







简介
优势:
- 可直接编译成机器码
- 不依赖其他库
- 运行即部署
- 静态语言,编译的时候可以检查出隐藏的问题
- 语言层面的并发
相关概念
Viper
Viper是Golang语言的一个配置管理库,支持设置、读取和预处理各种类型(JSON、TOML、YAML、INI、HCL、envfile和Java property files)的配置文件。Viper库的设计目标之一是让配置管理更加灵活和易用,同时提供了丰富的功能和扩展性,可适应各种不同的应用场景。
使用 Viper 读取配置文件
注意点
- 创建结构体实例通常有两种方式:使用
book{}和使用&book{}。它们的区别主要体现在传递方式和可修改性上。- book {},返回结构体的一个拷贝。
- &book{},得到指向结构体的指针,更加方便对结构体的属性进行修改。
type book struct { title string author string } func main() { // 使用 &book{} 创建结构体实例 b := &book{title: "Go语言入门教程", author: "Robert"} // 修改结构体实例的属性值 b.title = "Go语言实战" b.author = "William Kennedy" // 输出修改后的值 fmt.Println(b.title, b.author) // 输出 "Go语言实战 William Kennedy" }
- 匿名函数:匿名函数变量声明后跟随空括号表示该匿名函数会被立即执行,并将匿名函数的返回值赋值给匿名函数变量。
注意:
- 当在匿名函数后面跟一个空括号表示要立即调用该匿名函数,并将返回值赋值给变量。
- 在使用channel时,需要在 子协程函数的后面加 ( ),表示立即启动协程,只有两个协程都启动,channel才能正常通信,否则只有一个协程会导致channel阻塞。
在 Go 语言中,匿名函数也被称为闭包(Closure),它是一个没有函数名的函数,通常用于对变量的封装和处理。
匿名函数的声明语法格式如下:
func main() {
// 带括号,立即执行该匿名函数并将结果赋值给 fn1
fn1 := func() int {
return 1
}()
fmt.Println(fn1) // 输出 1
// 不带括号,将该匿名函数作为值赋值给 fn2,fn2 是一个函数类型变量
fn2 := func() int {
return 2
}
fmt.Println(fn2()) // 输出 2
}- ' ' 和 " " 的区别:
- 单引号表示字符时,只能表示单个字符
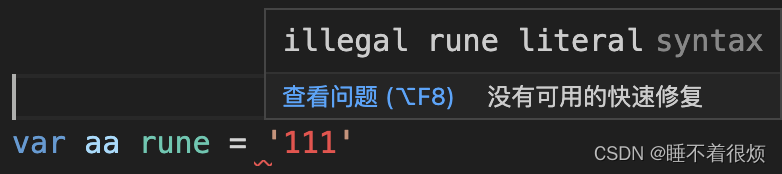
- '' 字符是使用
rune类型来表示的,rune是一个别名类型,本质上是一个 32 位的整数类型,也就是int32类型。 - 字符的占位符:%c,字符串的占位符:%s
- 单引号表示字符时,只能表示单个字符
-
指针和值传递的区别
值传递和指针是函数和方法中参数传递的两种方式,它们之间的主要区别在于传递的是值还是地址(指针)。
- 值传递:在函数或方法调用时将实参的值副本传递给形参,也就是传递的是值的拷贝,这样在函数或方法中对形参的修改不会影响实参本身的值。
- 指针传递:将实参的地址传递给函数或方法的形参,这样在函数或方法中对形参的修改会影响实参的值。
- 占位符
一些常用的占位符及其对应类型:
占位符 类型 %v任何值的默认格式化 %T打印值的类型 %tbool 类型 %d,%b,%o,%x,%X整数类型 %s字符串 %c字符 %f,%e,%E,%g,%G浮点数类型 %p指针 %q该值的 Go 语法表示
- Go程序加载流程

程序的初始化和执行都起始于main包。
init函数在main函数之前执行。
- 导包
- 匿名导包:一般来说,导包不用会报错,但匿名导包就不会报错。 如 import _"xx/xx/xx"
- 将包全部导入当前包中:."xx/xx/xx",即将别的包的所有的内容都导进当前包中,可以在当前包中直接使用别的包的方法名,如 其他导包方式:xx.test(), 全导:test()
- 给导进的其他包起个别名:如 imort mylib "xx/xx",则使用时:mylib.test()
-
指针:*表示指针,指针是一种变量,用来存储一个值的内存地址。&表示地址。举例子,如果h是一个指针变量, *h 表示获取
h指针所指向的值,是一个指针类型的数据。 &h 表示取得h指针的地址,是一个指向指针的指针。-
Go 语言的取地址符是 &,放到一个变量前使用就会返回相应变量的内存地址。
-
通过指针修改内存:*p = 200
var ptr *int // 声明一个指针变量ptr var a int = 100 ptr = &a // 将a的地址赋值给指针ptr,即指针ptr指向a的地址 *ptr = 200 // 通过指针修改变量a的值,即指针ptr找到指向的地址,并修改该地址的内存值。 fmt.Println(a) // 输出200 - 多级指针:**..,指针也可以被定义为指向另一个指针的变量,这就构成了多级指针。指针可以有任意多级,被称为一级、二级、三级指针等等。
var a int var ptr1 *int = &a // 指针ptr1指向a的地址 var ptr2 **int = &ptr1 // 指针ptr2指向指针ptr1 var ptr3 ***int = &ptr2
-

- defer关键字:类似于Java中的final关键字,在函数的最后执行。defer在return之后执行
defer语句可以与匿名函数或闭包结合使用。// func(args):匿名函数 defer func(args) { // do something }(args) // 有名字的函数 defer function_name(args)- recover函数:recover函数必须在defer函数中使用,相当于catch。当程序出现 panic 异常时,Go 会依次执行当前函数的
defer函数,如果其中有一个调用了recover函数,则该程序会恢复正常执行,并直接返回recover()的值。defer func() { if err := recover(); err != nil { fmt.Println("recover from panic:", err) } }() panic("run time panic") //触发 panic
- 数组和动态数组(切片)
- 数组和切片的区别
- 大小:数组的大小固定,切片没有大小限制。
-
值类型和引用类型:数组是值类型,即在赋值或传递时会进行复制。这意味着当你将一个数组分配给另一个数组时,整个数组都会被复制。切片是引用类型,当你将一个切片分配给另一个切片时,它们实际上仍然引用同一个底层数组。
-
内存布局:数组是依次存储在内存中的连续块中,因此它们的访问速度非常快。切片是指向底层数组的指针、长度和容量的结构体。它们在内存中不是连续的,因此对切片的访问可能需要一些额外的开销。
- 声明数组:
// 固定长度的数组 var arr1 [10]int arr2 := [10]int{1, 2, 3, 4}-
数组切片
// 表示从下标为 1 ,到下标为 3 (不包含下标为 3 的元素),最终得到包含两个元素(也就是 2 和 3)的数组切片。 s := a[1:3] - copy函数:目的是为了让目标 Slice 与原 Slice 不共享底层的数组,从而独立开来。copy函数只接受切片作为参数,而不接受数组。
// 语法 copy(“目标切片”,“源切片”)
-
- slice 切片:即动态数组。
func print(arr []int) { for _, value := range arr { fmt.Println(value) } } func main() { // 声明slice切片 arr := []int{1, 2, 3} fmt.Printf("%T\n", arr) print(arr) }- 切片的长度和容量:len() 和 cap()。
- 长度:表示 Slice 当前包含的元素个数
- 容量:表示 Slice 最大能够扩展到的元素个数
- 切片追加元素:append(),扩容一个原切片的大小。
var nums = make([]int, 3, 3) fmt.Printf("len= %d,cap= %d, slice=%v\n", len(nums), cap(nums), nums) nums = append(nums, 1) fmt.Printf("len= %d,cap= %d, slice=%v\n", len(nums), cap(nums), nums) /*结果: len= 3,cap= 3, slice=[0 0 0] len= 4,cap= 6, slice=[0 0 0 1] */ - slice的声明方式(4)
// 声明slice切片,并且初始化,即分配空间 slice := []int{1, 2, 3} // 声明slice切片,未初始化,即没有分配空间,需要用 make函数 分配空间 var slice1 []int // 声明slice切片,同时初始化 var slice2 []int = make([]int, 3) // 声明slice切片,同时初始化,通过 := 推导出slice是一个切片 slice3 := make([]int, 3)-
make方法:Type只能是
slice、map、channel这三种数据类型make(Type, 长度, 容量)长度是数据实际的长度,容量是
-
- 切片的长度和容量:len() 和 cap()。
- 声明数组:
- 数组和切片的区别
-
map
-
声明方式
-
最常用的,初始时map长度为0
test1 := make(map[string]string, 10) test1["one"] = "php" test1["two"] = "golang" test1["three"] = "java" fmt.Println(test1) //map[two:golang three:java one:php] -
直接声明,未初始化
var map1 map[string]int - 声明并初始化
map3 := map[string]int{"a": 1, "b": 2, "c": 3}
-
-
- 循环
- for
- 常规:for i := 0; i < len(arr) ; i++{ }
- range
for index, value := range arr2 { fmt.Println("index=", index, "value=", value) }
- for
- make函数:
make()是一个内置函数,主要用于创建一个动态类型的变量(Slice、Map 和 Channel),而不是创建一个它们的指针。make(T, size) // T 表示创建的变量的类型,size 表示为其分配的大小
- Switch
在Go语言中,switch语句是一种用于多条件判断的结构。它可以替代较为复杂的if-else结构,使代码更加简洁和清晰。
switch expression {
case value1:
// do something
case value2:
// do something
...
default:
// do something
}其中,expression是待判断的表达式,case语句列出了待判断的值,default为默认情况下要执行的代码。
switch num {
case 1:
fmt.Println("num is 1")
case 2, 3, 4:
fmt.Println("num is 2, 3 or 4")
default:
fmt.Println("unknown number")
}- Go的变量结构
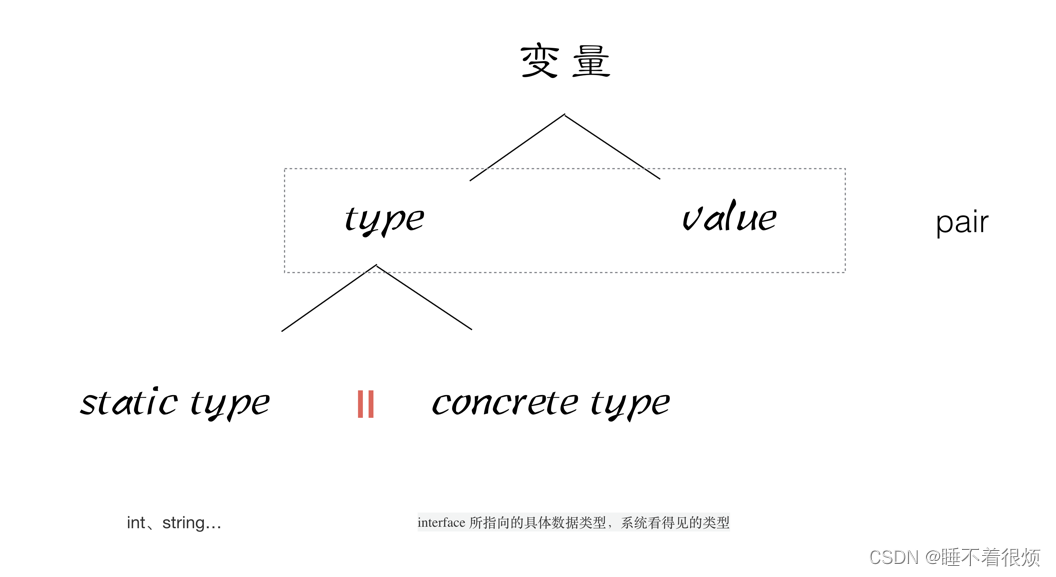
变量的 Pair = type + value
// Pair<staticType:string, value:"1111">
var a string
a = "1111"
// allType = a 即 将 allType 中的 Type 指针指向 a 中的 Type, 则Pair<type:string, value:"1111">
var allType interface{}
allType = a
str, _ := allType.(string)
fmt.Println(str)
// 结果
1111- 反射 :
反射相关的操作主要通过 reflect 包来实现。reflect包提供了一个 Type 结构体来反映类型信息,以及一个 Value 结构体来反映值信息。反射也可以将“反射类型对象”再重新转换为“接口类型变量” ,用Interface()
- reflect包有两个重要的接口,valueOf 和 TypeOf

- reflect包有两个重要的接口,valueOf 和 TypeOf
// 获取变量的类型信息
fmt.Println(reflect.TypeOf(myStr)) // string
fmt.Println(reflect.TypeOf(myInt)) // int
fmt.Println(reflect.TypeOf(myPerson)) // main.Person
// 获取变量的值信息
fmt.Println(reflect.ValueOf(myStr)) // Hello, world!
fmt.Println(reflect.ValueOf(myInt)) // 666
fmt.Println(reflect.ValueOf(myPerson)) // {Robert 23}
- Field() 方法:该方法位于
reflect.Type类型中,用于获取结构体的类型信息type User struct { Name string `json:"name"` Age int `json:"age"` } func main() { var user User user.Name = "David" user.Age = 25 t := reflect.TypeOf(user) fmt.Println(t.Field(0).Name, t.Field(0).Type) // 输出 Name string fmt.Println(t.Field(1).Name, t.Field(1).Type) // 输出 Age int } - 通过 reflect.value 设置实际变量的值
-
CantSet()表示是否可以重新设置其值,是true可修改,false不能修改。在使用
CanSet()方法之前,需要先调用Elem()方法获取到指向底层值的 reflect.Value 类型的值。如果值不可设置,将不会影响底层值。 - reflect.Value.Elem() 返回的是指针指向的值,只有原始对象才能修改,当前反射对象是不能修改的。Elem() 将 reflect.value类型的指针变量 转换成 指向底层值的 reflect.Value 变量,然后调用相应的方法就可以设置实际变量的值。
-
reflect.Value变量 是通过 reflect.ValueOf(X) 获得的,只有当X是指针的时候,才可以通过reflec.Value修改实际变量X的值,即:要修改反射类型的对象就一定要保证其值是“addressable”的。
var num float64 = 1.2345 fmt.Println("old value of pointer:", num) // 通过reflect.ValueOf获取num中的reflect.Value,注意,参数必须是指针才能修改其值 pointer := reflect.ValueOf(&num) newValue := pointer.Elem() fmt.Println("type of pointer:", newValue.Type()) fmt.Println("settability of pointer:", newValue.CanSet()) // 重新赋值 newValue.SetFloat(77) fmt.Println("new value of pointer:", num)
-
-
通过反射进行方法的调用
在 Go 语言中,使用反射可以动态地调用结构体中的方法。- reflect.valueOf() 方法:将 结构体的实例变量 转换为 reflect.Value 反射类型变量
- 一般需要创建一个参数切片 args 并将参数值转换为反射值,传入方法进行调用
-
reflect.Value.MethodByName() 方法:获取目标结构体中的方法名。通过反射调用方法,首先得将方法用 MethodByName()注册。
args := []reflect.Value{reflect.ValueOf("Alice")} -
reflect.Method(索引值) 方法:通过索引获取目标结构体的方法,从而通过 Call() 调用该方法
-
Call() 方法:调用结构体的方法
type User struct { Id int Name string Age int } func (u User) ReflectCallFuncHasArgs(name string, age int) { fmt.Println("ReflectCallFuncHasArgs name: ", name, ", age:", age, "and origal User.Name:", u.Name) } func (u User) ReflectCallFuncNoArgs() { fmt.Println("ReflectCallFuncNoArgs") } // 如何通过反射来进行方法的调用? // 本来可以用u.ReflectCallFuncXXX直接调用的,但是如果要通过反射,那么首先要将方法注册,也就是MethodByName,然后通过反射调动mv.Call func main() { user := User{1, "Allen.Wu", 25} // 1. 要通过反射来调用起对应的方法,必须要先通过reflect.ValueOf(interface)来获取到reflect.Value,得到“反射类型对象”后才能做下一步处理 getValue := reflect.ValueOf(user) // 一定要指定参数为正确的方法名 // 2. 先看看带有参数的调用方法 methodValue := getValue.MethodByName("ReflectCallFuncHasArgs") args := []reflect.Value{reflect.ValueOf("wudebao"), reflect.ValueOf(30)} methodValue.Call(args) // 一定要指定参数为正确的方法名 // 3. 再看看无参数的调用方法 methodValue = getValue.MethodByName("ReflectCallFuncNoArgs") args = make([]reflect.Value, 0) methodValue.Call(args) } // 运行结果: ReflectCallFuncHasArgs name: wudebao , age: 30 and origal User.Name: Allen.Wu ReflectCallFuncNoArgs
- 结构体标签:结构体标签常用于序列化、反序列化、ORM 框架、验证器等场景,可以使编码更加方便和高效。
通过反射机制使用 reflect 包来获取一个结构体的类型信息,以及获取结构体中每个字段的值和标签。结构体标签是在结构体属性上的键值对,以注释的形式写在属性定义后面 。
type resume struct {
Name string `info:"name" doc:"我的名字"`
Sex string `info:"性别"`
}
func main() {
var re resume
re.Name = "BeryCao"
re.Sex = "man"
// 通过反射机制使用 reflect 包来获取一个结构体的类型信息
r := reflect.TypeOf(re)
// 获取结构体中每个字段的值和标签
fmt.Println(r.Field(0).Name, r.Field(0).Tag.Get("info"), r.Field(0).Tag.Get("doc"))
fmt.Println(r.Field(1).Name, r.Field(1).Tag.Get("info"))
}
// 结果
Name name 我的名字
Sex 性别- 结构体标签在JSON中的应用:在使用 Go 语言进行 JSON 编解码时,标记可以用于指定字段的 JSON 编码名称和其他 JSON 相关选项。
- json.Marshal() 和 json.Unmarshal() :用于将数据编码为 JSON 格式。
type User struct { Name string Age int Emails []string } func main() { // 声明一个结构体并初始化 user := User{ Name: "Alice", Age: 18, Emails: []string{"alice@test.com", "alice@gmail.com"}, } // 将结构体转换成 JSON 字符串 userJSON, err := json.Marshal(user) if err != nil { fmt.Println("JSON Marshal error:", err) return } // 打印 JSON 字符串 fmt.Println(string(userJSON)) // 解码 userData := User{} err = json.Unmarshal(userJSON, &userData) if err != nil { fmt.Println(err) return } fmt.Println(userData) }
- json.Marshal() 和 json.Unmarshal() :用于将数据编码为 JSON 格式。
面向对象
封装
Go语言中没有传统面向对象编程语言中的类(class)的概念,但可以使用结构体(struct)和方法(method)来实现面向对象的编程思想,并支持面向接口(interface)的编程方式。
- 结构体(struct)
- type关键字
- 可以定义新的类型
// 定义了一个新类型MyInt,使其成为int类型的别名。这样,我们可以将MyInt类型的变量视为int类型的变量来操作 type MyInt int - 可以定义结构体、接口等
- 可以定义新的类型
- 类名首字母大写,则其他包也能访问。类的属性首字母大写,表示该属性对外也能访问。
- type关键字
- 方法(method)
- 语法:接收者类型是方法作用的主体。接收者类型可以是任何类型,包括Go语言自带的基本类型,也可以是我们自定义的类型(比如结构体、函数类型、接口类型等)。
func (实例名 接收者类型) 方法名(参数及其类型) 返回值类型 { 行为 } -
type Hero struct { Name string Age int } // 写成*Hero,this 则指向当前的地址,进行写操作时能直接改变地址的内存值 func (this *Hero) show() { fmt.Println("Name=", this.Name) fmt.Println("Age=", this.Age) } func (this *Hero) GetName() string { return this.Name } func (this *Hero) SetName(newName string) { this.Name = newName } func main() { hero := Hero{Name: "BeryCao", Age: 25} hero.show() fmt.Println(hero.GetName()) hero.SetName("bery") fmt.Println(hero) } -
方法表达式及其调动方法
func (t T) funcName(args) returnType { //... }(t T)标识了这个方法是属于T类型的方法,funcName是这个方法的名称,args是方法的参数列表,returnType是这个方法的返回值类型。var f func(T, Args) ReturnType = T.funcName res := f(t, args)T.funcName表示获取T类型中名为funcName的方法。我们可以将其赋值给一个函数变量f,然后通过f来调用该方法。如下func (this *Hero) SayHi() { fmt.Printf("Hi, my name is %s, I'm %d years old.\n", this.Name, this.Age) } func main() { h := Hero{Name: "xxx", Age: 18} f := (*Hero).SayHi f(&h) }SayHi方法是Hero类的一个方法,接收者类型为指向Hero类的指针。定义了一个
f变量,将其初始化为(*Hero).SayHi,可以理解为获取了Hero类型中的SayHi方法,并把这个方法的指针地址赋值给函数变量f。这样,我们就可以通过函数变量f来调用该方法。创建了一个
Hero类型的 实例h,然后使用f(&h)来调用该实例的SayHi方法。因为SayHi方法的接收者类型是一个指向Hero类的指针,所以需要传递一个指向 实例h 的指针 &h。在调用方法时,我们只需要使用f(&h)来代替h.SayHi()就可以完成对该方法的调用。
- 语法:接收者类型是方法作用的主体。接收者类型可以是任何类型,包括Go语言自带的基本类型,也可以是我们自定义的类型(比如结构体、函数类型、接口类型等)。
继承
Go语言天生不支持类和继承,但是可以通过嵌入和组合等技术实现类似于继承的功能。
-
type Person struct { Name string Age int } func (p *Person) SayHi() { fmt.Printf("Hi, my name is %s, I'm %d years old.\n", p.Name, p.Age) } type Student struct { Person // 嵌入Person类型 ID string } func main() { // stu := Student{Person{"amy", 18}, "001"} var stu Student stu.Name = "bery" stu.Age = 25 stu.ID = "001" stu.SayHi() // 调用Person类型的SayHi方法 fmt.Println(stu.Name, stu.Age, stu.ID) // 访问嵌入的字段 }
多态(接口)
多态表示同一个类型实例,在不同的情况下,可以表现出不同的行为。通俗地说,多态就是一种允许我们用同一种类型的对象来代表不同的东西的能力。
Go语言是一门静态类型语言,它天生具有多态的特性。静态类型语言的多态是通过接口和函数重载实现的。 其他类如果实现了该接口中定义的所有方法,则该类就隐式地实现了该接口。
- 多态的基本要素
- 有一个父类(有接口)
- 有子类(实现了父类的全部接口方法)
- 父类类型的变量(指针)指向(引用)子类的具体数据变量
-
// 多态的基本要素第一点,有一个父类接口 type Animal interface { Sleep() GetColor() string } // 多态的基本要素第二点,有子类实现了父类接口的全部方法 type Cat struct { color string } type Dog struct { color string } func (this *Cat) Sleep() { fmt.Println("Cat is sleeping") } func (this *Cat) GetColor() string { return this.color } func (this *Dog) Sleep() { fmt.Println("Dog is sleeping") } func (this *Dog) GetColor() string { return this.color } func showAnimals(animal Animal) { animal.Sleep() // 多态的体现,传入什么子类,就调用什么子类的方法 fmt.Println("color = ", animal.GetColor()) } func main() { cat := Cat{"Green"} dog := Dog{"Black"} // 多态的基本要素第三点,父类类型的变量(指针)指向(引用)子类的具体数据变量 showAnimals(&cat) showAnimals(&dog) }在Go中,结构体类型实现接口的方法,必须使用指针类型(
*)进行接收。因此,我们向showAnimals函数中传递&cat和&dog,即它们的地址,以便实现接口多态。 -
通用万能类型(空接口)

interface{} 空接口可以代表任意类型,将参数类型设为interface{},这样就可以接收任意类型的参数。
// 将参数类型设为interface{},这样就可以接收任意类型的参数。
func myFunc(arg interface{}) {
fmt.Println(arg)
}
type Book struct {
auth string
}
func main() {
book := Book{"Bery"}
myFunc(book)
myFunc(100)
myFunc(3.14)
}
// 结果
{Bery}
100
3.14- 类型断言:为了判断 通用类型 interface{} 底层数据类型是什么 和 转换类型
- 用法1:将 interface通用类型变量 转换为 断言类型 的值
value, ok = x.(T)这里value就是变量的值,ok是一个bool类型,x 是interface{}通用类型变量,T是断言的类型。
如果 x 里面确实存储了T类型的数值,那么ok返回true,否则返回false。只能在类型断言成功后访问value变量,即 ok 为 true时才能访问value变量。
// 将参数类型设为interface{},这样就可以接收任意类型的参数。 func myFunc(arg interface{}) { fmt.Println(arg) // 类型断言,判断通用类型interface{}的底层数据类型是什么 value, ok := arg.(string) if !ok { fmt.Println("arg is not string") } else { fmt.Println("arg is string") // 只能在类型断言成功后访问value变量。 fmt.Printf("value type is %T\n", value) } } type Book struct { auth string } func main() { book := Book{"Bery"} myFunc(book) myFunc("abc") } // 结果 {Bery} arg is not string abc arg is string value type is string - 用法2:x.(type),x 是interface{}通用类型变量,type 自动判断变量类型。在
switch语句中使用,在编译期间自动判断接口变量的实际类型,并执行相应的分支代码。func getType(i interface{}) { // x.(type),自动判断通用类型变量 interface{}的类型,并执行相应的分支代码 switch i.(type) { case int: fmt.Println("integer") case string: fmt.Println("string") case float64: fmt.Println("float") default: fmt.Println("unknown") } } func main() { getType(1) getType("hello") getType(3.14) getType(false) } // 结果 integer string float unknown
- 用法1:将 interface通用类型变量 转换为 断言类型 的值
Golang高阶
Go语言中的并发程序主要使用两种手段来实现。goroutine和channel。
协程
由 Go 运行时(Go runtime)调度器管理的。
Go 协程是由 Go 运行时(Go runtime)负责调度的用户态线程(User-space thread),使用协程的方式可以更好地处理并发和异步任务。
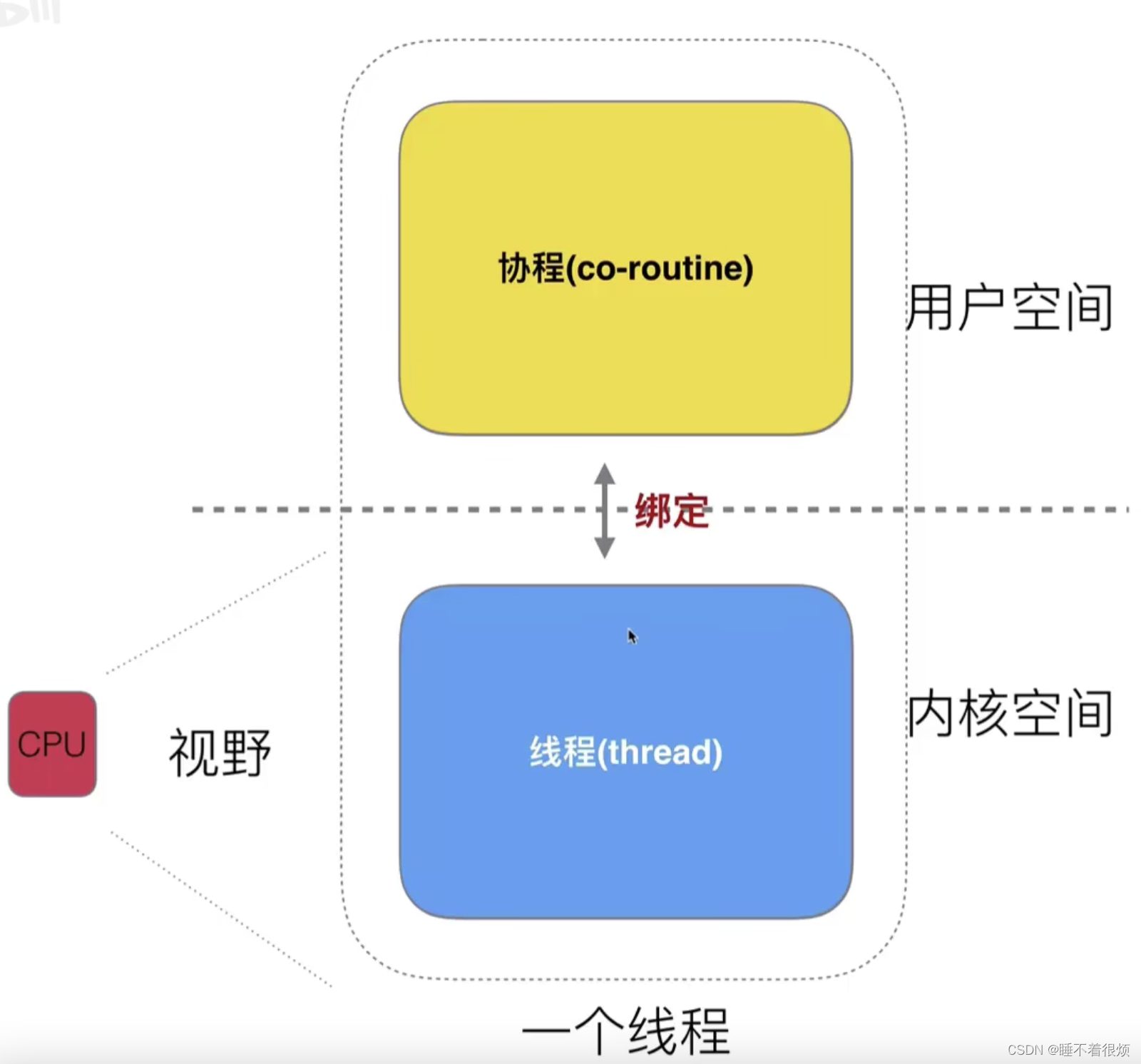
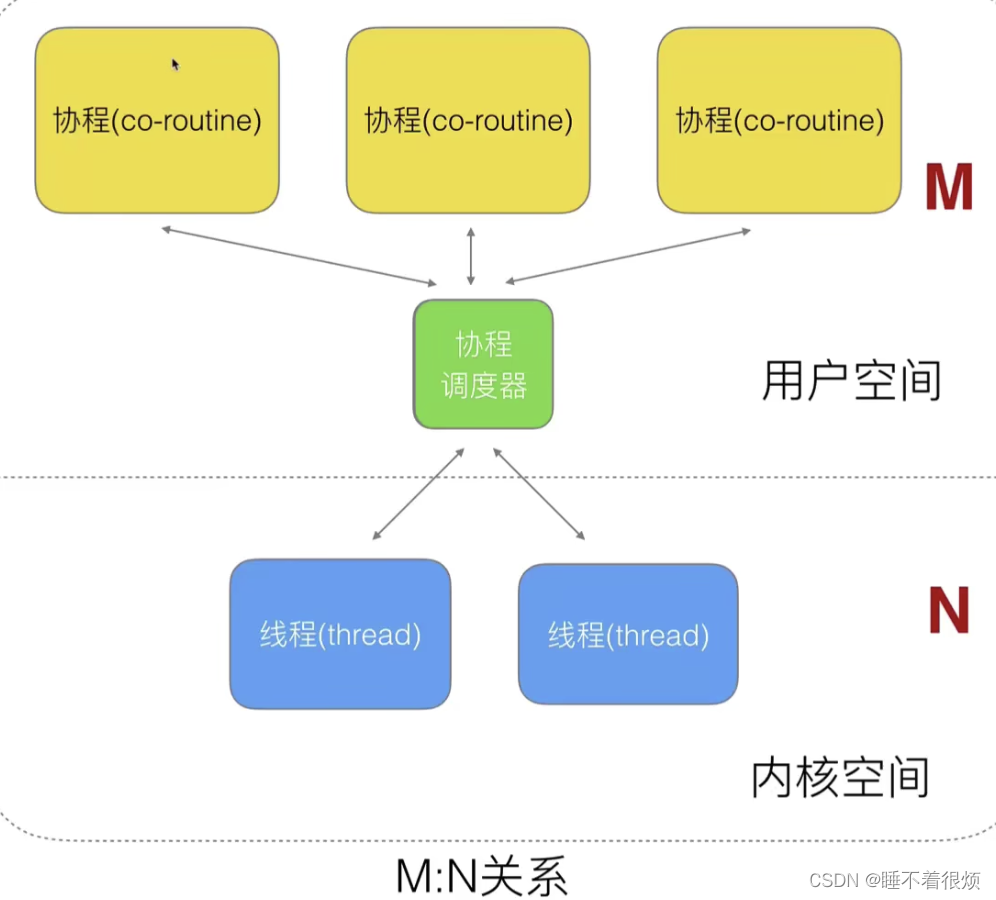
- GMP:GMP 模型是 Go 语言运行时(Go runtime)系统中的一种并发模型,用于实现并行的协程(Goroutines)和并发的系统调用(Syscall)。
- Go runtime:Go 运行时调度器会将不同的协程分配到不同的操作系统线程上运行,每个线程可以同时运行多个协程,这样可以利用多核 CPU 的性能,提高并发性能。
- M 代表操作系统线程(OS Thread),是真正的执行体,是操作系统调度的基本单位。在 GMP 模型中,每个 G 和 P 都需要一个操作系统线程来支持其运行。
-
P 表示 Processor,表示处理器,它是 Go 语言内部的调度单位。每个 P 都绑定一个操作系统线程,用于执行 Goroutine。Go 运行时使用了一个类似于队列的数据结构来管理 Processor,当协程需要执行时,它会被调度到某个 Processor 上,并在该 Processor 上执行指令。当协程需要等待外部事件完成时,它会被挂起,而 Processor 会用于执行其他协程相关的程序
调度器 GOMAXPROCS 的数量 = Go当前能并行的最大数量

使用协程 Goroutine 实现并行的例子 :子协程的内存空间依赖于主协程,主协程退出则子协程也退出
// 子协程
func Task() {
i := 0
for {
i++
fmt.Printf("new Goroutine : i = %d\n", i)
time.Sleep(1 * time.Second)
}
}
// 主协程
func main() {
// 创建一个协程,去执行Task方法
go Task()
i := 0
for {
i++
fmt.Printf("main Goroutine: i = %d\n", i)
time.Sleep(1 * time.Second)
}
}
// 结果
main Goroutine: i = 1
new Goroutine : i = 1
new Goroutine : i = 2
main Goroutine: i = 2
main Goroutine: i = 3
new Goroutine : i = 3- 协程的使用:有参协程 和 无参协程(匿名协程)
func main() {
// 匿名协程的使用
go func() {
defer fmt.Println("A.defer")
func() {
defer fmt.Println("B.defer")
// 退出当前协程
runtime.Goexit()
fmt.Println("B")
}()
fmt.Println("A")
}()
for {
time.Sleep(1 * time.Second)
}
// 有参协程的使用
name := "BeryCao"
go func(name string) {
fmt.Printf("%s\n", name)
}(name)
time.Sleep(1 * time.Second)
fmt.Println("main Goroutine!")
}
runtime.Goexit() :退出当前的协程
- 调度器的设计策略(4)待补充
channel
channel(通道)是一种用于在 Goroutine协程 之间进行通信和同步的机制,保证数据的互斥访问和同步执行。
goroutine运行在相同的地址空间,因此访问共享内存必须做好同步。goroutine 奉行通过通信来共享内存,而不是共享内存来通信。
引⽤类型 channel可用于多个 goroutine 通讯。其内部实现了同步,确保并发安全。
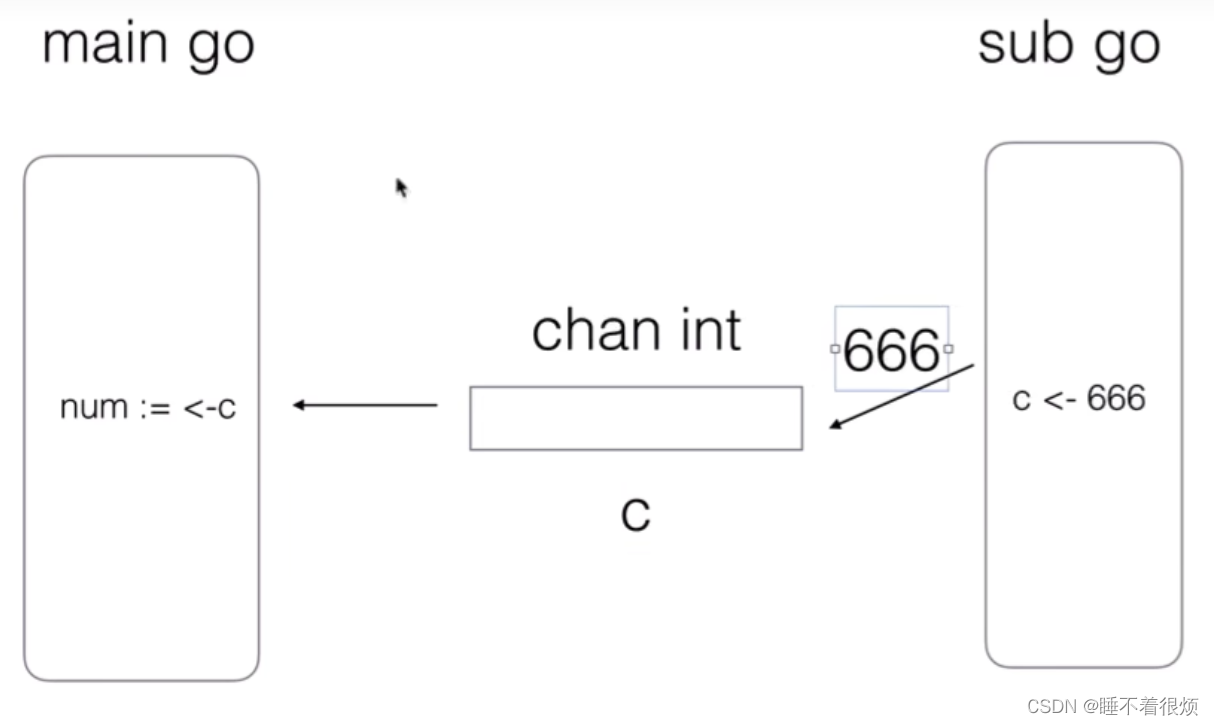
- 声明
make(chan Type) //等价于make(chan Type, 0) make(chan Type, capacity)-
capacity :capacity 是指该 channel 可以容纳的元素数量。当 参数capacity= 0 时,channel 是无缓冲阻塞读写的;当capacity > 0 时,channel 有缓冲、是非阻塞的,直到写满 capacity个元素才阻塞写入。
-
channel使用方式
channel <- value //发送value到channel <-channel //接收并将其丢弃 x := <-channel //从channel中接收数据,并赋值给x x, ok := <-channel //功能同上,同时检查通道是否已关闭或者是否为空 -
无缓冲的通道(unbuffered channel):是指在接收前没有能力保存任何数据值的通道。这种对通道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
make(chan Type) //等价于make(chan Type, 0)无缓冲的通道保证进行发送和接收的 goroutine 会在同一时间进行数据交换
-
有缓冲的通道(buffered channel):是一种在被接收前能存储一个或者多个数据值的通道。只有通道中没有要接收的值时,接收动作才会阻塞。只有通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。
make(chan Type, capacity)如果给定了一个 capacity缓冲区容量,通道就是异步的。只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么其通信就会无阻塞地进行。
借助函数 len(ch) 求取缓冲区中剩余元素个数, cap(ch) 求取缓冲区元素容量大小。close() 函数可以关闭channel
-
- 单向channel :只收 或者 只发的channel
- 声明方式
var ch1 chan int // ch1是一个正常的channel,是双向的 var ch2 chan<- float64 // ch2是单向channel,只用于写float64数据 var ch3 <-chan int // ch3是单向channel,只用于读int数据可以将 channel 隐式转换为单向队列,只收或只发,不能将单向 channel 转换为普通 channel
c := make(chan int, 3) var send chan<- int = c // send-only var recv <-chan int = c // receive-only
- 声明方式
- Select : 可以同时监视多个通道,直到其中任何一个通道准备好数据接收/发送。
- 使用方法
select { case <-ch1: // 当ch1通道准备好数据时执行此分支 case data := <-ch2: // 当ch2通道准备好数据时执行此分支,同时把数据存入data变量 case ch3 <- data: // 当ch3通道准备好接收数据时执行此分支,且把data发送到ch3通道中 default: // 所有的case分支都没有准备好时会执行default分支 } -
例子:斐波那契算法的实现
- 使用方法
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 6; i++ {
// 循环读取 c 管道中的数据,无数据则阻塞
fmt.Println(<-c)
}
// 循环结束后,即读完 c 管道中的数据后,向 quit 管道输入一个0,表示退出
quit <- 0
}()
solution(c, quit)
}
func solution(c, quit chan int) {
x, y := 1, 1
// 同时监控 c 、 quit 管道
for {
select {
// 如果 c 管道可写,则进入该 case
case c <- x:
x = y
y = x + y
// 如果 quit 管道可读,则说明对 c 管道的读操作已经结束
case <-quit:
fmt.Println("quit")
return
}
}
}













 1822
1822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









