






思路如下:
- 访问网站
- 定位主页的搜索框,搜索想要搜索的关键词
- 模拟鼠标滑动
- 爬取数据
- 将数据保存至ecsel
- 定位跳转页面输入框,跳转到下一页继续爬取
访问网站的时,最好增加一些反爬参数
opt = ChromeOptions()
opt.add_experimental_option('excludeSwitches', ['enable-automation']) # 去除浏览器顶部显示受自动化程序控制
opt.add_experimental_option('detach', True) # 规避程序运行完自动退出浏览器
opt.add_argument('--ignore-certificate-errors')
opt.add_argument('--ignore-ssl-errors')
opt.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36')
定义模拟鼠标滚动的方法
原理就是执行JavaScript模拟鼠标滚动
def simulate_scroll():
#获取页面高度
page_height = driver.execute_script("return document.body.scrollHeight")
#定义滚动的步长
scroll_step = 300
#模拟慢滚动
current_position = 0
while current_position < page_height:
#计算下一个滚动位置
next_position = current_position + scroll_step
driver.execute_script(f"window.scrollTo(0,{next_position})")
sleep(0.5)
#更新位置
current_position = next_position 定义爬取数据方法
这里就用xpath提取数据就行,但要注意一点就是京东页面跳转有时候会出现数据加载失败,导致数据无法更新,此时要分别定位最上面和最下面的两个重试按钮并点击
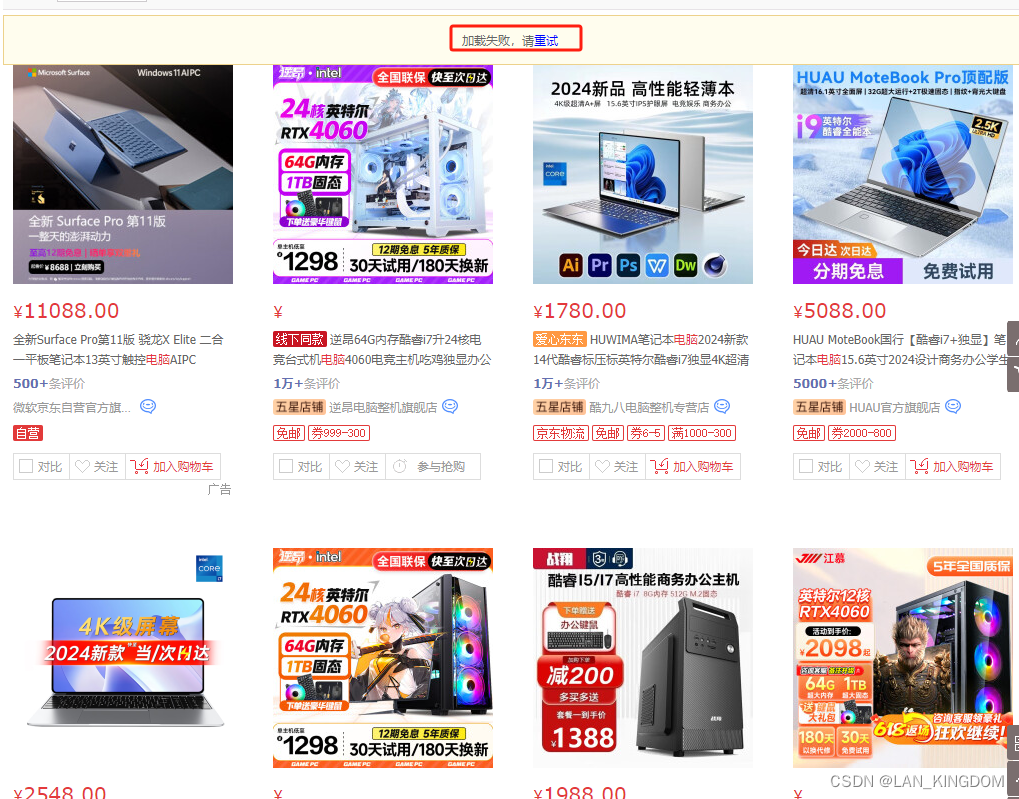
标题和评论我用了函数式写法,string(.)是获取该标签写的所有内容,因为有些内容不在同一个标签里
例如
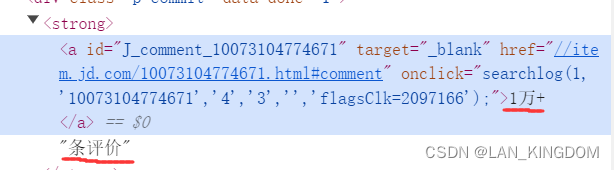
代码如下
def get_products(driver):
#如果出现数据加载失败,则点击重试
while True:
try:
a = WebDriverWait(driver, 2).until(EC.presence_of_element_located((By.XPATH,'//*[@id="J_scroll_loading"]/span/a/font')))
a.click()
except:
break
while True:
try:
a = WebDriverWait(driver, 2).until(EC.presence_of_element_located((By.XPATH,'//*[@id="J_loading"]/div/span/a/font')))
a.click()
except:
break
global cc
print(f"---------------------------------爬取{cc}页数据-------------------------------------")
e = etree.HTML(driver.page_source)
title = [em.xpath('string(.)') for em in e.xpath("//div[@class='gl-i-wrap']/div[@class='p-name p-name-type-2']/a/em")]
price = e.xpath("//ul[@class='gl-warp clearfix']/li/div/div/strong/i/text()")
comment = [strong.xpath('string(.)') for strong in e.xpath("//div[@class='p-commit']/strong")]
shop = e.xpath("//span[@class='J_im_icon']/a/text()")
for t, p, c, s in zip(title, price, comment, shop):
product = {
"商品简介": t,
"商品价格": p,
"评论数": c,
"店铺名称": s
}
ws.append([product['商品简介'], product['商品价格'], product['评论数'], product['店铺名称']])
print(product)
#下一页
cc = cc+1
a = WebDriverWait(driver,10).until(EC.presence_of_element_located((By.XPATH,"//span[@class='p-skip']/input[@class='input-txt']")))
a.clear()
a.send_keys(cc)
#模拟回车键
a.send_keys(Keys.RETURN)
完整代码如下
from selenium import webdriver
from lxml import etree
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver import ChromeOptions
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from openpyxl import Workbook
def get_driver(all_page,shopname):
global cc
#访问
opt = ChromeOptions()
opt.add_experimental_option('excludeSwitches', ['enable-automation']) # 去除浏览器顶部显示受自动化程序控制
opt.add_experimental_option('detach', True) # 规避程序运行完自动退出浏览器
opt.add_argument('--ignore-certificate-errors')
opt.add_argument('--ignore-ssl-errors')
opt.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36')
driver = webdriver.Chrome(options=opt)
# 解除浏览器特征识别selenium
script = 'Object.defineProperty(navigator,"webdriver", {get: () => false,});'
driver.execute_script(script)
driver.get('https://www.jd.com/')
#定位输入框
a = WebDriverWait(driver,10).until(EC.presence_of_element_located((By.XPATH,"//input[@id='key']")))
a.send_keys(shopname)
a = WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//button[@class='button']")))
a.click()
a = WebDriverWait(driver, 100).until(EC.presence_of_element_located((By.XPATH,"//div[@class='gl-i-wrap']/div[@class='p-name p-name-type-2']/a/em"))) #等待文本元素出现
while cc < all_page+1:
#滚动
simulate_scroll(driver)
#爬取
get_products(driver)
#写入xlsx
wb.save(r"京东数据.xlsx")
def simulate_scroll(driver):
global cc
# 获取页面高度
page_height = driver.execute_script("return document.body.scrollHeight")
#定义滚动步长和时间间隔
scroll_step = 300
#模拟慢慢滚动
current_position = 0
while current_position<page_height:
#计算下一个滚动位置
next_position = current_position + scroll_step
driver.execute_script(f"window.scrollTo(0,{next_position});")
sleep(0.2)
#更新当前位置
current_position = next_position
def get_products(driver):
#如果出现数据加载失败,则点击重试
while True:
try:
a = WebDriverWait(driver, 2).until(EC.presence_of_element_located((By.XPATH,'//*[@id="J_scroll_loading"]/span/a/font')))
a.click()
except:
break
while True:
try:
a = WebDriverWait(driver, 2).until(EC.presence_of_element_located((By.XPATH,'//*[@id="J_loading"]/div/span/a/font')))
a.click()
except:
break
global cc
print(f"---------------------------------爬取{cc}页数据-------------------------------------")
e = etree.HTML(driver.page_source)
title = [em.xpath('string(.)') for em in e.xpath("//div[@class='gl-i-wrap']/div[@class='p-name p-name-type-2']/a/em")]
price = e.xpath("//ul[@class='gl-warp clearfix']/li/div/div/strong/i/text()")
comment = [strong.xpath('string(.)') for strong in e.xpath("//div[@class='p-commit']/strong")]
shop = e.xpath("//span[@class='J_im_icon']/a/text()")
for t, p, c, s in zip(title, price, comment, shop):
product = {
"商品简介": t,
"商品价格": p,
"评论数": c,
"店铺名称": s
}
ws.append([product['商品简介'], product['商品价格'], product['评论数'], product['店铺名称']])
print(product)
#下一页
cc = cc+1
a = WebDriverWait(driver,10).until(EC.presence_of_element_located((By.XPATH,"//span[@class='p-skip']/input[@class='input-txt']")))
a.clear()
a.send_keys(cc)
#模拟回车键
a.send_keys(Keys.RETURN)
if __name__ == '__main__':
cc = 1
shopname = '电脑'
all_page = int(input("请输入要爬取的页数:"))
wb = Workbook() # 创建工作簿
ws = wb.active # 创建工作表
ws.append(["商品简介", "商品价格", "评论数", "店铺名称"])
get_driver(all_page,shopname)
效果如下(只展示了部分数据)
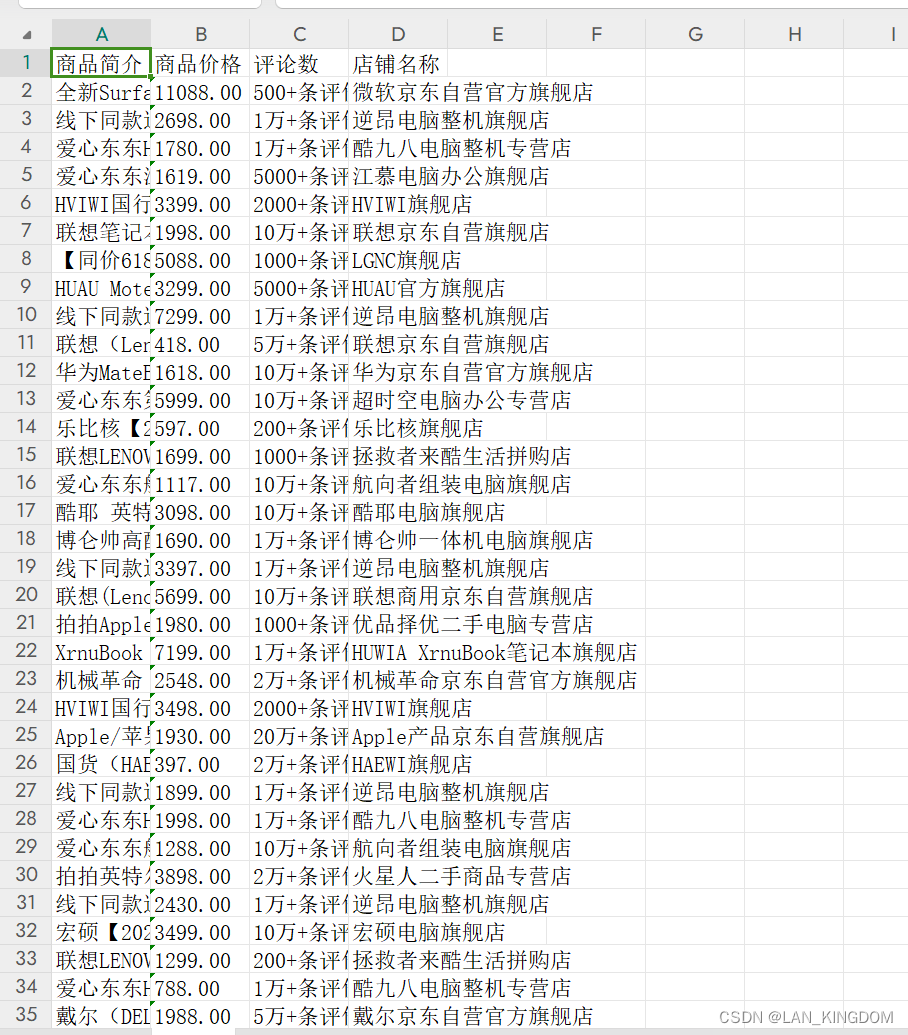
每一页的数据可能会爬得不是很全,会少那么几个。那是因为是网站的问题,会有几个商品的数据一直会加载不出来。















 2328
2328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









