









不完整多视图聚类的鲁棒多样化图对比网络
引用:Xue Z, Du J, Zhu H, et al. Robust diversified graph contrastive network for incomplete multi-view clustering[C]//Proceedings of the 30th ACM International Conference on Multimedia. 2022: 3936-3944.
研究背景
不完整多视图聚类是一项复杂的任务,旨在将带有缺失信息的未标记多视图数据分成不同的类簇。目前领域内的方法往往忽视数据中存在的多样化关联,并难以处理不同视图中的噪声。多媒体数据通常可以从多个视角进行描述,例如,图像的内容可以通过不同的视觉特征或周围的文本进行描述。网页可以通过文本、图像和超链接进行描述。由于每个视图包含一些独特的数据描述,不同视图通常相互补充。多视图聚类旨在通过充分利用不同视图的互补性,将相似的数据划分到同一组中,这已成为多媒体数据分析和机器学习中的重要研究课题。
问题挑战
当前不完整多视图聚类方法在有效利用数据中固有的多样化关联和处理不同视图中的噪声方面面临挑战。传统的多视图聚类方法假设数据是完整的,即每个样本在所有视图上都具有完整的特征。然而,在许多现实应用中,由于一些无法控制的因素,数据往往会失去部分视图,导致不完整的多视图数据。为了利用有限且不完整的多视图特征进行聚类,已经提出了不完整多视图聚类(IMC)方法。一些IMC方法采用矩阵或张量分解来完成聚类所需的缺失特征。图学习是对异构多视图特征建模的另一种重要方式,用于实现数据聚类。此外,一些IMC方法基于深度学习学习了不完整多视图数据的高级表示。最近,对比学习被应用于多视图聚类,由于其在自监督表示学习方面的强大能力,取得了令人满意的聚类性能。
尽管已经开发了各种IMC方法,但仍然存在一些尚未很好解决的关键问题。首先,多视图数据包含丰富的结构性关联,如视图内关联、视图间关联和类别关联。现有的IMC方法未能共同利用这种多样化的关联,以增强数据表示并减少由于视图缺失问题导致的信息丢失。其次,多视图数据通常包含一些噪声,而各个视图的可靠性是不同的。大多数现有方法忽视了噪声样本和不可靠视图的影响。第三,多视图表示学习和聚类是两个密切相关的任务。适当的数据表示可以促进数据聚类,而聚类结果是表示学习的有效指导。然而,现有的IMC方法很少考虑这两个任务的关联,因此这些方法的性能可能受到限制。
研究动机
作者的研究动机是克服现有不完整多视图聚类方法的局限性。旨在提出一种方法,不仅能够捕捉数据中的多样化关联,还能够有效处理不同视图中的噪声,从而提高聚类结果的准确性和鲁棒性。
解决方案
为解决上述问题,这篇文章提出了一种用于不完整多视图聚类的鲁棒多样化图对比网络RDGC。该方法将多视图表示学习和多样化图对比正则化集成到一个统一的框架中。具体如下:RDGC是一个新颖的深度IMC框架,联合进行多视图表示学习和鲁棒多样化图对比正则化,以获取更具判别性的多视图表示和有效的聚类结果。RDGC的框架如图1所示。
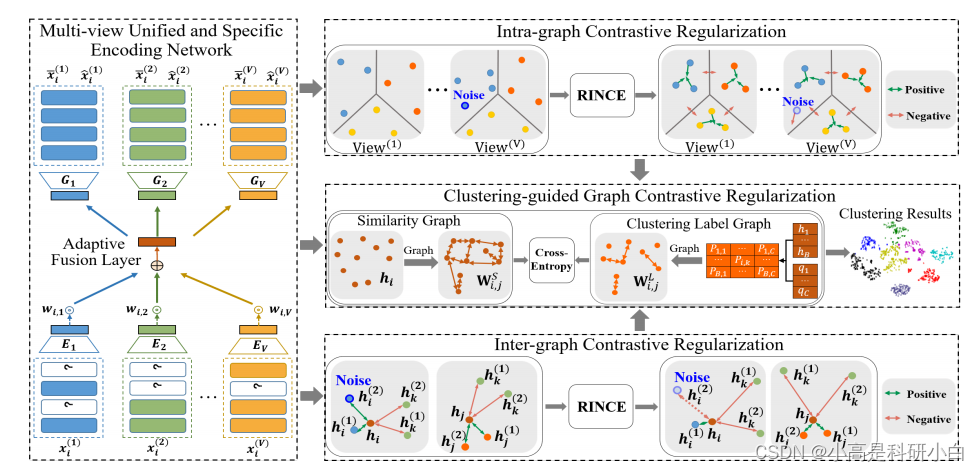
多视图表示学习通过多视图统一和特定编码网络实现,该网络可以准确捕捉不同视图的共享和唯一的信息。多样化图对比正则化包括视图内(局部)对比正则化、视图间(全局)对比正则化和聚类引导图对比正则化。它可以利用多视图数据中固有的多样化关联,减少由于视图缺失问题导致的信息丢失。引入鲁棒对比学习损失以处理噪声样本和不可靠视图。此外,联合进行多视图表示学习和数据聚类,使两个任务相互促进。
-
多视图统一和特定编码网络: 引入了一个网络,将不同视图统一并编码为一个连贯的表示。这种表示允许灵活地估计每个视图对于不完整多视图数据的重要性。
-
鲁棒多样化图对比正则化: 采用了一种鲁棒的多样化图对比正则化技术。该正则化能够捕捉多样化的数据关联,提高学到的表示的区分能力,并减轻由于缺失视图而引起的信息丢失。
-
有效处理噪声和不可靠视图: 通过采用鲁棒对比学习损失,有效地抵抗噪声和不可靠视图的影响。
文章贡献
- RDGC在多视图统一和特定编码网络中引入了自适应融合层,以获得不完整多视图数据的有效表示。它能够准确评估不同视图的重要性,以抵制不可靠视图和不完整视图的影响。
- RDGC提出了一种鲁棒多样化图对比正则化,以捕捉丰富的多视图关联,同时抵制噪声和不可靠视图。它能够有效减轻由于视图缺失问题导致的信息丢失,产生更具判别性的多视图表示。
- RDGC提出了一种聚类引导图对比正则化,联合进行多视图表示学习和数据聚类,使两个任务相互促进,获得更好的聚类性能。
相关工作
亿图脑图MindMaster协同版 https://mm.edrawsoft.cn/app/editor/mhtEukJjTZlKM2PgmlJvbAHyiaPTlqYA
https://mm.edrawsoft.cn/app/editor/mhtEukJjTZlKM2PgmlJvbAHyiaPTlqYA
相关工作部分,并没有完全去分析这篇文章,但但大多数多视图聚类文章的相关工作大差不差,所以我直接链接了自己总结的几篇文章相关工作的思维导图。
模型方法
Notation and Preliminary
提供了有关多视图数据表示的基本符号和预定义。
多视图数据通过 $X^{(v)}$ 表示,其中 $v$ 是视图的索引,$N$ 是样本数量。每个视图的特征用 $x^{(v)}i$ 表示,其中 $i$ 是样本索引。对于不完整的多视图数据,采用指示矩阵 $I$ 记录缺失的样本。指示矩阵 $I$ 的元素 $I{i,j}$ 表示第 $i$ 个样本是否在第 $j$ 个视图中存在。若 $I_{i,j} = 1$,则表示存在,否则为 $0$,这在处理缺失的特征时起到关键作用。
主要目标是对不完整的多视图数据进行聚类,即将 $N$ 个样本分成 $C$ 个类别,但不使用任何标签信息。这一任务的形式化和准备工作为后续方法提供了基础。
在对比学习方面,研究介绍了一种名为鲁棒信息归一化互信息(RINCE)的损失函数,作为对比学习的一般形式。该损失函数的提出是为了解决传统对比学习方法受到噪声干扰的问题。RINCE的对称性质使其能够有效地调整样本的重要性,以减轻噪声的影响,特别是对于那些没有共享信息的虚假正样本对。记为:
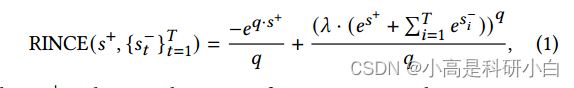
公式中的参数 $q$ 用于平衡对称性质,而 $\lambda$ 则是一个权重参数,控制正样本对和负样本对之间的比例 。其中 $s^+$ 和 $s^-_t$ 分别是正样本对和负样本对的分数,$q, \lambda \in (0, 1]$。$q$ 用于平衡对称性质。当 $q \rightarrow 1$ 时,RINCE变为一个完全满足对称性质的对比损失。在 $q \rightarrow 0$ 的极限下,RINCE渐近等价于 InfoNCE。$\lambda$ 是一个权重参数,用于控制正样本对和负样本对之间的比例。
Multi-view Unified and Specific Encoding Network
这部分主要介绍了一种用于学习不完整多视图数据表示的方法,即多视图统一和特定编码网络。
该方法主要通过引入多视图统一和特定编码网络来处理不完整的多视图数据。编码器网络负责提取视图特定的表示,而自适应融合层通过学习统一表示并区分不同视图的重要性,以应对不可靠或缺失的视图。融合过程如下:
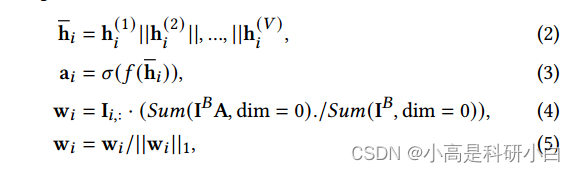
其中 $||$ 是连接操作符,$a_i \in \mathbb{R}^{V}$ 是第 $i$ 个样本的权重向量,$f(\cdot)$ 是全连接网络,$\sigma(\cdot)$ 是 Sigmoid 函数,$A = [a_1; a_2; ...; a_B] \in \mathbb{R}^{B \times V}$,$B$ 是批处理大小,$I_B \in \mathbb{R}^{B \times V}$ 是对应于当前批次中样本的指示矩阵,$w_i \in \mathbb{R}^{V}$ 是第 $i$ 个样本的融合权重。
通过使用自适应融合层,不同视图被分配不同的权重。重要的视图可以被分配更高的权重,不可靠的视图可以被分配较低的权重,而缺失视图的权重为零。此外,融合权重是通过在一个批次中对所有权重进行平均得到的,这可以获得更稳健的权重估计。因此,提出的自适应融合层灵活处理不完整的多视图数据,可以准确捕捉多视图互补信息。第 $i$ 个样本的统一表示通过以下方式计算:

这使得重要视图在融合中有更大的贡献,而不可靠的视图和缺失的视图在融合中有较小的影响。这种灵活的融合机制有助于处理不完整的多视图数据,使得系统能够更好地捕捉视图间的互补信息。整体而言,这一部分提出了一个具有自适应性的多视图编码框架,以处理不完整的多视图数据。
解码器网络 ${G_v}_{v=1}^V$ 旨在重构原始数据。为了保证学到的潜在表示很好地编码了多视图信息,统一表示和视图特定表示均用于数据重构。用统一表示和视图特定表示重构的数据分别用 $x^{(v)}_i = G_v(h^{(v)}_i)$ 和 $x^{(v)}_i = G_v(h_i)$ 表示。多视图统一和视图特定编码网络的损失函数如下所示:
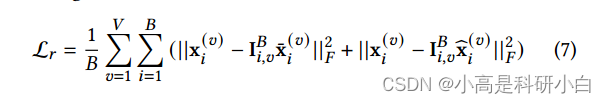
intra-graph Contrastive Regularization - Detailed Analysis
在这一部分,详细地分析图内对比正则化的方法以及其损失函数的原理、细节和意义。
图内对比正则化的原理
-
近邻关系建模: 核心思想是通过构建每个视图的最近邻图来捕捉视图内的局部结构相关性。对于每个样本,根据其在特定视图中的最近邻,形成正例对和负例对,以模拟样本之间的邻近关系。为每个视图构建了一个KNN图,其邻接矩阵 $A^{(v)} \in \mathbb{R}^{B \times B}$ 定义如下:
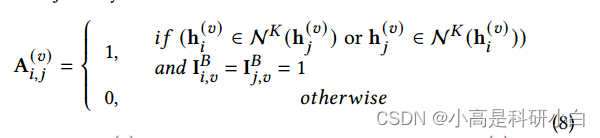
其中 $N_K(h^{(v)}j)$ 表示 $h^{(v)}j$ 的 $K$ 最近邻,通过在当前批次中进行最近邻搜索获得。
-
对比学习: 利用正例对和负例对进行对比学习。正例对的样本被认为在局部结构上相似,而负例对的样本则在局部结构上不相似。通过最大化正例对的相似性和最小化负例对的相似性,使得学到的潜在表示更好地保留了局部结构信息。基于邻接矩阵 $A^{(v)}$,构建了正对比学习的正例集 $\mathcal{C}^+{tr}(i, v)$ 和负对比学习的负例集 $\mathcal{C}^-{tr}(i, v)$,具体如下:
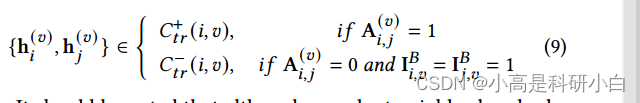
尽管采用邻近关系构建正例对,由于噪音问题,仍可能出现一些假正例(被标记为正例但属于不同类别的样本对)。为减小假阳性对对学到的潜在表示的影响,采用了RINCE用于图内对比正则化。
-
RINCE损失函数: 它是对比损失的一种改进。RINCE考虑了对称性,并通过调整样本的重要性来减轻噪音的影响,特别是对于在表面上没有明显共享信息的假阳性对。对于每个 $h^{(v)}i, i \in {1, ..., B}, v \in {1, ..., V}$,从 $\mathcal{C}^+{tr}(i, v)$ 中采样一个正例对 $\mathbf{s}^+{tr}(i, v)$ 和 $T$ 个负例对集合 ${\mathbf{s}^-{tr}(i, v)t}{t=1}^{T}$,损失函数的表达式如下:
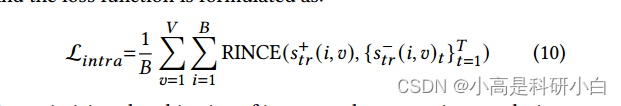
方法的细节分析
-
邻近关系构建: 通过构建每个视图的最近邻图,方法捕捉了样本在局部结构上的邻近关系,以促进潜在表示的判别能力。
-
对比学习策略: 通过正例对和负例对的对比学习,学习到的潜在表示被设计为在局部结构上对相似样本更加敏感。
-
RINCE损失的应用: RINCE损失函数的引入使得对比学习更加鲁棒,能够在存在噪音的情况下更好地优化模型。
-
适用性: 该方法的适用性在于提高多视图数据的表示学习质量,特别是在存在局部结构相关性的情况下,有助于更好地保留样本之间的关系。
Inter-graph Contrastive Regularization - Detailed Analysis
在这一部分,我们将更详细地分析图间对比正则化的方法以及其损失函数的原理、细节和意义。
图间对比正则化的原理
-
在这一部分,我们将更详细地分析图间对比正则化的方法、损失函数的原理、细节和公式符号的具体表示。
图间对比正则化的原理
-
图的对齐: 方法旨在利用不同视图之间的相关性。通过对齐同一样本的视图特定表示和统一表示,不同视图可以相互补充,从而获得更有效的表示。
-
正例对和负例对:正例对(Positive Pairs): 对于每个样本 $i$ 和每个视图 $v$,正例对包含样本的统一表示 $h_i$ 和相应视图的视图特定表示 $h^{(v)}_i$。这样可以确保同一样本在不同视图中的表示相似。负例对(Negative Pairs): 对于每个样本 $i$、每个视图 $v$ 和其他样本 $j$,负例对包含样本的统一表示 $h_i$ 和其他样本 $j$ 在视图 $v$ 中的视图特定表示 $h^{(v)}_j$。这样可以确保同一样本在不同视图中的表示与其他样本在相同视图中的表示不同。
具体而言,正例对和负例对的构建如下:- 正例对:$\mathcal{C}^+_t(i, v) = {{h_i, h^{(v)}i}, v = 1, ..., V, I^B{i,v} = 1}$
-
负例对:$\mathcal{C}^-_t(i, v) = {{h_i, h_j}, {h^{(v)}i, h^{(t)}j}, j \neq i, t = 1, ..., V, I^B{i,v} = I^B{j,v} = 1}$
这里,$I^B_{i,v}$ 是指示矩阵,表示在当前批次中样本 $i$ 在视图 $v$ 中是否存在。
-
RINCE损失的应用: 为了应对不可靠视图引起的假正例对,对比损失的改进版本RINCE被用于图间对比正则化。对于每个统一表示 $h_i$,从 $\mathcal{C}^+_t(i, v)$ 中采样一个正例对 $\mathbf{s}^+_t(i, v)$ 和 $\mathcal{C}^-t(i, v)$ 中的 $T$ 个负例对 ${\mathbf{s}^-{t}(i, v)t}{t=1}^{T}$,损失函数的定义如下:
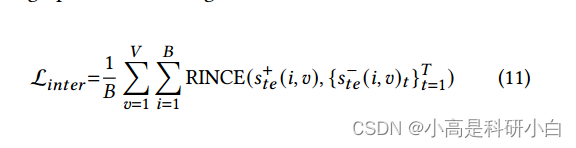
其中 $s^+_{te}(i, v)$ 表示正例对,${s^-_{te}(i, v)t}{t=1}^{T}$ 表示负例对。
Clustering-guided Graph Contrastive Regularization
聚类引导的图对比正则化的目标
该方法的目标是通过联合进行统一表示学习和数据聚类,利用两个任务之间的相关性,并使它们相互影响,从而进一步提高多视图聚类性能。
2. 具体项的说明:
- 聚类概率的计算:
- K-means 聚类: 采用 K-means 聚类方法来评估每个样本的聚类概率。
- 聚类中心: 统一表示 ${h_i}$ 被聚类为 $C$ 个簇,聚类中心由 $Q = [q_1, q_2, .., q_C] \in \mathbb{R}^{k \times C}$ 表示。
- 聚类概率矩阵: 通过以下公式计算聚类概率矩阵 $P \in \mathbb{R}^{B \times C}$:
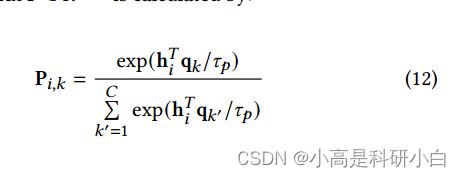
这里,$\tau_p$ 是标量参数。
- 聚类标签图的构建:
- 通过使用聚类概率 $P$,构建聚类标签图 $W^L_{ij}$:
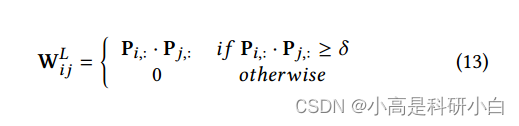
W_L_{i,j} = \begin{cases} P_{i,:} \cdot P_{j,:} & \text{if } \sum P_{i,:} \cdot P_{j,:} \geq \delta \\ 0 & \text{otherwise} \end{cases}
其中小于 $\delta$ 的元素被设置为0,以增强具有更相似聚类分布的样本之间的相关性。
-
相似性图的构建:
- 通过统一表示构建相似性图 $W_S$,其中 $W_{S_{i,j}} = \exp(h_i^T \cdot h_j / \tau_S)$。
-
图的结构相似性的最小化:
- 将相似性图 $W_S$ 和聚类标签图 $W_L$ 的结构相似性最小化,通过对这两个图进行行归一化,得到归一化矩阵 $W_S^{\text{norm}}$ 和 $W_L^{\text{norm}}$,然后使用它们之间的交叉熵损失:
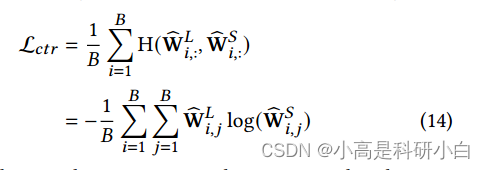
L_{ctgr} = -\frac{1}{B} \sum_{i=1}^{B} H(W_L^{\text{norm}}_{i,:}, W_S^{\text{norm}}_{i,:})
这里,$H(·, ·)$ 表示两个分布之间的交叉熵。
The Overall Loss Function
通过整合上述目标,RDGC(即 Robust Deep Graph Contrastive)的整体损失函数定义如下:
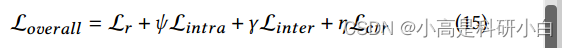
其中,参数是用于平衡不同对比正则化项的超参数。算法1展示了提出方法的完整学习过程。

这个损失函数包括了多个部分,每个部分都有其独特的作用,通过调整超参数,可以平衡这些部分对最终损失的影响。整体而言,这个损失函数旨在通过对比正则化、图对比正则化以及聚类引导的图对比正则化来实现对多视图数据的有效学习。
实验证实
在四个多视图聚类数据集上进行的大量实验证明了RDGC方法相对于现有最先进方法的卓越性能。实验结果验证了RDGC方法在捕捉多样化关联、处理缺失视图和抵抗噪声方面的有效性,为不完整多视图聚类任务提供了更为准确和鲁棒的解决方案。
结论
- 提出了一种鲁棒多样化图对比网络(RDGC)用于不完整多视图聚类(IMC)。
- RDGC整合了多视图表示学习和鲁棒多样化图对比正则化,形成了一个统一的框架。
- 与现有IMC方法相比,RDGC采用鲁棒对比学习损失,抵抗不可靠的视图和噪声,提高了多视图表示的鲁棒性。
- 引入了多样化图对比正则化,以捕捉多视图数据中的数据相关性,提高了数据表示的判别能力。
- RDGC能够联合进行数据聚类和表示学习,促使这两个任务相互促进。
- 实验证明RDGC在多视图聚类方面优于当前最先进的IMC方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









