






一、池化层:对信号进行收集并总结。
(目标:冗余信息的提出,减少后面的信息量)
收集:多变少
总结:最大值/平均值(max/average)
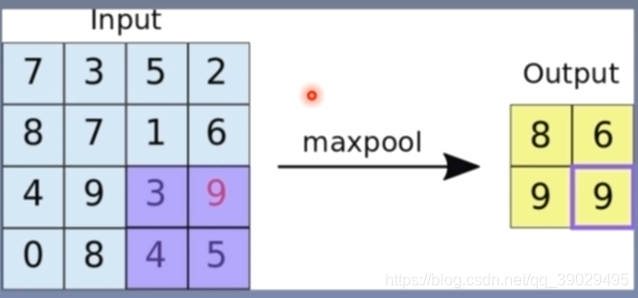
1 nn.MaxPool2d(功能对二维信号-图像进行最大池化)

常见参数:kernel_size:池化核尺寸
stride:步长(应该与池化核尺寸相同,防止重叠所以也为一个元组)
padding:填充个数
dilation:池化核间隔大小
ceil_mode:尺寸像上(True)/(false默认)下取整
return_indices:记录池化像素索引
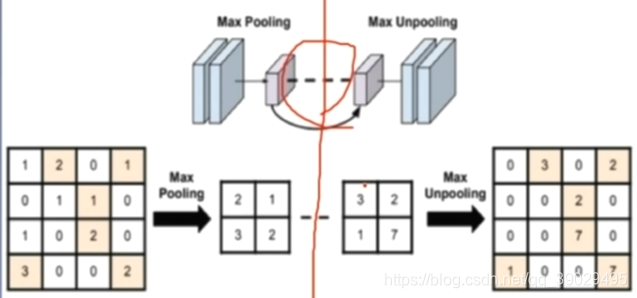
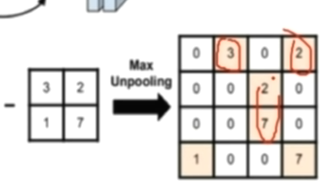
当把maxpool取出的像素如果想扩充,则根据return_indices记录的索引放置
2 nn.AvgPool2d(功能对二维信号-图像进行平均池化)
主要参数:kernel_size:池化核尺寸
stride:步长(应该与池化核尺寸相同,防止重叠所以也为一个元组)
padding:填充个数
ceil_mode:尺寸像上(True)/(false默认)下取整
count_include_pad:填充值是否要用于计算均值
divisor_override:除法因子(分母如果不想用n可以用这个自己设置)
3 nn.MaxUnpool2d(反池化层):对二维信号进行最大值上采样(根据索引填充)

主要参数:kernel_size:池化核尺寸
stride:步长
padding:填充个数
使用的时候,要将输入(池化层得到的东西)和索引indices(由maxpool2d获得)作为参数,
unmaxpool=nn.MaxUnpool2d((2,2),(2,2))
unmaxpool(池化层得到的东西,indices)得到后面的
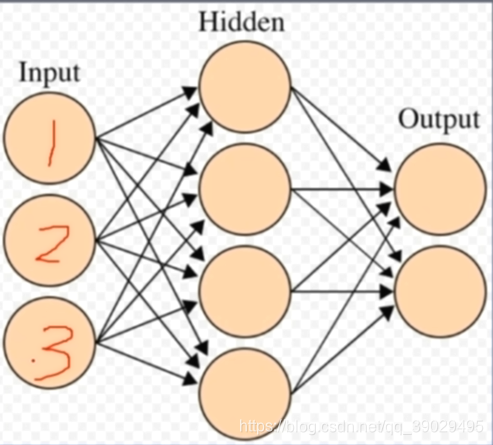
二、线性层(全连接层):每个神经元与上一层所有神经元相连
nn.Linear()

主要参数:
in_features:输入结点数
out_features:输出结点数
bias:是否需要偏置
模型参数设置:
linear_layer.weight.data=torch.tensor(神经矩阵)
linear_layer.bias.data.fill_(1.)
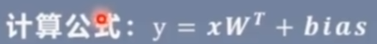
三、激活函数层:使特征进行非线性变化,然多层神经网络有更深层次意义
nn.sigmoid()
输出在(0,1)间
导数范围[0,0.25]易导致梯度消失
输出为非零均值,破坏数据分布
nn.sigmoi()
输出在(-1,1)符合0均值
导数范围(0,1),一定程度减轻了梯度消失问题(深了还是会消失)
nn.ReLU()
输出均为正数,但会导致负半轴死神经元
导数是1,缓解梯度消失,但易导致梯度爆炸
改进变形:
leakyReLU():负半轴增加了一个很小的斜率negative——slope
PReLU():负半轴为可学习斜率init
RReLU():负半轴为从均匀分布中随机取斜率(上界upper,下界lower)















 1042
1042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









