







前面更多的都是介绍如何使用,功能和机制。
文章目录
前言
本章是针对Redis底层的数据类型的学习,存储结构进行介绍。本章内容也算是比较丰富,当然也是参考了很多文章,没有一一列出参考文献,因为太多了。如果需要我一定加上。
存储方式
前面提到了Redis插槽的概念。在集群中,每个master也分配了不同的插槽范围。怎么判断是插入哪个插槽?如果碰撞了怎么处理呢?
Redis的做法是,将key进行hash再对槽位进行求余数,就可以确定放在哪个槽位。肯定会有求余之后在同一个槽位。此时就会通过链表的形式,把新的K-V接在这个槽位上K-V的后面。因此可以看出DICT是采用数组加链表的方式存储。
假设槽位是4个,现在有四个key要存入,先对三个key进行hash和求余
hash(k1)%4=0
hash(k2)%4=1
hash(k3)%4=2
hash(k4)%4=1
可以看到k2和k4都要插入同一个槽位
arr[0]=(k1,next=null)
arr[1]=(k2,next=k4),(k4,next=nell)
arr[2]=(k3,next=null)
arr[3]=null
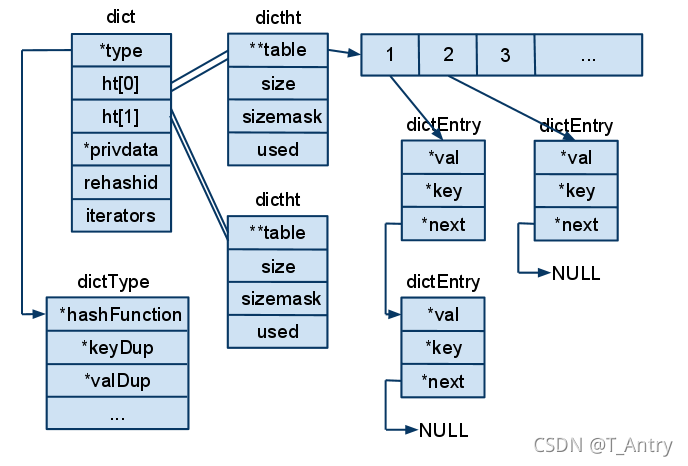
用这个图,可以更清晰地看出,一个个dictentry放入插槽中,如果碰撞在同一个插槽,那么就会接在上一个dictentry后面。
扩容
扩展哈希表,就是为ht[1]分配一块大小为ht[0]两倍的空间,然后把ht[0]的数据通过rehash的方式全部迁移到ht[1],最后释放ht[0],使ht[1]成为ht[0],再为ht[1]分配一个空哈希表。收缩哈希表类似。
渐进式rehash: redis并不是专门找时间一次性地进行rehash,而是渐进地进行,rehash期间不影响外部对ht[0]的访问,要求修改字典时要把对应数据同步到ht[1]中,全部数据转移完成时,rehash结束。
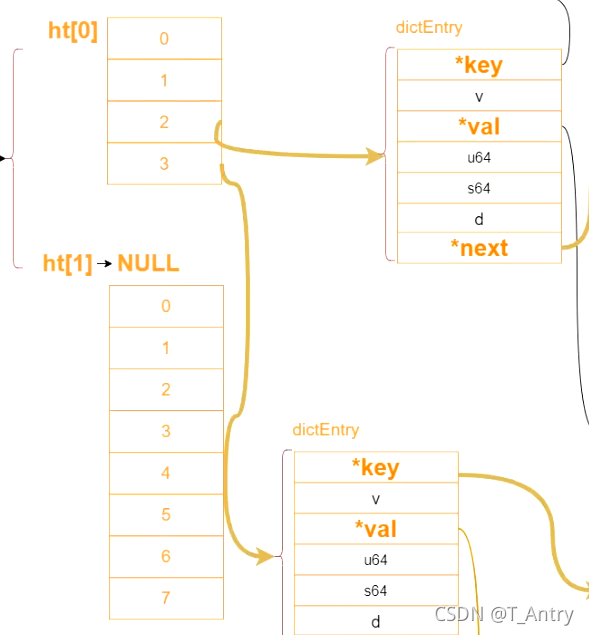
dictEntry
是字典指向的内容,*val有五种类型String list hash set zset
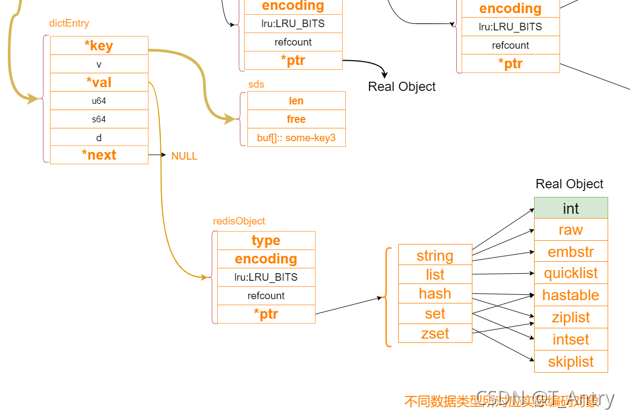
SDS类型(String)
这里可以看到key的类型是sds,实际上key是String类型,而Redis 是使用 C 语言实现的,但是 Redis 中使用的字符串却不是直接用的 C 语言中字符串的定义,而是自己实现了一个数据结构,叫做 SDS(simple dynamic String), 即简单动态字符串,五大类型的String也是用SDS。

struct sdshdr{
int len;
int free;
char buf[];
}
len=5, 说明当前存储的字符串长度为 5.
free=4, 4个空闲字符串长度。
buf 属性是一个 char 类型的数组,保存了实际的字符串信息。
可以看到 len 属性和 buf 属性的已使用部分都和第一个示例相同,但是 free 属性为 4, 同时 buf 属性的除了保存了真实的字符串内容之外,还有 5 个空的未使用空间 (’\0’结束字符不在长度中计算)

Redis 为什么要这么做呢,或者说使用 SDS 来作为字符串的具体实现结构,有什么好处呢?
C 语言的字符串定义,是使用和字符串相等长度的字符数组来存储字符串,并且在后面额外加一个字符来存储空字符’\0’
高性能获取字符串长度
从 C 语言字符串的结构图中,我们可以看到,如果我们想获取一个字符串的长度,那么唯一的办法就是遍历整个字符串。遍历操作需要 O(N) 的时间复杂度。
而 SDS 记录了字符串的长度,也就是 len属性,我们只需要直接访问该属性,就可以拿到当前 SDS 的长度。访问属性操作的时间复杂度是 O(1).
Redis 字符串数据结构的 求长度的命令 STRLEN. 内部即应用了这一特性。无论你的 string 中存储了多长的字符串,当你想求出它的长度时,可以随意的执行 STRLEN, 而不用担心对 Redis 服务器的性能造成压力。
杜绝缓冲区溢出
C 语言的的字符串拼接函数,strcat(*desc, const char *src), 会将第二个参数的值直接连接在第一个字符串后面,然而如果第一个字符串的空间本就不足,那么此时就会产生缓冲区溢出。
SDS 记录了字符串的长度,同时在 API 实现上杜绝了这一个问题,当需要对 SDS 进行拼接时,SDS 会首先检查剩余的未使用空间是否足够,如果不足,会首先扩展未使用空间,然后进行字符串拼接。
因此,SDS 通过记录使用长度及未使用空间长度,以及封装 API, 完美的杜绝了在拼接字符串时容易造成缓冲区溢出的问题。
二进制安全
C 语言的字符串不是二进制安全的,因为它使用空间符’\0’来判断一个字符串的结尾。也就是说,假如你的字符串是 abc\0aa\0 哈哈哈、0, 那么你就不能使用 C 语言的字符串,因为它识别到第一个空字符’\0’的时候就结束识别了,它认为这次的字符串值是’abc\0’。
而二进制中的数据,我们谁也说不好,如果我们存储一段音频序列化后的数据,中间肯定会有无数个空字符,这时候怎么 C 语言的字符串就无能为力了。
而 SDS 可以,虽然 SDS 中也会在字符串的末尾储存一个空字符,但是它并不以这个空字符为判断条件,SDS 判断字符串的长度时使用 len属性的,截取 字节数组 buf 中的前 len 个字符即可。
减少修改字符串产生的内存分配次数,提高修改字符串性能
C 语言的字符串实现,是一个长度永远等于 字符串内容长度+1 的字节数组。那么也就意味着,当字符串发生修改,它所占用的内存空间必须要发生更改。
- 字符串变长。需要首先扩展当前字符串的字节数组,来容纳新的内容。
- 字符串变短。在修改完字符串后,需要释放掉空余出来的内存空间。
空间预分配
SDS 在进行修改之后,会对接下来可能需要的空间进行预分配。这也就是 free 属性存在的意义,记录当前预分配了多少空间。
分配策略:
- 如果当前 SDS 的长度小于 1M, 那么分配等于已占用空间的未使用空间,即让 free 等于 len.
- 如果当前 SDS 的长度大于 1M, 那么分配 1M 的 free 空间。
在 SDS 修改时,会先查看 free属性的值,来确定是否需要进行空间扩展,如果不需要就直接进行拼接了。
通过预分配策略,SDS 连续增长 N 次,所需要的内存分配次数从绝对 N 次,变成了最多 N 次。
惰性释放内存
当 SDS 进行了缩短操作,那么多余的空间不着急进行释放,暂时留着以备下次进行增长时使用。
听起来预分配和惰性释放本质上也是使用空间换取时间的操作,SDS 也提供了对应的 API, 在需要的时候,会自己释放掉多余的未使用空间。
redis 3.2 后:
sds结构一共开始有五种Header定义,其目的是为了满足不同长度的字符串可以使用不同大小的Header,从而节省内存。 Header部分主要包含以下几个部分:
- len:表示字符串真正的长度,不包含空终止字符
- alloc:表示字符串的最大容量,不包含Header和最后的空终止字符
- flags:表示header的类型。
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
在RedisObject中,SDS的三种存储形式
字符串对象的底层实现有三种:int, raw, embstr.
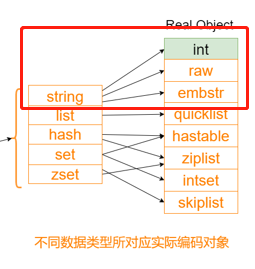
- int
如果一个字符串对象,保存的值是一个整数值,并且这个整数值在 long 的范围内,那么 redis 用整数值来保存这个信息,并且将字符串编码设置为 int.
127.0.0.1:6379> set antry 999999999999999999
OK
127.0.0.1:6379> object encoding antry
"int"
- embstr
如果字符串对象保存的是一个字符串, 但是长度小于 32 个字节,它就会使用embstr来保存了,embstr编码不是一个数据结构,而是对 SDS 的一个小优化,当使用 SDS 的时候,程序需要调用两次内存分配,来给 字符串对象 和 SDS 各自分配一块空间,而embstr只需要一次内存分配,因为他需要的空间很少,所以采用 连续的空间保存,即将 SDS 的值和 字符串对象的值放在一块连续的内存空间上。这样能在短字符串的时候提高一些效率。
127.0.0.1:6379> set antry 9999999999999999991
OK
127.0.0.1:6379> object encoding antry
"embstr"
127.0.0.1:6379> set antry aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
OK
127.0.0.1:6379> object encoding antry
"raw"
- raw
如果字符串对象保存的是一个字符串, 并且长度大于 32 个字节,它就会使用前面讲过的SDS(简单动态字符串)数据结构来保存这个字符串值,并且将字符串对象的编码设置为raw.
127.0.0.1:6379> set antry aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
OK
127.0.0.1:6379> object encoding antry
"raw"
List的数结构
List低层采用 ziplist + qicklist 实现,采用一段连续的存储空间来存储数据,如下的Entry区域。

当Entry区域的数据太大时(如上设置为8K),需要把该Entry进行分裂,分裂成2个,用QuickList来存储数据,大概结构如下:
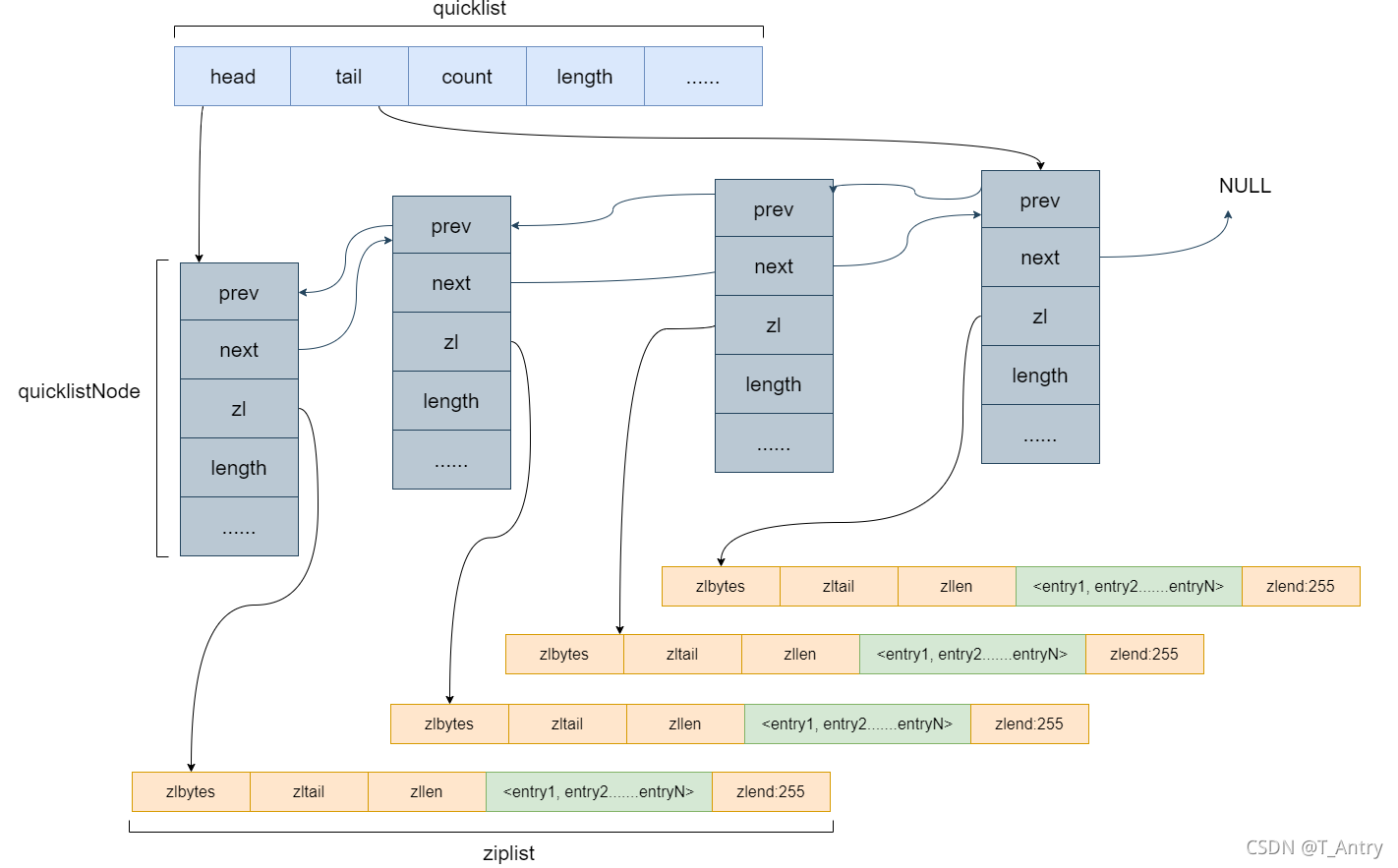
可以通过设置每个ziplist的最大容量,quicklist的数据压缩范围,提升数据存取效率
list-max-ziplist-size -2 // 单个ziplist节点最大能存储 8kb ,超过则进行分裂,将数据存储在新的ziplist节点中
list-compress-depth 1 // 0 代表所有节点,都不进行压缩,1, 代表从头节点往后走一个,尾节点往前走一个不用压缩,其他的全部压缩,2,3,4 ... 以此类推
Hash的数据结构
Hash数据结构底层实现为一个字典(dict),也是RedisDB用来存储K-V的数据结构,当数据量比较小,或者单个元素比较小时,底层用ziplist存储。
127.0.0.1:6379> object encoding hash
"ziplist"
127.0.0.1:6379> hset hash name 11111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111
(integer) 1
127.0.0.1:6379> object encoding hash
"hashtable"
数据大小和元素数量阈值可以通过如下参数设置。
hash-max-ziplist-entries 512 // ziplist 元素个数超过 512 ,将改为hashtable编码
hash-max-ziplist-value 64 // 单个元素大小超过 64 byte时,将改为hashtable编码
Set 数据结构:
Set为无序的,自动去重的集合数据结构,set数据结构底层实现是一个Value为null的字典(dict),当数可以用整型表示时,Set结婚将被编码为intset数据结构当满足以下任意调节时用hashtable存储数据。
set-max-intset-entries 512 // intset 能存储的最大元素个数,超过则用hashtable编码
Zset数据结构:
ZSet 为有序的,自动去重的集合数据类型,ZSet 数据结构底层实现为 字典(dict) + 跳表(skiplist) ,当数据比较少时,用ziplist编码结构存储
zset-max-ziplist-entries 128 // 元素个数超过128 ,将用skiplist编码
zset-max-ziplist-value 64 // 单个元素大小超过 64 byte, 将用 skiplist编码
跳表 skip list
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针(注:可以理解为维护了多条路径),从而达到快速访问节点的目的。
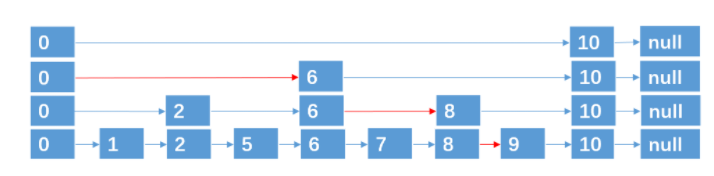
特点:
- 跳跃表的每一层都是一条有序的链表。
- 维护了多条节点路径。
- 最底层的链表包含所有元素。
- 跳跃表的空间复杂度为 O(n)。
- 跳跃表支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
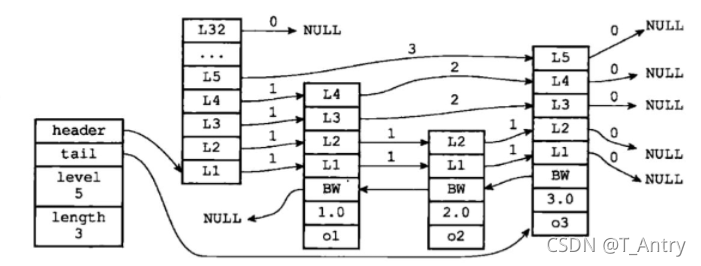
、Redis的跳跃表由redis.h/zskiplistNode和redis.h/zskiplist两个结构定义,其中zskiplistNode结构用于表示跳跃表节点,而zskiplist结构则用于保存跳跃表节点的相关信息。
比如节点的数量,以及指向表头节点和表尾节点的指针等等。位于图片最左边的是zskiplist结构,该结构包含以下属性:
- header:指向跳跃表的表头节点
- tail:指向跳跃表的表尾节点
- level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)
- length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)
位于zskiplist结构右方的是四个zskiplistNode结构,该结构包含以下属性:
- 层(level): 节点中用L1、L2、L3等字样标记节点的各个层,L1代表第一层,L2代表第二层,依次类推。
每个层都带有两个属性:前进指针和跨度。
-
前进指针: 用于访问位于表尾方向的其他节点
-
跨度: 记录了前进指针所指向节点和当前节点的距离。
在上面的图片中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。 -
后退(backward)指针:节点中用BW字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
-
分值(score):各个节点中的1.0、2.0和3.0是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。
-
成员对象(obj):各个节点中的o1、o2和o3是节点所保存的成员对象。
GeoHash 算法
业界比较通用的地理位置距离排序算法是 GeoHash 算法,Redis 也使用 GeoHash 算法。
GeoHash 算法将二维的经纬度数据映射到一维的整数,这样所有的元素都将在挂载到一条线上,距离靠近的二维坐标映射到一维后的点之间距离也会很接近。
设想一个正方形的蛋糕摆在你面前,二刀下去均分分成四块小正方形,这四个小正方形可以分别标记为 00,01,10,11 四个二进制整数。然后对每一个小正方形继续用二刀法切割一下,这时每个小小正方形就可以使用 4bit 的二进制整数予以表示。然后继续切下去,正方形就会越来越小,二进制整数也会越来越长,精确度就会越来越高。
上面的例子中使用的是二刀法,真实算法中还会有很多其它刀法,最终编码出来的整数数字也都不一样。
编码之后,每个地图元素的坐标都将变成一个整数,通过这个整数可以还原出元素的坐标,整数越长,还原出来的坐标值的损失程度就越小。
Geo 指令基本使用
geoadd 指令携带集合名称以及多个经纬度名称三元组,注意这里可以加入多个三元组
127.0.0.1:6379> geoadd company 116.48105 39.996794 juejin
(integer) 1
127.0.0.1:6379> geoadd company 116.514203 39.905409 ireader
(integer) 1
127.0.0.1:6379> geoadd company 116.489033 40.007669 meituan
(integer) 1
127.0.0.1:6379> geoadd company 116.562108 39.787602 jd 116.334255 40.027400 xiaomi
(integer) 2
距离
geodist 指令可以用来计算两个元素之间的距离,携带集合名称、2 个名称和距离单位。
127.0.0.1:6379> geodist company juejin ireader km
"10.5501"
127.0.0.1:6379> geodist company juejin meituan km
"1.3878"
127.0.0.1:6379> geodist company juejin jd km
"24.2739"
127.0.0.1:6379> geodist company juejin xiaomi km
"12.9606"
多线程
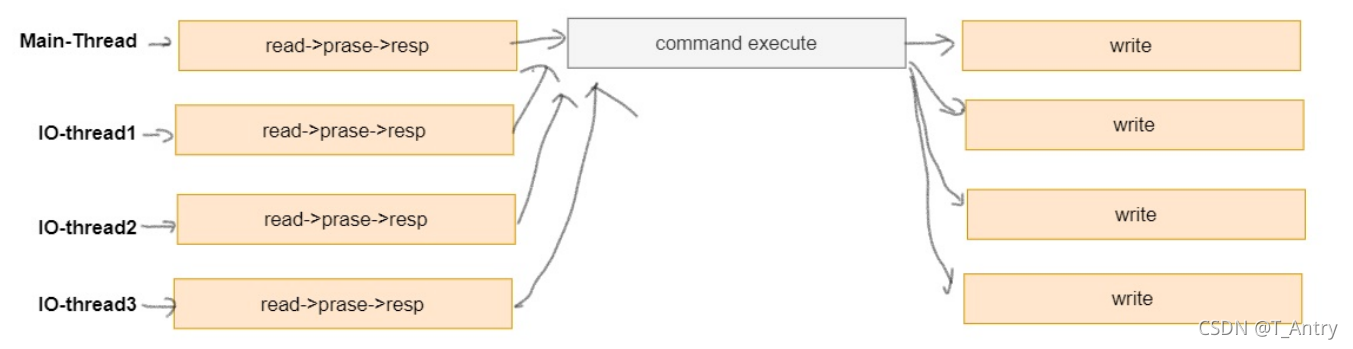
redis 6.0 提供了多线程的支持,redis 6 以前的版本,严格来说也是多线程,只不过执行用户命令的请求时单线程模型,还有一些线程用来执行后台任务, 比如 unlink 删除 大key,rdb持久化等。
redis 6.0 提供了多线程的读写IO, 但是最终执行用户命令的线程依然是单线程的,这样,就没有多线程数据的竞争关系,依然很高效。
redis 6.0 以前线程执行模式,如下操作在一个线程中执行完成

redis 6.0 线程执行模式:
可以通过如下参数配置多线程模型:
io‐threads 4 // 这里说 有三个IO 线程,还有一个线程是main线程,main线程负责IO读写和
命令执行操作
默认情况下,如上配置,有三个IO线程, 这三个IO线程只会执行 IO中的write 操作,也就是说,read 和 命令执行 都由main线程执行。最后多线程将数据写回到客户端。
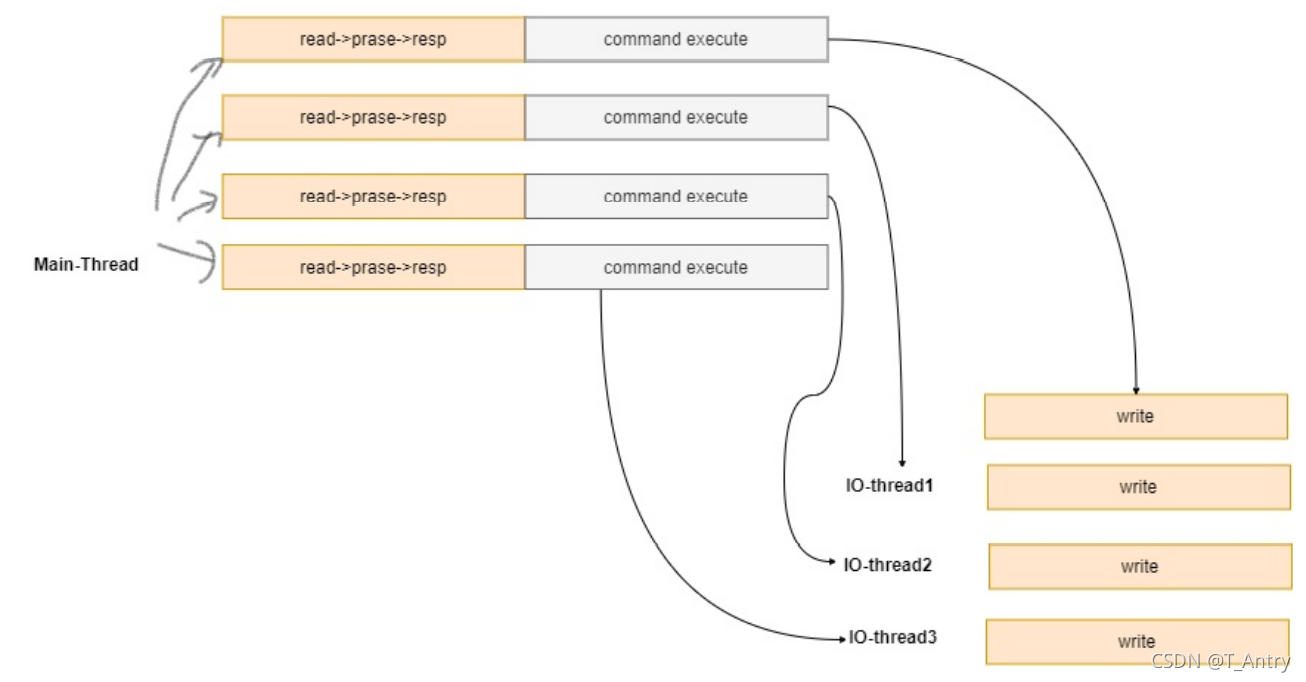
io‐threads‐do‐reads yes // 将支持IO线程执行 读写任务。
命令执行交给mian线程,其他都可以做。
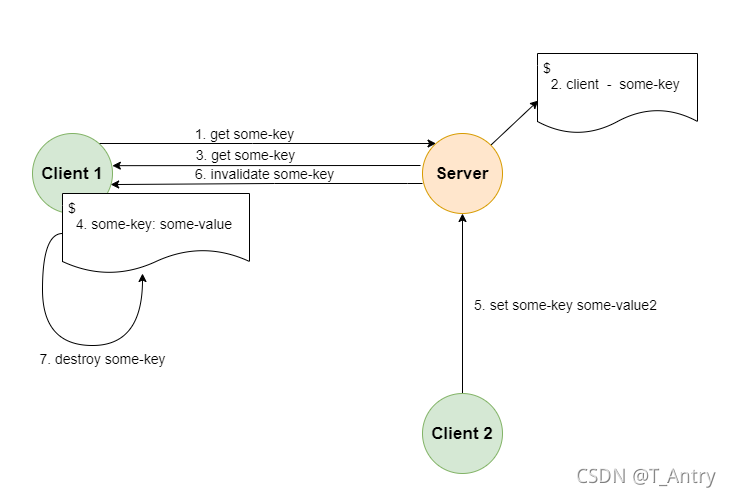
client side caching
客户端缓存:redis 6 提供了服务端追踪key的变化,客户端缓存数据的特性,这需要客户端实现
执行流程为, 当客户端访问某个key时,服务端将记录key 和 client ,客户端拿到数据后,进行客户端缓存,这时,当key再次被访问时,key将被直接返回,避免了与redis 服务器的再次交
互,节省服务端资源,当数据被其他请求修改时,服务端将主动通知客户端失效的key,客户端进行本地失效,下次请求时,重新获取最新数据。
ACL
ACL 是对于命令的访问和执行权限的控制,默认情况下,可以有执行任意的指令,兼容以前版本<
ACL设置有两种方式:
- .命令方式
ACL SETUSER + 具体的权限规则, 通过 ACL SAVE 进行持久化 - 对 ACL 配置文件进行编写,并且执行 ACL LOAD 进行加载
ACL存储有两种方式,但是两种方式不能同时配置,否则直接报错退出进程- redis 配置文件: redis.conf
- ACL配置文件, 在redis.conf 中通过 aclfile /path 配置acl文件的路径

















 1244
1244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









