







前言
接上篇,第六章第二部分,上篇讲到了红黑树的FixAfterInsertion方法,这个方法原理与fixAfterDelete类似,只讲这个添加时的调整方法
红黑树



代码可以看到,调整后的根节点一定是黑色的,叶子节点可红可黑,叶子下挂的虚节点一定是黑色,体现了红黑树的性质
左旋和右旋的代码如下,这里只有左旋,右旋类似

下图为color of 方法代码

下图为以一个treemap为例演示平衡策略


这里去除57,插入59会触发右旋和左旋

如上图,插入55为根,为黑,之后插入56为红,之后插入57为红,发现两红相邻,重染色并且旋转
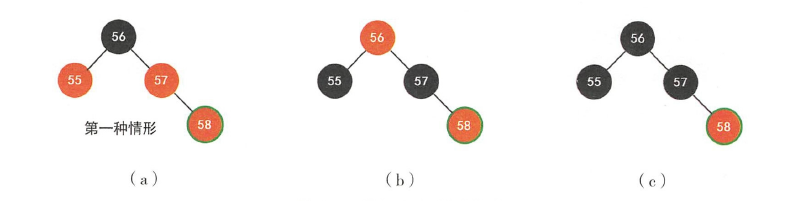
这里插入58,发现父节点是爷爷节点的右节点,左叔为红,所以把父节点和左叔都变黑,爷节点变红,因为56是根,退出循环同时执行根节点变黑
这里插入83,发现左叔不存在,父节点是爷节点右子树,认为是黑色NIL,将爷节点作为输入参数执行左旋
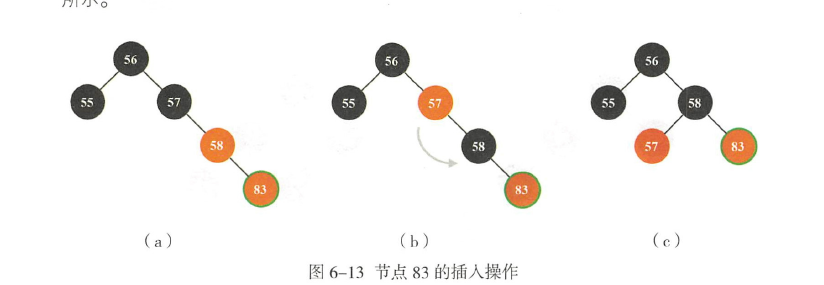
之后代码里要删除57,57是叶节点,为红,不影响红黑树,直接删除
之后59插入,比56大,比58大,比83小,放在83左子树
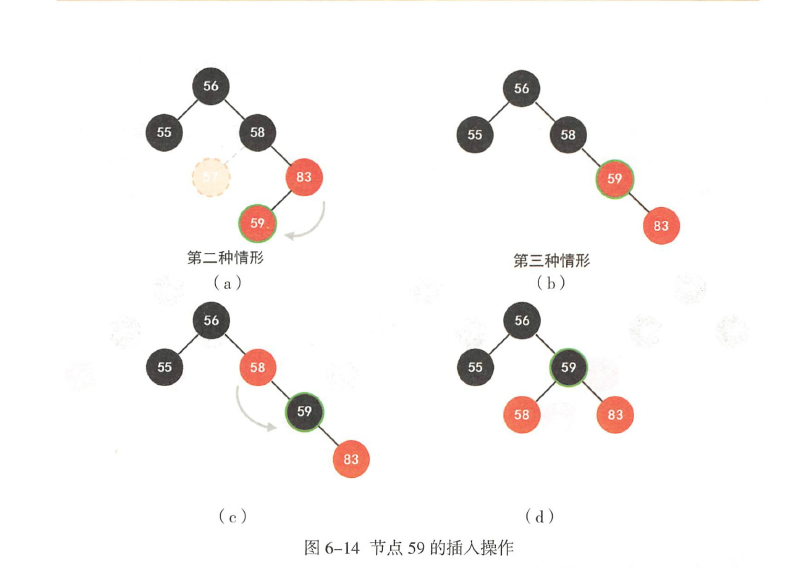
对于59,满足这些条件,开始右旋
· 父亲是爷爷的右子节点,
· 当前节点是父亲的左子节点;
· 左叔是黑色的( 删除57 的原因所在)
右旋之后, 把59 涂黑, 把58 置为红色, 然后以58 为输入参数, 进入左旋操作
树的演化中,有三种情况
1.父红叔红,重新做色
2.父红叔黑, 新节点是父节点左节点,右旋
3.父红叔黑,新节点是父节点右节点,左旋。
可以看到,任何旋转都在三次以内,每次回溯步长2,对于频繁插入删除场景,性能较好。
总结:TreeMap时间复杂度较高,但有序,稳定,支持范围查找,在排序场景中高效
线程不安全,不能在多线程中共享数据进行写操作,需要添加互斥机制,或者把对象放在Collections .
synchroinzedMap(treeMap) 中实现同步。
- JDK7 之后的HashMap 、Tree Set 、ConcurrentHashMap , 也使用红黑树,单个元素排序使用treeSet即可,TreeSet底层是TreeMap,value共享一个静态object对象

HashMap
在有线程安全需求场景下,推荐使用ConcurrentHashMap
HashMap有两个缺陷:死链和扩容数据丢失
场景:init时初始化一个static的HashMap集合,从数据库读入集合,但inti错误执行两次,启动失败,cpu占用过高,解决办法三种
第l 种解决方案是用ConcurrentHashMap 替代Hasmap
第2 种解决方案是使用Collections.synchronizedMap(hashMap ) 包装成同步集合
第3 种解决方案是对init()进行同步操作。此案例最终选择第3 种解决方案, 毕竟只有启动时调用而已。
场景2:

这里猜测是与并发读写有关,首先需要了解一下hashmap基本概念

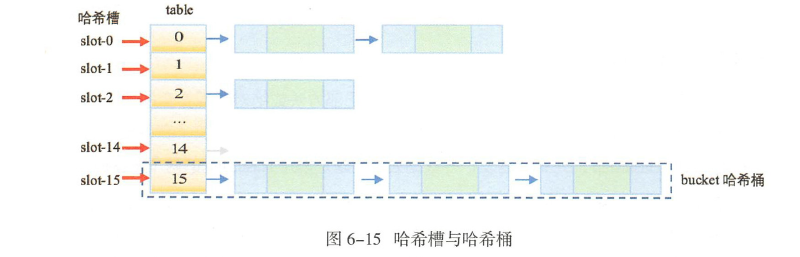
如上图,左侧是table数组,红色是位置标示,虚线里是哈希桶(包含链表和树)
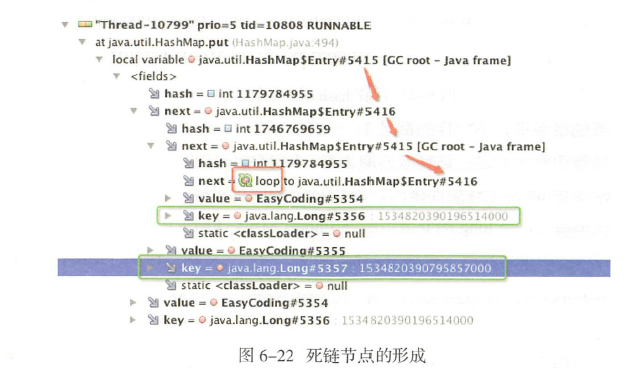
为了分析死链问题,需要看hashmap源码,这里是put方法


这里的createentry新加入元素会放在slot槽,为了可以更快访问,如果多个线程都执行到1处,就会产生覆盖现象
同时,还有扩容条件下的数据迁移



这些都是十分眼熟却易混淆的HashMap 相关概念值。理想的哈希集合对象的存
放应该符合,
· 只要对象不一样, hashcode就不一样;
· 只要hashCode 不一样,得到的hash Code 与hashSeed 位运算的hash 就不一样;
· 只要hash 不一样,存放在数组上的slot 就不一样。
但是现实中往往达不到,比如12个人分到8个位置,第1个和第9个用8取模就会有重合,如果位置扩大,比如12个人分100个位置,虽然可以减少冲突,但是资源浪费了,所以要用负载引入,比如0.75负载因子,就是12个人分开(12/0.75),这个12也是临界值,就是人数超过12时,就会引发扩容,在HashMap中,扩容会变为2倍
HashMap多个元素落在一个位置上就会向链表里放,遍历时有两个方向:
第一个方向,从下标table [0] 至table[length -1], 遍历所有哈希槽
第二个方向,如果哈希槽上存在元素,遍历哈希桶里的所有元素。
- 插入第13个元素时,会进行resize如下图

这里可以看到,旧表数据逆序放入新表,主要靠resize和transfer方法


transfer方法消耗资源较大,而且在transfer元素时,新元素可能落到旧表已经遍历过的哈希槽,旧表会被回收,这些元素也就丢失了
同时resize完成后,后续元素会插入新表,如果是多线程同时resize,每个线程单独执行newEntry[ newCapacity],由于这是线程单独可见,resize的线程赋给table共享变量,就会覆盖其他线程操作,因此新表中插入的元素会丢失
总结,hashmap对象丢失情况有:
1、并发赋值时被覆盖。
2、己遍历区间新增元素会丢失。
3、“新表”被覆盖。
4、迁移丢失。在迁移过程中,有并发时, next 被提前置成null 。
书中用10万个线程放对象,上来丢失1092个对象,因为对象覆盖
之后gc又少了8055个,属于引用丢失,剩下的被Map强引用持有

接下来的代码启动10 万个线程,以System.
nano Time()返回的Long 值为Key , 自定义对象EasyCoding 为Value


这里到一万个对象时,cpu使用率就超过300%
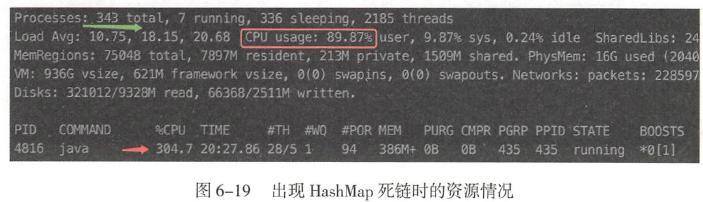
排查到两个线程,一直在running,说明有死链

使用jstack命令查看

这两处都存在对哈希桶内链表的遍历访问,其中, 601 行是循环提取同一个哈希
桶里的所有元素, 然后逐一倒序插入新表中。而494 行也是遍历访问, 在新增元素之前进行hashcode和equals比较,决定是覆盖value还是延伸到链表里
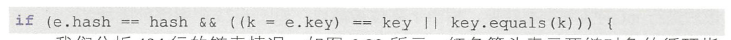
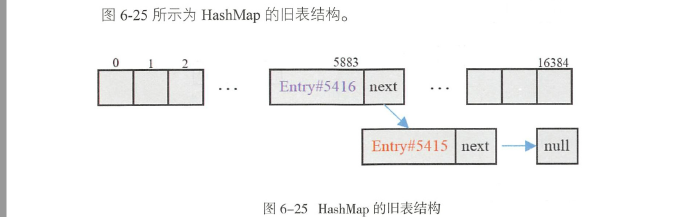
如下图,可以看到5415指向5416,之后又回指5415
下图计算了两个key是否落在一个哈希槽内

这里扩展了一点,long的hashcode不同于integer的hashcode,先获取Long( 1534820390 l 965 l 4000L )的二进制值,然后右移32 位后, 再与原来的值进行异或,最后进行int 的强制类型转换, 相当于高位被截掉,这样有利于泊松分布,上表得到哈希槽值5883,验证如下,访问下标5883的链表元素
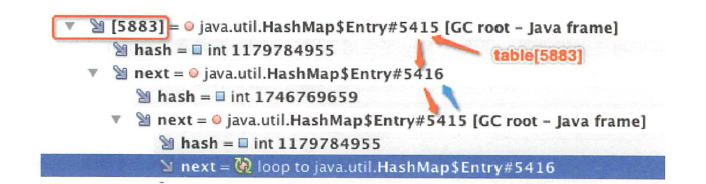
之前两个无限get的线程,始终在running状态,为了分析死链,要查看slot=5883

一直在第二步和第三步之间互相数据覆盖,死链生成有三点
原先没有死链的同一个slot节点遍历一定能按顺序走完
table数组是各线程共享的
put,get,transfer三种操作运行到有死链的slot上,cpu使用率会飙升
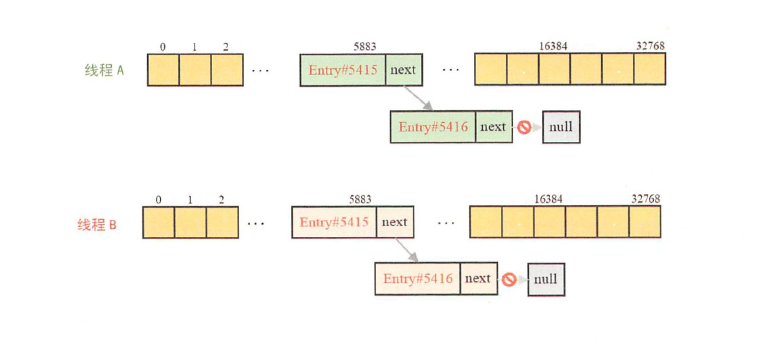
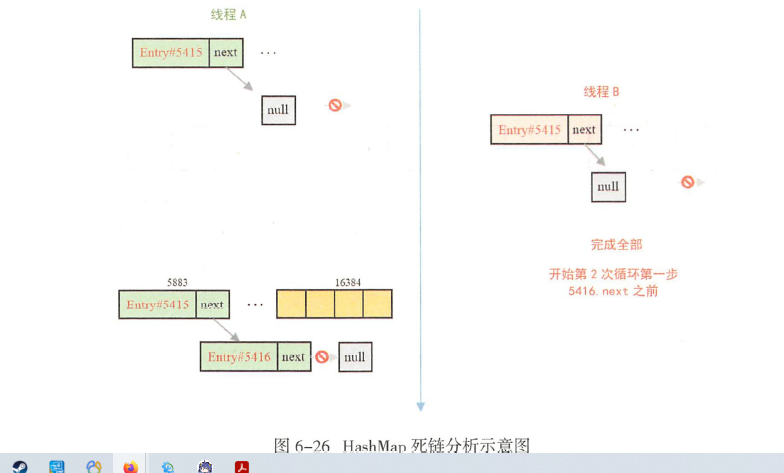
AB两个线程,执行transfer方法,产生问题的根源是Entry的next被并发修改,导致
( I )到象丢失。
( 2 )两个对象互链。
( 3)对象自己互链
环路问题原因是两个线程遍历完第一个节点后,第二个节点处产生互链
JDK7当中,是( size >= threshold) && (n ull != table[bucketlndex ]),先扩容后新添加
JDK8则是先添加后扩容
现实中扩容后,get请求赶到死链的slot上,或者put已经形成死链时,get命中,使得服务器运算超出负荷
JDK8的HashMap从头结点就开始操作数据迁移,就是为了规避这一点
如果在JDK8之前,最好记住这些坑,或者用ConcurrentHashMap
ConcurrentHashMap
ConcurrentHashMap是一种并发线程安全的哈希集合,它使用了大量的lockfree 技术
经常会与hashtable进行对比,Hashtable是JDK1.0中的,用全互斥处理并发,性能极差
HashMap是JDK1.2引入的,非线程安全,并发写时容易死链,导致服务不可用
ConcurrentHashMap是JDK1.5引入,JDk8前用分段锁技术,相当于Hashtable和HashMap的折中
分段锁就是一种分开操作,各个segment单独操作,内部不会冲突
JDK11对7的版本有三处变化
1.取消分段锁,降低冲突概率
2.引入红黑树
3.优化统计集合内元素数量的方式,原先size只能到2的32次方减一,现在mappingCount能到2^63-1,元素个数更新时也有CAS和优化办法



从源码中可以总结它的存储结构如下
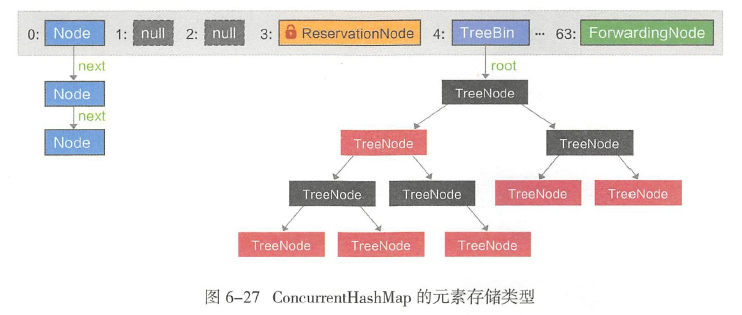
这里table长度64.数据存储结构分为链表或红黑树
槽内元素超过8且table容量大于等于64,链表转为红黑树,table小于64时,只会扩容而不会变链表为红黑树
,转换时先锁住当前槽的首元素,就不会受到其他进程的修改了,之后用CAS替换原链表;如果是红黑树转链表,就只需要遍历节点并且把TreeNode转为Node即可
下图为链表转红黑树过程
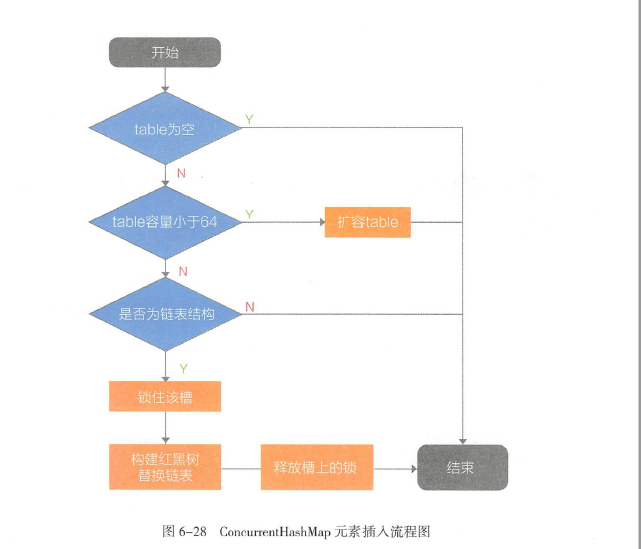
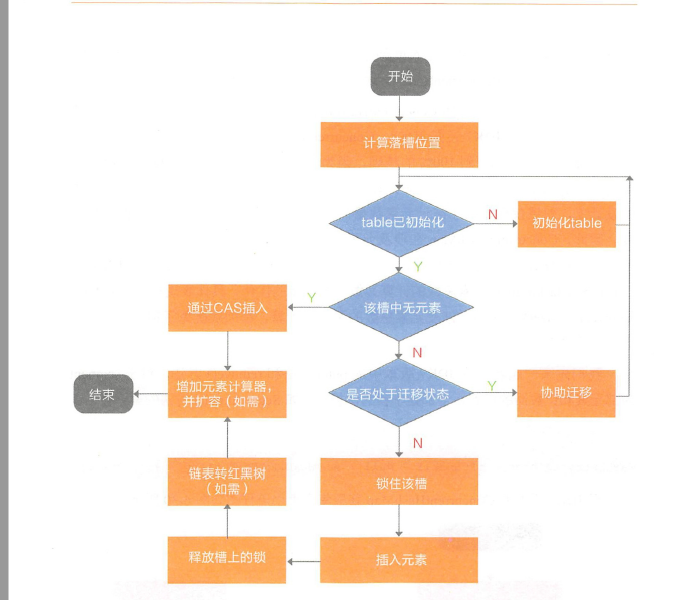
触发转换的操作是put方法,基本思想类似HashMap,多了一个锁的处理
ConcurrentHashMap 元素插入流程如图
Node还有两个子类ForwardingNode 和ReservationNode
前者是table扩容时,原table的槽内放置一个ForwardingNode 节点,它会把find请求转发到扩容后的table上,put方法碰到这个节点也会协助迁移
后者是用来在computeIfAbsent中作为预留节点使用,它会占位加锁,来防止槽被其他线程操作
最后,ConcurrentHashMap优化了计算集合size的方法,之前这个方法是不准确的,因为在计算时也会有增删操作,导致最终结果有差异
,停止操作又会很浪费性能,于是JDK8它主要用CAS代替了锁操作
JDK7之前put和remove方法,segment内部元素和计数器更新都是上锁的

JDK7的ConcurrentHashMap获取集合大小如下
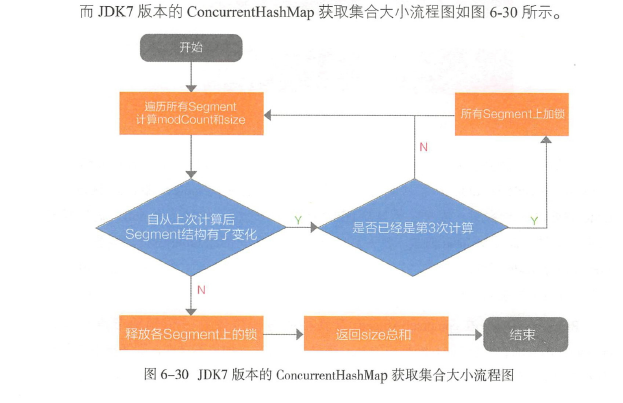
如上图,可以看到,已经尽力避免上锁,但如果3次计算后发现总有结构变化,仍然会上锁
JDk8对获取size的优化用到这些属性

通过baseCount 和counterCells 两个属性,配合多个CAS方法,避免了加锁
思路主要是:
当并发量较小时,优先使用CAS 的方式直接更新baseCount 。
·当更新baseCount 冲突, 会认为进入到比较激烈的竞争状态, 通过启用counterCells 减少竞争, 通过CAS 的方式把总数更新情况记录在counterCells对应的位置上。
·如果更新counterCells 上的某个位置时出现了多次失败, 会通过扩容counterCells 的方式减少冲突。
·当counterCells 处在扩容期间时,会尝试更新baseCount 值。
统计时只需让baseCount加上各个counterCells内数据,就可以得到哈希内元素总数,不需借助锁
这也就是为什么推荐并发使用这个集合进行KV键值对的存储和使用















 3618
3618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









