







需要周期性的统计近万台设备的实时状态,包括设备ID、压力、温度、湿度以及对应的时间戳,这些与发生时间相关的数据,就成为时间序列数据。这些数据的特点是没有严格的关系模型,记录的信息可以表示成键和值的关系,所以并不需要关系型数据库来保存。Redis基于自身数据结构和扩展模块,提供了两种解决方案。
在实际应用中,时间序列数据通常是持续高并发写入的,时间序列数据的写入通常是插入新数据,而不是更新已存在的数据。这种数据的写入特点很简单,就是插入数据快,这要求我们选择的数据类型,在进行数据插入时,时间复杂度要低,尽量不阻塞。Redis中Hash和String的时间复杂度时O(1),但是String类型在记录小数据时,元数据开销过大,不适合保存大量数据。
针对时间序列的数据要写得快,Redis的高性能写特性就可以直接满足了,而时间序列的查询模式比较多,要支持单点查询、范围查询和聚合查询。Redis提供了保存时间序列数据的两种方案,分别是基于Hash和Sorted Set实现,以及基于RedisTimeSeries模块实现。
Hash和Sorted Set组合的方式有一个明显的好处,它们是Redis内在的数据类型,代码成熟和性能稳定。为什么保存时间序列数据,要同时用这两种类型?
关于Hash类型,它可以实现对单键的快速查询,这就满足了时间序列数据的单键查询需求。我们可以把时间戳作为Hash集合的key,把记录的设备状态值作为Hash集合的value。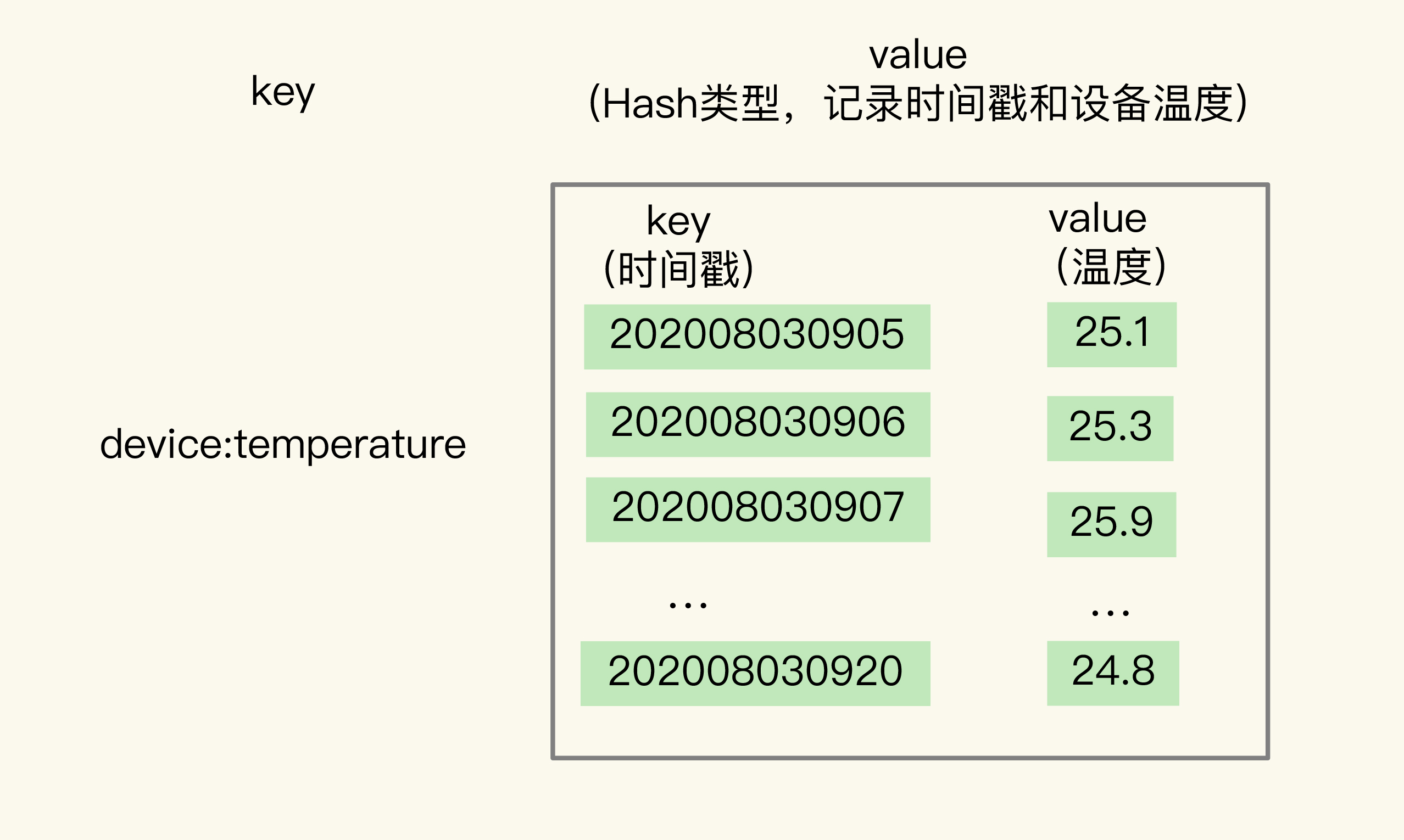
当我们想要查询某个时间点或者是多个时间点上的温度数据时&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











