






字节发力了。
论文链接
公式
GRPO公式:
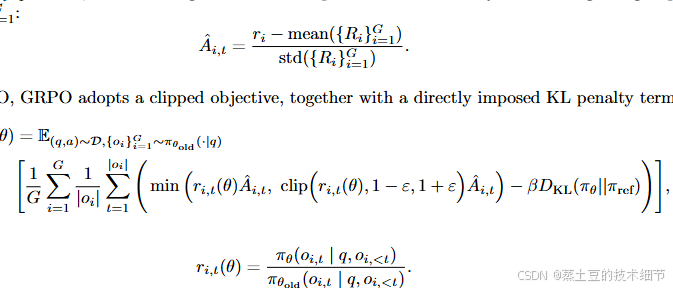
DAPO公式:
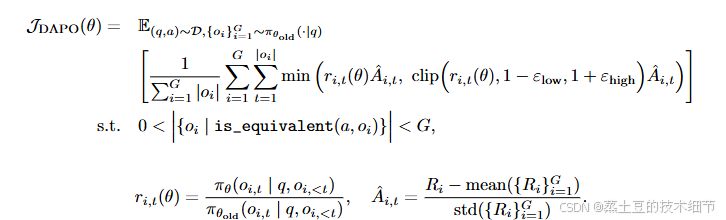
可见,其中有如下改动:
- KL散度去掉了,因为long cot要探索,本来就要大大偏离原模型。
- clip策略的上下截断超参数单独设定。如果clip太狠,模型梯度就很稳健(小),实验观察到该机制让模型早早地放弃了探索,在一次grpo的早期group采样里甚至出现一组都是一个采样的情况。举例来说,好的采样reward大,但是概率很小,前期本应大步地更新,结果一个clip限高了,就很难受。在所谓的生成熵上计算,发现很快就熵减了。所以肯定要全线拉高clip的上限和下限,提高探索效果。
- 如果一个group里都是正确答案,则rule-based reward相同,那么这一批就没东西可学了,这是不对的。该现象在训练中出现了,一个group里正确答案的比例在逐步升高,这导致后面的优化里,临近的group的优化方向gap较大,即方差较大。这里的改动是:在训练开始前,不停地采样,对那些准确率高的group要过采样,对低的要做过滤(也不能全是错的),感觉意思是让正确和错误的比例在一个平衡范围内。
- 改了一下求和方式。原先的是:每个句子token-level reward之和取平均,再在group里取平均。现在是所有token的reward加和,再除以这个group里的token总数。这样的好处是:group里更长的数据可以按比例地提供更多信号,如果长的数据更好,它会给更多的激励。反之惩罚也更大:如果到了某个程度就已经够长了,再长就罗嗦了,那么更长的采样会给更多的惩罚。
- 为了人为控制模型cot的探索长度,当过长时,会给一个过长的惩罚性reward。显然,这不好,万一真需要思考这么长呢?而且会给那些同样思路但较短的cot一个打击。他们先试了一下不用过长惩罚,结果训练稳定了,后期不崩了。但是还是得限制长度,因此加了一个软性过长惩罚(如下,很好理解,它会被加入rule-base reward)。
数据集
他们扒了AoPS和竞赛网站的数学题。对于结果复杂的数学题,会用LLM修改题目,使其答案变成可接受的简单形式,例如答案是开根号的x,就让题目加一句给结果做个平方,就只有x了。该方法下,做出了DAPO-Math-17K数据集,数据集保证每个query的answer都是一个整数。
超参数

我不翻译了,上文方法里提到的超参在这里都能找到。
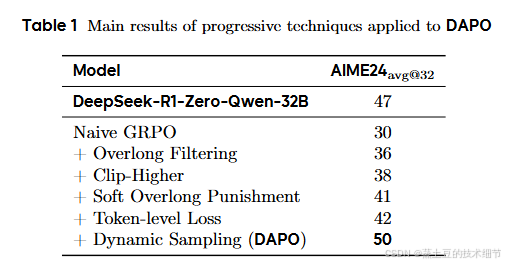
消融
显然,每一点都有用。这里没统计KL散度的消融。
其中,token-level loss虽然没涨几个点,但是训练稳定性大大增加。
值得注意的是,DAPO只用了一半的step(5000)就达到了GRPO 10000个step的效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









