







 本文深入探讨了深度学习在推荐系统中的应用,特别是DIN(深度兴趣网络)模型,它通过引入注意力机制解决了用户行为序列的信息丢失问题。DIN的核心在于weighted-sum pooling和激活函数Dice,旨在更有效地关注用户行为中的重要信息。此外,文章还讨论了优化策略如ReLU激活函数、优化器选择和防止过拟合的方法,以及评估模型性能的ROC和AUC等指标。
本文深入探讨了深度学习在推荐系统中的应用,特别是DIN(深度兴趣网络)模型,它通过引入注意力机制解决了用户行为序列的信息丢失问题。DIN的核心在于weighted-sum pooling和激活函数Dice,旨在更有效地关注用户行为中的重要信息。此外,文章还讨论了优化策略如ReLU激活函数、优化器选择和防止过拟合的方法,以及评估模型性能的ROC和AUC等指标。
算法基础总结
激活函数
推荐模型
DIN(首次引入attention)
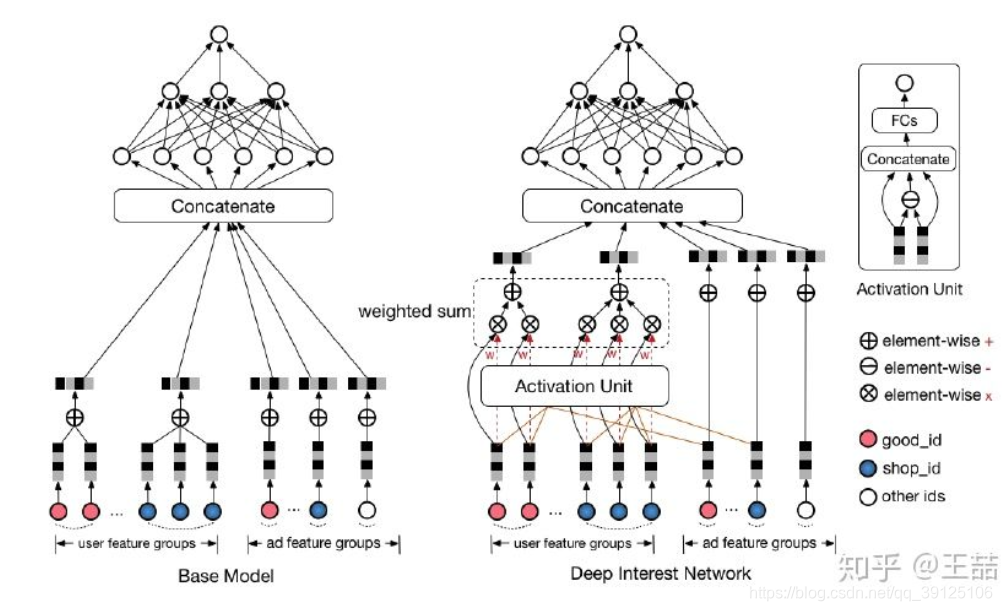
对比DIN模型和Base模型就可以发现在模型结构上的差别主要就在如何聚合多个用户行为Embedding向量,Base模型中直接对多个Embedding向量进行等权的sum-pooling,这种方法肯定会带来信息的丢失,而且相对重要的Embedding向量也无法完全突出自己所包含的信息。所以DIN采取了一个比较直观的方式,就是weighted-sum pooling,而且Attention的本质也可以认为是weighted-sum,让模型更加关注有用的信息(有用信息的权重会更大一些)
1、模型结构
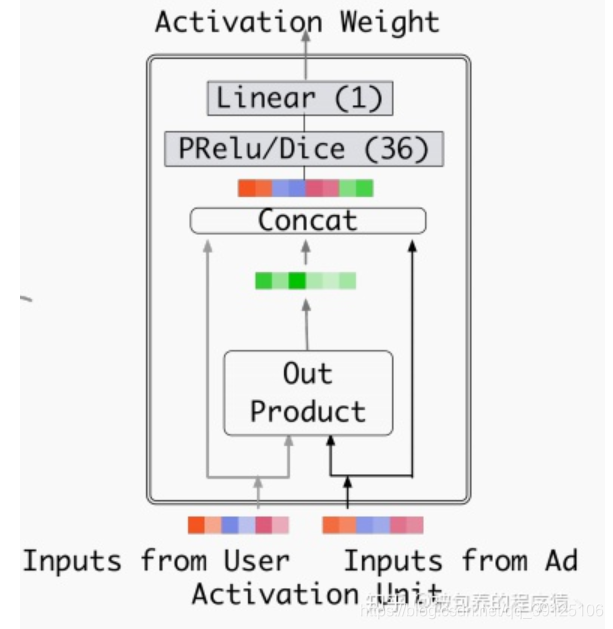
(1) 做差式
(2) 做外积式
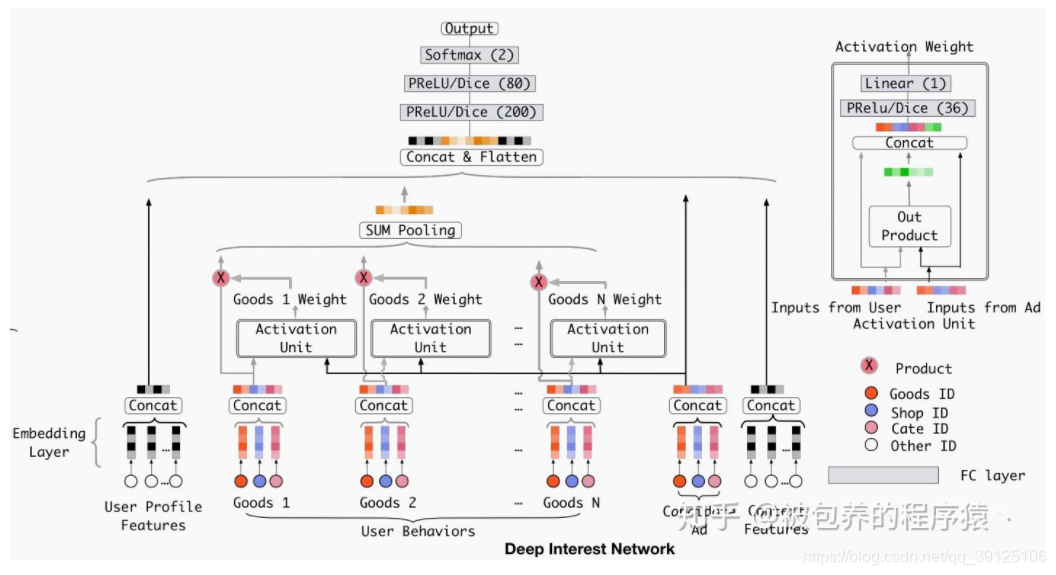
文中计算Attention权重的方式是利用用户行为的Embedding向量和广告的Embedding向量,结构如下
文中放宽了对于权重加和等于一的限制,即没有做attention的归一化,这样更有利于体现不同用户行为特征之间的差异化程度。
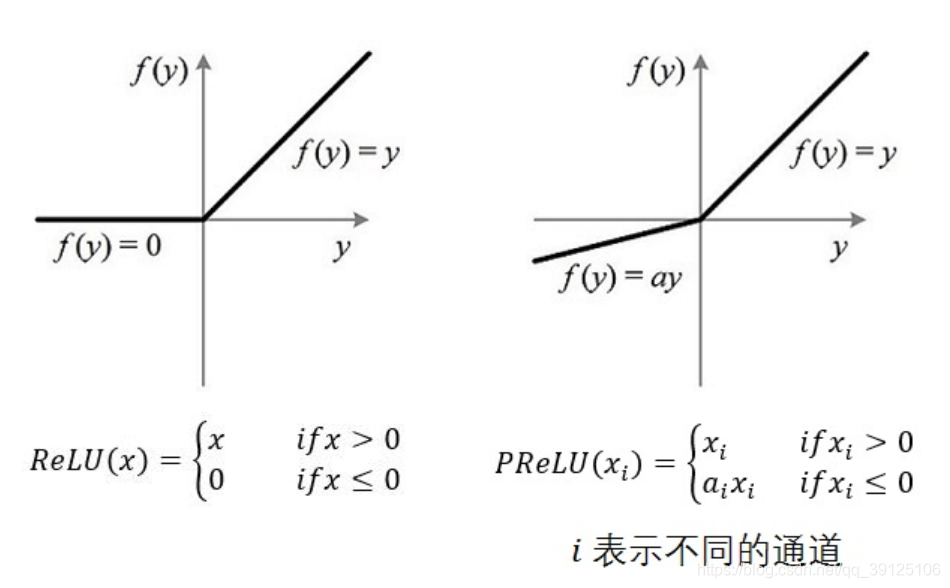
2、提出了一个激活函数Dice
对于Relu或者PRelu来说,rectified point(梯度发生变化的点)都在0值,Dice对每个特征以mini-batch为单位计算均值和方差,然后将rectified point调整到均值位置。
3、optimizer优化
对L2正则化梯度回传过程的改进:在进行SGD优化的时候,每个mini-batch都只会输入部分训练数据,反向传播只针对部分非零特征参数进行训练,添加上L2之后,需要对整个网络的参数包括所有特征的embedding向量进行训练,这个计算量非常大且不可接受。论文中提出,在每个mini-batch中只对该batch的特征embedding参数进行L2正则化。
DIEN
N C T V
Deep learning
李宏毅深度学习课程笔记
为什么网络越深效果越好
一种理解:4层网络通过取不同的参数值可以等价于3层、2层……的网络,也就是可选的拟合函数集范围更大,因此可能能训得更好的网络
梯度消失
由于网络初始几层的参数的更新需要从后往前的梯度相乘,造成前面的梯度越来越小

直观理解:初始层的δw变化很多,但是经过sigmoid后变化的值δc非常小
1.使用ReLU类的激活函数

部分神经元的值变为0,其余变为线性,相当于下图,在梯度反向传播时,就只训了下图中存在的节点,其他节点能在其他样本输入的情况下训练

RELU相关变体

Maxout(类似max pooling)

可以自适应得到不同结构的激活函数

2.更优的optimizer
过拟合
1.early stopping
用validation set让模型停在test loss最小的地方
2.正则化
3.Dropout
train:训练时每个神经元都有p%的概率不参与训练,实际相当于训了多个不同的子网络(每个batch都是不同的子网络),但是这些子网络间的权重是共享的,只是排列组合成了不同的子网络,如下图

test:
给每一个权值乘以(1-p%)【相当于期望??(自己理解)】,测试相当于所有训练的子模型取平均。如下图所示,但其实这种直观的理解只对线性模型等价,对于非线性模型是不等价的,但是也work,原因未知……

评价指标
ROC和AUC
ROC曲线:通过不断移动分类器的“截断点”来生成曲线上的一组关键点的,从最高的得分开始(实际上是从正无穷开始,对应着ROC曲线的零点),逐渐调整到最低得分,每一个截断点都会对应一个FPR和TPR,在ROC图上绘制出每个截断点对应的位置,再连接所有点就得到最终的ROC曲线。
AUC:ROC曲线下的面积大小,AUC越大,说明分类器越可能把真正的正样本排在前面,分类性能越好。
当二者相等时,即y=x。表示的意义是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的。换句话说,分类器对于正例和负例毫无区分能力,和抛硬币没什么区别。

我们希望分类器达到的效果是:对于真实类别为1的样本,分类器预测为1的概率(即TPRate),要大于真实类别为0而预测类别为1的概率(即FPRate),即y>x,因此大部分的ROC曲线长成下面这个样子:

理想的情况下,既没有真实类别为1而错分为0的样本——TPRate一直为1,也没有真实类别为0而错分为1的样本——FP rate一直为0,AUC为1,这便是AUC的极大值。
AUC的计算方法同时考虑了分类器对于正例和负例的分类能力,在样本不平衡的情况下所受影响较小,还能维持大致形状。
P-R曲线
P-R曲线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。整条P-R曲线是通过将阈值从高到低移动而生成的。

受正负样本影响较大


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









