






前言
JDK本身提供了很多方便的JVM性能调优监控工具,除了集成式的VisualVM和jConsole外,还有jps、jstack、jmap、jhat、jstat、hprof等小巧的工具,每一种工具都有其自身的特点,用户可以根据你需要检测的应用或者程序片段的状况,适当的选择相应的工具进行检测。接下来的两个专题分别会讲VisualVM的具体应用。
现实企业级Java开发中,有时候我们会碰到下面这些问题:
- OutOfMemoryError,内存不足
- 内存泄露
- 线程死锁
- 锁争用(Lock Contention)
- Java进程消耗CPU过高
这些问题在日常开发中可能被很多人忽视(比如有的人遇到上面的问题只是重启服务器或者调大内存,而不会深究问题根源),但能够理解并解决这些问题是Java程序员进阶的必备要求。
1. jps命令
1.1 语法
jps(Java Virtual Machine Process Status Tool)):用于输出当前用户JVM中运行的进程状态信息。当线上发现问题和故障时,能够利用jps快速定位到对应的Java进程ID
语法格式为:
jps [options] [hostid]
- [hostid] :如果不指定
hostid就默认为当前主机或服务器 - [options]:参数选项说明如下:
jps -q //不输出类名,jar包名和传入main方法的参数(只显示进程号)
jps -m //输出传入main方法的参数
jps -l //输出mian类和jar的全限名
jps -v // 输出传入JVM的参数
当然我们也可以使用Linux系统提供的查询进程状态信息,如下
ps -ef | grep java
我们也能快速获取 java服务的进程 id。
1.2 测试
我现在有一个DeadLock的Java程序正在本机运行。
jps -ml //输出类名和传入main方法的参数
测试结果:

2. jstack 命令
查看某个Java进程中所有线程的状态,打印线程堆栈信息,一般用来定位线程出现长时间停顿的原因,如发生死循环,死锁,请求外部资源长时间等待等!
2.1 语法
jstack [option] pid
- pid:线程id
- 参数选项说明如下:
jstack -l 2035629 //会打印出额外的锁信息,在发生死锁时可以用来观察锁持有情况
jstack -m 2035629 //不仅会输出Java堆栈信息,还会输出C/C++堆栈信息(比如Native方法)
jstack可以定位到线程堆栈,根据堆栈信息我们可以定位到具体代码,所以它在JVM性能调优中使用得非常多。
2.2 测试
题目:
找出某个Java进程中最耗费CPU的Java线程并定位堆栈信息,用到的命令有ps、top、printf、jstack、grep。
第一步: 首先找出Java进程ID,我们这里服务器上的应用程序名称为demo-02-0.0.1-SNAPSHOT.jar
- 使用jps命令查找
[root@VM-4-13-centos ~]# jps -l
2035629 demo-02-0.0.1-SNAPSHOT.jar //获取进程号2035629
2040881 sun.tools.jps.Jps
- 使用ps命令查找
[root@VM-4-13-centos ~]# ps -ef |grep demo-02-0.0.1-SNAPSHOT.jar
root 2035629 2018995 0 15:31 pts/1 00:00:19 java -jar demo-02-0.0.1-SNAPSHOT.jar
root 2041079 2025586 0 16:10 pts/2 00:00:00 grep --color=auto demo-02-0.0.1-SNAPSHOT.jar
两个命令都可以帮我们得到java的进程号2035629。
第二步:找出该进程内最耗费CPU的线程,利用 top 命令可以查出占 CPU 最高的线程 pid。
[root@VM-4-13-centos ~]# top -Hp 2191078

TIME列就是各个Java线程耗费的CPU时间,显然CPU时间最长的是ID为2035652的线程
第三步:占用率最高的线程 ID 为 2035652,将其转换为 16 进制形式 (因为 java native 线程以 16 进制形式输出)
[root@VM-4-13-centos ~]# printf "%x\n" 2035652
1f0fc4 // 得到2035652的十六进制值为b98,下面会用到。
第四步:利用 jstack 打印出 java 线程调用栈信息,用来输出进程2035629的堆栈信息,然后根据线程ID的十六进制值grep
[root@VM-4-13-centos ~]# jstack 2035629 | grep 1f0fc4 -A 50 --color
# 也可以放到文件中查看 jstack -l [进程 ID] >jstack.log
"Druid-ConnectionPool-Create-587003819" #16 daemon prio=5 os_prio=0 tid=0x00007f1140cd7000 nid=0x1f0fc4 waiting on condition [0x00007f11286da000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread.run(DruidDataSource.java:2720)
"mysql-cj-abandoned-connection-cleanup" #15 daemon prio=5 os_prio=0 tid=0x00007f11413b5800 nid=0x1f0fc3 in Object.wait() [0x00007f11289db000]
java.lang.Thread.State: TIMED_WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:144)
- locked <0x00000000c6a4f490> (a java.lang.ref.ReferenceQueue$Lock)
at com.mysql.jdbc.AbandonedConnectionCleanupThread.run(AbandonedConnectionCleanupThread.java:80)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
"container-0" #14 prio=5 os_prio=0 tid=0x00007f1141383800 nid=0x1f0fc2 waiting on condition [0x00007f1128cdc000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at org.apache.catalina.core.StandardServer.await(StandardServer.java:563)
at org.springframework.boot.web.embedded.tomcat.TomcatWebServer$1.run(TomcatWebServer.java:197)
"Catalina-utility-2" #13 prio=1 os_prio=0 tid=0x00007f114137b800 nid=0x1f0fc1 waiting on condition [0x00007f1129cc3000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000c5ea9518> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1093)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)
at java.lang.Thread.run(Thread.java:748)
"Catalina-utility-1" #12 prio=1 os_prio=0 tid=0x00007f1141370000 nid=0x1f0fc0 waiting on condition [0x00007f112a3c4000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000c5ea9518> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1088)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)
at java.lang.Thread.run(Thread.java:748)
"Service Thread" #7 daemon prio=9 os_prio=0 tid=0x00007f1140154000 nid=0x1f0fb7 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
可以看到CPU消耗在DruidDataSource这个类的连接数据库问题,于是就能很容易的定位到相关的代码了。
从个人的经验来看,一般以下问题:
- 一般是某个业务死循环没有出口,这种情况可以根据业务进行修复。
- 还有 C2 编译器执行编译时也会抢占 CPU,什么是 C2 编译器呢?当 Java 某一段代码执行次数超过 10000 次(默认)后,就会将该段代码从解释执行改为编译执行,也就是编译成机器码以提高速度。而这个 C2 编译器就是做这个的。如何解决呢?项目上线后,可以先通过压测工具进行预热,这样,等用户真正访问的时候,C2 编译器就不会干扰应用程序了。
- 如果是 GC 线程导致的,那么极有可能是 Full GC ,那么就要进行 GC 的优化。
3. jmap命令
jmap用来查看某个java进程堆内存使用情况,一般结合MAT工具使用。
3.1 语法
jmap [option] pid
- pid :进程id
- 参数选项说明如下:
jmap -permstat pid //打印进程的类加载器和类加载器加载的持久代对象信息
jmap -heap pid //查看进程堆内存使用情况,包括使用的GC算法、堆配置参数和各代中堆内存使用
jmap -histo[:live] pid //查看堆内存的对象数目,大小统计直方图,如果带上live则只统计活对象
jmap -dump:format=b,file=/usr/local/logs/gc/dump.hprof pid //以二进制输出档当前内存的堆情况,然后可以导入 MAT 等工具进行
3.2 测试
3.2.1 测试1
使用jmap -heap pid命令,查看进程堆内存使用情况:包括使用的GC算法、堆配置参数和各代中堆内存使用。如下图
[root@VM-4-13-centos ~]# jmap -heap 2080319
Attaching to process ID 2080319, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.191-b12
using thread-local object allocation.
Parallel GC with 2 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 981467136 (936.0MB)
NewSize = 20971520 (20.0MB)
MaxNewSize = 327155712 (312.0MB)
OldSize = 41943040 (40.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 249036800 (237.5MB)
used = 35691648 (34.0382080078125MB)
free = 213345152 (203.4617919921875MB)
14.331877055921053% used
From Space:
capacity = 5767168 (5.5MB)
used = 5414992 (5.1641387939453125MB)
free = 352176 (0.3358612060546875MB)
93.8934326171875% used
To Space:
capacity = 6815744 (6.5MB)
used = 0 (0.0MB)
free = 6815744 (6.5MB)
0.0% used
PS Old Generation
capacity = 40370176 (38.5MB)
used = 11752496 (11.208053588867188MB)
free = 28617680 (27.291946411132812MB)
29.111827503551137% used
16744 interned Strings occupying 1454336 bytes.
3.2.1 测试2
使用jmap -histo[:live] pid命令,查看堆内存中的对象数目、大小统计直方图,如果带上live则只统计活对象
[root@VM-4-13-centos ~]# jmap -histo:live 2080319 | head -n 10
num #instances #bytes class name
----------------------------------------------
1: 42959 4165800 [C
2: 16179 1423752 java.lang.reflect.Method
3: 32434 1037888 java.util.concurrent.ConcurrentHashMap$Node
4: 9365 1030896 java.lang.Class
5: 42906 1029744 java.lang.String
6: 4187 587552 [B
7: 7925 434240 [Ljava.lang.Object;
- 输出当前进程内存中所有对象实例数 (
instances) 和大小 (bytes), 如果某个业务对象实例数和大小存在异常情况,可能存在内存泄露或者业务设计方面存在不合理之处。 - class name是对象类型,说明如下:
B byte
C char
D double
F float
I int
J long
Z boolean
[ 数组,如[I表示int[]
[L+类名 其他对象
3.2.1 测试3
用jmap -dump命令把进程内存使用情况dump到文件中,再用jhat分析查看,需要注意的是 dump出来的文件还可以用MAT、VisualVM等工具查看。
[root@VM-4-13-centos ~]# jmap -dump:format=b,file=/download/project/dump.dat 2080319
Dumping heap to /download/project/dump.dat ...
Heap dump file created
然后使用jhat来对上面dump出来的内容进行分析
[root@VM-4-13-centos ~]# jhat -port 80 /download/project/dump.dat
Reading from /download/project/dump.dat...
Dump file created Sun Apr 03 21:26:57 CST 2022
Snapshot read, resolving...
Resolving 339846 objects...
Chasing references, expect 67 dots...................................................................
Eliminating duplicate references...................................................................
Snapshot resolved.
Started HTTP server on port 80
Server is ready.
注意如果Dump文件太大,可能需要加上-J-Xmx512m参数以指定最大堆内存,即jhat -J-Xmx512m -port 80 /download/project/dump.dat
。然后就可以在浏览器中输入主机地址:80查看了:
点击每一个蓝色的超链接,你都会看到其相关更具体的信息,而最后一项更是支持OQL(对象查询语言)。
注意:
如果你决定手动dump内存时,dump 操作占据一定 CPU 时间片、内存资源、磁盘资源等,因此会带来一定的负面影响。
所以生产环境一般会配置如下参数,让虚拟机在OOM异常出现之后自动生成dump文件
- Dump文件是
进程的内存镜像,可以把程序的执行状态通过调试器保存到dump文件中。 - 主要是用来在系统中
出现异常或崩溃的时候生成dump文件。 - 然后用
调试器进行调试,这样就可以把生产环境中的dump文件拷贝到自己的开发机上 - 通过MAT或其他分析工具,调试就可以找到程序出错的位置。
-XX:HeapDumpOnOutOfMemoryError //输出错误堆Dump信息
-XX:HeapDumpPath: //输出的路径
4. jstat命令
jstat是JVM统计监测工具,监测各个区内存和GC的情
4.1 语法
jstat [ generalOption | outputOptions vmid [interval[s|ms] [count]] ]
- vmid:是Java虚拟机ID,在Linux/Unix系统上一般就是进程ID。
- interval:是采样时间间隔。
- count:是采样数目。
4.2 测试
比如下面输出的是GC信息,采样时间间隔为250ms,采样数为6:
[root@VM-4-13-centos ~]# jstat -gc 2080319 250 6
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
6144.0 6144.0 0.0 320.0 307200.0 150195.2 49664.0 18371.1 54360.0 51227.6 7040.0 6475.4 21 0.127 3 0.218 0.345
6144.0 6144.0 0.0 320.0 307200.0 150195.2 49664.0 18371.1 54360.0 51227.6 7040.0 6475.4 21 0.127 3 0.218 0.345
6144.0 6144.0 0.0 320.0 307200.0 150195.2 49664.0 18371.1 54360.0 51227.6 7040.0 6475.4 21 0.127 3 0.218 0.345
6144.0 6144.0 0.0 320.0 307200.0 150195.2 49664.0 18371.1 54360.0 51227.6 7040.0 6475.4 21 0.127 3 0.218 0.345
6144.0 6144.0 0.0 320.0 307200.0 150195.2 49664.0 18371.1 54360.0 51227.6 7040.0 6475.4 21 0.127 3 0.218 0.345
6144.0 6144.0 0.0 320.0 307200.0 150195.2 49664.0 18371.1 54360.0 51227.6 7040.0 6475.4 21 0.127 3 0.218 0.345
要明白上面各列的意义,先看JVM堆内存布局:
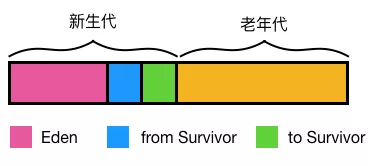
堆内存 = 年轻代 + 年老代 + 永久代(Java8移除,改为元空间)
年轻代 = Eden区 + 两个Survivor区(From和To)
现在来解释各列含义:
- S0C S1C S0U S1U:Survivor 0/1区容量(Capacity)和使用量(Used)。
- EC EU :Eden区容量和使用量
- OC OU:老年代容量和使用量
- MC MU:元空间容量和使用量
- YGC YGCT :年轻代GC次数和GC耗时
- FGC FGCT :Full GC次数和GC耗时
- GCT: GC总耗时
5. 如何使用MAT进行内存泄露分析
5.1 什么是MAT
MAT(Memory Analyzer Tool):是一个基于Eclipse的内存分析工具,是一个快速,功能丰富的Java Heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗,使用内存分析工具从众多的对象中进行分析,可以计算出内存中对象的实例数量,占用空间大小,引用关系等。看看是谁阻止了垃圾收集器的回收工作,并可以通过报表直观的查看到可能造成这种结果的对象。从而定位内存泄漏的原因。
什么时候会用到MAT?
- 系统发生OutOfMemoryError的时候,触发Full GC,但空间回收不了,引发内存泄漏。
- Java服务器系统异常,比如cpu异常,I/O异常,线程死锁等,都可能通过分析堆中的内存对象来定位原因。
5.2 下载并安装
MAT是eclipse中的一个插件,不过也提供了独立的版本,在IDEA风靡的今天,建议直接使用独立版本,官网下载地址 http://www.eclipse.org/mat/downloads.php ,根据操作系统版本下载最新的MAT,下载完成后直接解压就行。
5.3 配置MAT
有时候dump下来的.hprof文件太大,无法解析文件,必须手动配置才行,
我们找到MemoryAnalyzer.ini文件,该文件里面有个Xmx参数,该参数表示最大内存占用量,默认为1024m,根据堆转储文件大小修改该参数即可。
注意:不能分配超过本机可使用的内存。
5.4 如何获取Dump文件
- 如果想主动获取,可以使用jmap命令,对于部署到服务器上的程序可以采用这种方式,获取堆转储文件后scp到本地,然后本地分析。
jmap -dump:format=b,file=<dumpfile.hprof> <pid>
- 如果想在发生内存溢出的时候,自动dump,需要添加下面参数
-XX:+HeapDumpOnOutOfMemoryError
我们这里通过修改堆内存,自己编写一个代码模拟内存溢出的问题。
- JVM配置文件
-XX:+PrintGC //开启GC日志
-XX:+PrintGCDetails //打印GC详细日志
-XX:+PrintGCDateStamps //GC时间戳
-XX:+HeapDumpOnOutOfMemoryError //发生内存溢出的时候,自动dump
-Xms20m -Xmx20m //初始化堆为20m,最大堆内存20m
-XX:HeapDumpPath=C:\Users\DXH\Desktop\dump.hprof //输出路径
- java代码
public class OomDemo {
public static void main(String[] args) throws InterruptedException {
List list=new ArrayList();
for (int i = 0; i <10000000 ; i++) {
//Thread.sleep(1);
list.add(i);
}
System.out.println("任务完成");
}
}
5.5 使用MAT
5.5.1 打开MAT
打开MAT软件,点击左上角的打开文件,打开我们转换的 hprof文件 ,打开后的首页,里面是一些堆的基本概要信息,比如空间大小、类的数量、对象实例数量、类加载器等等
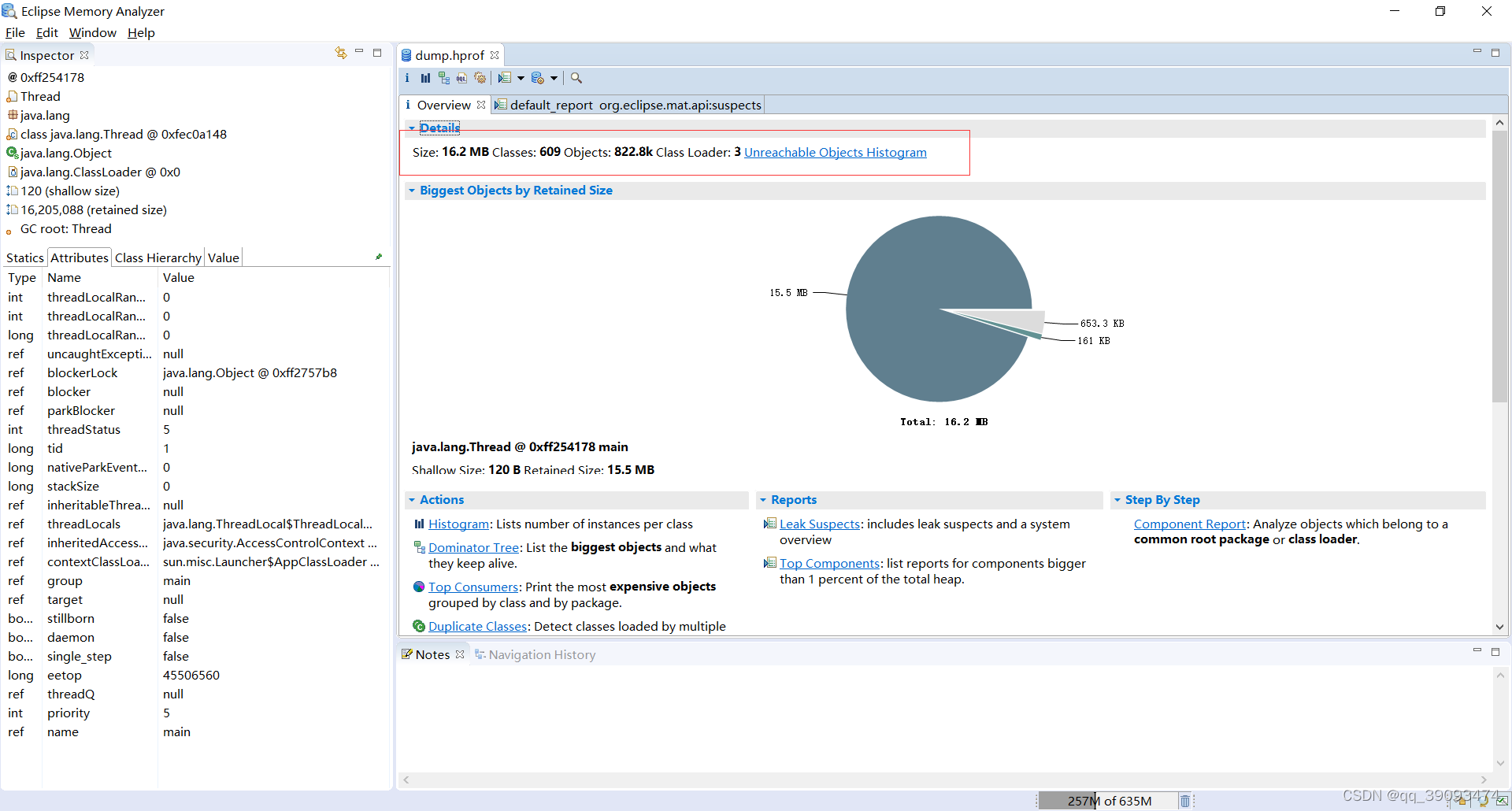
右侧的饼图显示当前快照中最大的对象。单击工具栏上的柱状图,可以查看当前堆的类信息,包括类的对象数量、浅堆 (Shallow heap)、深堆 (Retained Heap)。
Actions里面提供了多种分析维度
Histogram(常用):可以内存中对象,对象的个数以及大小。- Dominator Tree:可以列出那个线程,以及线程下面那些对象占用的空间。
- Top consumers:通过图形列出最大的object。
Leak Suspects(常用):通过MA自动分析泄漏的原因。
5.5.2 Histogram
这个功能主要是查看类和对象关系,对象和对象之间的关系,用来定位那些对象在Full GC之后还活着,那些对象占大部分内存。
- 点开Histogram ,可以看到它按类名将所有的实例对象列出来,点击表头(Class Name)可以排序,第一行输入正则表达式可以过滤筛选
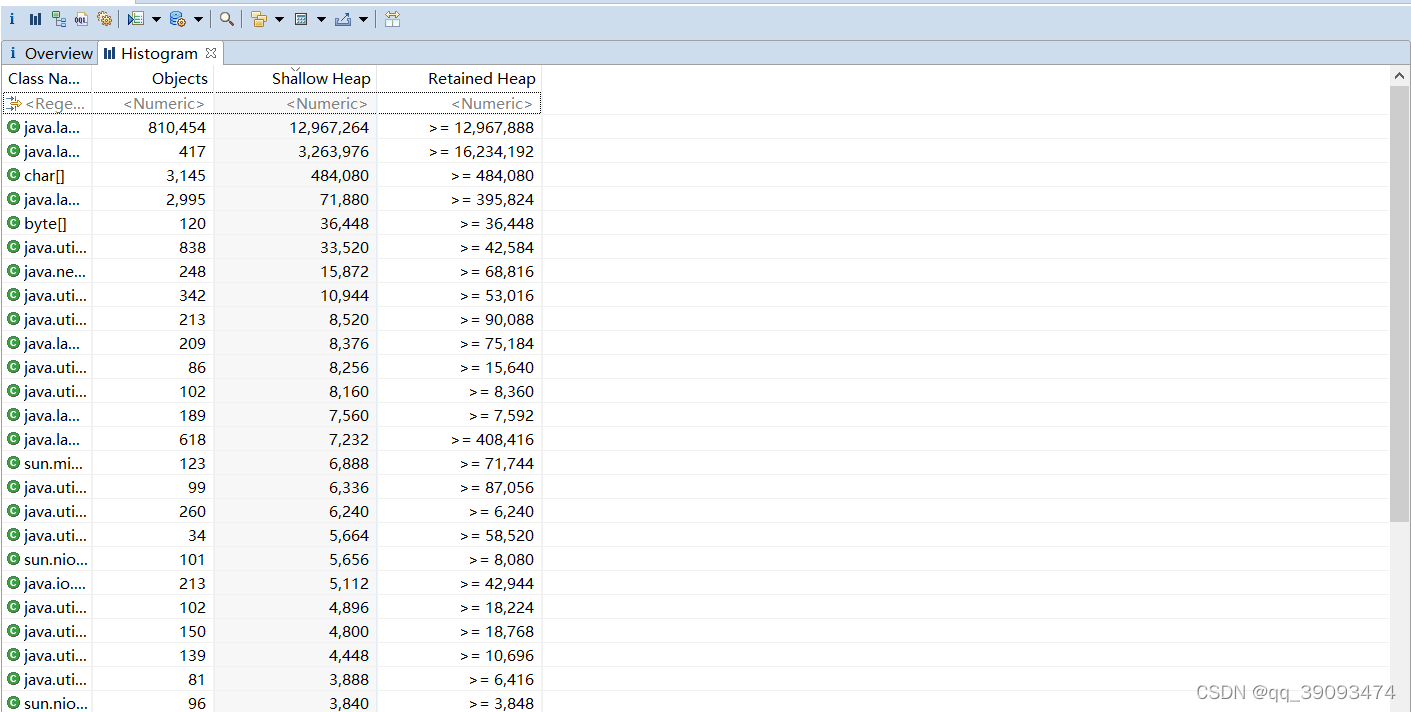
- Shallow Heap:就是对象本身占用内存的大小,不包含其引用的对象内存,实际分析中作用不大。常规对象(非数组)的ShallowSize由其成员变量的数量和类型决定。数组的shallow size有数组元素的类型(对象类型、基本类型)和数组长度决定。对象成员都是些引用,真正的内存都在堆上,看起来是一堆原生的byte[], char[], int[],对象本身的内存都很小。
- Retained Heap值的计算方式是将Retained Set(当该对象被回收时那些将被GC回收的对象集合)中的所有对象大小叠加。或者说,因为X被释放,导致其它所有被释放对象(包括被递归释放的)所占的heap大小。通俗来说就是shallow Heap的总和,也就是该对象被GC之后所能回收的内存大小。
Retained Heap例子:
一个ArrayList对象持有100个对象,每一个占用16 bytes,如果这个list对象被回收,那么其中100个对象也可以被回收,可以回收16*100 + X的内存,X代表ArrayList的shallow大小。
所以,RetainedHeap可以更精确的反映一个对象实际占用的大小。
- 选择一个Class,右键选择List objects > with incoming references

在新页面会显示通过这个class创建的对象信息
- with incoming references:将列出那些类引入该类
- with outgoing references:将列出该类引用了那些类
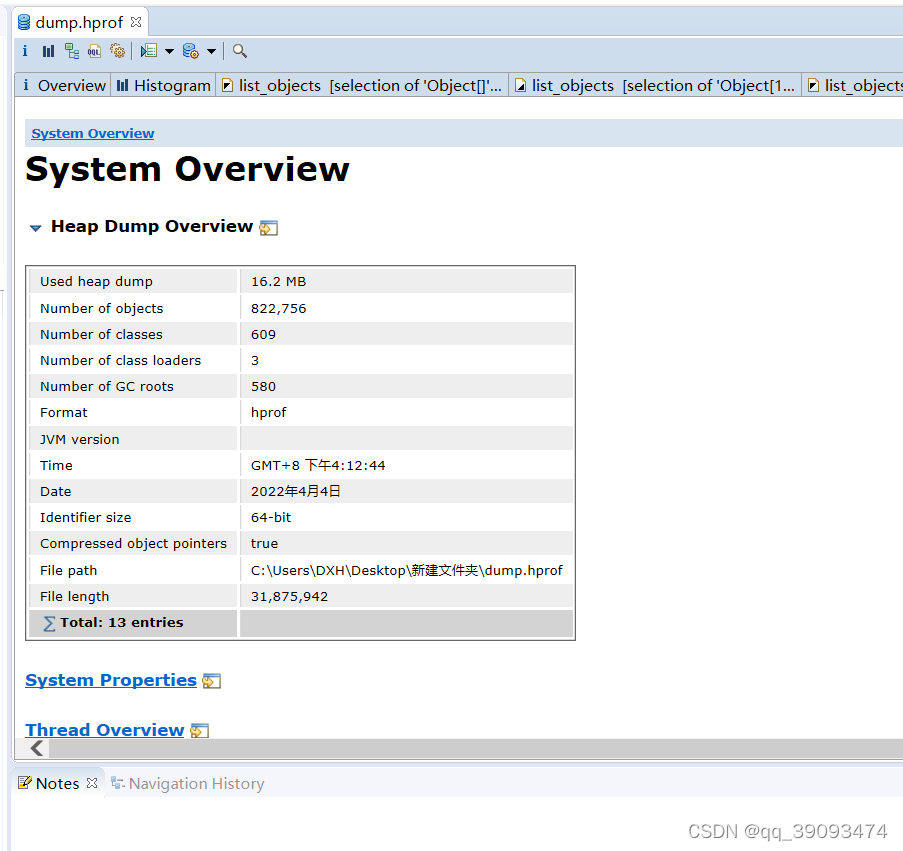
- 从工具栏中点开 Heap Dump Overview视图,可以看到一个全局的内存占用信息
- 选择一个对象,右键选择Path to GC Roots ,通常在排查内存泄漏的时候,我们会选择exclude all phantom/weak/soft etc.references。
意思是查看排除虚引用/弱引用/软引用等的引用链,因为被虚引用/弱引用/软引用的对象可以直接被GC给回收,我们要看的就是某个对象否还存在Strong 引用链(在导出HeapDump之前要手动出发GC来保证),如果有,则说明存在内存泄漏,然后再去排查具体引用。

这时会拿到GC Roots到该对象的路径,通过对象之间的引用,可以清楚的看出这个对象没有被回收的原因,然后再去定位问题。
假如说上面对象此时本来应该是被GC掉的,简单的办法就是将其中的某处置为null或者remove掉,使其到GC Root无路径可达,处于不可触及状态,垃圾回收器就可以回收了。
5.5.3 Dominator Tree
可以列出内存中存活的大对象列表,优点是有Percentage字段,可以看各种情况的百分比。
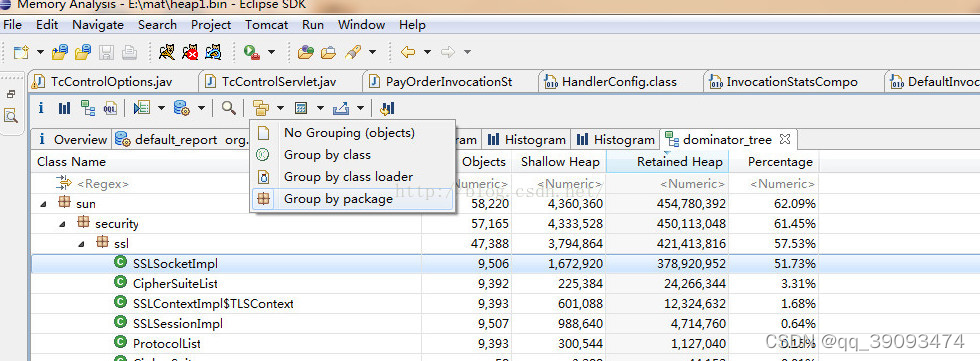
分组工具可以根据自己的需求分组查找,默认根据class分组,本文中是根据 package分组,发现存在大量的SSLSocketImpl类无法回收,这样会导致所有直接或间接引用到SSLSocketImpl的类都无法回收,图中可以看出虽然Shallow Heap大小只有1.6M,但Retained Heap大小却有378M。
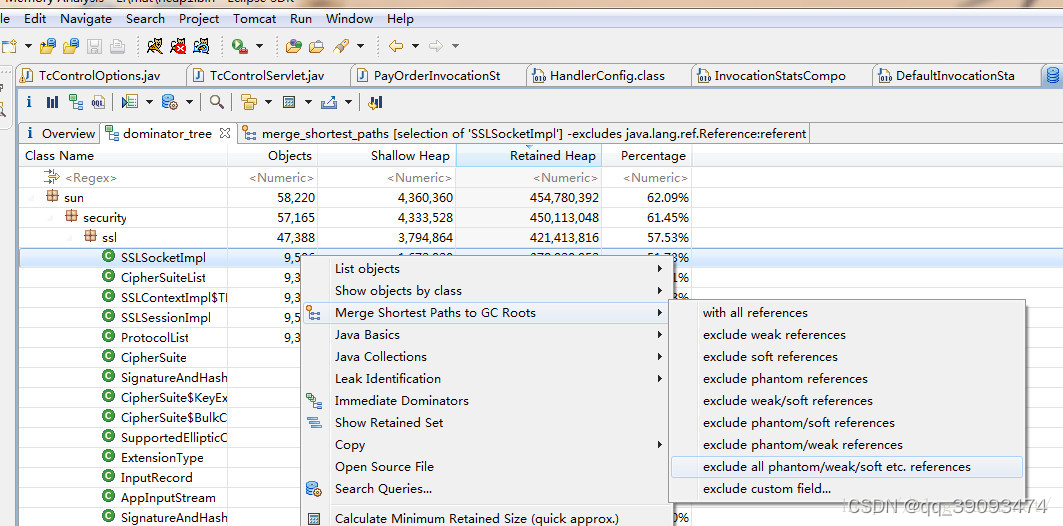

快速找出某个实例没被释放的原因,可以右健 Path to GC Roots–>exclude all phantom/weak/soft etc. references
它展示了对象间的引用关系,比如SSLSocketImpl @0xa124b208被PushNotificationManager 实例中的socket属性所引用。
5.5.4 Top consumers
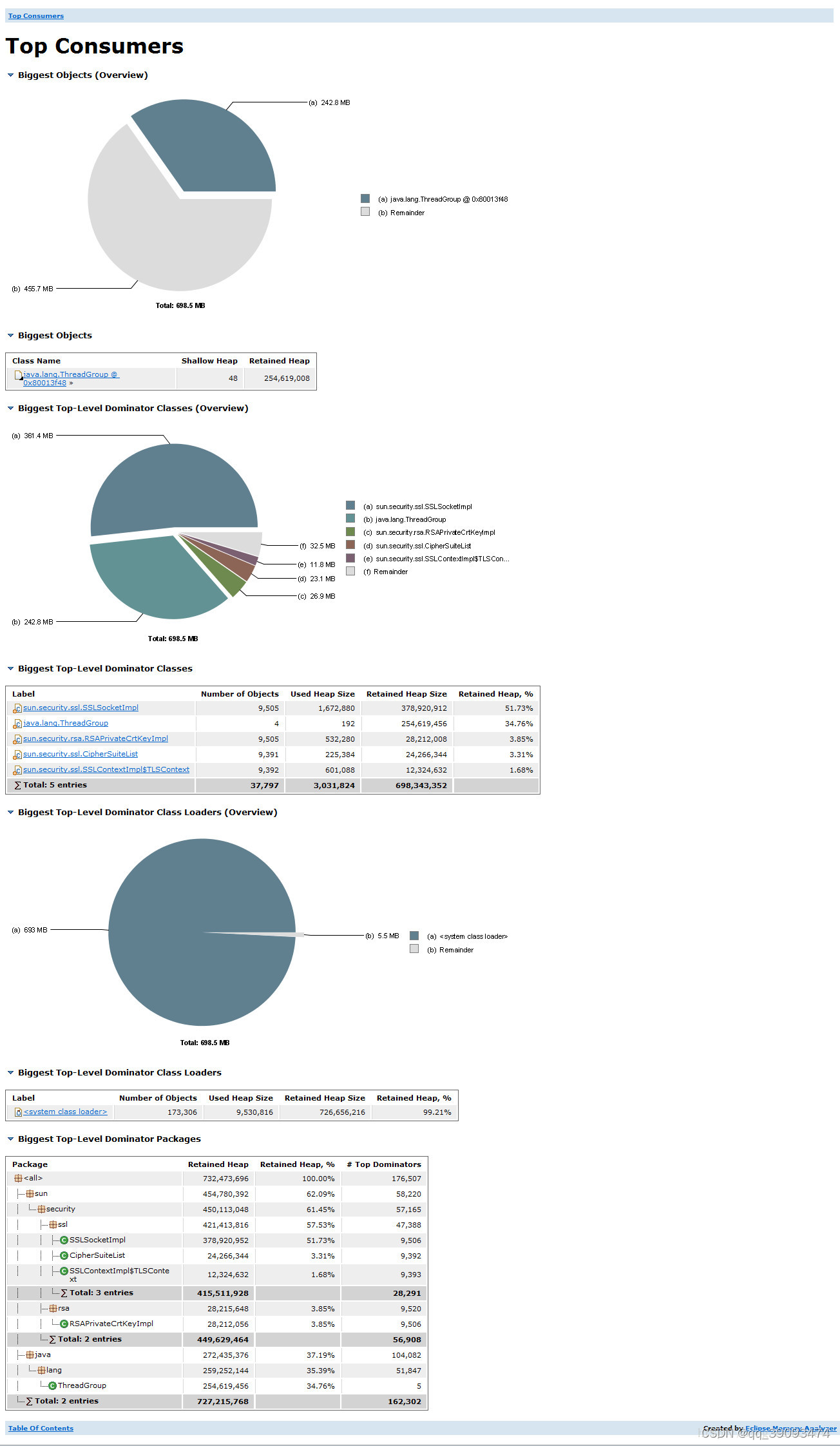
多种维度(包括 类大小、类加载器、包名)展示占用内存比较多的对象的分布,从而定位内存资源主要耗费在哪些地方!
5.5.5 Leak Suspects
Leak Suspects 界面提示可能存在内存的泄露。
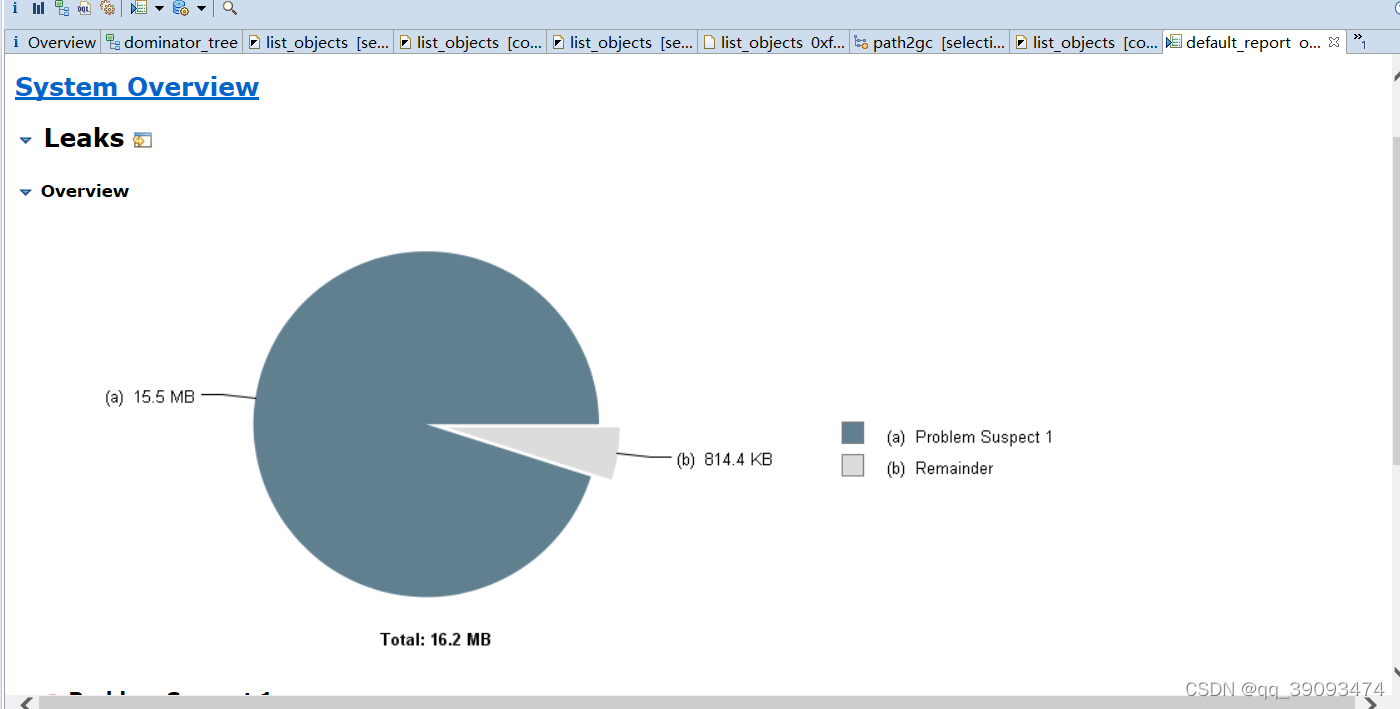
然后接着,是问题一的描述,列出了一些比较大的实例。
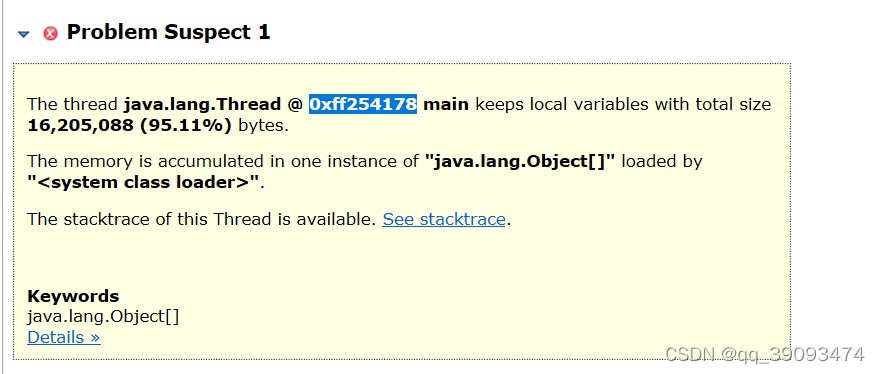
点击Details可以看到细节信息
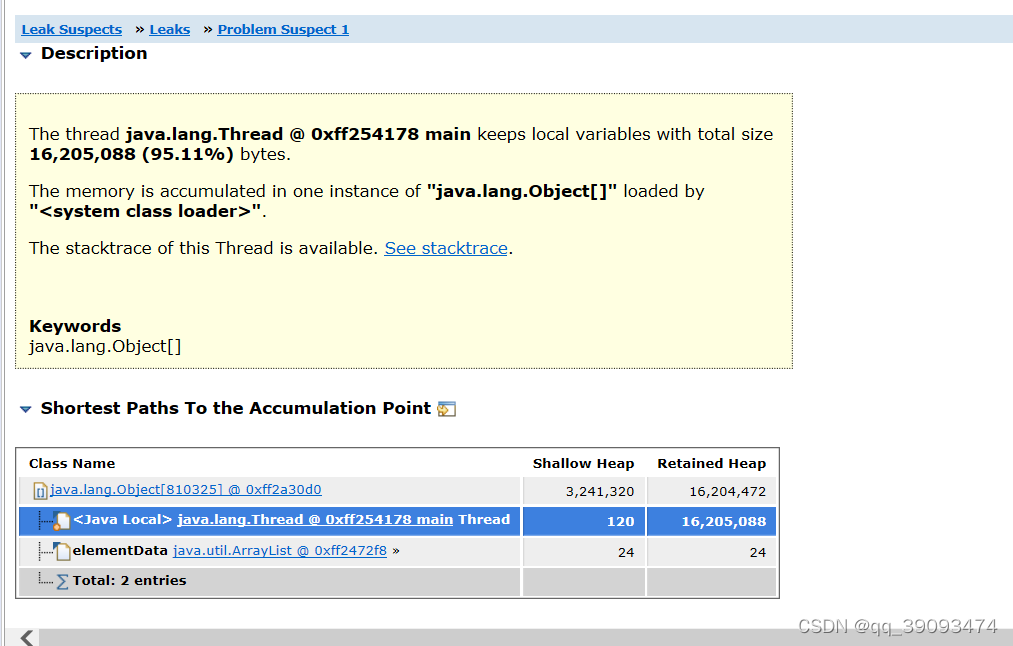
点开Details进入详情页面,在详情页面Shortest Paths To the Accumulation Point表示GC root到内存消耗聚集点的最短路径,如果某个内存消耗聚集点有路径到达GC root,则该内存消耗聚集点不会被当做垃圾被回收。
5.5.6 内存快照对比
为了更有效率的找出内存泄露的对象,一般会获取两个堆转储文件(先dump一个,隔段时间再dump一个),通过对比后的结果可以很方便定位。最后定位到问题所在

6. Java 线上问题排查思路与工具使用
6.1 Java 服务常见线上问题
所有 Java 服务的线上问题从系统表象来看归结起来总共有四方面:CPU、内存、磁盘、网络。例如 CPU 使用率峰值突然飚高、内存溢出 (泄露)、磁盘满了、网络流量异常、FullGC 等等问题。
基于这些现象我们可以将线上问题分成两大类: 系统异常、业务服务异常。
6.1.1 系统异常
常见的系统异常现象包括: CPU 占用率过高、CPU 上下文切换频率次数较高、磁盘满了、磁盘 I/O 过于频繁、网络流量异常 (连接数过多)、系统可用内存长期处于较低值 (导致 oom killer) 等等。
这些问题可以通过 top(cpu)、free(内存)、df(磁盘)、dstat(网络流量)、pstack、vmstat、strace(底层系统调用) 等工具获取系统异常现象数据。
此外,如果对系统以及应用进行排查后,均未发现异常现象的更笨原因,那么也有可能是外部基础设施如 IAAS 平台本身引发的问题。
6.1.2 业务服务异常
常见的业务服务异常现象包括: PV 量过高、服务调用耗时异常、线程死锁、多线程并发问题、频繁进行 Full GC、异常安全攻击扫描等。
6.2 问题定位
我们一般会采用排除法,从外部排查到内部排查的方式来定位线上服务问题。
- 首先我们要排除其他进程 (除主进程之外) 可能引起的故障问题;
- 然后排除业务应用可能引起的故障问题;
- 可以考虑是否为运营商或者云服务提供商所引起的故障。
6.2.1 系统异常排查流程
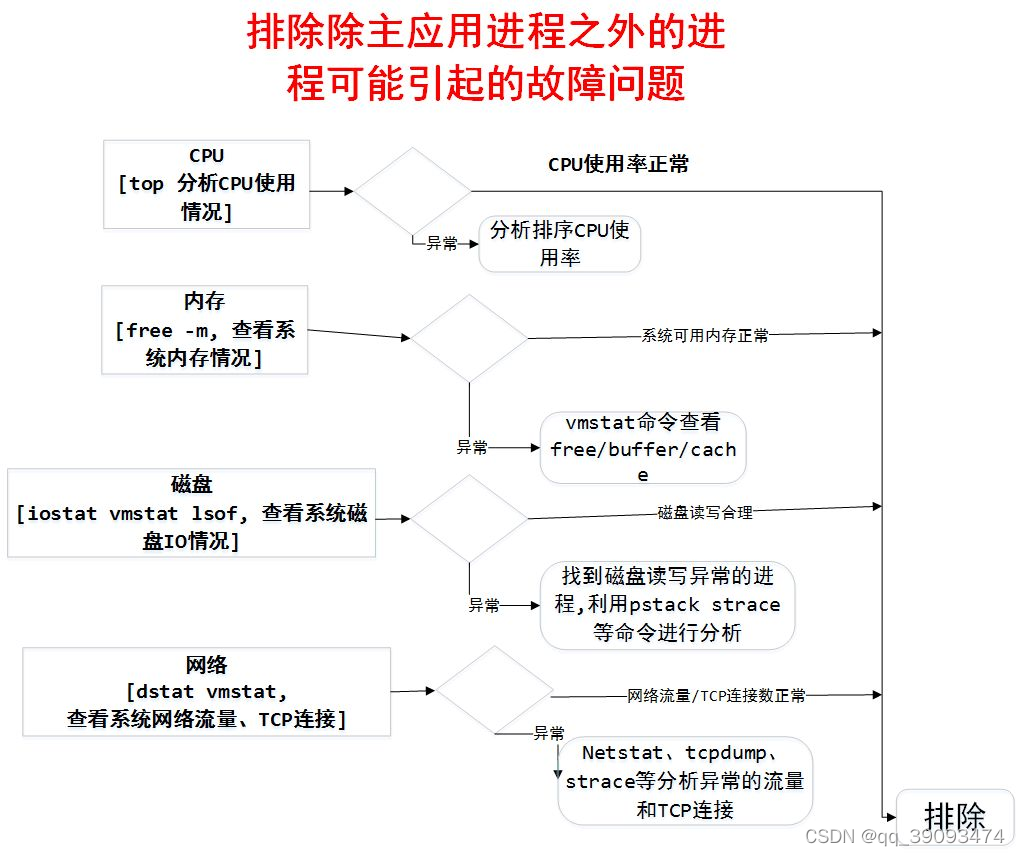
6.2.2 业务应用排查流程
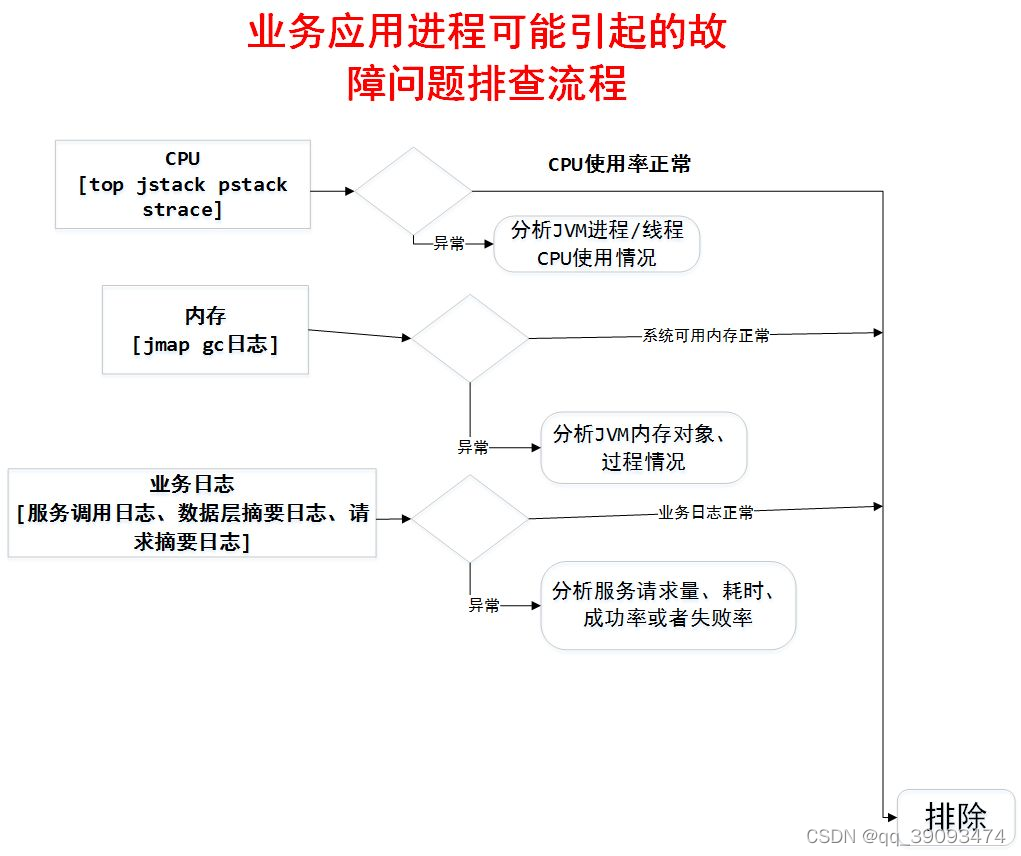
6.3 Linux 常用的性能分析工具
Linux 常用的性能分析工具使用包括 : top(cpu)、free(内存)、df(磁盘)、dstat(网络流量)、pstack、vmstat、strace(底层系统调用) 等。
6.3.1 CPU
CPU 是系统重要的监控指标,能够分析系统的整体运行状况。监控指标一般包括运行队列、CPU 使用率和上下文切换等。
top 命令是 Linux 下常用的 CPU 性能分析工具 , 能够实时显示系统中各个进程的资源占用状况 , 常用于服务端性能分析。

PID : 进程 id
USER : 进程所有者
PR : 进程优先级
NI : nice 值。负值表示高优先级,正值表示低优先级
VIRT : 进程使用的虚拟内存总量,单位 kb。VIRT=SWAP+RES
RES : 进程使用的、未被换出的物理内存大小,单位 kb。RES=CODE+DATA
SHR : 共享内存大小,单位 kb
S : 进程状态。D= 不可中断的睡眠状态 R= 运行 S= 睡眠 T= 跟踪 / 停止 Z= 僵尸进程
%CPU : 上次更新到现在的 CPU 时间占用百分比
%MEM : 进程使用的物理内存百分比
TIME+ : 进程使用的 CPU 时间总计,单位 1/100 秒
COMMAND : 进程名称
如果需要更详细的工具:点击这里
6.3.2 内存
内存是排查线上问题的重要参考依据,内存问题很多时候是引起 CPU 使用率较高的见解因素。
系统内存:free 是显示的当前内存的使用 ,-m 的意思是 M 字节来显示内容。

部分参数说明:
total 内存总数: 3790M
used 已经使用的内存数: 1880M
free 空闲的内存数: 118M
shared 当前已经废弃不用 , 总是 0
buffers Buffer 缓存内存数: 1792M
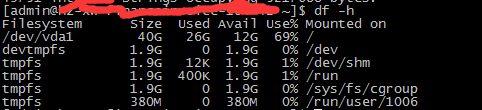
6.3.3 磁盘
df -h
du -m /path
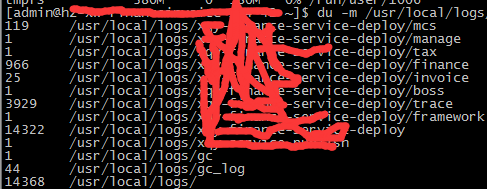
6.3.4 网络
dstat 命令可以集成了 vmstat、iostat、netstat 等等工具能完成的任务。
dstat -c cpu 情况
-d 磁盘读写
-n 网络状况
-l 显示系统负载
-m 显示形同内存状况
-p 显示系统进程信息
-r 显示系统 IO 情况
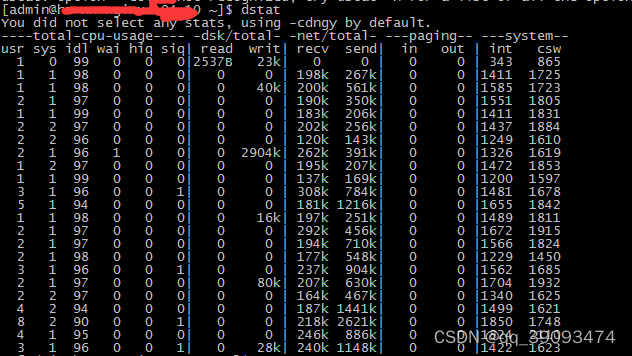
6.3.5 JVM 定位问题工具
就是我们本文前面说的jps,jmap等命令。
6.3.6 其他
vmstat:
vmstat 2 10 -t
vmstat 是 Virtual Meomory Statistics(虚拟内存统计)的缩写 , 是实时系统监控工具。该命令通过使用 knlist 子程序和 /dev/kmen 伪设备驱动器访问这些数据,输出信息直接打印在屏幕。
使用 vmstat 2 10 -t 命令,查看 io 的情况 (第一个参数是采样的时间间隔数单位是秒,第二个参数是采样的次数)。
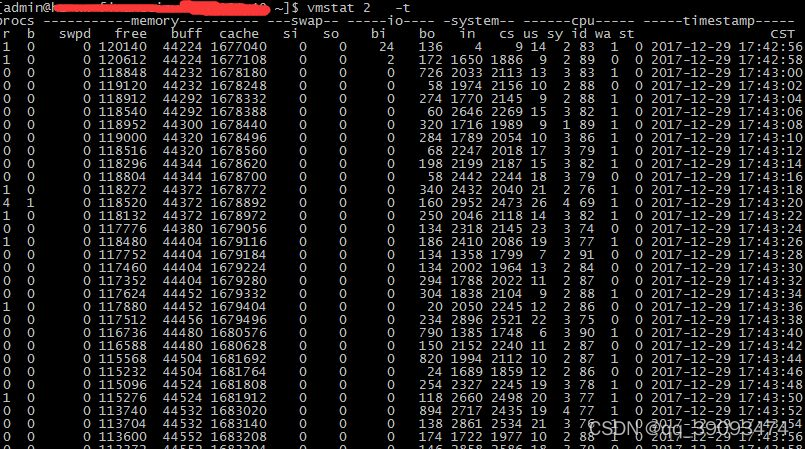
r 表示运行队列 (就是说多少个进程真的分配到 CPU),b 表示阻塞的进程。
swpd 虚拟内存已使用的大小,如果大于 0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共 8G,剩余 3415M。
buff Linux/Unix 系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用 300 多 M
cache 文件缓存
si 列表示由磁盘调入内存,也就是内存进入内存交换区的数量;
so 列表示由内存调入磁盘,也就是内存交换区进入内存的数量
一般情况下,si、so 的值都为 0,如果 si、so 的值长期不为 0,则表示系统内存不足,需要考虑是否增加系统内存。
bi 从块设备读入数据的总量(读磁盘)(每秒 kb)
bo 块设备写入数据的总量(写磁盘)(每秒 kb)
随机磁盘读写的时候,这两个值越大 ((超出 1024k),能看到 cpu 在 IO 等待的值也会越大
这里设置的 bi+bo 参考值为 1000,如果超过 1000,而且 wa 值比较大,则表示系统磁盘 IO 性能瓶颈。
in 每秒 CPU 的中断次数,包括时间中断
cs(上下文切换 Context Switch)
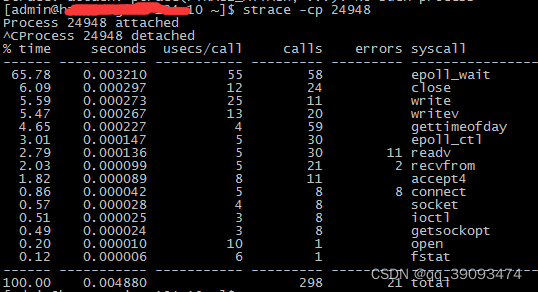
strace:strace 常用来跟踪进程执行时的系统调用和所接收的信号。
strace -cp tid
strace -T -p tid
-T 显示每一调用所耗的时间 .
-p pid 跟踪指定的进程 pid.
-v 输出所有的系统调用 . 一些调用关于环境变量 , 状态 , 输入输出等调用由于使用频繁 , 默认不输出 .
-V 输出 strace 的版本信息 .















 2014
2014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









