







########复习
# import codecs
#
# with codecs.open("1.txt","rwab") as f:#a追加 r读 w写 b二进制
# f.truncate() #清空
# f.write() #参数为字符串
# f.readlines() #返回对象是列表
#
# a = dict(a=1,b=2)
# print(dict(sorted(a.items(),key=lambda d:d[1])))
# a = lambda x: x*x
# print([x for x in range(1,10) if x%2==0])
#()装饰(迭代器) []列表生成式
#return yield
#列表相加list + list
#字典相加用update
'''
需求
组 人 人组关系表
'''
#组 test1 test2 test3
#人 aaa bbb ccc
#人组关系表 aaa test1 bbb test3 ccc test2
# 组 组员
#select 人 关系 关联 组ID
# select * from b,c where b.id = c.人ID
#select 组名 组id
# for i in x:
# for j in y:
# if x.id == y.组id
# 符合条件
# mmm = dict()
# for j in y:
# mmm[组id] = 组员名字
#
# result = dict() #key 组名 value list()
# nnn = list()
# for i in x:
# value = mmm.get(i.组id)
# if value == None:
# a = list()
# a.append(value)
# result[i.组名] = a
# result
#class
# 构造器 __init__(args)
#重写父类方法 super(子类,self)
#A(B)
#类
#main() : 实例化,调方法
#if __name__ == '__main__':
# main()
#__init__ __name__
# 装饰器
#在不改变现有函数情况下,给函数增加一些功能
def startEnd(fun):
def wrap(name):
print("start")
fun(name)
print("end")
return wrap
@startEnd
def hello(name):
print("hello {0}".format(name))
hello("jack")
import json
a = dict(hello="你好")
print(a)
print(a["hello"])
print(json.dumps(a, ensure_ascii=False)) ##python2解决乱码问题 .encode() python3直接加.encode()
'''
dump(s,f)
把json字符串s直接写入到文件中去
M = load(f)
直接把文件内容取出来,给M,M类unicode类型
前两个书处理字符串的
后两个是把字符串写入文件,或者解析出来的
'''
import codecs
import json
test = {"a":1,"b":2}
with codecs.open("1.txt","w") as f:
json.dump(test,f)
with codecs.open("1.txt","r") as f :
aa = json.loads(f)
print(aa)
print(type(aa))
'''
模块
'''
import os
os.mkdir #创建目录
os.path.exists() #判断文件是否存在
os.getcwd #pwd
os.chdir() #cd
import json
json.loads()#字符串-->python对象
load #文件加载成list dict
import commands getstatusoutput
import sys
sys.argv[1] #第一个参数
os.system("ipconfig") #运行系统命令
import random
random.random() #取一个0-1的值
random.randint(a,b) #取a-b随机一个整数
random.sample(itertable,k) #
random.randrange(1,100,2) #1 3 5 7 9以这个基数随机从1-99取数
import string
# import logging
# logger = logging.getLogger(__name__)
# logger.debug()
#
# import hashlib
# m = hashlib.md5()
# src = "asdsafd"
# m.update(bytes(src))
# m.hexdigest()
# from datetime import datetime
# datetime.now()
#datetime.year month day hour minute seconds
# datetime.now().strftime("%Y-%m-%d")
# import time
# time.time()
# time.sleep(10)
#
# from io import StringIO,BytesIO
# s = StringIO()
# s.write("hello world")
# s.getvalue()
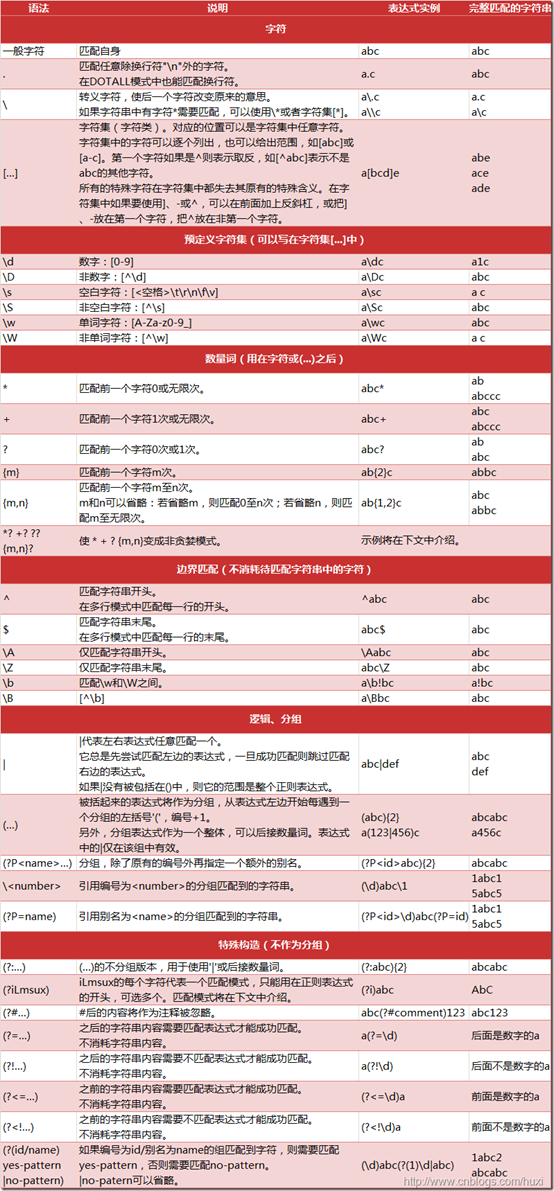
##在线正则表达式测试 https://regex101.com/ tool.oschina.net
'''<h1>xxx</h1> 查看不同匹配规则的效率'''
import re
import timeit
# print(timeit.timeit(setup='''import re; reg = re.compile('<(?P<tagname>\w*)>.*</(?P=tagname)>')''', stmt='''reg.match('<h1>xxx</h1>')''', number=1000000))
# print(timeit.timeit(setup='''import re''', stmt='''re.match('<(?P<tagname>\w*)>.*</(?P=tagname)>', '<h1>xxx</h1>')''', number=1000000))
s = "ab<h1>xxx</h1>dsafasdf<html>sdfads</html>"
reg = re.compile(r"(<(?P<tag>\w+)>(.*)</(?P=tag)>)")
print(reg.match(s))
print(reg.search(s).group(3))
print(reg.findall(s))
# print(reg.findall(s)[1])
# print(reg.findall(s)[2])
# reg.split(s)
# reg.findall(s)
# reg.groups(s)
x = '1one2two3three4four'
reg1 = re.compile("\d")
print(reg1.findall(x))
print(reg1.split(x))
# import codecs
#
# with codecs.open("1.txt","rwab") as f:#a追加 r读 w写 b二进制
# f.truncate() #清空
# f.write() #参数为字符串
# f.readlines() #返回对象是列表
#
# a = dict(a=1,b=2)
# print(dict(sorted(a.items(),key=lambda d:d[1])))
# a = lambda x: x*x
# print([x for x in range(1,10) if x%2==0])
#()装饰(迭代器) []列表生成式
#return yield
#列表相加list + list
#字典相加用update
'''
需求
组 人 人组关系表
'''
#组 test1 test2 test3
#人 aaa bbb ccc
#人组关系表 aaa test1 bbb test3 ccc test2
# 组 组员
#select 人 关系 关联 组ID
# select * from b,c where b.id = c.人ID
#select 组名 组id
# for i in x:
# for j in y:
# if x.id == y.组id
# 符合条件
# mmm = dict()
# for j in y:
# mmm[组id] = 组员名字
#
# result = dict() #key 组名 value list()
# nnn = list()
# for i in x:
# value = mmm.get(i.组id)
# if value == None:
# a = list()
# a.append(value)
# result[i.组名] = a
# result
#class
# 构造器 __init__(args)
#重写父类方法 super(子类,self)
#A(B)
#类
#main() : 实例化,调方法
#if __name__ == '__main__':
# main()
#__init__ __name__
# 装饰器
#在不改变现有函数情况下,给函数增加一些功能
def startEnd(fun):
def wrap(name):
print("start")
fun(name)
print("end")
return wrap
@startEnd
def hello(name):
print("hello {0}".format(name))
hello("jack")
import json
a = dict(hello="你好")
print(a)
print(a["hello"])
print(json.dumps(a, ensure_ascii=False)) ##python2解决乱码问题 .encode() python3直接加.encode()
'''
dump(s,f)
把json字符串s直接写入到文件中去
M = load(f)
直接把文件内容取出来,给M,M类unicode类型
前两个书处理字符串的
后两个是把字符串写入文件,或者解析出来的
'''
import codecs
import json
test = {"a":1,"b":2}
with codecs.open("1.txt","w") as f:
json.dump(test,f)
with codecs.open("1.txt","r") as f :
aa = json.loads(f)
print(aa)
print(type(aa))
'''
模块
'''
import os
os.mkdir #创建目录
os.path.exists() #判断文件是否存在
os.getcwd #pwd
os.chdir() #cd
import json
json.loads()#字符串-->python对象
load #文件加载成list dict
import commands getstatusoutput
import sys
sys.argv[1] #第一个参数
os.system("ipconfig") #运行系统命令
import random
random.random() #取一个0-1的值
random.randint(a,b) #取a-b随机一个整数
random.sample(itertable,k) #
random.randrange(1,100,2) #1 3 5 7 9以这个基数随机从1-99取数
import string
# import logging
# logger = logging.getLogger(__name__)
# logger.debug()
#
# import hashlib
# m = hashlib.md5()
# src = "asdsafd"
# m.update(bytes(src))
# m.hexdigest()
# from datetime import datetime
# datetime.now()
#datetime.year month day hour minute seconds
# datetime.now().strftime("%Y-%m-%d")
# import time
# time.time()
# time.sleep(10)
#
# from io import StringIO,BytesIO
# s = StringIO()
# s.write("hello world")
# s.getvalue()
# s.truncate()
##在线正则表达式测试 https://regex101.com/ tool.oschina.net
'''<h1>xxx</h1> 查看不同匹配规则的效率'''
import re
import timeit
# print(timeit.timeit(setup='''import re; reg = re.compile('<(?P<tagname>\w*)>.*</(?P=tagname)>')''', stmt='''reg.match('<h1>xxx</h1>')''', number=1000000))
# print(timeit.timeit(setup='''import re''', stmt='''re.match('<(?P<tagname>\w*)>.*</(?P=tagname)>', '<h1>xxx</h1>')''', number=1000000))
s = "ab<h1>xxx</h1>dsafasdf<html>sdfads</html>"
reg = re.compile(r"(<(?P<tag>\w+)>(.*)</(?P=tag)>)")
print(reg.match(s))
print(reg.search(s).group(3))
print(reg.findall(s))
# print(reg.findall(s)[1])
# print(reg.findall(s)[2])
# reg.split(s)
# reg.findall(s)
# reg.groups(s)
x = '1one2two3three4four'
reg1 = re.compile("\d")
print(reg1.findall(x))
print(reg1.split(x))














 6017
6017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









