







目录
什么是NIO
NIO是Java提供的一种基于Channel和Buffer的IO操作方式,即:利用内存映射文件方式处理输入和输出。NIO具有更加强大和灵活的IO操作能力,提供了非阻塞IO、多路复用等特性,特别适合需要处理大量连接的网络编程场景
-
在JDK1.4时提出了NIO(New I/O),在BIO模型(Blocking IO)的基础上,增加了NIO模型(Non-Blocking IO),即同步非阻塞方式
-
JDK7时在NIO包中增加了AIO,NIO也随之被称为NIO2.0(即NIO+AIO),NIO是同步非阻塞的,AIO是异步非阻塞的。
NIO官方叫法为New I/O,但是由于后续加入了AIO,导致New IO已经不能表达已有的IO模型,因此NIO也被业界称为Non-blocking I/O,即非阻塞IO
本文只对Non-blocking IO进行探讨,AIO不做过多赘述,AIO详情请参考AIO(异步IO)
想要详细了解IO多路复用模型原理参考:IO多路复用模型原理
使用场景
-
对于低负载、低并发的应用程序,可以使用同步阻塞IO来提升开发效率和维护性
-
但是对于高负载、高并发的网络应用,应该使用NIO的非阻塞模式来开发
NIO(new IO)相关包路径
其中包下的常用类后续会详细说明
-
java.nio:主要包含各种与Buffer相关的类
-
java.nio.channels:主要包含与Channel和Selector相关的类
套接字的特别说明(因为也在这个包下)
在该包路径下,NIO提供了与传统IO模型中
Socket和ServerSocket相对应的SocketChannel和ServerSocketChannel两种不同的套接字通道实现新增的这两种通道都支持阻塞和非阻塞方式
-
java.nio.charset:主要包含与字符集相关的类
-
java.nio.file:主要包含文件处理的工具类
-
java.nio.channels.spi:主要包含与Channel相关的服务提供者编程接口
-
java.nio.charset.spi:主要包含与字符集相关的服务提供者编程接口
NIO的实现基础
NIO是基于Linux IO模型的IO多路复用模型实现的,netty、tomcat5及以后的版本的实现都是基于NIO,想要理解Linux的IO模型参考:Linux的五种网络IO模型
IO复用模型图解
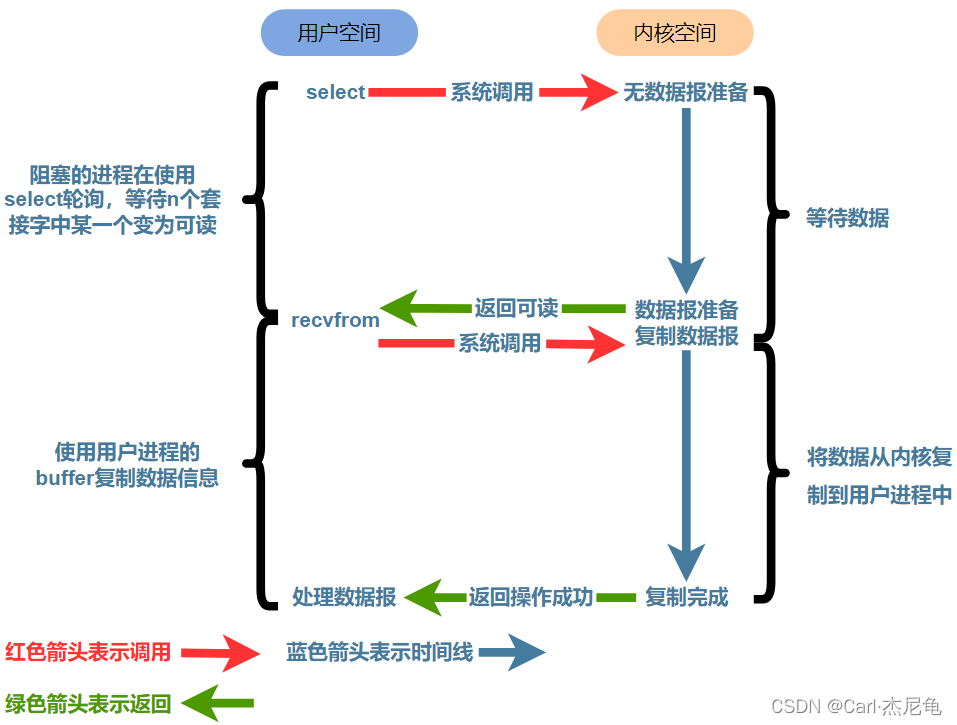
这里的多路是指N个连接,每一个连接对应一个channel,或者说多路就是多个channel,是指多个连接复用了一个线程或者少量线程(在tomcat中是少量线程)
NIO的核心组件
JavaNIO主要包含三个核心组件:
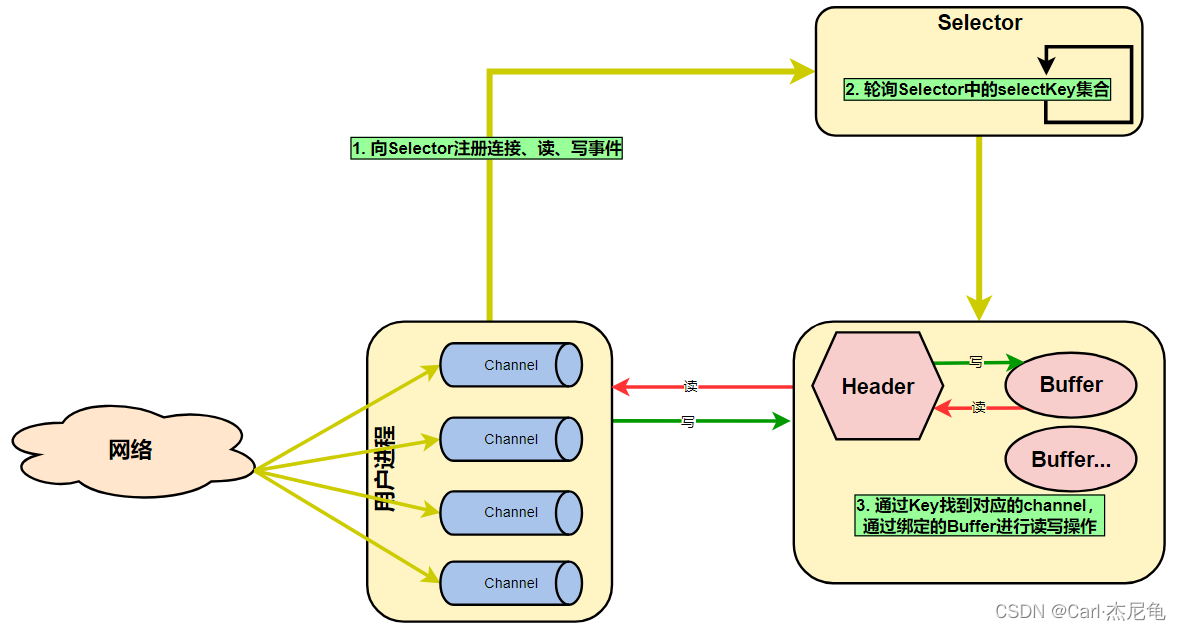
**Selector:**多路复用器(选择器),是NIO的基础,也可以称为轮询代理器、事件订阅器或Channel容器管理器。Selector提供选择已经就绪的任务的能力,允许一个线程同时监听多个通道上的事件,即:单线程同时管理多个网络连接,并在某个通道上有数据可读或可写时及时做出响应,是Java NIO实现非阻塞IO的关键组件
**Channel:**是所有数据的传输通道,通道可以是文件、网络连接等。Channel提供了一个map()方法,通过该map()方法可以直接将“一块数据”映射到内存中
**Buffer:**是一个容器(类似数组),发送到Channel中的所有对象都必须首先放到Buffer中,从Channel中读取的数据也会先放到Buffer中
为什么要将传统IO模型中stream的概念换成channel+buffer的概念?
-
Stream与Channel对比
-
传统的阻塞IO模型中,
stream是用于在程序和数据源之间进行数据传输的抽象概念,流的特点就是顺序的、逐个访问。 -
Java NIO中提出的Channel也是进行数据传输的抽象概念,区别在于stream是单向数据传输,而channel是双向数据传输,
从这个角度看,Channel是全双工通信,Stream是单工通信,那么Channel必然就会比Stream更加高效
-
-
为什么传统IO没有提出Buffer的概念?
缓冲区以及缓冲区是如何工作的,这是所有IO实现的基础,即输入和输出就是把数据移进 or 移出缓冲区
进程执行IO操作,就是向操作系统发出请求,将数据从缓冲区取出(写操作),或者将数据写入缓冲区(读操作)
既然Buffer是所有IO实现的基础,传统IO模型并没有Buffer,是不是说错了或者传统IO并不是IO?
其实并不是,只是传统IO中Buffer是开发者自己创建的,也就是byte[]数组,这个byte数组设置多大都是开发者自己决定,因此没有提出Buffer的概念
Java byte[] input = new byte[1024]; /* 读取数据 */ socket.getInputStream().read(input);
而在JavaNIO中,缓冲区是一个固定大小的,连续内存块,用于暂时存储数据,为缓冲区也提供了一系列的操作API,因此在NIO特意强调了Buffer的概念
NIO注册、轮询等待、读写操作协作关系如下图:
Buffer
Buffer是Channel操作读写的组件,包含了写入和读取得数据。在NIO库中,所有数据都是用缓冲区处理的,缓冲区实际上就是一个数组,并提供了对数据结构化以及维护读写位置等信息。
Buffer是一个抽象类,我们在网络传输中大多数都是使用ByteBuffer,它可以在底层字节数组上进行get/set操作。除了ByteBuffer之外,对应于其他基本数据类型(boolean除外)都有相应的Buffer类(CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer)。
这些Buffer类没有提供构造器访问,因此创建Buffer类就必须使用静态方法allocate(int capacity),即:ByteBuffer buffer = ByteBuffer.allocate(10)表示创建容量为10的ByteBuffer对象
ByteBuffer类的子类:MappedByteBuffer用于表示Channel将磁盘文件的部分或全部内容映射到内存中后得到的结果。MappedByteBuffer对象是由Channel的map()方法返回
-
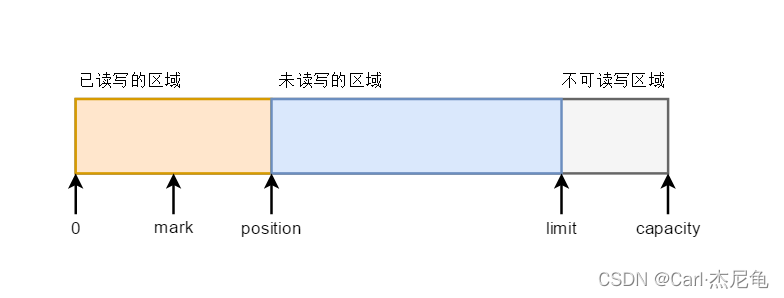
容量(capacity):缓冲区的容量,表示该Buffer的最大数据容量,创建后不可改变,不能为负值
-
界限(limit):第一个不应该被读出或写入的缓冲区位置索引,位于limit后的数据既不可被读也不可被写
-
位置(position):用于指明下一个可以被读出或写入的缓冲区位置索引,索引从0开始,即如果从Channel中读了两个数据后(0,1),position指向的索引应该是2(第三个即将读取数据的位置)
position可以自己设置,即设置从索引为mark处读取数据
/**
* XxxBuffer方法:
* put():向Buffer中放入一些数据--一般不使用,都是从Channel中获取数据
* get():向Buffer中取出数据
* flip():当Buffer装入数据结束后,调用该方法可以设置limit为当前位置,避免后续数据的添加--为输出数据做准备
* clear():对界限、位置进行初始化,limit置为capacity,position设置为0,为下一次取数做准备
* int capacity():返回Buffer的容量大小
* boolean hasRemaining():判断当前位置和界限之间是否还有元素可供处理
* int limit():返回Buffer的界限(limit)的位置
* Buffer mark():设置Buffer的标记(mark)位置,只能在0-position之间做标记
* int position():返回Buffer中的position值
* Buffer position(int newPs):设置Buffer的position,并返回position被修改后的Buffer对象
* int remaining():返回当前位置和界限之间的元素个数
* Buffer reset():将位置转到mark所在的位置
* Buffer rewind():将位置设置为0,取消设置的mark
* @Param:
* @return: void
*/
public void BufferTest(){
//创建一个CharBuffer缓冲区,设置容量为20
CharBuffer buff= CharBuffer.allocate(20);
//测试方法:
//获取当前容量、界限、位置
System.out.println("初始值:"+buff.capacity()+"\n"+
buff.limit()+"\n"+
buff.position());//20、20、0
buff.put('1');
buff.put('2');
buff.put('3');
buff.position(1).mark();//标记位置索引处
buff.rewind();//将position设置为0,并将mark清除,此时再调用reset()将会报错java.nio.InvalidMarkException
buff.mark().reset();//将position转移到标记处
buff.put("abc");
buff.put("java");
//abcjava
//设置界限值
buff.limit(buff.position());
System.out.println("添加数据后:"+buff.capacity()+"\n"+
buff.limit()+"\n"+
buff.position());//20、7、7
//初始化容量、界限、位置
int position = buff.position();
buff.position(0);
System.out.println("修改后:"+buff.capacity()+"\n"+
buff.limit()+"\n"+
buff.position());//20、7、0
//遍历Buffer数组的数据
for (int i = 0; i < position; i++) {
System.out.print(buff.get());
}
System.out.println();
//hasRemaining判断是否可继续添加元素,position >= limit返回false,position < limit返回true
System.out.println(buff.remaining());//0
System.out.println(buff.hasRemaining());//false
buff.limit(15);
System.out.println(buff.hasRemaining());//true
System.out.println(buff.position());//7
System.out.println("remaining="+buff.remaining());//8 还可以添加8个元素
buff.clear();
System.out.println("clear后:"+buff.capacity()+"\n"+
buff.limit()+"\n"+
buff.position());//20、20、0
}
Buffer的缺点:
-
XxxBuffer使用
allocate()方法创建的Buffer对象是普通的Buffer–创建在Heap上的一块连续区域–间接缓冲区 -
ByteBuffer还有一个
allocateDirect()方法创建的Buffer是直接Buffer–创建在物理内存上开辟空间–直接缓冲区
1. 间接缓冲区:易于管理,垃圾回收器可回收,但是空间有限,读写文件速度较慢(从磁盘读到内存)
2. 直接缓冲区:空间较大,读写速度快(从磁盘读到磁盘的速度),但是不受垃圾回收器的管理,创建和销毁都极耗性能
-
直接Buffer的创建成本高于间接Buffer,所以直接Buffer只用于生存期长的Buffer。
-
直接Buffer只有ByteBuffer才能创建,因此如果需要其他的类型,只能使用创建好的ByteBuffer转型为其他类型
重要注意事项:
flip()方法可以将Buffer从写模式切换到读模式,flip()方法会将position设回到0,并将limit设置成之前position的值
缓冲区详解
数据如何从磁盘读到用户进程
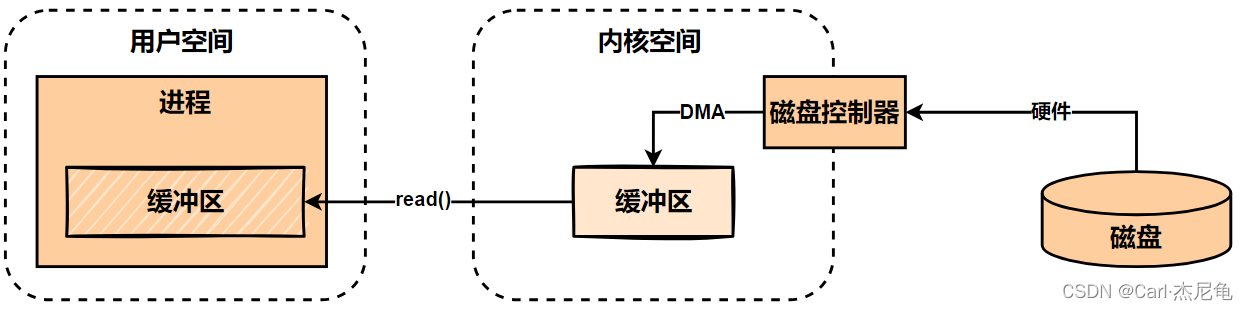
上图解析
该图描述了数据从外部磁盘向运行中的进程的内存区域移动的过程
-
进程使用read()系统调用,要求从指定目标处获取数据
-
此时CPU会通过特定的指令将磁盘控制器初始化,包括设置数据传输的起始地址、目的地址、数据长度等
-
外部设备发起直接内存访问请求,请求磁盘控制器来执行数据传输操作
-
磁盘控制器根据初始化的参数直接在外设和内核内存缓冲区之间进行数据传输,不需要CPU干预
-
当数据传输完成后,磁盘控制器会发送一个信号中断给CPU,通知传输完成
-
一旦内核的内存缓冲区数据传输完成,内核就会立即把数据从内核空间的临时缓冲区拷贝到用户进程执行read()系统调用时指定的缓冲区内
Channel
Channel表示打开到IO设备的连接,可以直接将指定的文件的部分或全部直接映射为Buffer–映射,程序不能直接访问Channel中的数据(读取、写入都不行),必须通过Buffer进行承载后从Buffer中操作这些数据
Channel有两种实现:SelectableChannel1用于网络读写;FileChannel用于文件操作
其中SelectableChannel有以下几种实现:
-
ServerSocketChannel:应用服务器程序的监听通道。只有通过了这个通道,应用程序才能向操作系统注册支持多路复用IO的端口监听。同时支持UDP协议和TCP协议
-
SocketChannel:TCP Socket套接字的监听通道,一个Socket套接字对应了一个客户端IP:端口 → 服务端IP:端口的通信连接
-
DatagramChannel:UDP数据报文的监听通道
Channel相比于IO中的Stream流更加高效2,但是必须和Buffer一起使用。
Channel的使用
-
Channel不能使用构造器来创建,只能通过字节流InputStream,OutputStream(节点流)来调用getChannel()方法来创建
-
不同的节点流调用getChannel()方法创建的Channel对象不一样。
如:FileInputStream/FileOutputStream->FileChannel
PipedInputStream/PipedOutputStream->Pip.SinkChannel/Pip.SourceChannel -
Channel常用的三个方法:
-
MappedByteBuffer map(FileChannel.MapMode mode,long position,long size)
将Channel对应的部分或全部的数据映射成ByteBuffer
参数说明:
mode:映射模式-三种:READ_ONLY(只读)、PRIVATE(私有(写时复制))、READ_WRITE(读写)
position:Buffer的初始化位置
size:Buffer的容量
-
read():用于读取Buffer中的数据
-
write():用于将数据写入Buffer
-
FileChannel inChannel = null;
FileChannel outChannel = null;
try {
//1.创建文件对象--指定读取和写入的文件
File src=new File("E:\\Documents\\java.txt");
File dest=new File("E:\\Documents\\java1.txt");
//2.使用FileInputStream进行文件读取、FileOutputStream进行文件写入
//不一样的是采用管道的方式--这里就需要getChannel()创建Channel对象
inChannel = new FileInputStream(src).getChannel();//只能读
outChannel = new FileOutputStream(dest).getChannel();//只能写
//3.将管道数据通过map()方法传递给MappedByteBuffer对象进行缓冲承载
MappedByteBuffer buffer=inChannel.map(FileChannel.MapMode.READ_ONLY, 0, src.length());
//4.将获取的内容buffer交给Channel写回到指定文件java1.txt中
outChannel.write(buffer);
//将文件内容打印到控制台
//1.初始化position和limit
buffer.clear();
//2.设置输出编码格式
Charset charset=Charset.forName("UTF-8");
//3.将ByteBuffer转换成字符集的Buffer
CharsetDecoder decoder=charset.newDecoder();
CharBuffer cb=decoder.decode(buffer);
//4.输出字符集buffer
System.out.println(cb);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
inChannel.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
outChannel.close();
} catch (IOException e) {
e.printStackTrace();
}
}
使用RandomAccessFile创建Channel对象
-
管道的写数据的方式是追加–但是重新执行程序就是覆盖–这种情况需要修改position的位置
-
源文件的随机访问对象创建的管道必须可读,目标文件的随机访问对象创建的管道必须可写
-
源文件的随机访问对象创建的管道使用map()方法生成buffer后,目标文件的随机访问对象创建的管道使用write()方法写出buffer
-
最后一定要关闭流
FileChannel channel = null;
FileChannel channel1 = null;
try {
File srcPath=new File("E:\\Documents\\java.txt");
File destPath=new File("E:\\Documents\\java1.txt");
channel = new RandomAccessFile(srcPath,"r").getChannel();
channel1 = new RandomAccessFile(destPath,"rw").getChannel();
ByteBuffer map = channel.map(FileChannel.MapMode.READ_ONLY, 0, srcPath.length());
channel1.position(destPath.length());
channel1.write(map);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
channel.close();
} catch (IOException e) {
e.printStackTrace();
}
}
File src=new File("E:/Documents/java.txt");
FileChannel channel = new FileInputStream(src).getChannel();
ByteBuffer bf=ByteBuffer.allocate(256);
int len=0;
while ((len=channel.read(bf))!=-1) {
//limit设置为position,避免操作空白区域。如果覆盖到指定位置后,后续还有内容也不可读取,这样避免覆盖不完全出现错误数据
bf.flip();
System.out.println(bf);
Charset charset=Charset.forName("UTF-8");
CharsetDecoder decoder = charset.newDecoder();
CharBuffer cb = decoder.decode(bf);
System.out.println(cb);
//重置buffer的参数,内容依旧是采用覆盖的方式,clear不会修改Buffer中的内容
bf.clear();
}
其他组件
**Charset类:**用于将Unicode字符映射成为字节序列以及逆映射操作
字符集和Charset
由于计算机的文件、数据、图片文件底层都是二进制存储的(全部都是字节码)
编码:将明文的字符序列转换成计算机理解的二进制序列称为编码
解码:将二进制序列转换成明文字符串称为解码
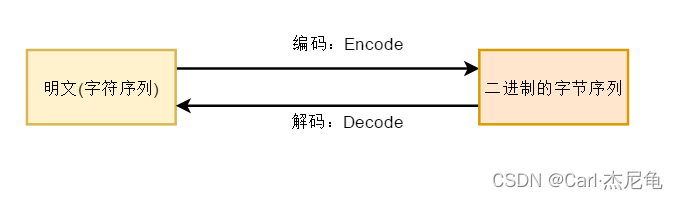
java默认使用Unicode字符集,当从操作系统中读取数据到java程序容易出现乱码
当A程序使用A字符集进行数据编码(二进制)存储到硬盘,B程序采用B字符集进行数据解码,解码的二进制数据转换后的字符与A字符集转换后的字符不一致就出现了乱码的情况。
JDK1.4提供了Charset来处理字节序列和字符序列之间的转换关系
-
该类包含了用于创建编码器和解码器的方法
-
获取Charset所支持的字符集的方法availableCharsets()
forName(String charsetName):创建Charset对应字符集的对象实例
newDecoder():通过Charset对象获取对应的解码器
newEncoder():通过Charset对象获取对应的编码器
CharBuffer encode(ByteBuffer bb):将ByteBuffer中的字节序列转换为字符序列
ByteBuffer decode(CharBuffer cb):将CharBuffer中的字符序列转换为字节序列
ByteBuffer encode(String str):将String中的字符序列转换为字节序列
// SortedMap<String, Charset> stringCharsetSortedMap = Charset.availableCharsets();
// stringCharsetSortedMap.forEach((key,value)-> System.out.println(key+"<->"+value));
Charset charset = Charset.forName("UTF-8");
ByteBuffer bb = charset.encode("中文字符");
System.out.println(bb);//java.nio.HeapByteBuffer[pos=0 lim=12 cap=19]
//编码解码方式一:
CharBuffer decode1 = charset.decode(bb);
System.out.println(decode1);//中文字符
ByteBuffer encode1 = charset.encode(decode1);
System.out.println(encode1);//java.nio.HeapByteBuffer[pos=0 lim=12 cap=19]
//编码解码方式二:
CharsetDecoder decoder = charset.newDecoder();
CharsetEncoder encoder = charset.newEncoder();
CharBuffer decode = decoder.decode(encode1);
System.out.println(decode);//中文字符
ByteBuffer encode = encoder.encode(decode);
System.out.println(encode);//java.nio.HeapByteBuffer[pos=0 lim=12 cap=19]
}
文件锁
-
文件锁是在多个运行的程序需要并发修改同一个文件时所必须的
-
使用文件锁可以有效地阻止多个进程并发的修改同一个文件,但是并不是所有平台都提供了文件锁机制
-
文件锁能控制文件的全部或部分字节的访问
-
文件锁在不同的操作系统的差别较大
NIO中java提供了FileLock来支持文件锁定功能,在FileChannel中提供的lock()/tryLock()方法可以获取文件锁FileLock对象
-
lock(long position,long size,boolean shared):如果未获取文件锁,则会导致线程阻塞
-
tryLock(long position,long size,boolean shared):如果未获取文件锁直接返回null,获取返回该文件锁
-
上述两个方法参数解析:
-
position:从文件的position位置开始
-
size:给长度为size的内容加锁
-
shared:true表示为共享锁:允许多个进程来读取该文件,但是其他进程获得该文件的排他锁;false表示该锁为排他锁,自己读取时其他线程不能获取锁
-
-
直接使用lock()或tryLock()方法获取的文件锁是排他锁,即shared默认值为false
FileLock fileLock = null;
try {
FileOutputStream fileOutputStream = new FileOutputStream("E:/Documents/java.txt");
FileChannel channel = fileOutputStream.getChannel();
fileLock = channel.tryLock();//创建锁以后,其他程序将无法对该文件进行修改
Thread.sleep(1000);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
try {
fileLock.release();
} catch (IOException e) {
e.printStackTrace();
}
}
虽然文件锁可以用于控制并发访问,但是还是推荐使用数据库来保存程序信息,而不是文件
注意:
-
对于部分平台,文件锁即使可以被获取,文件依旧是可以被其他线程操作的
-
对于部分平台,不支持同步地锁定一个文件并把它映射到内存中
-
文件锁是由java虚拟机持有的,如果两个java程序使用同一个java虚拟机,则不能对同一个文件进行加锁操作
-
对于部分平台,关闭FileChannel时,会释放java虚拟机在该文件上的所有锁,因此应该避免对同一个被锁定的文件打开多个FileChannel
NIO工具类
NIO问题:
-
File类功能有限
-
File类不能利用特定文件系统的特性
-
File类的方法性能不高
-
File类大多数方法出错时不会提供异常信息
升级NIO.2:
-
提供了Path接口和Paths实现工具类
-
提供了Files工具类
public class Nio2Test {
@Test
public void pathsTest(){
Path path = Paths.get("E:/Documents/java.txt");
//path包含的路径数量
System.out.println(path.getNameCount());//2=>(Document,java.txt)
//获取根目录
System.out.println(path.getRoot());//E:\
//获取绝对路径
System.out.println(path.toAbsolutePath());//E:\Documents\java.txt
Path path1 = Paths.get("E:", "Documents", "java.txt");
System.out.println(path1);//E:\Documents\java.txt
}
@Test
public void File() throws IOException {
//复制文件
Files.copy(Paths.get("E:","Documents","java1.txt"), new FileOutputStream("E:/Documents/java2.txt"));
//检查文件是否为隐藏文件
System.out.println("Nio2Test.java:"+Files.isHidden(Paths.get("out.txt")));//false
List<String> list = Files.readAllLines(Paths.get("E:/Documents/java2.txt"), Charset.forName("UTF-8"));
System.out.println(list);
//获取文件大小
long size = Files.size(Paths.get("E:/Documents/java2.txt"));
System.out.println(size);
//写数据到文件中
ArrayList<String> poem = new ArrayList<>();
poem.add("今天搞完IO没得问题吧");
poem.add("明天搞完网络编程第一章没得问题吧");
poem.add("后天搞完网络编程第二章搞完IO没得问题吧");
poem.add("大后天搞完网络编程第三章搞完IO没得问题吧");
Path write = Files.write(Paths.get("E:/Documents/java2.txt"), poem, Charset.forName("UTF-8"));//覆盖
System.out.println(write);
//按行获取文件内容,使用Stream接口中的forEache方法遍历
Files.lines(Paths.get("E:/Documents/java2.txt"),Charset.forName("UTF-8")).forEach(ele-> System.out.println(ele));
//获取目录下文件,使用Stream接口中的forEache方法遍历
Files.list(Paths.get("E:/Documents")).forEach(ele-> System.out.println(ele));
//获取当前文件的根目录别名
FileStore fileStore = Files.getFileStore(Paths.get("E:/Documents/java2.txt"));
System.out.println(fileStore);
//E盘总空间
long totalSpace = fileStore.getTotalSpace();
System.out.println(totalSpace);
//E盘可用空间
long unallocatedSpace = fileStore.getUnallocatedSpace();
System.out.println(unallocatedSpace);
}
}
使用Files的FileVisitor遍历文件和目录
不使用Files,通常想要遍历指定目录下的所有文件和子目录都是使用递归的方式,这种方式不仅复杂,灵活性也不高
在Files类中提供了两个方法来遍历文件和子目录
walkFileTree(Path start,FileVisitor<? super Path> visitor):遍历start路径下的所有文件和子目录
walkFileTree(Path start,Set options,int maxDepth,FileVisitor<? super Path> visitor):遍历start路径下的所有文件和子目录,但是可根据maxDepth控制遍历深度
两个方法都使用了FileVisitor作为入参,FileVisitor代表一个文件访问器,walkFileTree()方法会自动遍历start路径下的所有文件和子目录,遍历文件和子目录都会触发FileVisitor中相应的方法
FileVisitor中定义的四个方法:
FileVisitResult postVisitDirectory(T dir,IOException exc):访问子目录之后触发该方法
FileVisitResult preVisitDirectory(T dir,BasicFileAttributes attrs):访问子目录之前触发该方法
FileVisitResult visitFile(T file,BasicFileAttributes attrs):访问file文件时触发该方法
FileVisitResult visitFileFailed(T file,IOException exec):访问file文件失败时触发该方法
FileVisitResult是一个枚举类,代表访问之后的后续行为:
CONTINUE:代表继续访问
SKIP_SIBLINGS:代表继续访问,但不访问该文件或目录的兄弟文件或目录
SKIP_SUBTREE:代表继续访问,但不访问该文件或目录的子目录树
TERMINATE:代表中止访问
如果想要实现自己的文件访问器,可以通过继承SimpleFileVisitor来实现,SimpleFileVisitor是FileVisitor的实现类,这样就可以根据需要、选择性的重写指定方法了
public class FileVisitorTest{
public static void main(String[] args) throws Exception{
Files.walkFileTree(Paths.get("G:","publish","codes","15"),new SimpleFileVisitor<Path>(){
@Override
public FileVisitResult visitFile(Path file,BasicFileAttributes attrs) throws IOException{
System.out.println("正在访问"+file+"文件");
//找到了FileVisitorTest.java文件
if(file.endsWith("FileVisitorTest.java")){
System.out.println("--已经找到目标文件--");
return FileVisitResult.TERMINATE;
}
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult preVisitDirectory(Path dir,BasicFileAttributes attrs) throws IOException{
System.out.println("正在访问"+dir+"路径");
return FileVisitResult.CONTINUE;
}
})
}
}
使用WatchService监控文件变化
不使用WatchService的情况下,想要监控文件的变化,则需要考虑启动一条后台线程,这条后台线程每隔一段实践去遍历一次指定目录的文件,如果发现此次遍历结果与上次遍历结果不同,则认为文件发生了变化,这种方式不仅十分繁琐,而且性能也不好
Path类提供了一个方法用于监听文件系统的变化
register(WatchService watcher,WatchEvent.Kind<?>… events):用watcher监听该path代表的目录下的文件变化。events参数指定要监听哪些类型的事件
这个方法最核心的就是WatchService,它代表一个文件系统监听服务,它负责监听path代表的目录下的文件变化,一旦使用register()方法完成注册之后,接下来就可以调用WatchService的如下三个方法来获取监听目录的文件变化事件
WatchKey poll():获取下一个WatchKey,如果没有WatchKey发生就立即返回null;
WatchKey poll(long timeout,TimeUnit unit):尝试等待timeout实践去获取下一个WatchKey;
WatchKey take():获取下一个WatchKey,如果没有WatchKey发生就一直等待
public class WatchServiceTest{
public static void main(String[) args) throws Exception{
//获取文件系统atchService对象
WatchService watchService = FileSystems.getDefault()
.newWatchService();
//为C:盘根路径注册监昕
Paths.get("C:/").register(watchService
, StandardWatchEventKinds.ENTRY_CREATE
, StandardWatchEventKinds.ENTRY_MODIFY
, StandardWatchEventKinds.ENTRY_DELETE) ;
while(true){
//获取下一个文件变化事件
WatchKey key = watchService.take(); //①
for (WatchEvent<?> event : key.pollEvents()){
System.out.println(event.context() + "文件发生了" + event.kind() + "事件!" ) ;
}
//重设 WatchKey
boolean valid = key.reset();
// 如果重设失败 退出监听
if (!valid){
break;
}
}
}
}
代码说明:
在①处试图获取下一个WatchKey,如果没有发生就等待,因此C盘路径下的每次文件的变化都会被该程序监听到
访问文件属性
在未使用NIO工具类的情况下,以前的File类可以访问一些简单的文件属性,比如文件大小、修改时间、文件是否隐藏、是文件还是目录等。如果程序需要获取或修改更多的文件属性,必须利用运行所在的平台的特定代码来实现。
NIO.2在java.nio.file.attribute包下提供了大量的工具类,通过这些工具类,开发者可以非常简单的读取、修改文件属性。这些工具类主要分为两类:
-
XxxAttributeView:代表某种文件属性的视图
-
XxxAttributes:代表某种文件属性的集合,一般通过XxxAttributeView获取XxxAttributes
FileAttributeView是其他XxxAttributeView的父接口,以下是一些常用的FileAttributeView的实现类
AclFileAttributeView:通过AclFileAttributeView,可以为特定文件设置ACL(Access Control List)及文件所有者属性。其中getAcl()方法返回List对象,代表了该文件的权限集合;通过setAcl(List)方法可以修改该文件的ACL
BasicFileAttributeView:它可以获取或修改文件的基本属性,包括文件的最后修改时间、最后访问时间、创建时间、大小、是否为目录、是否为符号链接等。其中readAttributes()方法返回一个BasicFileAttributes对象,对文件夹基本属性的修改是通过BasicFileAttributes对象来完成的
DosFileAttributeView:它主要用于获取或修改文件的DOS相关属性,比如文件是否只读、是否隐藏、是否为系统文件、是否为存档文件等。其中readAttributes()方法返回一个DosFileAttributes对象,对这些属性的修改是通过DosFileAttributes对象来完成的
FileOwnerAttributeView:它主要用于获取或修改文件的所有者。其中getOwner()方法返回一个UserPrincipal对象来代表文件所有者,也可以调用setOwner(UserPrincipal owner)方法来改变文件的所有者
PosixFileAttributeView:它主要用于获取或修改POSIX(Portable Operating System Interface of INIX)属性,其中readAttributes()方法返回一个PosixFileAttributes对象,该对象可用于获取或修改文件的所有者、组所有者、访问权限信息(可以看作是UNIX中chmod所作的事情)。注意:这个View只在Unix、Linux等系统上有用
UserDefinedFileAttributeAttributeView:它可以让开发者为文件设置一些自定义属性

















 1431
1431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











