










如果同学不喜欢看理论,可以直接看后面王者数据分析的部分。
关联规则
- 如果不知道尿布和啤酒问题,建议百度百科,先有个大致的了解
- 我们找百度百科上面的例子来讲一下
- tid是交易单号,后面每一纵列中1代表购买,0代表没买。
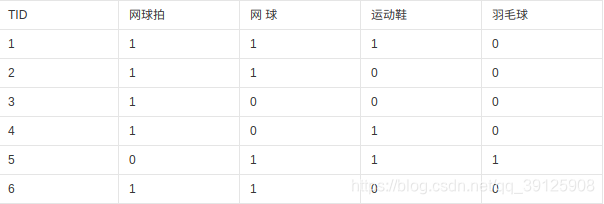
- 我们只需要明白
- 支持度==概率(只有这个支持度足够大,说明我们选出的集合买的人多,对于商家的价值也就越大)
- 置信度==条件概率(这是算关联程度的)
- 关联规则挖掘过程主要包含两个阶段:第一阶段必须先从资料集合中找出所有的高频项目组(Frequent Itemsets),第二阶段再由这些高频项目组中产生关联规则(Association Rules),这里我们说说apriori算法。
-
Apriori算法分为两部分
-
我们要算出符合支持度>0.4的集合
- 一开始我们的集合1列有
个成员,我们可以看到羽毛球小于支持度0.4,所以跟他有关的我们的直接舍去
- 集合2列
个我们同样得出支持度。
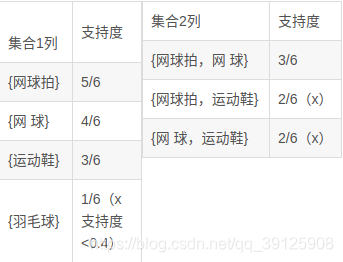
- 一开始我们的集合1列有
- 我们要算出里面符合置信度的。这里只有2项
- 网球拍=>网球,置信度3/5
- 网球=>网球拍,置信度3/4
- 也就数说网球拍=>网球,网球=>网球拍,这两个规则都满足要求
- 这里我们提一下:转自
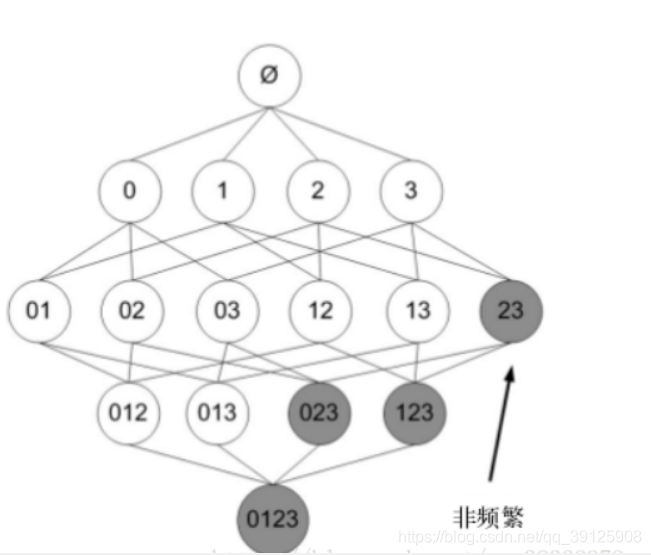
- Apriori原理:如果某个项集是频繁的,那么它的所有子集也是频繁的。该定理的逆反定理为:如果某一个项集是非频繁的,那么它的所有超集(包含该集合的集合)也是非频繁的。Apriori原理的出现,可以在得知某些项集是非频繁之后,不需要计算该集合的超集,有效地避免项集数目的指数增长,从而在合理时间内计算出频繁项集。
- 在图中,已知阴影项集{2,3}是非频繁的。利用这个知识,我们就知道项集{0,2,3},{1,2,3}以及{0,1,2,3}也是非频繁的。也就是说,一旦计算出了{2,3}的支持度,知道它是非频繁的后,就可以紧接着排除{0,2,3}、{1,2,3}和{0,1,2,3}。
-
- 代码如下
- 如果我们计算组合直接调用 apriori(dataSet, min_support=0.5),修改dateset和min_support就行。
- 当然如果我们需要置信度和支持度和提升度,就需要arules(dataSet, min_support=0.5)
- 先说下什么叫提升度:
提升度表示含有X的条件下,同时含有Y的概率,与只看Y发生的概率之比。提升度反映了关联规则中的X与Y的相关性,提升度>1且越高表明正相关性越高,提升度<1且越低表明负相关性越高,提升度=1表明没有相关性,即相互独立。
Lift(X→Y) = P(Y|X) / P(Y)
-
arules函数会返回rules|support|confidence|lift。最后直接通过DataFrame的方法提取符合条件的组合就行。
- 先说下什么叫提升度:
-
import itertools
import pandas as pd
def createC1(dataSet): # 'C1' for Candidate-itemset of 1 item.“C1”表示1个项目的候选项集
# Flatten the dataSet, leave unique item 展平数据集,保留唯一项
C1 = set(itertools.chain(*dataSet))
# Transform to a list of frozenset 转换为冻结集列表
return [frozenset([i]) for i in C1]
# 计算集合的支持度
def scanD(dataSet, Ck, min_support): # 'Ck' for Candidate-set of k items. k项候选集的“Ck”
support = {}
# Calculate the support of all itemsets 计算所有项集的支持
for i in dataSet:
for j in Ck:
if j.issubset(i):
support[j] = support.get(j, 0) + 1
n = len(dataSet)
# Return litemset with support
return {k: v/n for k, v in support.items() if v/n >= min_support}
def aprioriGen(Lk): # 'Lk' for Large-itemset of k items. “Lk”表示k个项目的大项目集
# Generate candidate k+1 itemset from litemset 从litemset生成候选k+1项集
lenLk = len(Lk)
k = len(Lk[0])
if lenLk > 1 and k > 0:
return set([
Lk[i].union(Lk[j])
for i in range(lenLk - 1)
for j in range(i + 1, lenLk)
if len(Lk[i] | Lk[j]) == k +1
]) # Use set() to drop duplicates
def apriori(dataSet, min_support=0.5):
'''
Return all large itemsets
'''
C1 = createC1(dataSet)
L1 = scanD(dataSet, C1, min_support)
L = [L1, ] # Large-itemsets
k = 2
while len(L[k-2]) > 1:
Ck = aprioriGen(list(L[k-2].keys()))
Lk = scanD(dataSet, Ck, min_support)
if len(Lk) > 0:
L.append(Lk)
k += 1
else:
break
# Flatten the freqSets 展平频率集
d = {}
for Lk in L:
d.update(Lk)
return d
def rulesGen(iterable):
# Generate nonvoid proper subset of litemset. 生成litemset的非空真子集
subSet = []
for i in range(1, len(iterable)):
subSet.extend(itertools.combinations(iterable, i))
return [(frozenset(lhs), frozenset(iterable.difference(lhs)))
for lhs in subSet] # Left hand rule and right hand rule 左手定则和右手定则
def arules(dataSet, min_support=0.5):
'''
Return a pandas.DataFrame of 'rules|support|confidence|lift'
'''
# Generate a dict of 'large-itemset: support' pairs
L = apriori(dataSet, min_support)
# Generate candidate rules
rules = []
for Lk in L.keys():
if len(Lk) > 1:
rules.extend(rulesGen(Lk))
# Calculate support、confidence、lift
scl = [] # 'scl' for 'Support, Confidence and Lift'
for rule in rules:
lhs = rule[0]; rhs = rule[1]
support = L[lhs | rhs]
confidence = support / L[lhs]
lift = confidence / L[rhs]
scl.append({'LHS':lhs, 'RHS':rhs, 'support':support, 'confidence':confidence, 'lift':lift})
return pd.DataFrame(scl)
if __name__ == '__main__':
transactions = pd.read_csv("./Transactions.csv")
baskets = transactions['Model'].groupby(transactions['OrderNumber']).apply(list)
# 为了满足arules函数的变量,将其转化为嵌套的列表。
dataSet = baskets.tolist()
rules = arules(dataSet, min_support=0.02)
conf = rules[(rules.confidence > 0.5) & (rules.lift > 1)]
# print(conf.sort_values(by = 'support', ascending=True).head())
else:
print ('apriori imported!')
王者荣耀数据分析实战
- 如果知道ban/pick的同学,任何一款imba类的游戏都有自己的英雄搭配。随着比赛战队的不同和英雄属性的调整,英雄的搭配也就不同了。如果我们考虑不同战队的ban或者以选代ban,那数据就太少了。因为要排除版本更替带来的影响,我们选取了2018年冬冠EDG.M的战绩分析。
- 首先我们要先去找数据,如果你会爬虫,可以直接爬。数据地址。也可以用开发者模式(如果你有兴趣)。
- 经过一些数据清洗,这些我就不介绍了,爬下来的数据一般都很乱,不会写代码还要手动处理。可以看到有很多无用信息。
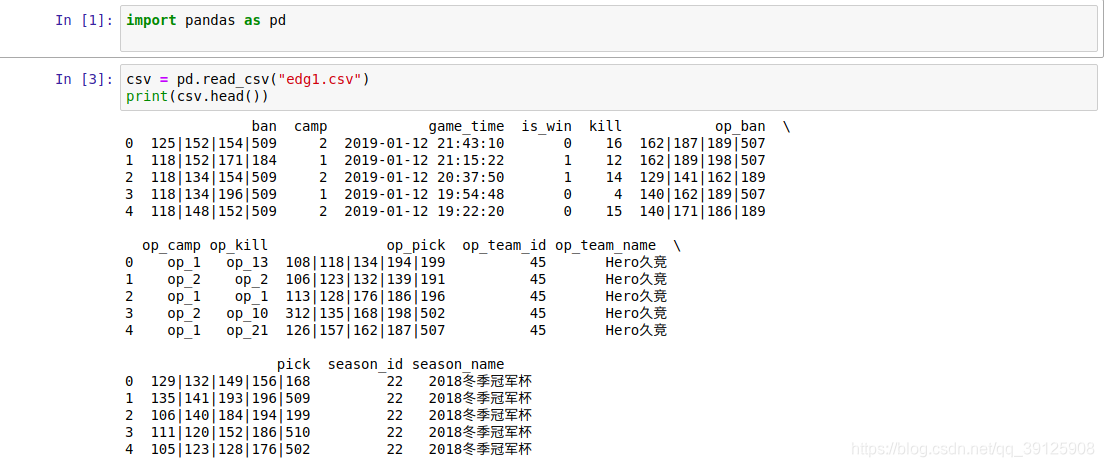
- 最后搞成只有英雄就行。
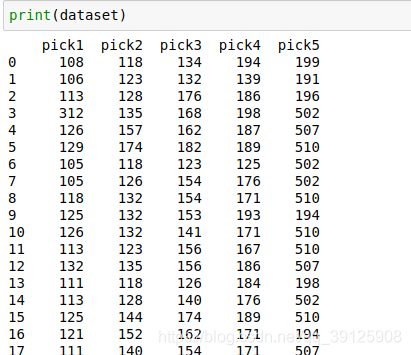
- 下面就简单了,直接调用我上面给的函数
import pandas as pd import numpy as np import sys sys.path.append(r'../apriori') # python 原有apriori.py 文件故需要少些最后一个字母 import aprior csv = pd.read_csv("edg1.csv") content_list = csv['op_pick'] with open('op_pick1.csv','a') as f: for content in content_list: f.write(content) f.write('\n') dataset = pd.read_csv('op_pick1.csv') data = np.array(dataset).reshape(-1, 5) print(aprior.apriori(data,min_support = 0.09))# 我取最后两个组合,对此王者官网确定,确定(154,花木兰),(199,公孙离),(162,鸟人),(134,达摩)
# 这次的数据较少,只体现了edg在2018冬季冠军杯最喜欢的两队组合是(花木兰,公孙离)和(达摩,娜可露露)。也就是当时初晨(打野)和阿澈(下单)的组合较为稳定。
如果大家有兴趣可以自己试一试。
参考:
Python机器学习算法 — 关联规则(Apriori、FP-growth):https://www.cnblogs.com/lsqin/p/9342926.html
百度百科:https://baike.baidu.com/item/%E5%85%B3%E8%81%94%E8%A7%84%E5%88%99/6319603?fr=aladdin


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









