







SparkSQL jdbc()写入流程分析
导言
在使用SparkSQL自带的jdbc()方法测试ClickHouse的写入性能时,jdbc()写入无法支持Array类型的数据写入。
网上有人说不支持数组写入的原因是SparkSQL的jdbc()方法获取到的是statement连接,而不是preparedStatement连接,因此SparkSQL不支持Array类型的写入。
抛开这个结论的正确性不谈,要想知道jdbc()不支持数组的原因,只要深入Spark的源码,应该就能找到答案了。因此笔者准备用两篇文章记录spark写入clickhouse的具体流程,这篇文章将着重介绍程序入口jdbc()的写入流程。
jdbc()程序的入口
dataFrame
.repartition(1)
.write
.mode("append")
.jdbc(url,clickhouse_table,properties)
上述代码为jdbc()的标准代码,它也可以写成以下形式
dataFrame.write
.format("jdbc")
.mode("append")
.option("dbtable",dbtable)
.option("url",url)
.option("user",user)
.option("password",password)
.save()
从上面两种代码来分析,可以判断,jdbc()方法应该是对save()方法的封装。
下面对jdbc()源码开始逐层分析
def jdbc(url: String, table: String, connectionProperties: Properties): Unit = {
assertNotPartitioned("jdbc")
assertNotBucketed("jdbc")
this.extraOptions ++= connectionProperties.asScala
this.extraOptions += ("url" -> url, "dbtable" -> table)
/**
* 不难发现,jdbc()其实是对save()方法的一层封装
*/
format("jdbc").save()
}
- save()
def save(): Unit = {
......
/**
private var source: String = df.sparkSession.sessionState.conf.defaultDataSourceName
*/
val cls = DataSource.lookupDataSource(source, df.sparkSession.sessionState.conf)
if (classOf[DataSourceV2].isAssignableFrom(cls)) {
val ds = cls.newInstance()
ds match {
case ws: WriteSupport =>
val options = new DataSourceOptions((extraOptions ++
DataSourceV2Utils.extractSessionConfigs(
ds = ds.asInstanceOf[DataSourceV2],
conf = df.sparkSession.sessionState.conf)).asJava)
val jobId = new SimpleDateFormat("yyyyMMddHHmmss", Locale.US)
.format(new Date()) + "-" + UUID.randomUUID()
val writer = ws.createWriter(jobId, df.logicalPlan.schema, mode, options)
if (writer.isPresent) {
runCommand(df.sparkSession, "save") {
WriteToDataSourceV2(writer.get(), df.logicalPlan)
}
}
case _ => saveToV1Source()
}
} else {
saveToV1Source()
}
}
在save()方法内,会调用lookupDataSource()方法对判断当前的Source类型来执行不同的写入方法(WriteToDataSourceV2() 或者 saveToV1Source() )
- lookupDataSource()
lookupDataSource() def lookupDataSource(provider: String, conf: SQLConf): Class[_] = {
val provider1 = backwardCompatibilityMap.getOrElse(provider, provider) match {
case name if name.equalsIgnoreCase("orc") &&
conf.getConf(SQLConf.ORC_IMPLEMENTATION) == "native" =>
classOf[OrcFileFormat].getCanonicalName
case name if name.equalsIgnoreCase("orc") &&
conf.getConf(SQLConf.ORC_IMPLEMENTATION) == "hive" =>
"org.apache.spark.sql.hive.orc.OrcFileFormat"
case name => name
}
val provider2 = s"$provider1.DefaultSource"
val loader = Utils.getContextOrSparkClassLoader
val serviceLoader = ServiceLoader.load(classOf[DataSourceRegister], loader)
try {
serviceLoader.asScala.filter(_.shortName().equalsIgnoreCase(provider1)).toList match {
case Nil =>
Try(loader.loadClass(provider1)).orElse(Try(loader.loadClass(provider2))) match {
case Success(dataSource) =>
......
dataSource
case Failure(error) => .......
}
case head :: Nil => ...... head.getClass
case sources => ....... val internalSources =
sources.filter(_.getClass.getName.startsWith("org.apache.spark"))
internalSources.head.getClass
}
}
- backwardCompatibilityMap()
private val backwardCompatibilityMap: Map[String, String] = {
val jdbc = classOf[JdbcRelationProvider].getCanonicalName
val json = classOf[JsonFileFormat].getCanonicalName
val parquet = classOf[ParquetFileFormat].getCanonicalName
val csv = classOf[CSVFileFormat].getCanonicalName
val libsvm = "org.apache.spark.ml.source.libsvm.LibSVMFileFormat"
val orc = "org.apache.spark.sql.hive.orc.OrcFileFormat"
val nativeOrc = classOf[OrcFileFormat].getCanonicalName
Map(
"org.apache.spark.sql.jdbc" -> jdbc,
"org.apache.spark.sql.jdbc.DefaultSource" -> jdbc,
"org.apache.spark.sql.execution.datasources.jdbc.DefaultSource" -> jdbc,
"org.apache.spark.sql.execution.datasources.jdbc" -> jdbc,
"org.apache.spark.sql.json" -> json,
"org.apache.spark.sql.json.DefaultSource" -> json,
"org.apache.spark.sql.execution.datasources.json" -> json,
"org.apache.spark.sql.execution.datasources.json.DefaultSource" -> json,
"org.apache.spark.sql.parquet" -> parquet,
"org.apache.spark.sql.parquet.DefaultSource" -> parquet,
"org.apache.spark.sql.execution.datasources.parquet" -> parquet,
"org.apache.spark.sql.execution.datasources.parquet.DefaultSource" -> parquet,
"org.apache.spark.sql.hive.orc.DefaultSource" -> orc,
"org.apache.spark.sql.hive.orc" -> orc,
"org.apache.spark.sql.execution.datasources.orc.DefaultSource" -> nativeOrc,
"org.apache.spark.sql.execution.datasources.orc" -> nativeOrc,
"org.apache.spark.ml.source.libsvm.DefaultSource" -> libsvm,
"org.apache.spark.ml.source.libsvm" -> libsvm,
"com.databricks.spark.csv" -> csv
)
}
lookupDataSource()会按照传入的provider的shortNmae()//jdbc去寻找DatasourceRegister的子类,jdbc返回的dataSource应该是 org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider,再把视线放回到save()方法内。


执行的应该是saveToV1Source()方法
- saveToV1Source()
private def saveToV1Source(): Unit = {
// Code path for data source v1.
runCommand(df.sparkSession, "save") {
DataSource(
sparkSession = df.sparkSession,
className = source,
partitionColumns = partitioningColumns.getOrElse(Nil),
options = extraOptions.toMap).planForWriting(mode, AnalysisBarrier(df.logicalPlan))
}
}
saveToV1Source()调用的是planForWriting(mode, AnalysisBarrier(df.logicalPlan))
- planForWriting()
def planForWriting(mode: SaveMode, data: LogicalPlan): LogicalPlan = {
if (data.schema.map(_.dataType).exists(_.isInstanceOf[CalendarIntervalType])) {
throw new AnalysisException("Cannot save interval data type into external storage.")
}
providingClass.newInstance() match {
case dataSource: CreatableRelationProvider =>
SaveIntoDataSourceCommand(data, dataSource, caseInsensitiveOptions, mode)
case format: FileFormat =>
planForWritingFileFormat(format, mode, data)
case _ =>
sys.error(s"${providingClass.getCanonicalName} does not allow create table as select.")
}
}
planForWriting会根据所传入的dataSource,判断执行方法
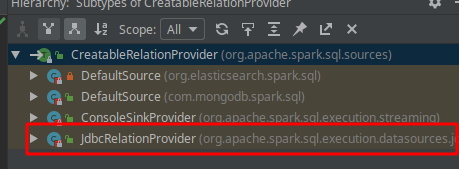
因此调用的应该是SaveIntoDataSourceCommand()
- SaveIntoDataSourceCommand()
case class SaveIntoDataSourceCommand(
query: LogicalPlan,
dataSource: CreatableRelationProvider,
options: Map[String, String],
mode: SaveMode) extends RunnableCommand {
override protected def innerChildren: Seq[QueryPlan[_]] = Seq(query)
override def run(sparkSession: SparkSession): Seq[Row] = {
dataSource.createRelation(
sparkSession.sqlContext, mode, options, Dataset.ofRows(sparkSession, query))
Seq.empty[Row]
}
override def simpleString: String = {
val redacted = Utils.redact(SparkEnv.get.conf, options.toSeq).toMap
s"SaveIntoDataSourceCommand ${dataSource}, ${redacted}, ${mode}"
}
}
执行 createRelation()
- createRelation()
trait CreatableRelationProvider {
/**
* Saves a DataFrame to a destination (using data source-specific parameters)
*
* @param sqlContext SQLContext
* @param mode specifies what happens when the destination already exists
* @param parameters data source-specific parameters
* @param data DataFrame to save (i.e. the rows after executing the query)
* @return Relation with a known schema
*
* @since 1.3.0
*/
def createRelation(
sqlContext: SQLContext,
mode: SaveMode,
parameters: Map[String, String],
data: DataFrame): BaseRelation
}
......
}
我们发现createRelation()是一个trait类内的方法,寻找实现类
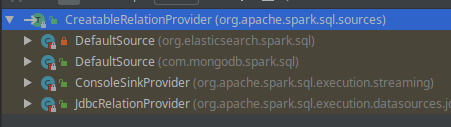
- JdbcRelationProvide()
class JdbcRelationProvider extends CreatableRelationProvider
with RelationProvider with DataSourceRegister {
......
override def createRelation(
sqlContext: SQLContext,
mode: SaveMode,
parameters: Map[String, String],
df: DataFrame): BaseRelation = {
val options = new JDBCOptions(parameters)
val isCaseSensitive = sqlContext.conf.caseSensitiveAnalysis
val conn = JdbcUtils.createConnectionFactory(options)()
try {
val tableExists = JdbcUtils.tableExists(conn, options)
if (tableExists) {
mode match {
case SaveMode.Overwrite =>
if (options.isTruncate && isCascadingTruncateTable(options.url) == Some(false)) {
truncateTable(conn, options)
val tableSchema = JdbcUtils.getSchemaOption(conn, options)
saveTable(df, tableSchema, isCaseSensitive, options)
} else {
dropTable(conn, options.table)
createTable(conn, df, options)
saveTable(df, Some(df.schema), isCaseSensitive, options)
}
case SaveMode.Append =>
val tableSchema = JdbcUtils.getSchemaOption(conn, options)
saveTable(df, tableSchema, isCaseSensitive, options)
......
}
.......
createRelation(sqlContext, parameters)
}
}
可以看到createRelation()内会调用saveTable()
在执行saveTable之前,会调用getSchemaOption()获取表的对象,返回值是一个StructType类。
- saveTable()
def saveTable(
df: DataFrame,
tableSchema: Option[StructType],
isCaseSensitive: Boolean,
options: JDBCOptions): Unit = {
val url = options.url
val table = options.table
val dialect = JdbcDialects.get(url)
val rddSchema = df.schema
val getConnection: () => Connection = createConnectionFactory(options)
val batchSize = options.batchSize
val isolationLevel = options.isolationLevel
val insertStmt = getInsertStatement(table, rddSchema, tableSchema, isCaseSensitive, dialect)
val repartitionedDF = options.numPartitions match {
case Some(n) if n <= 0 => throw new IllegalArgumentException(
s"Invalid value `$n` for parameter `${JDBCOptions.JDBC_NUM_PARTITIONS}` in table writing " +
"via JDBC. The minimum value is 1.")
case Some(n) if n < df.rdd.getNumPartitions => df.coalesce(n)
case _ => df
}
repartitionedDF.rdd.foreachPartition(iterator => savePartition(
getConnection, table, iterator, rddSchema, insertStmt, batchSize, dialect, isolationLevel)
)
}
在saveTable()内,会使用getInsertStatement()方法获取insert的sql语句,导言内的疑问,似乎即将揭晓答案了,而写入操作,在不同分区内循环执行savePartition( )
- getInsertStatement()
def getInsertStatement(
table: String,
rddSchema: StructType,
tableSchema: Option[StructType],
isCaseSensitive: Boolean,
dialect: JdbcDialect): String = {
val columns = if (tableSchema.isEmpty) {
rddSchema.fields.map(x => dialect.quoteIdentifier(x.name)).mkString(",")
} else {
val columnNameEquality = if (isCaseSensitive) {
org.apache.spark.sql.catalyst.analysis.caseSensitiveResolution
} else {
org.apache.spark.sql.catalyst.analysis.caseInsensitiveResolution
}
val tableColumnNames = tableSchema.get.fieldNames
rddSchema.fields.map { col =>
val normalizedName = tableColumnNames.find(f => columnNameEquality(f, col.name)).getOrElse {
throw new AnalysisException(s"""Column "${col.name}" not found in schema $tableSchema""")
}
dialect.quoteIdentifier(normalizedName)
}.mkString(",")
}
val placeholders = rddSchema.fields.map(_ => "?").mkString(",")
s"INSERT INTO $table ($columns) VALUES ($placeholders)"
}
- savePartition()
def savePartition(
getConnection: () => Connection,
table: String,
iterator: Iterator[Row],
rddSchema: StructType,
insertStmt: String,
batchSize: Int,
dialect: JdbcDialect,
isolationLevel: Int): Iterator[Byte] = {
val conn = getConnection()
var committed = false
......
try {
......
val stmt = conn.prepareStatement(insertStmt)
val setters = rddSchema.fields.map(f => makeSetter(conn, dialect, f.dataType))
val nullTypes = rddSchema.fields.map(f => getJdbcType(f.dataType, dialect).jdbcNullType)
val numFields = rddSchema.fields.length
try {
var rowCount = 0
while (iterator.hasNext) {
val row = iterator.next()
var i = 0
while (i < numFields) {
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i)
}
i = i + 1
}
stmt.addBatch()
rowCount += 1
if (rowCount % batchSize == 0) {
stmt.executeBatch()
rowCount = 0
}
}
if (rowCount > 0) {
stmt.executeBatch()
}
} finally {
stmt.close()
}
if (supportsTransactions) {
conn.commit()
}
committed = true
Iterator.empty
}
看到这里,疑问得到了解答,SparkSQL执行sql写入,会利用getInsertStatement()获取insert的SQL语句INSERT INTO $table ($columns) VALUES ($placeholders)
以一个示例来解释此sql语句
//假设一个dataframe的形式为
root
|-- a: string (nullable = true)
|-- b: integer (nullable = true)
|-- c: long (nullable = true)
//那么sql语句便是
INSERT INTO $table (a,b,c) VALUES (?,?,?)
与传统的JDBC preparStatement写入方式一样,spark写入JDBC的方式也是使用占位符插入语句,循环set相应的数据类型,在savePartition()中,执行set操作的则是makeSetter()方法.
def makeSetter(
conn: Connection,
dialect: JdbcDialect,
dataType: DataType): JDBCValueSetter = dataType match {
case IntegerType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setInt(pos + 1, row.getInt(pos))
case LongType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setLong(pos + 1, row.getLong(pos))
case DoubleType =>
(stmt: PreparedStatement, row: Row, pos: Int) =>
stmt.setDouble(pos + 1, row.getDouble(pos))
......
case ArrayType(et, _) =>
// remove type length parameters from end of type name
val typeName = getJdbcType(et, dialect).databaseTypeDefinition
.toLowerCase(Locale.ROOT).split("\\(")(0)
(stmt: PreparedStatement, row: Row, pos: Int) =>
val array = conn.createArrayOf(
typeName,
row.getSeq[AnyRef](pos).toArray)
stmt.setArray(pos + 1, array)
case _ =>
(_: PreparedStatement, _: Row, pos: Int) =>
throw new IllegalArgumentException(
s"Can't translate non-null value for field $pos")
}
可以看到,makeSetter()方法内是有ArrayType()的写入方式的,那么为什么jdbc()写入数组时会抛出异常呢?
def getCommonJDBCType(dt: DataType): Option[JdbcType] = {
dt match {
case IntegerType => Option(JdbcType("INTEGER", java.sql.Types.INTEGER))
case LongType => Option(JdbcType("BIGINT", java.sql.Types.BIGINT))
case DoubleType => Option(JdbcType("DOUBLE PRECISION", java.sql.Types.DOUBLE))
case FloatType => Option(JdbcType("REAL", java.sql.Types.FLOAT))
case ShortType => Option(JdbcType("INTEGER", java.sql.Types.SMALLINT))
case ByteType => Option(JdbcType("BYTE", java.sql.Types.TINYINT))
case BooleanType => Option(JdbcType("BIT(1)", java.sql.Types.BIT))
case StringType => Option(JdbcType("TEXT", java.sql.Types.CLOB))
case BinaryType => Option(JdbcType("BLOB", java.sql.Types.BLOB))
case TimestampType => Option(JdbcType("TIMESTAMP", java.sql.Types.TIMESTAMP))
case DateType => Option(JdbcType("DATE", java.sql.Types.DATE))
case t: DecimalType => Option(
JdbcType(s"DECIMAL(${t.precision},${t.scale})", java.sql.Types.DECIMAL))
case _ => None
}
}
private def getJdbcType(dt: DataType, dialect: JdbcDialect): JdbcType = {
dialect.getJDBCType(dt).orElse(getCommonJDBCType(dt)).getOrElse(
throw new IllegalArgumentException(s"Can't get JDBC type for ${dt.simpleString}"))
}
我们进入getJdbcType()方法不难发现,数组类型调用的是getCommonJDBCType(),而在此方法内,并没有添加ArrayType的case。















 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









