







 本文详细介绍了如何在一台虚拟机上使用Docker部署ApacheHadoop3.3.5环境,包括拉取镜像、配置文件设置、创建docker-compose.yaml文件以及部署步骤。最后验证HDFS和YARN服务是否正常运行。
本文详细介绍了如何在一台虚拟机上使用Docker部署ApacheHadoop3.3.5环境,包括拉取镜像、配置文件设置、创建docker-compose.yaml文件以及部署步骤。最后验证HDFS和YARN服务是否正常运行。
docker部署hadoop环境
1 前提准备
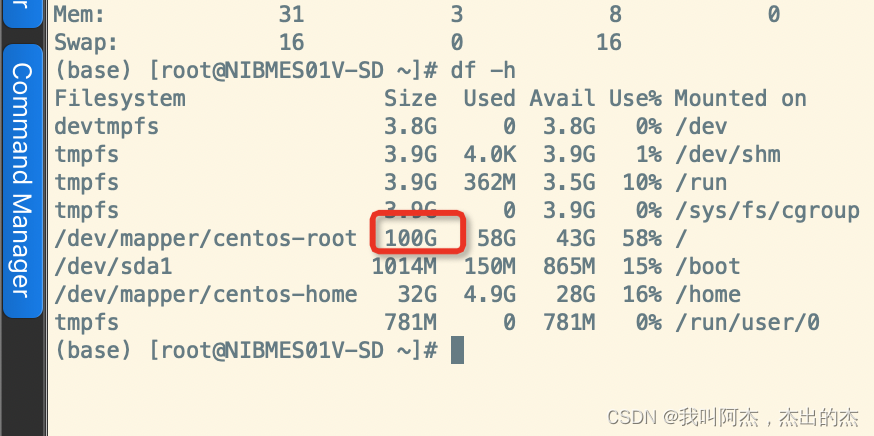
准备一台内存足够,空间足够的虚拟机,并且安装了docker
内存32G
硬盘100G

2 拉取hadoop官方镜像
docker pull apache/hadoop:2.10.2
3 创建目录及相关配置文件
mkdir -p hadoop
vim hadoop/config
config文件内容如下:
CORE-SITE.XML_fs.default.name=hdfs://namenode
CORE-SITE.XML_fs.defaultFS=hdfs://namenode
HDFS-SITE.XML_dfs.namenode.rpc-address=namenode:8020
HDFS-SITE.XML_dfs.replication=1
MAPRED-SITE.XML_mapreduce.framework.name=yarn
MAPRED-SITE.XML_yarn.app.mapreduce.am.env=HADOOP_MAPRED_HOME=$HADOOP_HOME
MAPRED-SITE.XML_mapreduce.map.env=HADOOP_MAPRED_HOME=$HADOOP_HOME
MAPRED-SITE.XML_mapreduce.reduce.env=HADOOP_MAPRED_HOME=$HADOOP_HOME
YARN-SITE.XML_yarn.resourcemanager.hostname=resourcemanager
YARN-SITE.XML_yarn.nodemanager.pmem-check-enabled=false
YARN-SITE.XML_yarn.nodemanager.delete.debug-delay-sec=600
YARN-SITE.XML_yarn.nodemanager.vmem-check-enabled=false
YARN-SITE.XML_yarn.nodemanager.aux-services=mapreduce_shuffle
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-applications=10000
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-am-resource-percent=0.1
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.queues=default
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.capacity=100
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.user-limit-factor=1
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.maximum-capacity=100
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.state=RUNNING
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_submit_applications=*
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_administer_queue=*
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.node-locality-delay=40
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings=
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings-override.enable=false
创建docker-compose.yaml文件
vim hadoop/docker-compose.yaml
docker-compose.yaml文件内容如下:
version: "2"
services:
namenode:
image: apache/hadoop:3.3.5
hostname: namenode
command: ["hdfs", "namenode"]
ports:
- 9870:9870
env_file:
- ./config
environment:
ENSURE_NAMENODE_DIR: "/tmp/hadoop-root/dfs/name"
datanode:
image: apache/hadoop:3.3.5
command: ["hdfs", "datanode"]
env_file:
- ./config
resourcemanager:
image: apache/hadoop:3.3.5
hostname: resourcemanager
command: ["yarn", "resourcemanager"]
ports:
- 8088:8088
env_file:
- ./config
volumes:
- ./test.sh:/opt/test.sh
nodemanager:
image: apache/hadoop:3.3.5
command: ["yarn", "nodemanager"]
env_file:
- ./config
4 部署hadoop
cd hadoop
HADOOP_HOME="/opt/hadoop" docker-compose up -d
部署成功如下图所示

使用docker命令查看容器
docker ps

使用访问docker堵住集的9870端口,正常访问说明hdfs部署成功
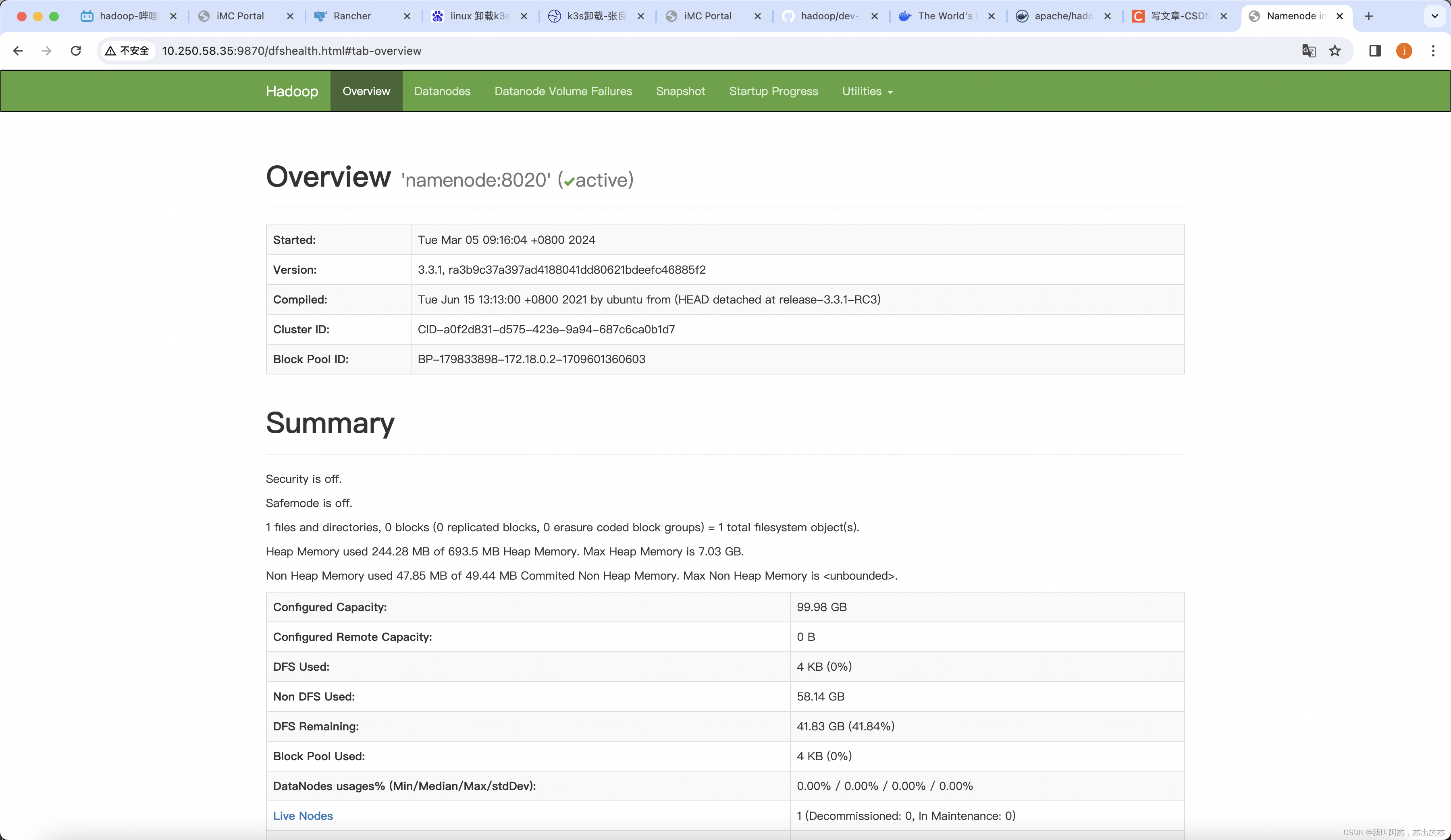
测试验证yarn是否可用
# 进入namenode的容器
docker exec -it hadoop-namenode-1 /bin/bash
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar pi 10 15
如果yarn可用,会得到pi的输出结果


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









