






近期服务用到了streamsets的rest service 数据源组件,通过相关资料与实践总结出如下, 如有偏差还请指正
streamsets的rest service源数据组件简介
Streamsets是一款大数据实时采集和ETL工具, 最重要的概念就是数据源(Origins)、操作(Processors)、目的地(Destinations); rest service 是一个多线程源,用于处理所有授权的REST API请求。当与同一管道中的一个或多个发送响应一起使用时,源站还可以将带有状态代码的记录发送回源站REST API客户端。
rest service 源是接受http请求,为收到的每个请求生成一个批处理, 即在sdc.properties文件中的production.maxBatchSize值也就会无效, 这个默认值是1000; 因此能有效提升rest service管道的处理吞吐的属性也就落在了maxConcurrentRequests和maxRunners上面;根据并发合理的配置maxConcurrentRequests和maxRunners 尤为重要, 当然也要考虑服务器的cpu
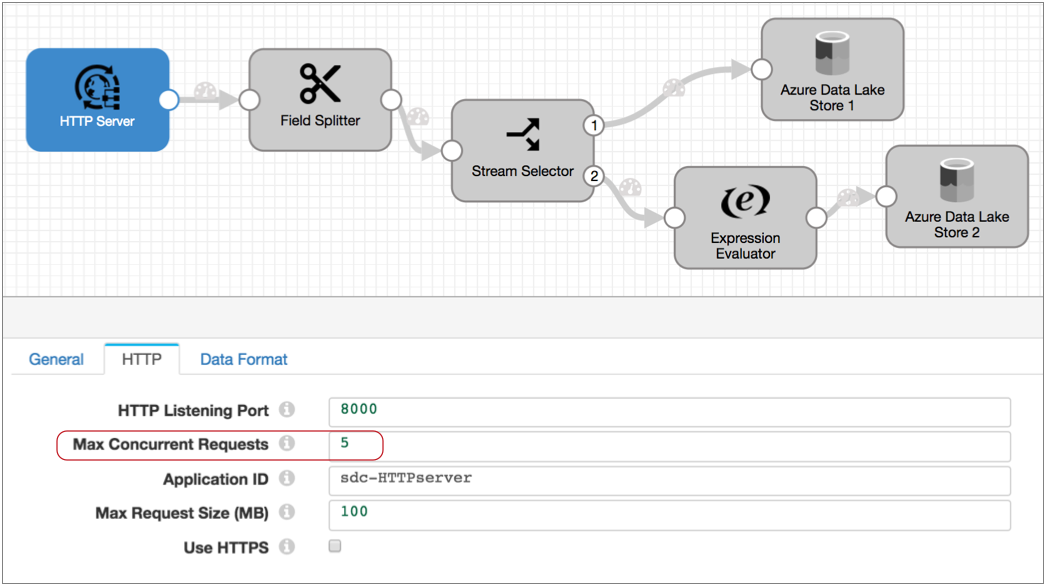
将Max Concurrent Requests设置为5时,启动管道时,原点将创建五个线程,Data Collector将创建五个pipeline runners。收到数据后,源站将批传递给每个管道运行器进行处理。
rest service源使用基于Max concurrent Requests属性的多个并发线程。启动管道时,原点将创建Max Concurrent Requests属性中指定的线程数。每个线程从传入请求生成一个批处理,并将该批处理传递给可用的 pipeline runners。
每个管道运行程序一次处理一个批,就像在单个线程上运行的管道一样。当数据流变慢时,管道运行程序会无所事事地等待,直到需要它们为止,并定期生成一个空批。您可以配置Runner Idle Time pipeline属性以指定间隔或选择退出空批处理生成。
多线程管道保留每个批中记录的顺序,就像单线程管道一样。但由于批处理由不同的管道运行程序处理,因此无法确保将批写入目标的顺序。
例如,假设您将Max Concurrent Requests属性设置为5。启动管道时,原点将创建五个线程,Data Collector将创建匹配数量的 pipeline runners。收到数据后,源站将批传递给每个pipeline runners 进行处理。
每个管道运行器执行与管道其余部分关联的处理。将批写入管道目标后,管道运行程序可用于另一批数据。每个批都会尽快处理和写入,独立于其他管道运行程序处理的其他批,因此批的写入可能与读取顺序不同。
在任何给定时刻,五个管道运行程序都可以处理一个批,因此此多线程管道一次最多处理五个批。当传入数据变慢时,管道运行程序处于空闲状态,一旦数据流增加就可以使用。
streamsets 性能优化
streamSets默认情况下,StreamSets Data Collector可以同时运行大约22个独立管道, 因为streamsets服务 sdc.properties配置文件里的属性runner.thread.pool.size默认值是50 , 如果部署的pipeline增多需要增加runner.thread.pool.size值, 要求条件: runner.thread.pool.size > pipeline数量 x 2.2, 此外增加 runner.thread.pool.size值需要考虑机器cpu是否需要调大
未完待续... ... 后期工作中或学习中有新的理解体会再更新















 1428
1428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









