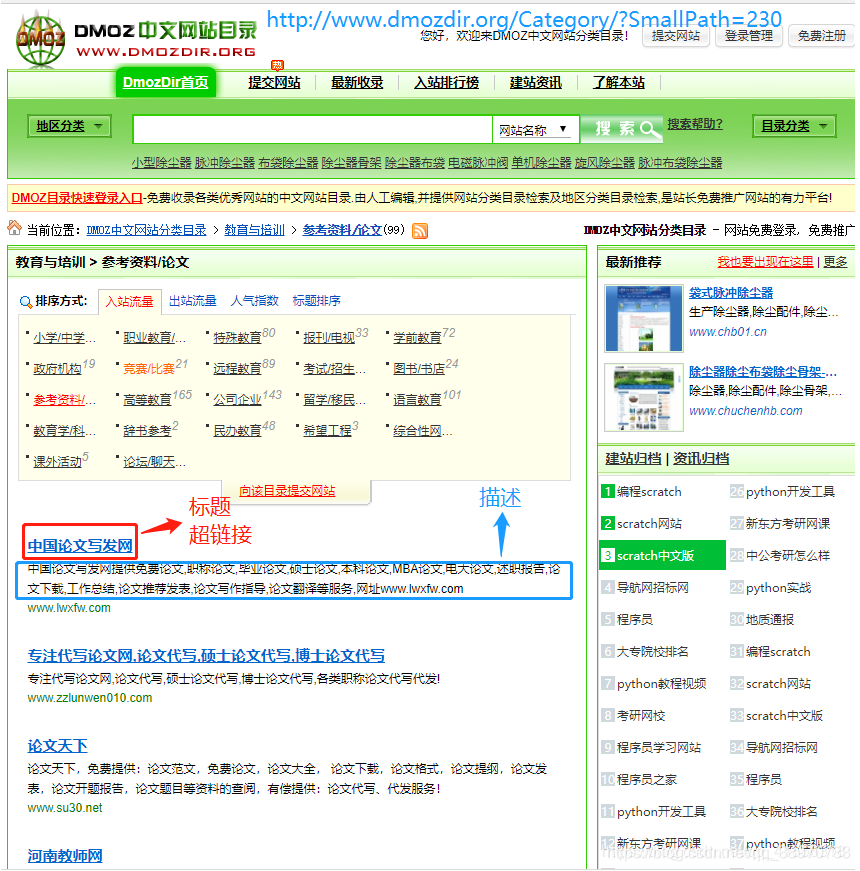
只需要在 items.py 文件里建立相应的字段:
初次打开未经修改的内容如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
其中都已经注释好了,
# name = scrapy.Field() ;
name ; 就是你要建立的字段的名字
scrapy.Field() ; 就是对应的占位符。
我们就照着写就可以了:
class DmozItem(scrapy.Item): #改个与项目对应的名字
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() #标题
link = scrapy.Field() #超链接
desc = scrapy.Field() #描述
致此,完成了步骤二:定义 Item 容器;
步骤三:编写爬虫;
编写爬虫,我们就写在 spiders 文件夹里面,其实就是编写爬虫类 Spider,Spider 是用户编写用于从网站上爬取数据的类。
其包含一个用于下载的初始 URL,然后是如何跟进网页中的链接以及如何分析页面中的内容,还有提取生成 item 的方法。
这就包含两个部分,第一个部分就是写一个初始化 URL ,例如 我们这里初始化 是从 http://www.dmozdir.org/Category/?SmallPath=230 ;和 http://www.dmozdir.org/Category/?SmallPath=411 这两个 URL下载,我们就把它列到 spider 里面,然后就是还需要写一个方法,如何分析页面中的内容,还有生成 item 。
我们的操作是:在spider 里创建一个 dmoz_spider.py 的源文件。
我们首先写一个 Spider 类,我们命名为 DmozSpider,这里要求必须是继承 scray.Spider 类,首先需要有一个 name,name 这里必须是唯一的,用来确认你这只 蜘蛛 的名字。
接着有一个 allowed_domains,是一个列表,确定这只蜘蛛要爬取的范围,这里我们规定只能 爬取在 dmozdir.org/Category 网址里面,这样它在一个网址里面找到其他网页的链接,也不会跑过去了,它只会在这个域名里面去爬,要是没有规定这个的话,蜘蛛爬着爬着就回不来了。
接下来就是 start_urls ,这里是开始爬取的网址,规定从哪里开始爬。我们这里为了节约时间,就搞两个。
接下来写一个分析的方法,命名为 parse,有一个唯一的参数 response,事实上,我们看一下 Scrapy 的框架图,我们前面写的内容就是由 Scrapy Engine 从 Spiders 提取,然后变成 Requests 给 Schedulder,然后我们刚刚说了,downloader 会下载出来的 Reponses 数据给 Scrapy Engine ,然后给 Spiders,我们要一个分析机来处理,这就是我们的parse方法,这个方法接收 Responses,然后对它进行分析处理,并且提取成 Items 给 Item Pipeline,所以我们就要在这个方法里写一些指定的代码。我们这里先来一个简单的代码范例:
根据网站地址,创建一个名为 网站倒数第一个字段的最后3位(230 和 411)的文件,保存 response.body。 response.body 就是这个网页的源代码 。
#dmoz_spider.py
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ['dmozdir.org/Category']
start_urls = ['http://www.dmozdir.org/Category/?SmallPath=230',
'http://www.dmozdir.org/Category/?SmallPath=411']
def parse(self, response):
filename = response.url.split('/')[-1][-3:] #文件名为230和411
with open(filename, 'wb') as f:
f.write(response.body)
保存dmoz_spider.py文件,我们把这个爬取分为先爬后取两个独立动作,展开给大家看:
首先是爬:
在 cmd 中,目录切到 tutorial 根目录,调用命令 scrapy crawl dmoz:(这里的 crawl 翻译过来就是 爬取 的意思,dmoz 就是我们选择的蜘蛛,我们在 dmoz_spider 里写了一个 name 叫做 dmoz,它就知道调用哪个爬虫去工作了)
#CMD窗口
C:\Users\XiangyangDai\Desktop>cd tutorial
C:\Users\XiangyangDai\Desktop\tutorial>scrapy crawl dmoz
运行结果如下:
#CMD窗口
C:\Users\XiangyangDai\Desktop\tutorial>scrapy crawl dmoz
2018-12-17 15:57:54 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: tutorial)
2018-12-17 15:57:54 [scrapy.utils.log] INFO: Versions: lxml 4.2.5.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted 18.9.0, Python 3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0j 20 Nov 2018), cryptography 2.4.2, Platform Windows-10-10.0.17134-SP0
2018-12-17 15:57:54 [scrapy.crawler] INFO: Overridden settings: {'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'tutorial', 'SPIDER_MODULES': ['tutorial.spiders'], 'NEWSPIDER_MODULE': 'tutorial.spiders'}
2018-12-17 15:57:54 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats',
'scrapy.extensions.corestats.CoreStats']
2018-12-17 15:57:55 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-12-17 15:57:55 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-12-17 15:57:55 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-12-17 15:57:55 [scrapy.core.engine] INFO: Spider opened
2018-12-17 15:57:55 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-12-17 15:57:55 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-12-17 15:57:55 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/robots.txt> (referer: None)
2018-12-17 15:57:56 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=230> (referer: None)
2018-12-17 15:57:56 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=411> (referer: None)
2018-12-17 15:57:56 [scrapy.core.engine] INFO: Closing spider (finished)
2018-12-17 15:57:56 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 698,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 14618,
'downloader/response_count': 3,
'downloader/response_status_count/200': 3,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 12, 17, 7, 57, 56, 333599),
'log_count/DEBUG': 4,
'log_count/INFO': 7,
'response_received_count': 3,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2018, 12, 17, 7, 57, 55, 738552)}
2018-12-17 15:57:56 [scrapy.core.engine] INFO: Spider closed (finished)
中间有两条内容:
2018-12-17 15:57:56 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=230> (referer: None)
2018-12-17 15:57:56 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=411> (referer: None)
200就是网页状态码,表示链接成功,后面接的网址就是我们爬取的网址。
另外,我们在 tutorial 根目录下看到增加一个名为 ;230 和 411 ;的文件,你如果用 Notepad 打开的话,实际上就是上面那个网页的源代码(保存的是 response.body)。
我们上面做的事情就是 Scrapy Engin 从Spider 这里获取到两个 初始化的地址,为什么它知道从 ;
start_urls = [‘http://www.dmozdir.org/Category/?SmallPath=230’,
‘http://www.dmozdir.org/Category/?SmallPath=411’]
这里获取,我们刚才给它的命令是 scrapy crawl dmoz,那它就会来找这个叫做 dmoz 的 spider,所以我们说这个 name 不能重复,重复的话它就不知道找哪一只蜘蛛了,这个 dmoz 是唯一的蜘蛛,它的名字叫做 dmoz。找到它之后,它知道它的两个初始化的地址,所以就提交给 Scheduler,Scheduler 再安排好顺序,发给 Downloader 去下载,下载之后就返回一个 Responses 给 Spiders,Spiders 的这个 parse 方法(回调函数)接收到 Responses 后,就会执行函数体的内容,就会把 230 和 411 分别保存为两个文件。
我们接下来继续深入讲解,那这个是爬的过程,爬完整个网页,接下来就是取的过程啦。
大家还记得我们之前定义的 Item 容器吧:一个是 title,一个是 link,一个是 desc。
#items.py
import scrapy
class DmozItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() #标题
link = scrapy.Field() #超链接
desc = scrapy.Field() #描述
我们现在的目标就是要从这个 230 和 411 这个偌大的内容中找出 title 、link 和 desc ,然后分别保存提取出来,大家知道,这就是一个大浪淘沙的过程。将得到的网页提取出我们需要的数据,之前我教给大家的是使用正则表达式,在Scrapy 里面,是使用一种基于 XPath 和 CSS 的表达式机制:Scrapy Selectors。
Selectors 是一个选择器,它有4个基本方法:
xpath():传入 xpath 表达式,返回该表达式所对应的所有节点的 selector list 列表。
css():传入 css 表达式,返回该表达式所对应的所有节点的 selector list 列表。
extract():序列化该节点为 unicode 字符串并返回 list。
re():根据传入的正则表达式对数据进行提取,返回 unicode 字符串 list 列表。
为了介绍 selector 的使用方法,接下来我们使用内置的 scrapy shell,首先你需要在CMD中进入项目的根目录(在前面我们已经进入了),输入:
scrapy shell “http://www.dmozdir.org/Category/?SmallPath=411”
回车,得到下面的内容:
进入 shell
#CMD窗口
C:\Users\XiangyangDai\Desktop\tutorial>scrapy shell "http://www.dmozdir.org/Category/?SmallPath=411"
2018-12-17 16:40:55 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: tutorial)
2018-12-17 16:40:55 [scrapy.utils.log] INFO: Versions: lxml 4.2.5.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted 18.9.0, Python 3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0j 20 Nov 2018), cryptography 2.4.2, Platform Windows-10-10.0.17134-SP0
2018-12-17 16:40:55 [scrapy.crawler] INFO: Overridden settings: {'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['tutorial.spiders'], 'LOGSTATS_INTERVAL': 0, 'BOT_NAME': 'tutorial', 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'NEWSPIDER_MODULE': 'tutorial.spiders'}
2018-12-17 16:40:55 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2018-12-17 16:40:55 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-12-17 16:40:55 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-12-17 16:40:55 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-12-17 16:40:55 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-12-17 16:40:55 [scrapy.core.engine] INFO: Spider opened
2018-12-17 16:40:56 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/robots.txt> (referer: None)
2018-12-17 16:40:56 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=411> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x0000019382563D68>
[s] item {}
[s] request <GET http://www.dmozdir.org/Category/?SmallPath=411>
[s] response <200 http://www.dmozdir.org/Category/?SmallPath=411>
[s] settings <scrapy.settings.Settings object at 0x0000019382565B38>
[s] spider <DefaultSpider 'default' at 0x193827dfe80>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [1]:
当出现 In [1]: 或者 >>>,就说明已经进入了 shell,在shell 载入之后,你将得到 Responses 回应,我们就可以对它进行操作:
例如,我们输入 response.headers ,就会得到 网页的 头:
#CMD窗口
In [1]: response.headers
Out[1]:
{b'Cache-Control': b'private',
b'Content-Type': b'text/html; Charset=utf-8',
b'Date': b'Mon, 17 Dec 2018 08:40:47 GMT',
b'Server': b'Microsoft-IIS/6.0',
b'Set-Cookie': b'ASPSESSIONIDCSBBCQBD=NMHNAMKDCBHDGNNAAGNKKBLM; path=/',
b'Vary': b'Accept-Encoding',
b'X-Powered-By': b'ASP.NET'}
我们输入 response.body,就会得到 网页的 源代码:
#CMD窗口
In [3]: response.body
Out[3]: b'\r\n<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">\r\n<meta http-equiv="x-ua-compatible" content="ie=7" />\r\n<meta http-equiv="imagetoolbar" content="false" />\r\n<html xmlns="http://www.w3.org/1999/xhtml">\r\n<head>\r\n<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />\r\n<meta name="description" ...不打印出来了
上面是以二进制显示的,我们可以进行编码:
#CMD窗口
In [5]: response.body.decode('utf-8')
Out[5]: '\r\n<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">\r\n<meta http-equiv="x-ua-compatible" content="ie=7" />\r\n<meta http-equiv="imagetoolbar" content="false" />\r\n<html xmlns="http://www.w3.org/1999/xhtml">\r\n<head>\r\n<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />\r\n<meta name="description" content="婚恋交友,生活与服务网站分类目录 大全,收录与婚恋交友,生活与服务相关的所有精品网站!欢迎您提交与婚恋交友,生活与服务相关的网站,这是您彰显实力的好机会,赶快行动吧!丰富详实的婚恋交友,生活与服务网站,尽在DMOZ中文网站分类目录!" />\r\n<meta name="keywords" content="婚恋交友,生活与服务,网站目录,分类目录,网站分类目录,网址导航,网址大全,网页目录,行业分类" />\r\n<meta name="author" content="点燃一支烟" />\r\n<title>婚恋交友-生活与服务-目录分类-DMOZ中文网站分类目录</title>\r\n\r\n<link rel="alternate" type="application/rss+xml" ...等等不输出了
大家看到了,这个response.body 很多内容,
我们要从里面找到 title、link 和 desc ,事实上就是一个沙中淘金的过程,所以接下来我们就要找到一个筛子,把沙子给去掉,淘出金子。
selector 选择器就是这么一个筛子,正如我们刚才所讲到的,可以使用 response.selector.xpath() 或者 response.selector.css() 或者 response.selector.extract() 或者 response.selector. re() 这四个基本方法来进行筛选。
我们首先教大家使用 xpath()
XPath 是一门在网页中查找特定信息的语言。所以用 Xpath 来筛选数据,比使用正则表达式容易些。
事实上,你使用正则表达式来查找 html 这类的网页文件的话,经常会出现一些问题,用 XPath 就不会,因为它是针对性的。
我们祥和里给出一个 XPath 表达式的例子,以及对应的含义:
/html/head/title:选择HTML文档中<head>标签中的<title>元素</font>
/html/head/title/text():选择上面提到的<title>元素的文字
//td:选择所有的 <td> 元素
//div[@class=“mine”]:选择所有具有 class="mine"属性的 div 元素
我们这里给大家演示一下:(值的一提的是:reponse.xpath() 已经映射到了 response.selector.xpath() ,所以,我们以后就只使用 response.selector.xpath() )
#CMD窗口
In [6]: response.selector.xpath('//title')
Out[6]: [<Selector xpath='//title' data='<title>婚恋交友-生活与服务-目录分类-DMOZ中文网站分类目录</tit'>]
你如果想要得到 title 里面的文字(只显示title 的文字,不要标签),你就可以:
#CMD窗口
In [9]: response.selector.xpath('//title/text()').extract()
Out[9]: ['婚恋交友-生活与服务-目录分类-DMOZ中文网站分类目录']
非常方便,比你挖空心思去写正则表达式要容易得多,而且不会出错,因为它是根据节点(也就是网页中的标签)来一个一个去查找的。
我们接下来就是提取数据了,尝试从页面中提取出对我们有用的数据。你可以从 response.body 里面去找,但我们极力不建议这样做,因为这浪费时间又不讨好,之前不是说了,有一个审查元素吗,我们来看看 我们想要的 title,link 和 desc 的规律。
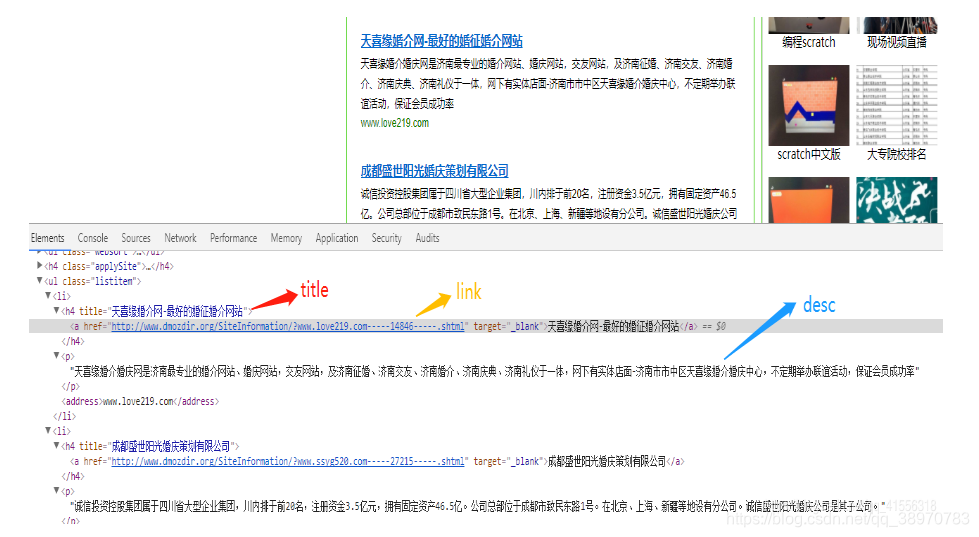
http://www.dmozdir.org/Category/?SmallPath=411
我们发现,在一个 ul 标签 和 li 标签中间,而且每个 li 标签对应一组数据,所以,我们先找 ul ,再找 li 就对了。
好,那我们来试一下:
#CMD窗口
In [12]: response.selector.xpath('//ul/li')
Out[12]:
[<Selector xpath='//ul/li' data='<li class="first"><a href="javascript:;"'>,
<Selector xpath='//ul/li' data='<li><a href="javascript:;" onclick="copy'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/User'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/User'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/User'>,
<Selector xpath='//ul/li' data='<li class="userinfo">您好,欢迎来DMOZ中文网站分类目录!'>,
<Selector xpath='//ul/li' data='<li class="thome"><a href="http://www.dm'>,
<Selector xpath='//ul/li' data='<li class="tadd"><a href="http://www.dmo'>,
<Selector xpath='//ul/li' data='<li class="tline">|</li>'>,
<Selector xpath='//ul/li' data='<li class="tnew"><a href="http://www.dmo'>,
<Selector xpath='//ul/li' data='<li class="tline">|</li>'>,
<Selector xpath='//ul/li' data='<li class="tgoin"><a href="http://www.dm'>,
<Selector xpath='//ul/li' data='<li class="tline">|</li>'>,
<Selector xpath='//ul/li' data='<li class="tnews"><a href="http://www.dm'>,
<Selector xpath='//ul/li' data='<li class="tline">|</li>'>,
<Selector xpath='//ul/li' data='<li class="tnews"><a href="http://www.dm'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/Cate'>,
...
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/Area'>,
...
<Selector xpath='//ul/li' data='<li class="first">排序方式:</li>'>,
<Selector xpath='//ul/li' data='<li class="check"><a href="?SmallPath=41'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=411&O=GoOut"'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=411&O=Digg">'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=411&O=Title"'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=410" title="各地生活'>,
<Selector xpath='//ul/li' data='<li class="check"><a href="?SmallPath=41'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=412" title="公司企业'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=413" title="生活常识'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=414" title="餐饮/菜'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=415" title="购物收录'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=416" title="租房收录'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=417" title="租赁/借'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=418" title="天气预报'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=419" title="家用电器'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=420" title="常用查询'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=421" title="地图收录'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=422" title="手机短信'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=423" title="预订服务'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=424" title="拍卖收录'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=425" title="家政服务'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=426" title="个人美化'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=427" title="生活情趣'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=428" title="装饰/装'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=429" title="紧急服务'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=430" title="综合网站'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=431" title="新闻媒体'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=432" title="成人用品'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=433" title="网上救助'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=434" title="会展活动'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=435" title="求医问药'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=436" title="体育健身'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=437" title="论坛/聊'>,
<Selector xpath='//ul/li' data='<li><a href="?SmallPath=576" title="办公服务'>,
<Selector xpath='//ul/li' data='<li><h4 title="天喜缘婚介网-最好的婚征婚介网站"><a href'>,
<Selector xpath='//ul/li' data='<li><h4 title="成都盛世阳光婚庆策划有限公司"><a href="'>,
<Selector xpath='//ul/li' data='<li><h4 title="情人网"><a href="http://www.'>,
<Selector xpath='//ul/li' data='<li><h4 title="国际免费婚介交友网站-相约100"><a href'>,
<Selector xpath='//ul/li' data='<li><h4 title="安徽婚庆网"><a href="http://ww'>,
<Selector xpath='//ul/li' data='<li><h4 title="聚缘北海交友网"><a href="http://'>,
<Selector xpath='//ul/li' data='<li><h4 title="爱我吧婚恋网"><a href="http://w'>,
<Selector xpath='//ul/li' data='<li><h4 title="77国际交友网"><a href="http://'>,
<Selector xpath='//ul/li' data='<li><h4 title="东莞韩风尚婚纱摄影工作室"><a href="ht'>,
<Selector xpath='//ul/li' data='<li><h4 title="百合婚礼社区"><a href="http://w'>,
<Selector xpath='//ul/li' data='<li><div class="img-preview"><a href="ht'>,
<Selector xpath='//ul/li' data='<li><div class="img-preview"><a href="ht'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/Abou'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/User'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/User'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/User'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/New.'>,
<Selector xpath='//ul/li' data='<li><a href="http://www.dmozdir.org/Comm'>,
<Selector xpath='//ul/li' data='<li><a href="javascript:;" target="_self'>,
<Selector xpath='//ul/li' data='<li><a href="Javascript:;" _fcksavedurl='>]
response.selector.xpath(’//ul/li’) 命令就把 response 里面所有的 ul/li 给打印出来了,我们要获得网站的描述的内容(desc),就还需要再加上一个 /p:
#CMD窗口
In [18]: response.selector.xpath('//ul/li/p')
Out[18]:
[<Selector xpath='//ul/li/p' data='<p>天喜缘婚介婚庆网是济南最专业的婚介网站、婚庆网站,交友网站,及济南征婚、济'>,
<Selector xpath='//ul/li/p' data='<p>诚信投资控股集团属于四川省大型企业集团,川内排于前20名,注册资金3.5亿'>,
<Selector xpath='//ul/li/p' data='<p>情人网交友中心为你提供最佳的网上情人交友机会,足不出户便能让你有更多的选择'>,
<Selector xpath='//ul/li/p' data='<p>国际免费婚介交友网站是相约100提供的完全免费的国际交友网站。会员以华人为'>,
<Selector xpath='//ul/li/p' data='<p>安徽婚庆网</p>'>,
<Selector xpath='//ul/li/p' data='<p>聚缘北海交友网是北海地区较规范的婚恋交友网站,致力于营造有趣而安全的网络交'>,
<Selector xpath='//ul/li/p' data='<p>爱我吧婚恋网是一个真实、严肃、高品位的婚恋平台,提供科学、高效的全程服务,'>,
<Selector xpath='//ul/li/p' data='<p>纯公益性,爱心社交网站,为广大青年及单身人士提供的全免费交友平台。</p>'>,
<Selector xpath='//ul/li/p' data='<p>东莞韩风尚婚纱摄影工作室是具有独特的韩国风格的东莞婚纱摄影工作室,韩风尚位'>,
<Selector xpath='//ul/li/p' data='<p>百合婚礼社区讨论话题涵盖婚纱照、婚纱摄影、婚礼筹备、婚纱礼服、婚庆等方面<'>]
这里看不完整,我们可以使用 extract():
#CMD窗口
In [19]: response.selector.xpath('//ul/li/p').extract()
Out[19]:
['<p>天喜缘婚介婚庆网是济南最专业的婚介网站、婚庆网站,交友网站,及济南征婚、济南交友、济南婚介、济南庆典、济南礼仪于一体,网下有实体店面-济南市市中区天喜缘婚介婚庆中心,不定期举办联谊活动,保证会员成功率</p>',
'<p>诚信投资控股集团属于四川省大型企业集团,川内排于前20名,注册资金3.5亿元,拥有固定资产46.5亿。公司总部位于成都市致民东路1号。在北京、上海、新疆等地设有分公司。诚信盛世阳光婚庆公司是其子公司。</p>',
'<p>情人网交友中心为你提供最佳的网上情人交友机会,足不出户便能让你有更多的选择!</p>',
'<p>国际免费婚介交友网站是相约100提供的完全免费的国际交友网站。会员以华人为主遍布五湖四海,所有会员完全免费。所有寻找国际免费婚介交友网站的朋友都能在国际交友网站在找到完全免费的国际免费婚介交友网站服务</p>',
'<p>安徽婚庆网</p>',
'<p>聚缘北海交友网是北海地区较规范的婚恋交友网站,致力于营造有趣而安全的网络交友社区,提供搜索、美文、约会、日记、聊天、等多项交友服务。并与地方婚介部门建立了良好的合作关系。</p>',
'<p>爱我吧婚恋网是一个真实、严肃、高品位的婚恋平台,提供科学、高效的全程服务,帮助真心寻找终身伴侣的人士实现和谐婚恋,努力营造国内最专业、严肃的婚恋交友平</p>',
'<p>纯公益性,爱心社交网站,为广大青年及单身人士提供的全免费交友平台。</p>',
'<p>东莞韩风尚婚纱摄影工作室是具有独特的韩国风格的东莞婚纱摄影工作室,韩风尚位于东莞东城区旗峰路国泰大厦10号,我们永远满怀创意与温情,通过一对一的服务为您提供超越您期望</p>',
'<p>百合婚礼社区讨论话题涵盖婚纱照、婚纱摄影、婚礼筹备、婚纱礼服、婚庆等方面</p>']
如果再加上 text() ,就只显示文本内容,删除了标签 p
#CMD窗口
In [20]: response.selector.xpath('//ul/li/p/text()').extract()
Out[20]:
['天喜缘婚介婚庆网是济南最专业的婚介网站、婚庆网站,交友网站,及济南征婚、济南交友、济南婚介、济南庆典、济南礼仪于一体,网下有实体店面-济南市市中区天喜缘婚介婚庆中心,不定期举办联谊活动,保证会员成功率',
'诚信投资控股集团属于四川省大型企业集团,川内排于前20名,注册资金3.5亿元,拥有固定资产46.5亿。公司总部位于成都市致民东路1号。在北京、上海、新疆等地设有分公司。诚信盛世阳光婚庆公司是其子公司。',
'情人网交友中心为你提供最佳的网上情人交友机会,足不出户便能让你有更多的选择!',
'国际免费婚介交友网站是相约100提供的完全免费的国际交友网站。会员以华人为主遍布五湖四海,所有会员完全免费。所有寻找国际免费婚介交友网站的朋友都能在国际交友网站在找到完全免费的国际免费婚介交友网站服务',
'安徽婚庆网',
'聚缘北海交友网是北海地区较规范的婚恋交友网站,致力于营造有趣而安全的网络交友社区,提供搜索、美文、约会、日记、聊天、等多项交友服务。并与地方婚介部门建立了良好的合作关系。',
'爱我吧婚恋网是一个真实、严肃、高品位的婚恋平台,提供科学、高效的全程服务,帮助真心寻找终身伴侣的人士实现和谐婚恋,努力营造国内最专业、严肃的婚恋交友平',
'纯公益性,爱心社交网站,为广大青年及单身人士提供的全免费交友平台。',
'东莞韩风尚婚纱摄影工作室是具有独特的韩国风格的东莞婚纱摄影工作室,韩风尚位于东莞东城区旗峰路国泰大厦10号,我们永远满怀创意与温情,通过一对一的服务为您提供超越您期望',
'百合婚礼社区讨论话题涵盖婚纱照、婚纱摄影、婚礼筹备、婚纱礼服、婚庆等方面']
我们想要得到各网站的标题(title):我们审查元素看到,标题的内容是在 h4 标签里面的 a 标签的文本里面,所以:
#CMD窗口
In [25]: response.selector.xpath('//ul/li/h4/a/text()').extract()
Out[25]:
['天喜缘婚介网-最好的婚征婚介网站',
'成都盛世阳光婚庆策划有限公司',
'情人网',
'国际免费婚介交友网站-相约100',
'安徽婚庆网',
'聚缘北海交友网',
'爱我吧婚恋网',
'77国际交友网',
'东莞韩风尚婚纱摄影工作室',
'百合婚礼社区']
接下来,我们想得到网址的超链接(link),我们可以使用 response.selector.xpath(’//ul/li/h4/a/@href’).extract()
#CMD窗口
In [28]: response.selector.xpath('//ul/li/h4/a/@href').extract()
Out[28]:
['http://www.dmozdir.org/SiteInformation/?www.love219.com-----14846-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.ssyg520.com-----27215-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.591lover.net-----36999-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.free-onlinedating.me-----10110-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.ahhqw.com-----18983-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.jyjjyy.com-----19343-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.lovemeba.com-----9983-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.77lds.com-----37176-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.dg-hfs.com-----18760-----.shtml',
'http://www.dmozdir.org/SiteInformation/?www.lilywed.cn-----9976-----.shtml']
上面所有的命令,如果没有假设 extract() ,就是得到 selector 对象的列表,加上 extract() 之后呢,得到的就是 将 selector 对象中的 data 变成字符串 提取出来。
我们这里还可以写一个循环来打印内容:
#CMD窗口
In [44]: a=response.selector.xpath('//ul/li/h4/a/text()').extract()
In [45]: for each in a:
...: print(each)
...:
天喜缘婚介网-最好的婚征婚介网站
成都盛世阳光婚庆策划有限公司
情人网
国际免费婚介交友网站-相约100
安徽婚庆网
聚缘北海交友网
爱我吧婚恋网
77国际交友网
东莞韩风尚婚纱摄影工作室
百合婚礼社区
一切OK了,接下来就是写我们的代码了,把它投入到生产线上去实现:
我们 退出 shell (使用命令 exit()),回到我们的 CMD,
#CMD窗口
In [48]: exit()
C:\Users\XiangyangDai\Desktop\tutorial>
修改我们的 Spider 代码,也就是 dmoz_spider.py。我们就按刚才从 shell 获得的经验来写 parse() 函数。
#dmoz_spider.py
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ['dmozdir.org/Category']
start_urls = ['http://www.dmozdir.org/Category/?SmallPath=411']
# 'http://www.dmozdir.org/Category/?SmallPath=411']
def parse(self, response):
titles = response.selector.xpath('//ul/li/h4/a/text()').extract() #标题 title
links = response.selector.xpath('//ul/li/h4/a/@href').extract() #超链接 link
decss = response.selector.xpath('//ul/li/p/text()').extract() #描述 decs
if len(titles) == len(links) == len(decss):
for i in range(len(titles)):
print(titles[i], links[i], decss[i])
写好之后,保存,进入 CMD,在 tutorial 根目录下执行命令:scrapy crawl dmoz
#CMD窗口
C:\Users\XiangyangDai\Desktop\tutorial>scrapy crawl dmoz
2018-12-17 19:32:48 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: tutorial)
2018-12-17 19:32:48 [scrapy.utils.log] INFO: Versions: lxml 4.2.5.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted 18.9.0, Python 3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0j 20 Nov 2018), cryptography 2.4.2, Platform Windows-10-10.0.17134-SP0
2018-12-17 19:32:48 [scrapy.crawler] INFO: Overridden settings: {'SPIDER_MODULES': ['tutorial.spiders'], 'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'tutorial', 'NEWSPIDER_MODULE': 'tutorial.spiders'}
2018-12-17 19:32:48 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.logstats.LogStats']
2018-12-17 19:32:49 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-12-17 19:32:49 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-12-17 19:32:49 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-12-17 19:32:49 [scrapy.core.engine] INFO: Spider opened
2018-12-17 19:32:49 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-12-17 19:32:49 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-12-17 19:32:49 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/robots.txt> (referer: None)
2018-12-17 19:32:49 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=230> (referer: None)
2018-12-17 19:32:49 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=411> (referer: None)
中国论文写发网 http://www.dmozdir.org/SiteInformation/?www.lwxfw.com-----13589-----.shtml 中国论文写发网提供免费论文,职称论文,毕业论文,硕士论文,本科论文,MBA论文,电大论文,述职报告,论文下载,工作总结,论文推荐发表,论文写作指导,论文翻译等服务,网址www.lwxfw.com
专注代写论文网,论文代写,硕士论文代写,博士论文代写 http://www.dmozdir.org/SiteInformation/?www.zzlunwen010.com-----28351-----.shtml 专注代写论文网,论文代写,硕士论文代写,博士论文代写,各类职称论文代写代发!
论文天下 http://www.dmozdir.org/SiteInformation/?www.su30.net-----20547-----.shtml 论文天下,免费提供:论文范文,免费论文,论文大全, 论文下载,论文格式,论文提纲,论文发表,论文开题报告,论文题目等资料的查阅,有偿提供:论文代写、代发服 务!
河南教师网 http://www.dmozdir.org/SiteInformation/?www.hateacher.com-----31307-----.shtml 河南教师网/河南教师考试网/河南教师资格网/河南教育信息网/河南教师资格证历年真题/河南教师资格证复习资料/河南招教考试真题/河南招教考试复习资料/学习笔 记/中国招教网/河南招教网/河南教师资格网
久久论文检测 http://www.dmozdir.org/SiteInformation/?www.99fx.net-----38891-----.shtml 久久论文检测网专业提供免费论文检测、论文检测软件、论文抄袭检测、知网论文检测、万方论文检测、论文修改资料以及免费论文检测系统。让您毕业答辩无忧!
李国旺工作室 http://www.dmozdir.org/SiteInformation/?www.lgwlncy.com-----12221-----.shtml 高三政治教学,政治高考,高中政治新课标,政治试卷,高中政治网址。
笔杆子论文 http://www.dmozdir.org/SiteInformation/?www.bgzlw.com-----45851-----.shtml 笔杆子论文网提供免费论文、毕业论文、论文范文、论文下载、各专业论文、工作总结、论文定制、发表论文、购买论文、论文写作指导等服务
中国论文热线网 http://www.dmozdir.org/SiteInformation/?www.lwrxw.com-----15692-----.shtml 中国论文热线网提供职称论文推荐发表、省级刊物、核心刊物、CN、ISSN刊物推荐发表等服务,可以推荐发表多专业职称论文,是您职称评审论文发表的最佳伙伴,网址www.lwrxw.com
就要学习网 http://www.dmozdir.org/SiteInformation/?www.62355065.cn-----11960-----.shtml 就要学习网是集教案,课件,试卷,毕业论文,教学视频为一体的免费资源网。
新论文代写网 http://www.dmozdir.org/SiteInformation/?www.newlw.com-----25276-----.shtml 毕业论文|毕业设计|毕业论文范文|计算机毕业设计|毕业论文格式范文|机械毕业设计|行政管理毕业论文|毕业设计开题报告|计算机网络毕业论文|毕业设计论文|毕业论 文网|代做毕业设计|怎样写毕业论文
天喜缘婚介网-最好的婚征婚介网站 http://www.dmozdir.org/SiteInformation/?www.love219.com-----14846-----.shtml 天喜缘婚介婚庆网是济南最专业的婚介网站、婚庆网站,交友网站,及济南征婚、济南交友、济南婚介、济南庆典、济南礼仪于一体,网下有实体店面-济南市市中区天喜缘婚介婚庆中心,不定期举办联谊活动,保证会员成功率
成都盛世阳光婚庆策划有限公司 http://www.dmozdir.org/SiteInformation/?www.ssyg520.com-----27215-----.shtml 诚信投资控股集团属于四川省大型企业集团,川内排于前20名,注册资金3.5亿元,拥有固定资产46.5亿。公司总部位于成都市致民东路1号。在北京 、上海、新疆等地设有分公司。诚信盛世阳光婚庆公司是其子公司。
情人网 http://www.dmozdir.org/SiteInformation/?www.591lover.net-----36999-----.shtml 情人网交友中心为你提供最佳的网上情人交友机会,足不出户便能让你有更多的选择!
国际免费婚介交友网站-相约100 http://www.dmozdir.org/SiteInformation/?www.free-onlinedating.me-----10110-----.shtml 国际免费婚介交友网站是相约100提供的完全免费的国际交友网站。会员以华人为主遍布五湖四海,所有会员完全免费。所有寻找国际免费婚介交友网站的朋友都能在国际交友网站在找到完全免费的国际免费婚介交友网站服务
安徽婚庆网 http://www.dmozdir.org/SiteInformation/?www.ahhqw.com-----18983-----.shtml 安徽婚庆网
聚缘北海交友网 http://www.dmozdir.org/SiteInformation/?www.jyjjyy.com-----19343-----.shtml 聚缘北海交友网是北海地区较规范的婚恋交友网站,致力于营造有趣而安全的网络交友社区,提供搜索、美文、约会、日记、聊天、等多项交友服务。并与地方婚介部门建立了良好的合作关系。
爱我吧婚恋网 http://www.dmozdir.org/SiteInformation/?www.lovemeba.com-----9983-----.shtml 爱我吧婚恋网是一个真实、严肃、高品位的婚恋平台,提供科学、高效的全程服务,帮助真心寻找终身伴侣的人士实现和谐婚恋,努力营造国内最专业、严肃的婚恋交 友平
77国际交友网 http://www.dmozdir.org/SiteInformation/?www.77lds.com-----37176-----.shtml 纯公益性,爱心社交网站,为广大青年及单身人士提供的全免费交友平台。
东莞韩风尚婚纱摄影工作室 http://www.dmozdir.org/SiteInformation/?www.dg-hfs.com-----18760-----.shtml 东莞韩风尚婚纱摄影工作室是具有独特的韩国风格的东莞婚纱摄影工作室,韩风尚位于东莞东城区旗峰路国泰大厦10号,我们永远满怀创意与温情,通过一对一的服务为您提供超越您期望
百合婚礼社区 http://www.dmozdir.org/SiteInformation/?www.lilywed.cn-----9976-----.shtml 百合婚礼社区讨论话题涵盖婚纱照、婚纱摄影、婚礼筹备、婚纱礼服、婚庆等方面
2018-12-17 19:32:49 [scrapy.core.engine] INFO: Closing spider (finished)
2018-12-17 19:32:49 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 698,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 14618,
'downloader/response_count': 3,
'downloader/response_status_count/200': 3,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 12, 17, 11, 32, 49, 552593),
'log_count/DEBUG': 4,
'log_count/INFO': 7,
'response_received_count': 3,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2018, 12, 17, 11, 32, 49, 93393)}
2018-12-17 19:32:49 [scrapy.core.engine] INFO: Spider closed (finished)
我们就看中间这一部分:
2018-12-17 19:32:49 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=230> (referer: None)
2018-12-17 19:32:49 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=411> (referer: None)
中国论文写发网 http://www.dmozdir.org/SiteInformation/?www.lwxfw.com-----13589-----.shtml 中国论文写发网提供免费论文,职称论文,毕业论文,硕士论文,本科论文,MBA论文,电大论文,述职报告,论文下载,工作总结,论文推荐发表,论文写作指导,论文翻译等服务,网址www.lwxfw.com
专注代写论文网,论文代写,硕士论文代写,博士论文代写 http://www.dmozdir.org/SiteInformation/?www.zzlunwen010.com-----28351-----.shtml 专注代写论文网,论文代写,硕士论文代写,博士论文代写,各类职称论文代写代发!
论文天下 http://www.dmozdir.org/SiteInformation/?www.su30.net-----20547-----.shtml 论文天下,免费提供:论文范文,免费论文,论文大全, 论文下载,论文格式,论文提纲,论文发表,论文开题报告,论文题目等资料的查阅,有偿提供:论文代写、代发服 务!
河南教师网 http://www.dmozdir.org/SiteInformation/?www.hateacher.com-----31307-----.shtml 河南教师网/河南教师考试网/河南教师资格网/河南教育信息网/河南教师资格证历年真题/河南教师资格证复习资料/河南招教考试真题/河南招教考试复习资料/学习笔 记/中国招教网/河南招教网/河南教师资格网
久久论文检测 http://www.dmozdir.org/SiteInformation/?www.99fx.net-----38891-----.shtml 久久论文检测网专业提供免费论文检测、论文检测软件、论文抄袭检测、知网论文检测、万方论文检测、论文修改资料以及免费论文检测系统。让您毕业答辩无忧!
李国旺工作室 http://www.dmozdir.org/SiteInformation/?www.lgwlncy.com-----12221-----.shtml 高三政治教学,政治高考,高中政治新课标,政治试卷,高中政治网址。
笔杆子论文 http://www.dmozdir.org/SiteInformation/?www.bgzlw.com-----45851-----.shtml 笔杆子论文网提供免费论文、毕业论文、论文范文、论文下载、各专业论文、工作总结、论文定制、发表论文、购买论文、论文写作指导等服务
中国论文热线网 http://www.dmozdir.org/SiteInformation/?www.lwrxw.com-----15692-----.shtml 中国论文热线网提供职称论文推荐发表、省级刊物、核心刊物、CN、ISSN刊物推荐发表等服务,可以推荐发表多专业职称论文,是您职称评审论文发表的最佳伙伴,网址www.lwrxw.com
就要学习网 http://www.dmozdir.org/SiteInformation/?www.62355065.cn-----11960-----.shtml 就要学习网是集教案,课件,试卷,毕业论文,教学视频为一体的免费资源网。
新论文代写网 http://www.dmozdir.org/SiteInformation/?www.newlw.com-----25276-----.shtml 毕业论文|毕业设计|毕业论文范文|计算机毕业设计|毕业论文格式范文|机械毕业设计|行政管理毕业论文|毕业设计开题报告|计算机网络毕业论文|毕业设计论文|毕业论 文网|代做毕业设计|怎样写毕业论文
天喜缘婚介网-最好的婚征婚介网站 http://www.dmozdir.org/SiteInformation/?www.love219.com-----14846-----.shtml 天喜缘婚介婚庆网是济南最专业的婚介网站、婚庆网站,交友网站,及济南征婚、济南交友、济南婚介、济南庆典、济南礼仪于一体,网下有实体店面-济南市市中区天喜缘婚介婚庆中心,不定期举办联谊活动,保证会员成功率
成都盛世阳光婚庆策划有限公司 http://www.dmozdir.org/SiteInformation/?www.ssyg520.com-----27215-----.shtml 诚信投资控股集团属于四川省大型企业集团,川内排于前20名,注册资金3.5亿元,拥有固定资产46.5亿。公司总部位于成都市致民东路1号。在北京 、上海、新疆等地设有分公司。诚信盛世阳光婚庆公司是其子公司。
情人网 http://www.dmozdir.org/SiteInformation/?www.591lover.net-----36999-----.shtml 情人网交友中心为你提供最佳的网上情人交友机会,足不出户便能让你有更多的选择!
国际免费婚介交友网站-相约100 http://www.dmozdir.org/SiteInformation/?www.free-onlinedating.me-----10110-----.shtml 国际免费婚介交友网站是相约100提供的完全免费的国际交友网站。会员以华人为主遍布五湖四海,所有会员完全免费。所有寻找国际免费婚介交友网站的朋友都能在国际交友网站在找到完全免费的国际免费婚介交友网站服务
安徽婚庆网 http://www.dmozdir.org/SiteInformation/?www.ahhqw.com-----18983-----.shtml 安徽婚庆网
聚缘北海交友网 http://www.dmozdir.org/SiteInformation/?www.jyjjyy.com-----19343-----.shtml 聚缘北海交友网是北海地区较规范的婚恋交友网站,致力于营造有趣而安全的网络交友社区,提供搜索、美文、约会、日记、聊天、等多项交友服务。并与地方婚介部门建立了良好的合作关系。
爱我吧婚恋网 http://www.dmozdir.org/SiteInformation/?www.lovemeba.com-----9983-----.shtml 爱我吧婚恋网是一个真实、严肃、高品位的婚恋平台,提供科学、高效的全程服务,帮助真心寻找终身伴侣的人士实现和谐婚恋,努力营造国内最专业、严肃的婚恋交 友平
77国际交友网 http://www.dmozdir.org/SiteInformation/?www.77lds.com-----37176-----.shtml 纯公益性,爱心社交网站,为广大青年及单身人士提供的全免费交友平台。
东莞韩风尚婚纱摄影工作室 http://www.dmozdir.org/SiteInformation/?www.dg-hfs.com-----18760-----.shtml 东莞韩风尚婚纱摄影工作室是具有独特的韩国风格的东莞婚纱摄影工作室,韩风尚位于东莞东城区旗峰路国泰大厦10号,我们永远满怀创意与温情,通过一对一的服务为您提供超越您期望
百合婚礼社区 http://www.dmozdir.org/SiteInformation/?www.lilywed.cn-----9976-----.shtml 百合婚礼社区讨论话题涵盖婚纱照、婚纱摄影、婚礼筹备、婚纱礼服、婚庆等方面
上面的结果没有错误。
这个是爬和取的过程,我们接下来就要使用 Items,我们前面说过,Items 是我们自定义的容器,用法和Python的字典是一样的,我们希望 Spider 将爬取然后筛选后的数据存放到 Items 容器里面,我们刚才也在 parse 里写了筛选出 Items 对应的数据的方法了。筛选之后,我希望将它存放到 Items 中去。
我们的 items.py 在 tutorial/items.py 路径下,items 既是容器,也是一个类,类名我们在这个项目中定义为 DmozItem。
我们需要 把 items 导入到 spider 中,才可以使用它,于是,我们在 dmoz_spider.py 文件中写道:
from turtorial.items import DmozItem
#dmoz_spider.py
import scrapy
from tutorial.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ['dmozdir.org/Category']
start_urls = ['http://www.dmozdir.org/Category/?SmallPath=230',
'http://www.dmozdir.org/Category/?SmallPath=411']
def parse(self, response):
titles = response.selector.xpath('//ul/li/h4/a/text()').extract() #标题 title
links = response.selector.xpath('//ul/li/h4/a/@href').extract() #超链接 link
descs = response.selector.xpath('//ul/li/p/text()').extract() #描述 desc
items = []
if len(titles) == len(links) == len(descs):
for i in range(len(titles)):
#print(titles[i], links[i], decss[i])
item = DmozItem()
#每一组保存为一个字典
item['title'] = titles[i]
item['link'] = links[i]
item['desc'] = descs[i]
#将每个字典添加到列表中
items.append(item)
return items
然后我们在CMD 中,tutorail 的根目录下,执行命令:scrapy crawl dmoz -o items.json -t json
-o 文件名 -t 保存形式。
#CMD窗口
C:\Users\XiangyangDai\Desktop\tutorial>scrapy crawl dmoz -o items.json -t json
2018-12-17 20:49:28 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: tutorial)
2018-12-17 20:49:28 [scrapy.utils.log] INFO: Versions: lxml 4.2.5.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted 18.9.0, Python 3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0j 20 Nov 2018), cryptography 2.4.2, Platform Windows-10-10.0.17134-SP0
2018-12-17 20:49:28 [scrapy.crawler] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'tutorial.spiders', 'SPIDER_MODULES': ['tutorial.spiders'], 'FEED_URI': 'items.json', 'BOT_NAME': 'tutorial', 'ROBOTSTXT_OBEY': True, 'FEED_FORMAT': 'json'}
2018-12-17 20:49:28 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2018-12-17 20:49:29 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-12-17 20:49:29 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-12-17 20:49:29 [scrapy.middleware] INFO: Enabled item pipelines:
['tutorial.pipelines.TutorialPipeline']
2018-12-17 20:49:29 [scrapy.core.engine] INFO: Spider opened
2018-12-17 20:49:29 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-12-17 20:49:29 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-12-17 20:49:29 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/robots.txt> (referer: None)
2018-12-17 20:49:29 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=230> (referer: None)
2018-12-17 20:49:29 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=411> (referer: None)
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=230>
{'desc': '中国论文写发网提供免费论文,职称论文,毕业论文,硕士论文,本科论文,MBA论文,电大论文,述职报告,论文下载,工作总结,论文推荐发表,论文写作指导,论文翻译等服务,网址www.lwxfw.com',
'link': 'http://www.dmozdir.org/SiteInformation/?www.lwxfw.com-----13589-----.shtml',
'title': '中国论文写发网'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=230>
{'desc': '专注代写论文网,论文代写,硕士论文代写,博士论文代写,各类职称论文代写代发!',
'link': 'http://www.dmozdir.org/SiteInformation/?www.zzlunwen010.com-----28351-----.shtml',
'title': '专注代写论文网,论文代写,硕士论文代写,博士论文代写'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=230>
{'desc': '论文天下,免费提供:论文范文,免费论文,论文大全, '
'论文下载,论文格式,论文提纲,论文发表,论文开题报告,论文题目等资料的查阅,有偿提供:论文代写、代发服务!',
'link': 'http://www.dmozdir.org/SiteInformation/?www.su30.net-----20547-----.shtml',
'title': '论文天下'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=230>
{'desc': '河南教师网/河南教师考试网/河南教师资格网/河南教育信息网/河南教师资格证历年真题/河南教师资格证复习资料/河南招教考试真题/河南招教考试复习资料/学习笔记/中国招教网/河南招教网/河南教师资格网',
'link': 'http://www.dmozdir.org/SiteInformation/?www.hateacher.com-----31307-----.shtml',
'title': '河南教师网'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=230>
{'desc': '久久论文检测网专业提供免费论文检测、论文检测软件、论文抄袭检测、知网论文检测、万方论文检测、论文修改资料以及免费论文检测系统。让您毕业答辩无忧!',
'link': 'http://www.dmozdir.org/SiteInformation/?www.99fx.net-----38891-----.shtml',
'title': '久久论文检测'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=230>
{'desc': '高三政治教学,政治高考,高中政治新课标,政治试卷,高中政治网址。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.lgwlncy.com-----12221-----.shtml',
'title': '李国旺工作室'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=230>
{'desc': '笔杆子论文网提供免费论文、毕业论文、论文范文、论文下载、各专业论文、工作总结、论文定制、发表论文、购买论文、论文写作指导等服务',
'link': 'http://www.dmozdir.org/SiteInformation/?www.bgzlw.com-----45851-----.shtml',
'title': '笔杆子论文'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=230>
{'desc': '中国论文热线网提供职称论文推荐发表、省级刊物、核心刊物、CN、ISSN刊物推荐发表等服务,可以推荐发表多专业职称论文,是您职称评审论文发表的最佳伙伴,网址www.lwrxw.com',
'link': 'http://www.dmozdir.org/SiteInformation/?www.lwrxw.com-----15692-----.shtml',
'title': '中国论文热线网'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=230>
{'desc': '就要学习网是集教案,课件,试卷,毕业论文,教学视频为一体的免费资源网。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.62355065.cn-----11960-----.shtml',
'title': '就要学习网'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=230>
{'desc': '毕业论文|毕业设计|毕业论文范文|计算机毕业设计|毕业论文格式范文|机械毕业设计|行政管理毕业论文|毕业设计开题报告|计算机网络毕业论文|毕业设计论文|毕业论文网|代做毕业设计|怎样写毕业论文',
'link': 'http://www.dmozdir.org/SiteInformation/?www.newlw.com-----25276-----.shtml',
'title': '新论文代写网'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=411>
{'desc': '天喜缘婚介婚庆网是济南最专业的婚介网站、婚庆网站,交友网站,及济南征婚、济南交友、济南婚介、济南庆典、济南礼仪于一体,网下有实体店面-济南市市中区天喜缘婚介婚庆中心,不定期举办联谊活动,保证会员成功率',
'link': 'http://www.dmozdir.org/SiteInformation/?www.love219.com-----14846-----.shtml',
'title': '天喜缘婚介网-最好的婚征婚介网站'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=411>
{'desc': '诚信投资控股集团属于四川省大型企业集团,川内排于前20名,注册资金3.5亿元,拥有固定资产46.5亿。公司总部位于成都市致民东路1号。在北京、上海、新疆等地设有分公司。诚信盛世阳光婚庆公司是其子公司。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.ssyg520.com-----27215-----.shtml',
'title': '成都盛世阳光婚庆策划有限公司'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=411>
{'desc': '情人网交友中心为你提供最佳的网上情人交友机会,足不出户便能让你有更多的选择!',
'link': 'http://www.dmozdir.org/SiteInformation/?www.591lover.net-----36999-----.shtml',
'title': '情人网'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=411>
{'desc': '国际免费婚介交友网站是相约100提供的完全免费的国际交友网站。会员以华人为主遍布五湖四海,所有会员完全免费。所有寻找国际免费婚介交友网站的朋友都能在国际交友网站在找到完全免费的国际免费婚介交友网站服务',
'link': 'http://www.dmozdir.org/SiteInformation/?www.free-onlinedating.me-----10110-----.shtml',
'title': '国际免费婚介交友网站-相约100'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=411>
{'desc': '安徽婚庆网',
'link': 'http://www.dmozdir.org/SiteInformation/?www.ahhqw.com-----18983-----.shtml',
'title': '安徽婚庆网'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=411>
{'desc': '聚缘北海交友网是北海地区较规范的婚恋交友网站,致力于营造有趣而安全的网络交友社区,提供搜索、美文、约会、日记、聊天、等多项交友服务。并与地方婚介部门建立了良好的合作关系。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.jyjjyy.com-----19343-----.shtml',
'title': '聚缘北海交友网'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=411>
{'desc': '爱我吧婚恋网是一个真实、严肃、高品位的婚恋平台,提供科学、高效的全程服务,帮助真心寻找终身伴侣的人士实现和谐婚恋,努力营造国内最专业、严肃的婚恋交友平',
'link': 'http://www.dmozdir.org/SiteInformation/?www.lovemeba.com-----9983-----.shtml',
'title': '爱我吧婚恋网'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=411>
{'desc': '纯公益性,爱心社交网站,为广大青年及单身人士提供的全免费交友平台。',
'link': 'http://www.dmozdir.org/SiteInformation/?www.77lds.com-----37176-----.shtml',
'title': '77国际交友网'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=411>
{'desc': '东莞韩风尚婚纱摄影工作室是具有独特的韩国风格的东莞婚纱摄影工作室,韩风尚位于东莞东城区旗峰路国泰大厦10号,我们永远满怀创意与温情,通过一对一的服务为您提供超越您期望',
'link': 'http://www.dmozdir.org/SiteInformation/?www.dg-hfs.com-----18760-----.shtml',
'title': '东莞韩风尚婚纱摄影工作室'}
2018-12-17 20:49:30 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=411>
{'desc': '百合婚礼社区讨论话题涵盖婚纱照、婚纱摄影、婚礼筹备、婚纱礼服、婚庆等方面',
'link': 'http://www.dmozdir.org/SiteInformation/?www.lilywed.cn-----9976-----.shtml',
'title': '百合婚礼社区'}
2018-12-17 20:49:30 [scrapy.core.engine] INFO: Closing spider (finished)
2018-12-17 20:49:30 [scrapy.extensions.feedexport] INFO: Stored json feed (20 items) in: items.json
2018-12-17 20:49:30 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 698,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 14618,
'downloader/response_count': 3,
'downloader/response_status_count/200': 3,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 12, 17, 12, 49, 30, 79269),
'item_scraped_count': 20,
'log_count/DEBUG': 24,
'log_count/INFO': 8,
'response_received_count': 3,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2018, 12, 17, 12, 49, 29, 574379)}
2018-12-17 20:49:30 [scrapy.core.engine] INFO: Spider closed (finished)
执行完毕后,在 tutorial 根目录 下就会有一个名为 items.json 的文件。
内容如下:
#items.json 文件内容
[
{"title": "\u4e2d\u56fd\u8bba\u6587\u5199\u53d1\u7f51", "desc": "\u4e2d\u56fd\u8bba\u6587\u5199\u53d1\u7f51\u63d0\u4f9b\u514d\u8d39\u8bba\u6587,\u804c\u79f0\u8bba\u6587,\u6bd5\u4e1a\u8bba\u6587,\u7855\u58eb\u8bba\u6587,\u672c\u79d1\u8bba\u6587,MBA\u8bba\u6587,\u7535\u5927\u8bba\u6587,\u8ff0\u804c\u62a5\u544a,\u8bba\u6587\u4e0b\u8f7d,\u5de5\u4f5c\u603b\u7ed3,\u8bba\u6587\u63a8\u8350\u53d1\u8868,\u8bba\u6587\u5199\u4f5c\u6307\u5bfc,\u8bba\u6587\u7ffb\u8bd1\u7b49\u670d\u52a1,\u7f51\u5740www.lwxfw.com", "link": "http://www.dmozdir.org/SiteInformation/?www.lwxfw.com-----13589-----.shtml"},
{"title": "\u4e13\u6ce8\u4ee3\u5199\u8bba\u6587\u7f51,\u8bba\u6587\u4ee3\u5199,\u7855\u58eb\u8bba\u6587\u4ee3\u5199,\u535a\u58eb\u8bba\u6587\u4ee3\u5199", "desc": "\u4e13\u6ce8\u4ee3\u5199\u8bba\u6587\u7f51,\u8bba\u6587\u4ee3\u5199,\u7855\u58eb\u8bba\u6587\u4ee3\u5199,\u535a\u58eb\u8bba\u6587\u4ee3\u5199,\u5404\u7c7b\u804c\u79f0\u8bba\u6587\u4ee3\u5199\u4ee3\u53d1!", "link": "http://www.dmozdir.org/SiteInformation/?www.zzlunwen010.com-----28351-----.shtml"},
...此处省略
得到的保存的文件的内容就是我们需要的,但是这是二进制编码的形式。
用于 Python 3 的方案
首先需要解释一点就是:pipeline.py 就是用于处理 item 的,所以,我们在pipeline.py 文件中对保存的文件进行处理操作:
将 pipeline.py 写成这样:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class TutorialPipeline(object):
def __init__(self):
self.f = open('items.json', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii = False) + "\n"
self.f.write(line.encode('utf-8'))
return item
def close_spider(self, spider):
self.f.close()
因为读取到的网页是 二进制文件,所以我们在__init__ 方法中, 建一个名为 items.json 的文件,以二进制形式写入。
在 process_item 方法中,对 item 文件进行编码 写入操作,最后在 close_spider 方法中,关闭文件。
接下来,就在 settings.py 文件中开启 pipeline,加入下面的命令即可:
ITEM_PIPELINES = {
'tutorial.pipelines.TutorialPipeline': 300,
}
其中,TutorialPipeline 就是 pipeline.py 文件中的 类名
另外有一点需要提醒的是:
因为我们在 pipeline.py 中完成了新建文件的操作,所以 在CMD 中输入的命令 应该改为:scrapy crawl dmoz -t json
C:\Users\XiangyangDai\Desktop\tutorial>scrapy crawl dmoz -t json
2018-12-17 21:43:57 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: tutorial)
2018-12-17 21:43:57 [scrapy.utils.log] INFO: Versions: lxml 4.2.5.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted 18.9.0, Python 3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0j 20 Nov 2018), cryptography 2.4.2, Platform Windows-10-10.0.17134-SP0
2018-12-17 21:43:57 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'tutorial', 'NEWSPIDER_MODULE': 'tutorial.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['tutorial.spiders']}
2018-12-17 21:43:57 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.logstats.LogStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2018-12-17 21:43:58 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-12-17 21:43:58 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-12-17 21:43:58 [scrapy.middleware] INFO: Enabled item pipelines:
['tutorial.pipelines.TutorialPipeline']
2018-12-17 21:43:58 [scrapy.core.engine] INFO: Spider opened
2018-12-17 21:43:58 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-12-17 21:43:58 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-12-17 21:43:58 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/robots.txt> (referer: None)
2018-12-17 21:43:58 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=230> (referer: None)
2018-12-17 21:43:58 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.dmozdir.org/Category/?SmallPath=411> (referer: None)
2018-12-17 21:43:58 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=230>
{'desc': '中国论文写发网提供免费论文,职称论文,毕业论文,硕士论文,本科论文,MBA论文,电大论文,述职报告,论文下载,工作总结,论 文推荐发表,论文写作指导,论文翻译等服务,网址www.lwxfw.com',
'link': 'http://www.dmozdir.org/SiteInformation/?www.lwxfw.com-----13589-----.shtml',
'title': '中国论文写发网'}
2018-12-17 21:43:58 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.dmozdir.org/Category/?SmallPath=230>
{'desc': '专注代写论文网,论文代写,硕士论文代写,博士论文代写,各类职称论文代写代发!',
'link': 'http://www.dmozdir.org/SiteInformation/?www.zzlunwen010.com-----28351-----.shtml',
'title': '专注代写论文网,论文代写,硕士论文代写,博士论文代写'}
...此处省略
2018-12-17 21:43:59 [scrapy.core.engine] INFO: Closing spider (finished)
2018-12-17 21:43:59 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 698,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 14618,
'downloader/response_count': 3,
'downloader/response_status_count/200': 3,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 12, 17, 13, 43, 59, 33263),
'item_scraped_count': 20,
'log_count/DEBUG': 24,
'log_count/INFO': 7,
'response_received_count': 3,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2018, 12, 17, 13, 43, 58, 626475)}
2018-12-17 21:43:59 [scrapy.core.engine] INFO: Spider closed (finished)
items.json 文件内容如下:
{"link": "http://www.dmozdir.org/SiteInformation/?www.lwxfw.com-----13589-----.shtml", "title": "中国论文写发网", "desc": "中国论文写发网提供免费论文,职称论文,毕业论文,硕士论文,本科论文,MBA论文,电大论文,述职报告,论文下载,工作总结,论文推荐发表,论文写作指导,论文翻译等服务,网址www.lwxfw.com"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.zzlunwen010.com-----28351-----.shtml", "title": "专注代写论文网,论文代写,硕士论文代写,博士论文代写", "desc": "专注代写论文网,论文代写,硕士论文代写,博士论文代写,各类职称论文代写代发!"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.su30.net-----20547-----.shtml", "title": "论文天下", "desc": "论文天下,免费提供:论文范文,免费论文,论文大全, 论文下载,论文格式,论文提纲,论文发表,论文开题报告,论文题目等资料的查阅,有偿提供:论文代写、代发服务!"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.hateacher.com-----31307-----.shtml", "title": "河南教师网", "desc": "河南教师网/河南教师考试网/河南教师资格网/河南教育信息网/河南教师资格证历年真题/河南教师资格证复习资料/河南招教考试真题/河南招教考试复习资料/学习笔记/中国招教网/河南招教网/河南教师资格网"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.99fx.net-----38891-----.shtml", "title": "久久论文检测", "desc": "久久论文检测网专业提供免费论文检测、论文检测软件、论文抄袭检测、知网论文检测、万方论文检测、论文修改资料以及免费论文检测系统。让您毕业答辩无忧!"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.lgwlncy.com-----12221-----.shtml", "title": "李国旺工作室", "desc": "高三政治教学,政治高考,高中政治新课标,政治试卷,高中政治网址。"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.bgzlw.com-----45851-----.shtml", "title": "笔杆子论文", "desc": "笔杆子论文网提供免费论文、毕业论文、论文范文、论文下载、各专业论文、工作总结、论文定制、发表论文、购买论文、论文写作指导等服务"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.lwrxw.com-----15692-----.shtml", "title": "中国论文热线网", "desc": "中国论文热线网提供职称论文推荐发表、省级刊物、核心刊物、CN、ISSN刊物推荐发表等服务,可以推荐发表多专业职称论文,是您职称评审论文发表的最佳伙伴,网址www.lwrxw.com"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.62355065.cn-----11960-----.shtml", "title": "就要学习网", "desc": "就要学习网是集教案,课件,试卷,毕业论文,教学视频为一体的免费资源网。"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.newlw.com-----25276-----.shtml", "title": "新论文代写网", "desc": "毕业论文|毕业设计|毕业论文范文|计算机毕业设计|毕业论文格式范文|机械毕业设计|行政管理毕业论文|毕业设计开题报告|计算机网络毕业论文|毕业设计论文|毕业论文网|代做毕业设计|怎样写毕业论文"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.love219.com-----14846-----.shtml", "title": "天喜缘婚介网-最好的婚征婚介网站", "desc": "天喜缘婚介婚庆网是济南最专业的婚介网站、婚庆网站,交友网站,及济南征婚、济南交友、济南婚介、济南庆典、济南礼仪于一体,网下有实体店面-济南市市中区天喜缘婚介婚庆中心,不定期举办联谊活动,保证会员成功率"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.ssyg520.com-----27215-----.shtml", "title": "成都盛世阳光婚庆策划有限公司", "desc": "诚信投资控股集团属于四川省大型企业集团,川内排于前20名,注册资金3.5亿元,拥有固定资产46.5亿。公司总部位于成都市致民东路1号。在北京、上海、新疆等地设有分公司。诚信盛世阳光婚庆公司是其子公司。"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.591lover.net-----36999-----.shtml", "title": "情人网", "desc": "情人网交友中心为你提供最佳的网上情人交友机会,足不出户便能让你有更多的选择!"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.free-onlinedating.me-----10110-----.shtml", "title": "国际免费婚介交友网站-相约100", "desc": "国际免费婚介交友网站是相约100提供的完全免费的国际交友网站。会员以华人为主遍布五湖四海,所有会员完全免费。所有寻找国际免费婚介交友网站的朋友都能在国际交友网站在找到完全免费的国际免费婚介交友网站服务"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.ahhqw.com-----18983-----.shtml", "title": "安徽婚庆网", "desc": "安徽婚庆网"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.jyjjyy.com-----19343-----.shtml", "title": "聚缘北海交友网", "desc": "聚缘北海交友网是北海地区较规范的婚恋交友网站,致力于营造有趣而安全的网络交友社区,提供搜索、美文、约会、日记、聊天、等多项交友服务。并与地方婚介部门建立了良好的合作关系。"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.lovemeba.com-----9983-----.shtml", "title": "爱我吧婚恋网", "desc": "爱我吧婚恋网是一个真实、严肃、高品位的婚恋平台,提供科学、高效的全程服务,帮助真心寻找终身伴侣的人士实现和谐婚恋,努力营造国内最专业、严肃的婚恋交友平"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.77lds.com-----37176-----.shtml", "title": "77国际交友网", "desc": "纯公益性,爱心社交网站,为广大青年及单身人士提供的全免费交友平台。"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.dg-hfs.com-----18760-----.shtml", "title": "东莞韩风尚婚纱摄影工作室", "desc": "东莞韩风尚婚纱摄影工作室是具有独特的韩国风格的东莞婚纱摄影工作室,韩风尚位于东莞东城区旗峰路国泰大厦10号,我们永远满怀创意与温情,通过一对一的服务为您提供超越您期望"}
{"link": "http://www.dmozdir.org/SiteInformation/?www.lilywed.cn-----9976-----.shtml", "title": "百合婚礼社区", "desc": "百合婚礼社区讨论话题涵盖婚纱照、婚纱摄影、婚礼筹备、婚纱礼服、婚庆等方面"}















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









