







中南大学超算深度学习环境配置
说明
原HPC的cuda为10.0版本,因此最新只能装torch1.4,但需要使用更高版本的torch,因此只能尝试更新cuda版本来安装高版本的torch
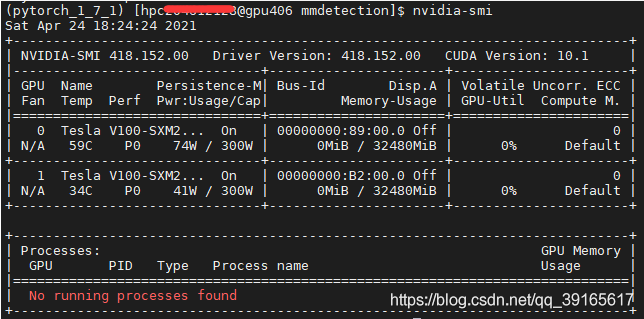
虽然在/public/software内安装了cuda10.2,但显卡驱动版本如下图所示为418.152.00,最高支持cuda10.1
平台简介
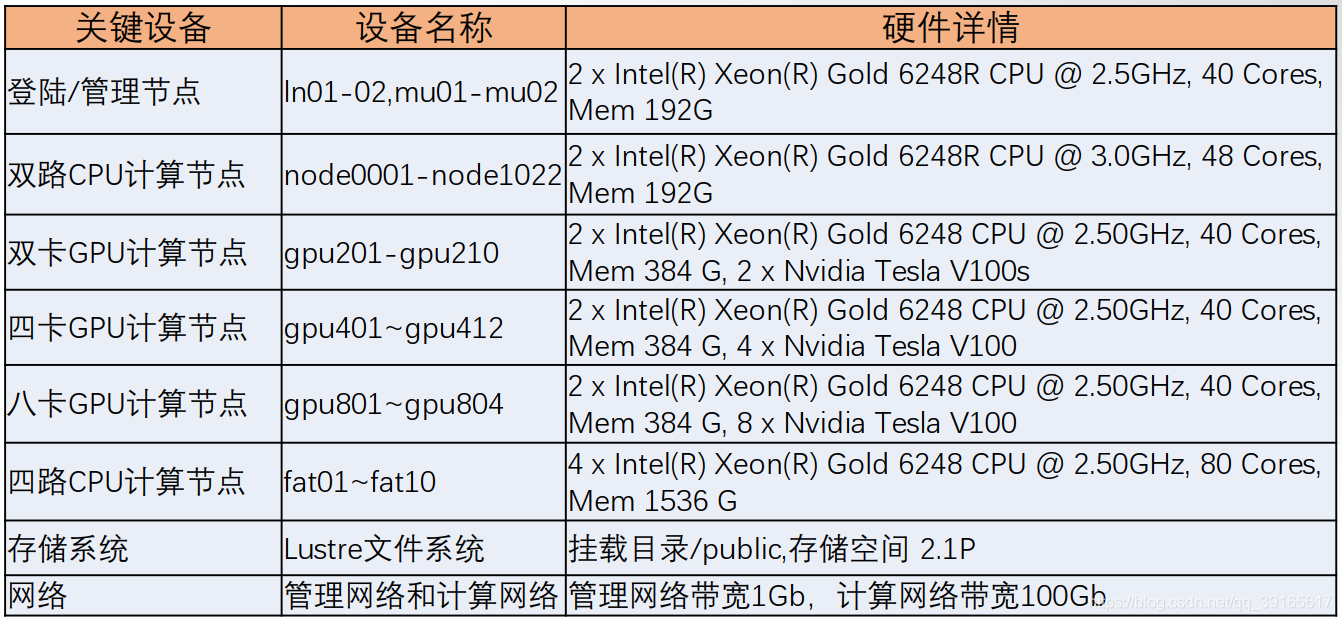
中南hpc硬件组成 节点数
- 双路CPU节点 1022个
- GPU数量 100块
配置
0.配置conda初始环境
'''登录到自己的节点后运行下面两行,重新登录终端'''
/public/software/anaconda3/bin/conda init bash #初始化conda环境,须重新登录生效
cp /public/software/anaconda3/condarc ~/.condarc && conda clean -i #配置清华大学conda源
# 重新登录终端后前面将出现(base)
1. 申请并切换gpu节点
该步骤不执行的话将会报错 Log file not open ./cuda_10.1.243_418.87.00_linux.run: line 512: 55517 Segmentation fault ./cuda-installer
- 查看可申请的节点
执行sinfo
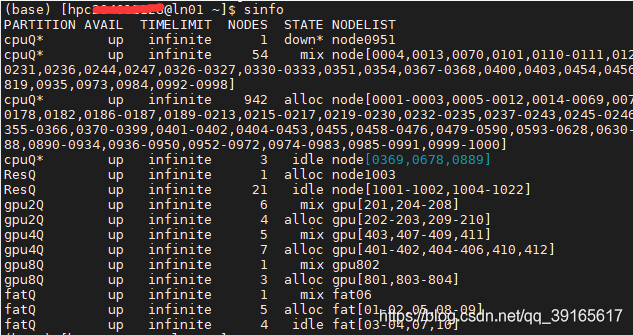
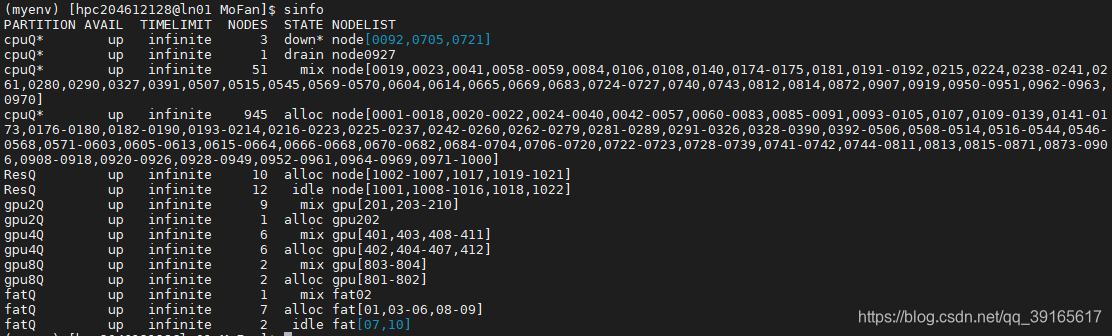
可以观察到所有gpu节点均处于alloc或mix状态,即无idel(空闲)状态,但mix状态我们同样可以申请非独占式的部分资源 - 申请gpu节点
例如申请属于gpu4Q(也可以是gpu2Q、gpu8Q)的节点,则执行salloc -p gpu4Q --qos=gpuq
若安装过程中还出现问题也有可能是申请的资源不够,可以只能更多资源例如salloc -N 1 -n 10 -p gpu2Q --gres=gpu:1 --qos=gpuq申请一个节点十个核心,gpu数量为1的节点

如果有节点资源可以申请到,则会及时返回一个任务号,如图为334847,一般还会返回申请到的节点名称,图中返回的是gpu411,如不返回节点名称,可输入squeue指令查看已申请的节点,最后一栏NODELIST即为申请到的节点名称 - 切换到gpu节点上
执行ssh gpu411切换到刚才申请的节点上

返回的如图是一个新的bash,@后面由ln01变成了gpu411
2. 安装cuda10.1
- 切换至下载了cuda安装文件的文件夹内运行如下安装

- 正常情况返回如下,点
accept同意
- 选中第一个回车取消安装显卡驱动(当然你也安不了),方向键下,再回车进入
options选项更改安装位置
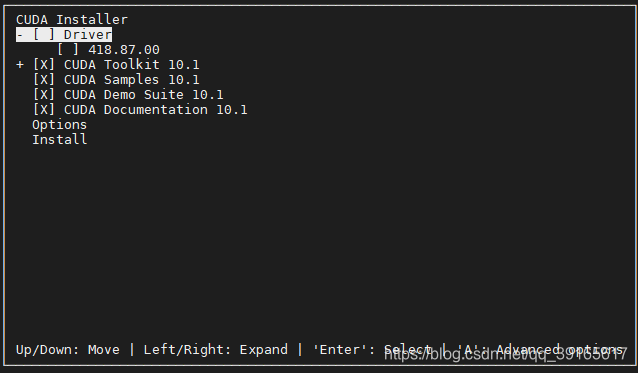
- 进入后,如图所示
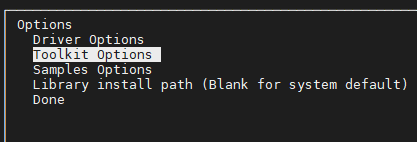
- 进入
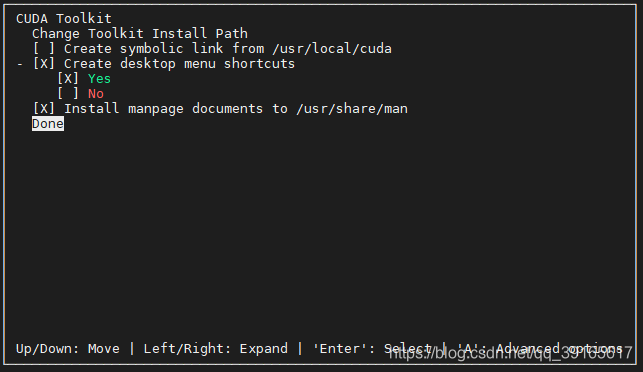
Toolkit Options,点第二个create symbolic link取消建立软连接,取消后如图所示(框中X消失),再点第一个Change Toolkit Install Path修改安装位置
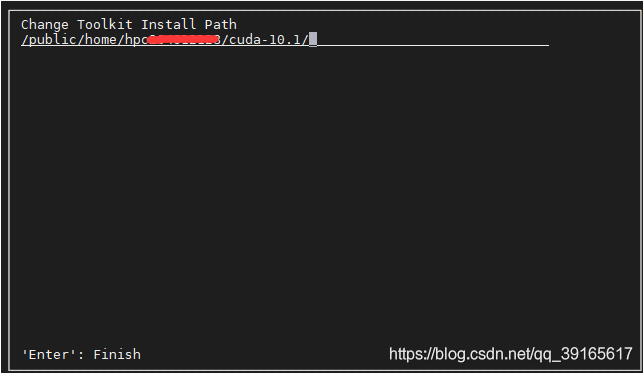
- 位置改为你的个人用户文件夹
你的文件夹/cuda-10.1
- 保存后点击Done返回,再点击
Library install path
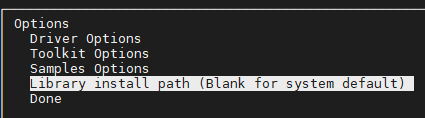
- 修改为自己安装的位置,修改后done,最后install
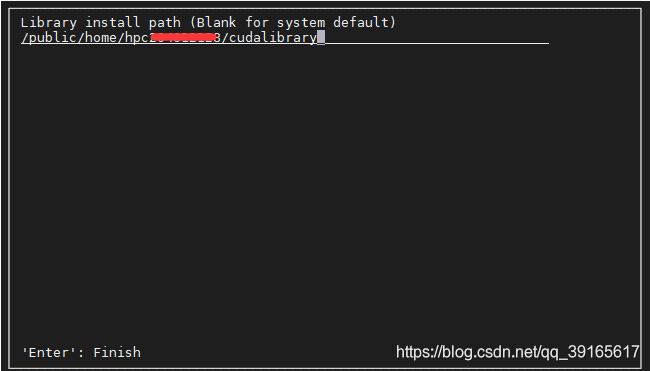
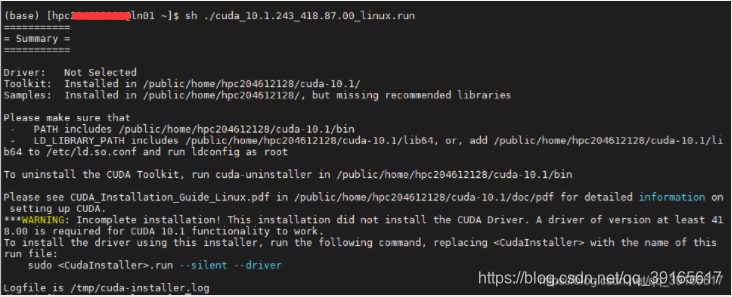
- 安装成功后的显示信息
3. 安装cudnn
下载并解压好cudnn
执行下面命令进行cudnn的安装即可
cp cuda/include/cudnn.h cuda-10.1/include
cp cuda/lib64/libcudnn* cuda-10.1/lib64/
chmod a+r cuda-10.1/include/cudnn.h
4.环境变量修改
因为hpc在启动个人bash时就已经添加了cuda相关的环境变量,但默认的为cuda10.0(详情/etc/profile),在~/.bashrc添加下面两行,在下次启动的时候自动转为个人用户下的cuda-10.1,下面两行内容前面为系统默认的cuda路径,后面为自己安装的cuda路径,按情况填写即可
PATH=${PATH//"/public/software/cuda10.0/bin"/"/public/home/hpc20*******/cuda-10.1/bin"}
LD_LIBRARY_PATH=${LD_LIBRARY_PATH//"/public/software/cuda10.0/lib64"/"/public/home/hpc20*******/cuda-10.1/lib64"}
设置完成后,执行source ~/.bashrc即可完成配置,下次登录无需修改和配置
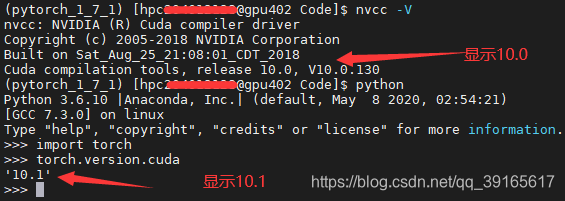
成功后输入nvcc -V,返回如下

在登录其它节点执行nvcc -V时可能出现还是显示10.0,但其实torch调用的还是cuda10.1,可在python+torch环境下进入执行torch.version.cuda验证查看,如下图所示
5.安装pytorch 1.7.1
'''创建环境'''
conda create -n torch171 python=3.6 #创建环境
conda activate torch171 #激活环境
安装torch时直接pip install会比较慢,建议本地浏览器或迅雷下载好,下载网址:https://download.pytorch.org/whl/cu101/torch_stable.html
我使用的是python 3.6 则下载py36 linux版本

'''下载好上图两个whl文件后,将其上传至自己的hpc文件夹中,并且在cd到两个whl的位置,依次运行如下两个指令'''
pip install torch-1.7.1-cp36-cp36m-linux_x86_64.whl
pip install torchvision-0.8.2-cp36-cp36m-linux_x86_64.whl
'''安装的过程中会将依赖的其它包安装上'''
超算下环境复制
在超算上可直接复制他人已有的环境,例如同学A已有配置好的anaconda下的python+torch环境,环境名称为torch171A,B正需要这种环境,在这种硬件条件相同的情况下可以进行环境复制
- A开放Home文件夹权限
chmod g+rx /public/home/A - B复制A的环境文件夹
cp -r /public/home/A/.conda/envs/trch171A /public/home/B/.conda/envs/trch171B_copy - A关闭权限
chmod g-rx /public/home/A - B根据文件新建环境
conda create -n torch171B --clone torch171B_copy
不进行这一步 conda env list 也可以查到torch171B_copy,也可以激活使用该环境,但是若进行了pip install 或其它环境管理操作则会出错 - 新建好后
conda activate torch171B即可使用环境 - 删除复制的文件夹
rm -rf /public/home/B/.conda/envs/trch171B_copy
如果有需要也可与本人联系,复制torch171等常用环境
安装tensorflow1.X
由于当前环境下使用的cuda已变为10.1,因此安装1.x版本不太一样,只需加conda install cudatoolkit=10.0
conda activate ***
conda install cudatoolkit=10.0
pip install tensorflow-gpu==1.13.1
## 测试(先登陆到gpu节点)
python
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))
Slurm指令
sinfo命令后显示信息
scontrol show partition '''显示分区信息 '''
sinfo '''显示队列或节点状态'''
squeue '''查看队列中的作业'''
squeue -u hpc2 '''显示队列中用户hpc2的作业'''
scancel 262 '''取消队列中任务ID为262的作业'''
scontrol show node gpu201 '''显示gpu201节点的详细信息'''
'''其他任务提交指令可参考最后给出的链接'''
srun -n 1 --exclusive -p gpu2Q --gres=gpu:2 --pty bash
# -n 1 一个节点
'''example 2----申请一个启动spyder的作业'''
srun -n1 --exclusive --x11 /public/software/anaconda3/bin/spyder
# --x11 x11 display 用于显示
# example 3------------------------------------
'''example 3----申请一个交互式作业bash 在之后运行spyder'''
srun -n 1 --x11 -p cpuQ --pty bash # --pty bash 为运行bash
# 将会返回一个 新bash(还在当前窗口的命令行) 再运行spyder
srun /public/software/anaconda3/bin/spyder
'''example 4----申请独占节点(双卡gpu)交互作业 并运行pycharm'''
srun --exclusive -n 1 --x11 -p gpu2Q --gres=gpu:2 --qos=gpuq --pty bash
# --gres 一般资源
# qos 质量 使用gpu时需指定
# 返回新的bash命令行 例如这个返回 (base) [hpc204612128@gpu207 bin]$
# -p gpu2Q -p为partition gpu2Q在sinfo中输出可查
sh pycharm.sh
salloc -N 1 -n 10 -p gpu4Q --gres=gpu:2 --qos=gpuq --pty bash #一个节点十个核心
salloc -N 1 -n 10 -p gpu4Q --gres=gpu:2 --qos=gpuq
# 假设申请到的节点是gpu406,则
ssh gpu406 # 切换至该节点
参考
基于中南大学高性能计算平台搭建深度学习平台
中南大学高性能计算平台-常见问题列表
中南大学高性能计算平台-快速使用指南
中南大学高性能计算平台-培训资料
中国科大超算中心-Slurm作业调度系统使用指南
北京大学高性能计算平台-使用指南
利用Slurm作业调度系统运行深度学习python文件















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









