







搜索树有两种方式,一种的bfs(广度优先搜索)一种是dfs(深度优先搜索),而之字形遍历属层次搜索,可通过改写bfs来实现。之字形的特点是一行正序则下一行倒序,循环下去。
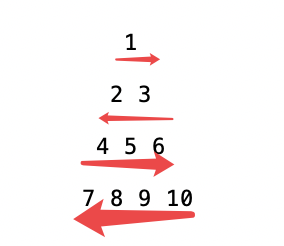
如上图,我们的遍历顺序应该是 1-》3->2-》4->5->6-》10->9->8->7,而倒序我们可以通过栈先进后出的特性来实现。
基本思路是用栈来存储我们当前遍历层次的孩子节点。比如说当前我们遍历到第一行,节点有1,那么我们将它的子节点2和3按从左到右顺序存入栈s1中,当第一行遍历完后我们开始遍历第二行可通过s的pop方法输出,则顺序为3->2。而在遍历第二行的时候我们也要存贮他们的子节点用于下层遍历,第三行的输出顺序应该为正序所以我们要倒着存入栈中。并且,正好第二层是倒着遍历的,只是子节点入栈顺序不再是从左到右而是从右到左(不难想吧)。
所以,规律就是奇数行子节点入栈顺序是先左子节点后右子节点,偶数行的话子节点入栈顺序就是先右子节点后左子节点,两种情况代码都差不多。
代码如下
public static void f(Node header) {
Stack<Node> s1 = new Stack<>();
s1.push(header);
Stack<Node> s2 = new Stack<>();
//用于标记是奇数行还是偶数行
int index = 1;
while (!s1.isEmpty() || !s2.isEmpty()) {
if (index % 2 != 0) {
//存储遍历结果,方便看每行结果。。。。
List<Integer> list = new ArrayList<>();
while (!s1.isEmpty()) {
Node temp = s1.pop();
if (temp != null) {
list.add(temp.val);
//先左后右
s2.push(temp.left);
s2.push(temp.right);
}
}
if (list.size() > 0) {
System.out.println(list);
index++;
}
} else {
List<Integer> list = new ArrayList<>();
while (!s2.isEmpty()) {
Node temp = s2.pop();
if (temp != null) {
list.add(temp.val);
//先右后左
s1.push(temp.right);
s1.push(temp.left);
}
}
if (list.size() > 0) {
System.out.println(list);
index++;
}
}
}
}















 4843
4843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









