






1. 集成 SpringBoot
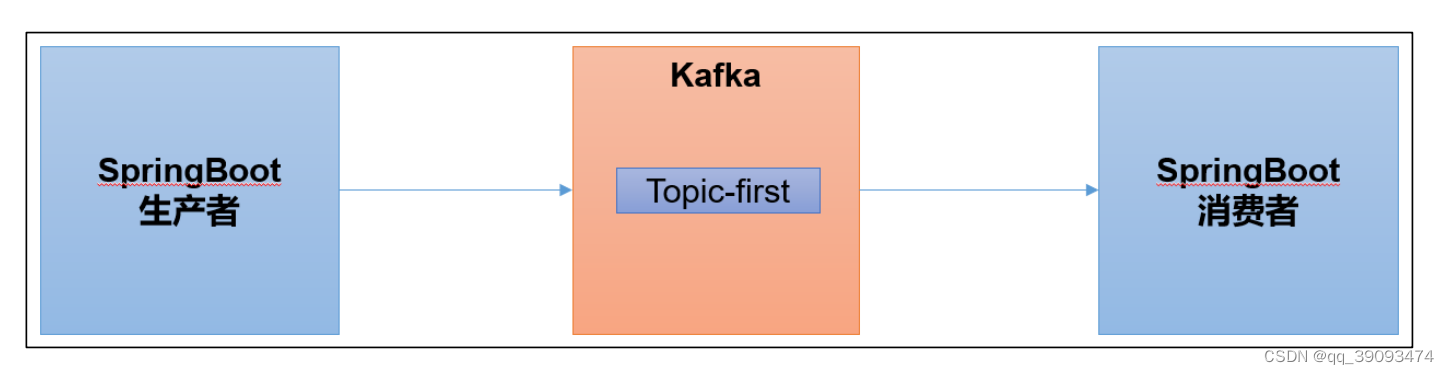
SpringBoot 是一个在 JavaEE 开发中非常常用的组件。可以用于 Kafka 的生产者,也可以用于 Kafka 的消费者。
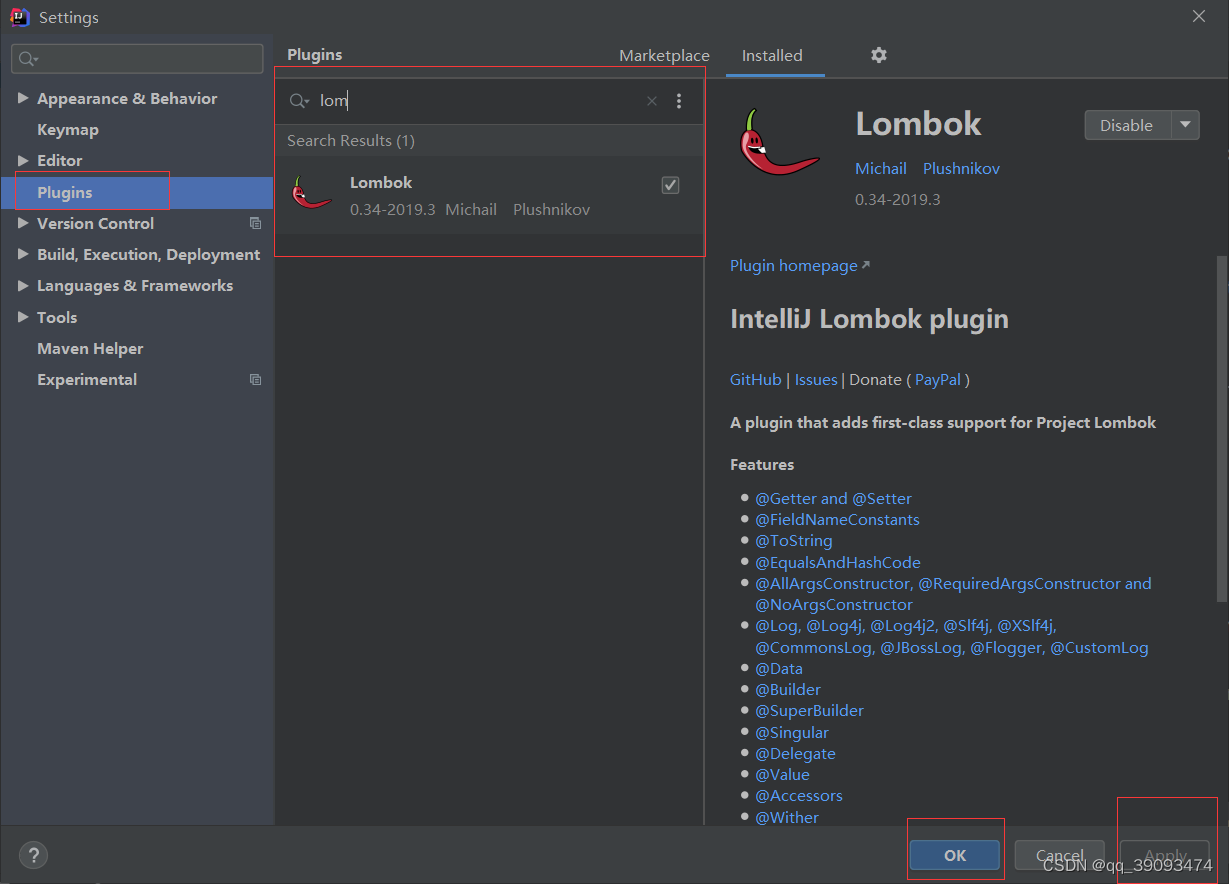
1.1 在 IDEA 中安装 lombok 插件
在 Plugins 下搜索 lombok 然后在线安装即可,安装后注意重启
1.2 SpringBoot 环境准备
-
创建一个 Spring Initializr
注意:有时候 SpringBoot 官方脚手架不稳定,我们切换国内地址 https://start.aliyun.com -
项目名称 springboot
-
添加项目依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
1.3 SpringBoot 生产者
- 修改 SpringBoot 核心配置文件 application.propeties, 添加生产者相关信息
# 应用名称
spring.application.name=springboot_kafka
# 指定 kafka 的地址
spring.kafka.bootstrap-servers=124.221.5.51:9092
#指定 key 和 value 的序列化器
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
- 创建 controller 从浏览器接收数据, 并写入指定的 topic
@RestController
public class ProducerController {
// Kafka 模板用来向 kafka 发送数据
@Autowired
KafkaTemplate<String, String> kafkaTemplate;
@RequestMapping("/producer")
public String data(String msg){
kafkaTemplate.send("first",msg);
return "success";
}
}
- 在浏览器中给/producer接口发送数据:http://localhost:8080/producer?msg=hello并启动Kafka消费者查看
1.4 SpringBoot 消费者
- 修改 SpringBoot 核心配置文件 application.propeties
# =========消费者配置开始=========
# 指定 kafka 的地址
spring.kafka.bootstrapservers=124.221.5.51:9092
# 指定 key 和 value 的反序列化器
spring.kafka.consumer.keydeserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.valuedeserializer=org.apache.kafka.common.serialization.StringDeserializer
#指定消费者组的 group_id
spring.kafka.consumer.group-id=test
# =========消费者配置结束=========
- 创建类消费 Kafka 中指定 topic 的数据
@Configuration
public class ConsumerController {
// 指定要监听的 topic
@KafkaListener(topics = "first")
public void consumeTopic(String msg) { // 参数: 收到的 value
System.out.println("收到的信息: " + msg);
}
}
- 向 first 主题发送数据也可以使用前面写的生产者生产数据测试。
2. Kafka调优之硬件配置选择
2.1 场景说明
100 万活跃用户,每人每天 100 条日志,每天总共的日志条数是 100 万 * 100 条 = 1 亿条。
1 亿/24 小时/60 分/60 秒 = 1150 条/每秒钟。
每条日志大小:0.5k - 2k(取 1k)。
1150 条/每秒钟 * 1k ≈ 1m/s 。
高峰期每秒钟:1150 条 * 20 倍 = 23000 条。
每秒多少数据量:20MB/s。
2.2 服务器台数选择
服务器台数= 2 * (生产者峰值生产速率 * 副本 / 100) + 1
= 2 * (20m/s * 2 / 100) + 1
= 3 台
建议 3 台服务器。
2.3 磁盘选择
kafka 底层主要是顺序写,固态硬盘和机械硬盘的顺序写速度差不多。
建议选择普通的机械硬盘。
每天总数据量:1 亿条 * 1k ≈ 100g
100g * 副本 2 * 保存时间 3 天 / 0.7 ≈ 1T
建议三台服务器硬盘总大小,大于等于 1T。
2.4 内存选择
Kafka 内存组成:
堆内存+页缓存
- Kafka 堆内存建议每个节点:10g ~ 15g
在 kafka-server-start.sh 中修改
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx10G -Xms10G"
fi
查看 Kafka 进程号
[root@VM-4-13-centos ~]# jps
1469462 Kafka
1864279 Jps
7935 QuorumPeerMain
根据 Kafka 进程号,查看 Kafka 的 GC 情况。jstat -gc 1469462 1s 10
[root@VM-4-13-centos ~]# jstat -gc 1469462 1s 10
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
0.0 1024.0 0.0 1024.0 659456.0 184320.0 388096.0 166939.2 54684.0 48915.7 7068.0 6389.0 114 25064.821 0 0.000 25064.821
0.0 1024.0 0.0 1024.0 659456.0 184320.0 388096.0 166939.2 54684.0 48915.7 7068.0 6389.0 114 25064.821 0 0.000 25064.821
0.0 1024.0 0.0 1024.0 659456.0 184320.0 388096.0 166939.2 54684.0 48915.7 7068.0 6389.0 114 25064.821 0 0.000 25064.821
0.0 1024.0 0.0 1024.0 659456.0 185344.0 388096.0 166939.2 54684.0 48915.7 7068.0 6389.0 114 25064.821 0 0.000 25064.821
0.0 1024.0 0.0 1024.0 659456.0 185344.0 388096.0 166939.2 54684.0 48915.7 7068.0 6389.0 114 25064.821 0 0.000 25064.821
0.0 1024.0 0.0 1024.0 659456.0 185344.0 388096.0 166939.2 54684.0 48915.7 7068.0 6389.0 114 25064.821 0 0.000 25064.821
0.0 1024.0 0.0 1024.0 659456.0 185344.0 388096.0 166939.2 54684.0 48915.7 7068.0 6389.0 114 25064.821 0 0.000 25064.821
0.0 1024.0 0.0 1024.0 659456.0 185344.0 388096.0 166939.2 54684.0 48915.7 7068.0 6389.0 114 25064.821 0 0.000 25064.821
0.0 1024.0 0.0 1024.0 659456.0 185344.0 388096.0 166939.2 54684.0 48915.7 7068.0 6389.0 114 25064.821 0 0.000 25064.821
0.0 1024.0 0.0 1024.0 659456.0 185344.0 388096.0 166939.2 54684.0 48915.7 7068.0 6389.0 114 25064.821 0 0.000 25064.821
参数说明:
- S0C:第一个幸存区的大小; S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小; S1U:第二个幸存区的使用大小
- EC:伊甸园区的大小; EU:伊甸园区的使用大小
- OC:老年代大小; OU:老年代使用大小
- MC:方法区大小; MU:方法区使用大小
- CCSC:压缩类空间大小; CCSU:压缩类空间使用大小
- YGC:年轻代垃圾回收次数; YGCT:年轻代垃圾回收消耗时间
- FGC:老年代垃圾回收次数; FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
- 根据 Kafka 进程号,查看 Kafka 的堆内存。
jmap -heap 1469462
[root@VM-4-13-centos ~]# jmap -heap 1469462
Attaching to process ID 1469462, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.191-b12
using thread-local object allocation.
Garbage-First (G1) GC with 2 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 1073741824 (1024.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 643825664 (614.0MB)
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 1048576 (1.0MB)
Heap Usage:
G1 Heap:
regions = 1024
capacity = 1073741824 (1024.0MB)
used = 372272336 (355.0265655517578MB)
free = 701469488 (668.9734344482422MB)
34.67056304216385% used
G1 Young Generation:
Eden Space:
regions = 191
capacity = 675282944 (644.0MB)
used = 200278016 (191.0MB)
free = 475004928 (453.0MB)
29.658385093167702% used
Survivor Space:
regions = 1
capacity = 1048576 (1.0MB)
used = 1048576 (1.0MB)
free = 0 (0.0MB)
100.0% used
G1 Old Generation:
regions = 165
capacity = 397410304 (379.0MB)
used = 170945744 (163.0265655517578MB)
free = 226464560 (215.9734344482422MB)
43.01492494769335% used
15180 interned Strings occupying 1727360 bytes.
- 页缓存:页缓存是 Linux 系统服务器的内存。我们只需要保证 1 个 segment(1g)中25%的数据在内存中就好。
每个节点页缓存大小 =(分区数 * 1g * 25%)/ 节点数。
例如 10 个分区,页缓存大小=(10 * 1g * 25%)/ 3 ≈ 1g
建议服务器内存大于等于 11G。
2.5 CPU 选择
- num.io.threads = 8 负责写磁盘的线程数,整个参数值要占总核数的 50%。
- num.replica.fetchers = 1 副本拉取线程数,这个参数占总核数的 50%的 1/3。
- num.network.threads = 3 数据传输线程数,这个参数占总核数的 50%的 2/3。
建议 32 个 cpu core。
2.6 网络选择
网络带宽 = 峰值吞吐量 ≈ 20MB/s 选择千兆网卡即可。
100Mbps 单位是 bit;10M/s 单位是 byte ; 1byte = 8bit,100Mbps/8 = 12.5M/s。
一般百兆的网卡(100Mbps )、千兆的网卡(1000Mbps)、万兆的网卡(10000Mbps)。
3. Kafka调优之Kafka 生产者
3.1 Kafka 生产者核心参数配置
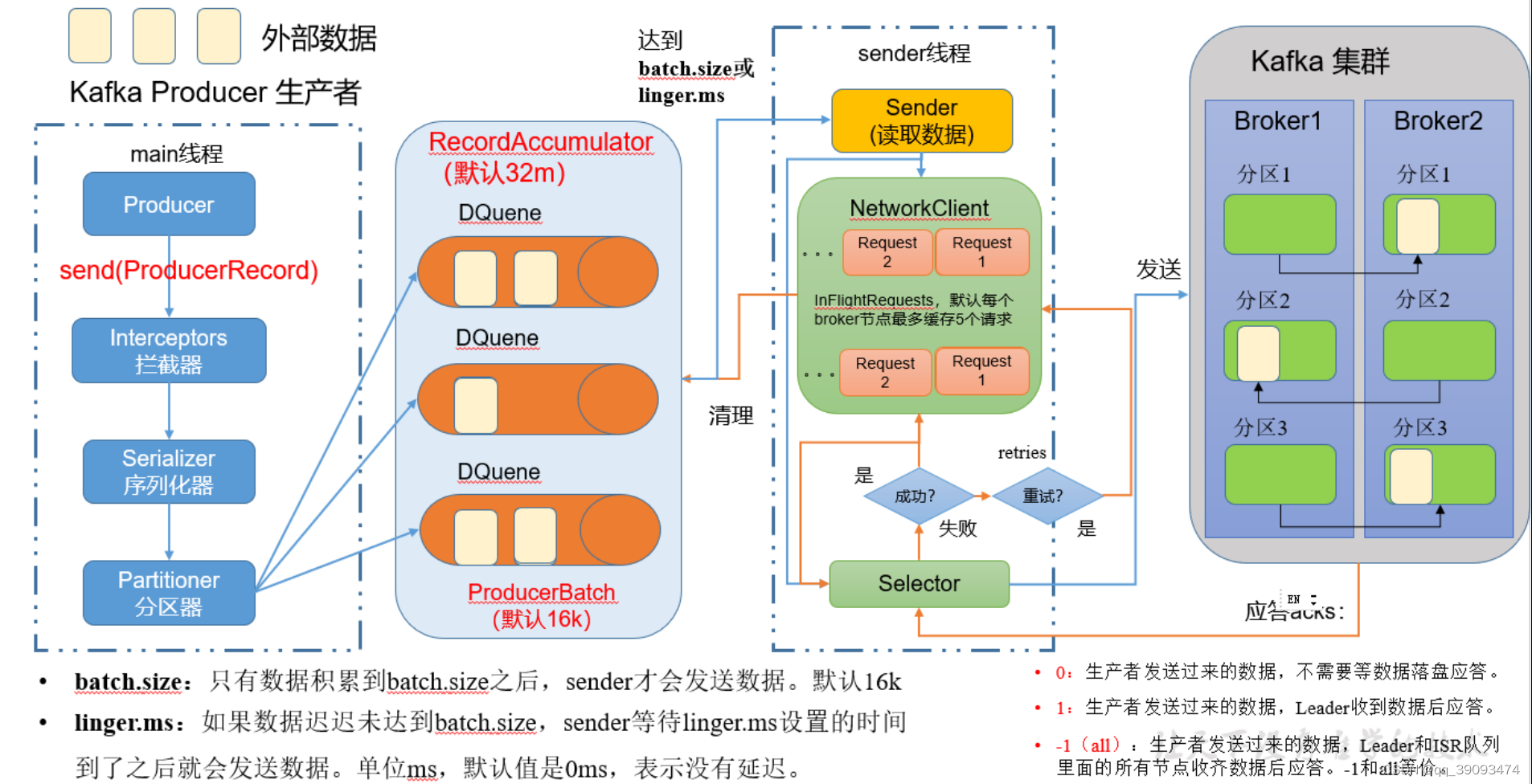
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 生产者连接集群所需的broker地址清单。例如hadoop102:9092,hadoop103:9092,hadoop104:9092可以设置1个或者多个,中间用逗号隔开。注意这里并非需要所有的broker地址,因为生产者从给定的broker里查找到其他broker信息 |
| key.serializer 和 value.serializer | 指定发送消息的 key 和 value 的序列化类型。一定要写全类名 |
| buffer.memory | RecordAccumulator 缓冲区总大小,默认32m |
| batch.size | 缓冲区一批数据最大值,默认16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。 |
| linger.ms | 如果数据迟迟未达到 batch.size,sender 等待 linger.time之后就会发送数据。单位 ms,默认值是 0ms,表示没有延迟。生产环境建议该值大小为 5-100ms 之间。 |
| acks | 0:生产者发送过来的数据,不需要等数据落盘应答。 1:生产者发送过来的数据,Leader 收到数据后应答。 -1(all):生产者发送过来的数据,Leader+和 isr 队列里面的所有节点收齐数据后应答。 默认值是-1,-1 和 all 是等价的 |
| max.in.flight.requests.per.connection | 允许最多没有返回 ack 的次数,默认为 5,开启幂等性要保证该值是 1-5 的数字 |
| retries | 当消息发送出现错误的时候,系统会重发消息。retrie表示重试次数。默认是 int 最大值,2147483647。如果设置了重试,还想保证消息的有序性,需要设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1 否则在重试此失败消息的时候,其他的消息可能发送成功了 |
| retry.backoff.ms | 两次重试之间的时间间隔,默认是 100ms |
| enable.idempotence | 是否开启幂等性,默认 true,开启幂等性。 |
| compression.type | 生产者发送的所有数据的压缩方式。默认是 none,就是不压缩。支持压缩类型:none、gzip、snappy、lz4 和 zstd。 |
4. Kafka调优之Kafka Broker
4.1 Broker 核心参数配置
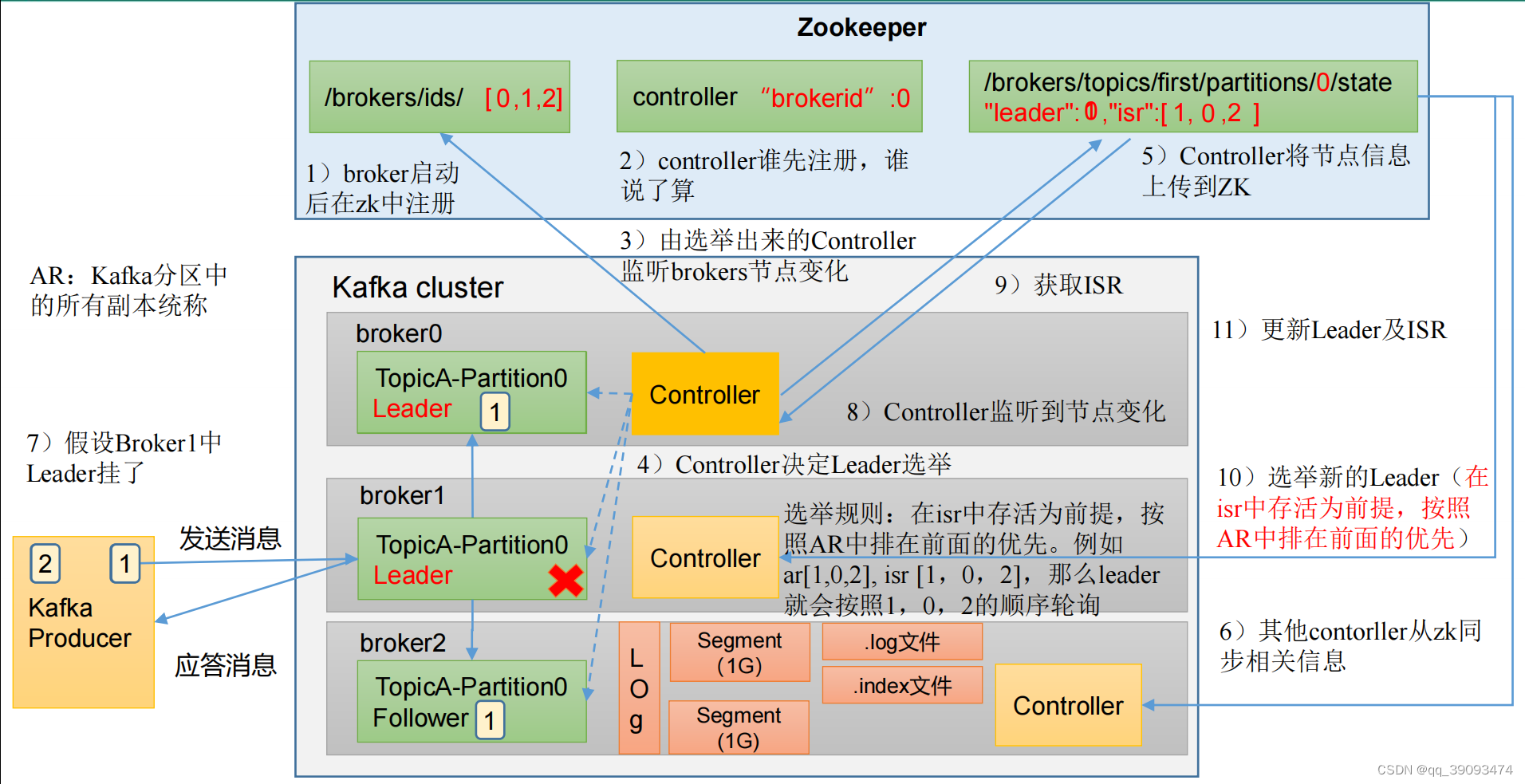
- broker启动后在zk中注册。所以要先启动zk集群。
- zk集群中controller谁先注册,谁说了算。
- 由选举出来的Controller监听brokers节点变化。
- Controller决定Leader的选举
- Controller将节点信息上传到zk
- 其他Controller从zk同步相关信息
- 假设Broker1中Leader挂了.
- Controller监听到节点变化。
- 从zk节点获取ISR信息。
- 选举新的Leader(在ISR中存活为前提,按照AR中排在前面的优先)。
- 更新Leader及ISR。
这里解释一些专业名字:
- ISR :Leader保持同步的Follower+Leader集合(leader:0,isr:0,1,2)
- AR:Kafka分区中的所有副本统称
- 选举规则:在ISR中存活为前提,按照AR中排在前面的优先。例如ar[1,0,2],isr[1,0,2]。那么Leader就会按照1,0,2的顺序进行轮询。
| 参数名称 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值,默认 30s。 |
| auto.leader.rebalance.enable | 默认是 true。 自动 Leader Partition 平衡。建议关闭 |
| leader.imbalance.per.broker.percentage | 默认是 10%。每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。 |
| log.segment.bytes | Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分 成块的大小,默认值 1G。 |
| log.index.interval.bytes | 默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。 |
| log.retention.hours | Kafka 中数据保存的时间,默认 7 天。 |
| log.retention.minutes | Kafka 中数据保存的时间,分钟级别,默认关闭。 |
| log.retention.ms | Kafka 中数据保存的时间,毫秒级别,默认关闭。 |
| log.retention.check.interval.ms | 检查数据是否保存超时的间隔,默认是 5 分钟。 |
| log.retention.bytes | 默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的 segment。 |
| log.cleanup.policy | 默认是 delete,表示所有数据启用删除策略;如果设置值为 compact,表示所有数据启用压缩策略。 |
| num.io.threads | 默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50%。 |
| num.replica.fetchers | 副本拉取线程数,这个参数占总核数的 50%的 1/3 |
| num.network.threads | 默认是 3。数据传输线程数,这个参数占总核数的50%的 2/3 。 |
| log.flush.interval.messages | 强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。 |
| log.flush.interval.ms | 每隔多久,刷数据到磁盘,默认是 null。一般不建议修改,交给系统自己管理。 |
4.2 自动创建主题
如果 broker 端配置参数 auto.create.topics.enable 设置为 true(默认值是 true),那么当生产者向一个未创建的主题发送消息时,会自动创建一个分区数为 num.partitions(默认值为
1)、副本因子为 default.replication.factor(默认值为 1)的主题。除此之外,当一个消费者开始从未知主题中读取消息时,或者当任意一个客户端向未知主题发送元数据请求时,都会自动创建一个相应主题。这种创建主题的方式是非预期的,增加了主题管理和维护的难度。
生产环境建议将该参数设置为 false。
- 向一个没有提前创建 five 主题发送数据
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic five
>hello world
- 查看 five 主题的详情
bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --describe --topic five
5. Kafka调优之Kafka 消费者
5.1 Kafka 消费者核心参数配置
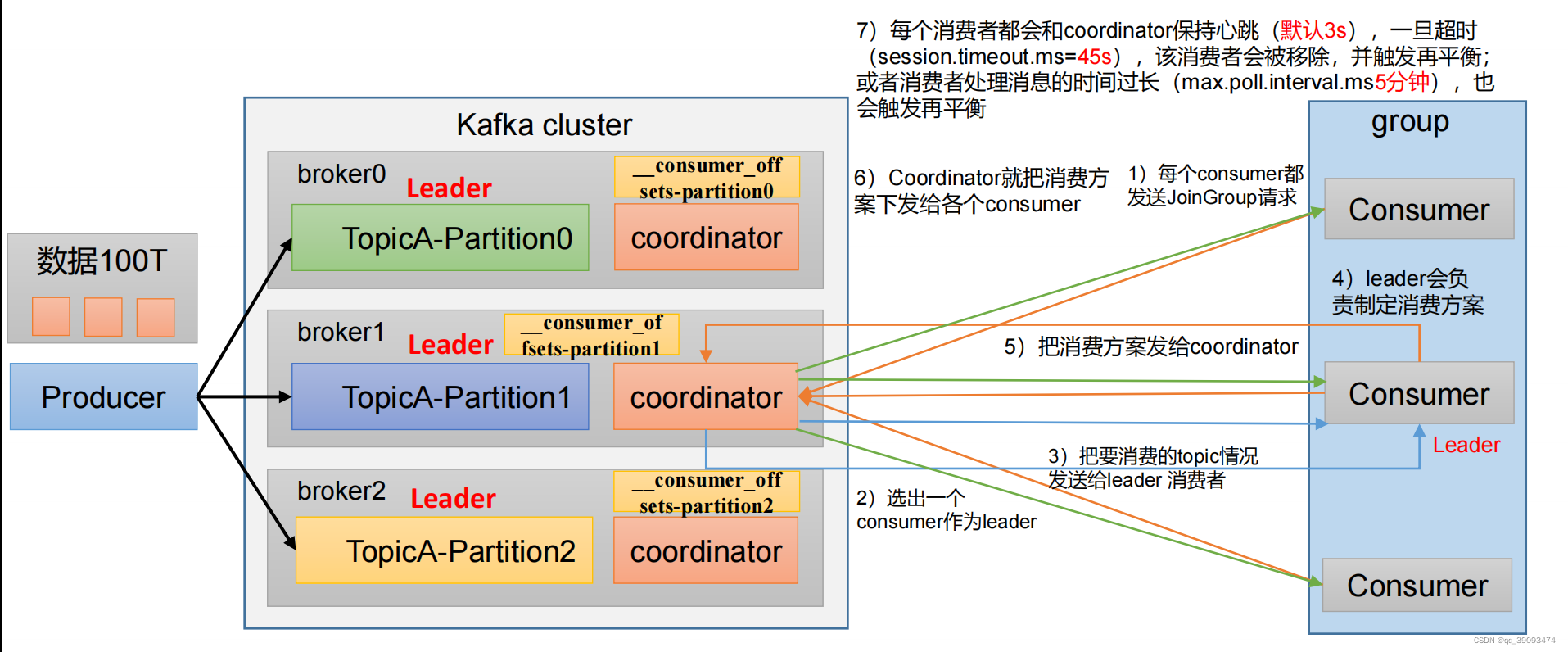
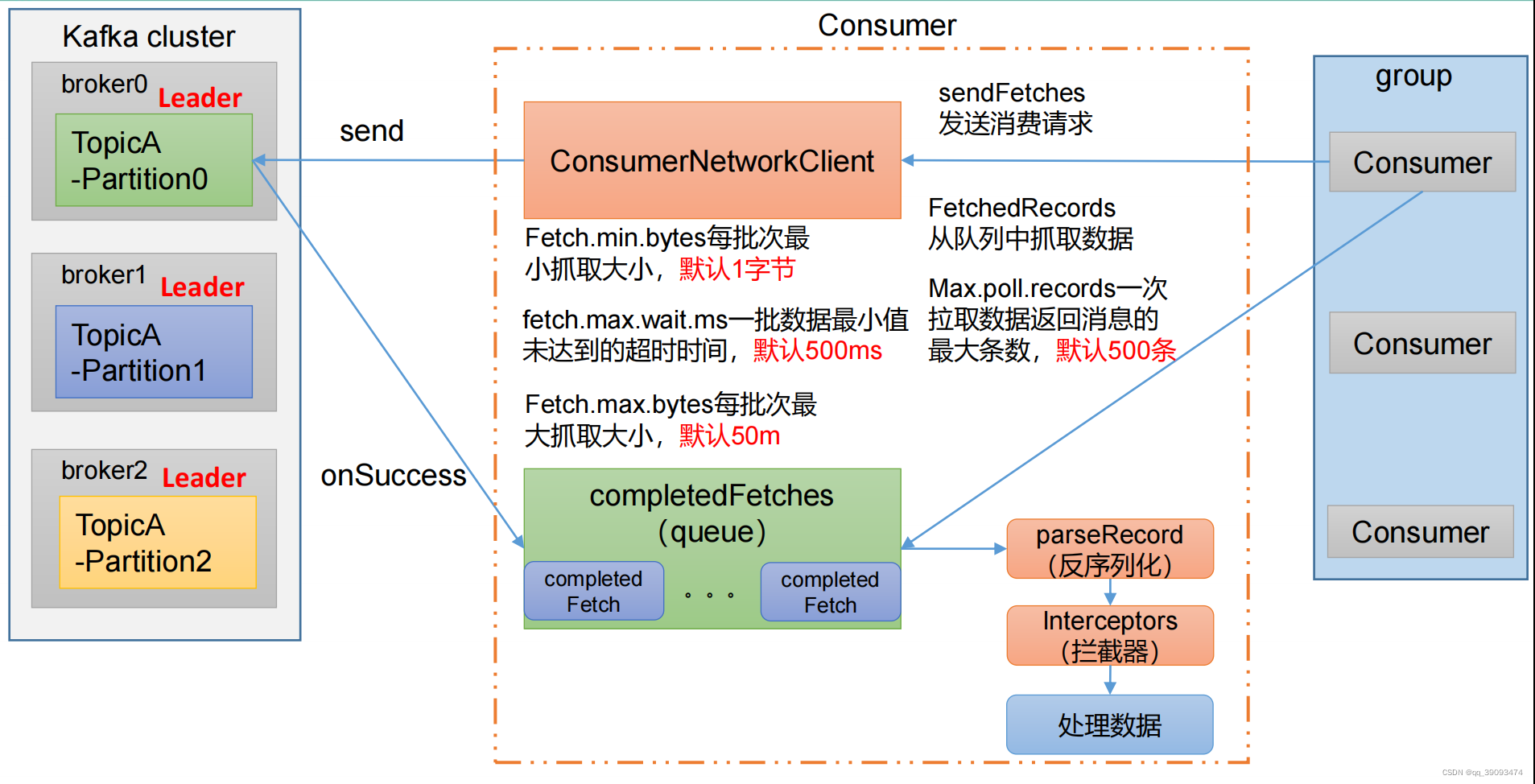
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 向 Kafka 集群建立初始连接用到的 host/port 列表。 |
| key.deserializer和value.deserializer | 指定接收消息的 key 和 value 的反序列化类型。一定要写全类名。 |
| group.id | 标记消费者所属的消费者组。 |
| enable.auto.commit | 默认值为 true,消费者会自动周期性地向服务器提交偏移量。 |
| auto.commit.interval.ms | 如果设置了 enable.auto.commit 的值为 true, 则该值定义了消费者偏移量向 Kafka 提交的频率,默认 5s。 |
| auto.offset.reset | 当 Kafka 中没有初始偏移量或当前偏移量在服务器中不存在(如,数据被删除了),该如何处理? earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常。 |
| offsets.topic.num.partitions | __consumer_offsets 的分区数,默认是 50 个分区。不建议修改。 |
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间,默认 3s。该条目的值必须小于 session.timeout.ms ,也不应该高于session.timeout.ms 的 1/3。不建议修改 |
| session.timeout.ms | Kafka 消费者和 coordinator 之间连接超时时间,默认 45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认 1 个字节。消费者获取服务器端一批消息最小的字节数。 |
| fetch.max.wait.ms | 默认 500ms。如果没有从服务器端获取到一批数据的最小字节数。该时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认 Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影响。 |
| max.poll.records | 一次 poll 拉取数据返回消息的最大条数,默认是 500 条。 |
6. Kafka调优之Kafka总体
6.1 提升生产吞吐量
- buffer.memory:发送消息的缓冲区大小,默认值是 32m,可以增加到 64m。
- batch.size:默认是 16k。如果 batch 设置太小,会导致频繁网络请求,吞吐量下降;如果 batch 太大,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
- linger.ms,这个值默认是 0,意思就是消息必须立即被发送。一般设置一个 5-100毫秒。如果 linger.ms 设置的太小,会导致频繁网络请求,吞吐量下降;如果 linger.ms 太长,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
- compression.type:默认是 none,不压缩,但是也可以使用 lz4 压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大 producer 端的 CPU 开销
6.2 消费者提高吞吐量
- 调整 fetch.max.bytes 大小,默认是 50m。
- 调整 max.poll.records 大小,默认是 500 条。
- 增加下游消费者处理能力
6.3 合理设置分区数
(1)创建一个只有 1 个分区的 topic。
(2)测试这个 topic 的 producer 吞吐量和 consumer 吞吐量。
(3)假设他们的值分别是 Tp 和 Tc,单位可以是 MB/s。
(4)然后假设总的目标吞吐量是 Tt,那么分区数 = Tt / min(Tp,Tc)。
例如:producer 吞吐量 = 20m/s;consumer 吞吐量 = 50m/s,期望吞吐量 100m/s;
分区数 = 100 / 20 = 5 分区
分区数一般设置为:3-10 个
分区数不是越多越好,也不是越少越好,需要搭建完集群,进行压测,再灵活调整分区
个数。
6.4 单条日志大于 1m
| 参数名称 | 描述 |
|---|---|
| message.max.bytes | 默认 1m,broker 端接收每个批次消息最大值。 |
| max.request.size | 默认 1m,生产者发往 broker 每个请求消息最大值。针对 topic级别设置消息体的大小。 |
| replica.fetch.max.bytes | 默认 1m,副本同步数据,每个批次消息最大值。 |
| fetch.max.bytes | 默认 Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影响。 |
6.5 服务器挂了
在生产环境中,如果某个 Kafka 节点挂掉。
正常处理办法:
- 先尝试重新启动一下,如果能启动正常,那直接解决。
- 如果重启不行,考虑增加内存、增加 CPU、网络带宽。
- 如果将 kafka 整个节点误删除,如果副本数大于等于 2,可以按照服役新节点的方式重新服役一个新节点,并执行负载均衡。
7. Kafka调优之集群压力测试
用 Kafka 官方自带的脚本,对 Kafka 进行压测。
- 生产者压测:kafka-producer-perf-test.sh
- 消费者压测:kafka-consumer-perf-test.sh
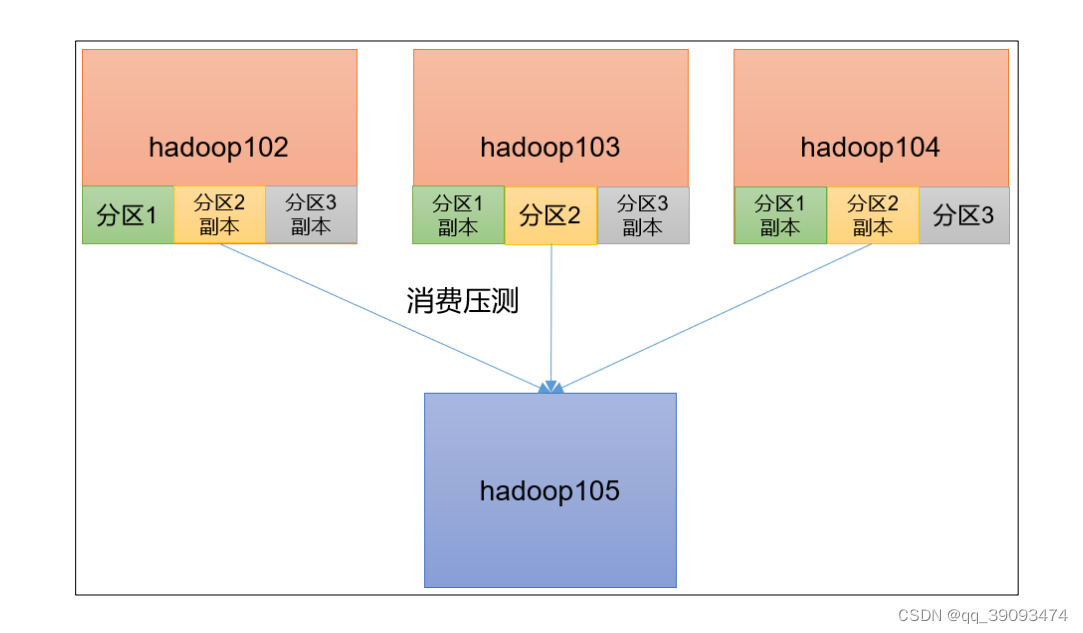
7.1 Kafka Producer 压力测试
- 创建一个 test topic,设置为 3 个分区 3 个副本
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --replication-factor 3 --partitions 3 --topic test
- 在/opt/module/kafka/bin 目录下面有这两个文件。我们来测试一下
bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=16384 linger.ms=0
参数说明:
- record-size:是一条信息有多大,单位是字节,本次测试设置为1k
- num-records:是总共发送多少条消息,本次测试设置为100w条
- throughput :是每秒多少条信息,设成-1,表示不限流,尽可能快的生产数据,可测出生产者最大吞吐量,本次测试设置为每秒钟1w条
- producer-props 后面可以配置生产者相关参数,batch.size 配置为 16k。
输出结果:
ap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=16384
linger.ms=0
37021 records sent, 7401.2 records/sec (7.23 MB/sec), 1136.0 ms avg latency,
1453.0 ms max latency.
50535 records sent, 10107.0 records/sec (9.87 MB/sec), 1199.5 ms avg
latency, 1404.0 ms max latency.
47835 records sent, 9567.0 records/sec (9.34 MB/sec), 1350.8 ms avg latency,
1570.0 ms max latency.
。。。 。。。
42390 records sent, 8444.2 records/sec (8.25 MB/sec), 3372.6 ms avg latency,
4008.0 ms max latency.
37800 records sent, 7558.5 records/sec (7.38 MB/sec), 4079.7 ms avg latency,
4758.0 ms max latency.
33570 records sent, 6714.0 records/sec (6.56 MB/sec), 4549.0 ms avg latency,
5049.0 ms max latency.
1000000 records sent, 9180.713158 records/sec (8.97 MB/sec), 1894.78 ms
avg latency, 5049.00 ms max latency, 1335 ms 50th, 4128 ms 95th, 4719 ms
99th, 5030 ms 99.9th.
- 可以按照提升生产者吞吐量参数和自身业务进行调整,找到适合自己的生产
配置。
- buffer.memory:发送消息的缓冲区大小,默认值是 32m,可以增加到 64m。
- batch.size:默认是 16k。如果 batch 设置太小,会导致频繁网络请求,吞吐量下降;如果 batch 太大,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
- linger.ms,这个值默认是 0,意思就是消息必须立即被发送。一般设置一个 5-100毫秒。如果 linger.ms 设置的太小,会导致频繁网络请求,吞吐量下降;如果 linger.ms 太长,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
- compression.type:默认是 none,不压缩,但是也可以使用 lz4 压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大 producer 端的 CPU 开销
7.2 Kafka Consumer 压力测试
- 修改/opt/module/kafka/config/consumer.properties 文件中的一次拉取条数为 500
max.poll.records=500
- 消费 100 万条日志进行压测
bin/kafka-consumer-perf-test.sh --bootstrap-server hadoop102:9092,hadoop103:9092,hadoop104:9092 - -topic test --messages 1000000 --consumer.config config/consumer.properties
参数说明:
- bootstrap-server :指定 Kafka 集群地址
- topic :指定 topic 的名称
- messages 总共要消费的消息个数。本次实验 100 万条。
- consumer.properties:消费条件
输出结果:

- 修改/opt/module/kafka/config/consumer.properties 文件中的一次拉取条数为 2000。进行测试
max.poll.records=2000
- 修改/opt/module/kafka/config/consumer.properties 文件中的拉取一批数据大小 100m。进行测试
fetch.max.bytes=104857600














 2159
2159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









