







目录
一、TiKV 介绍
TiKV 是一个分布式事务型的键值数据库,提供了满足 ACID 约束的分布式事务接口,并且通过 Raft 协议保证了多副本数据一致性以及高可用。TiKV 作为 TiDB 的存储层,为用户写入 TiDB 的数据提供了持久化以及读写服务,同时还存储了 TiDB 的统计信息数据。
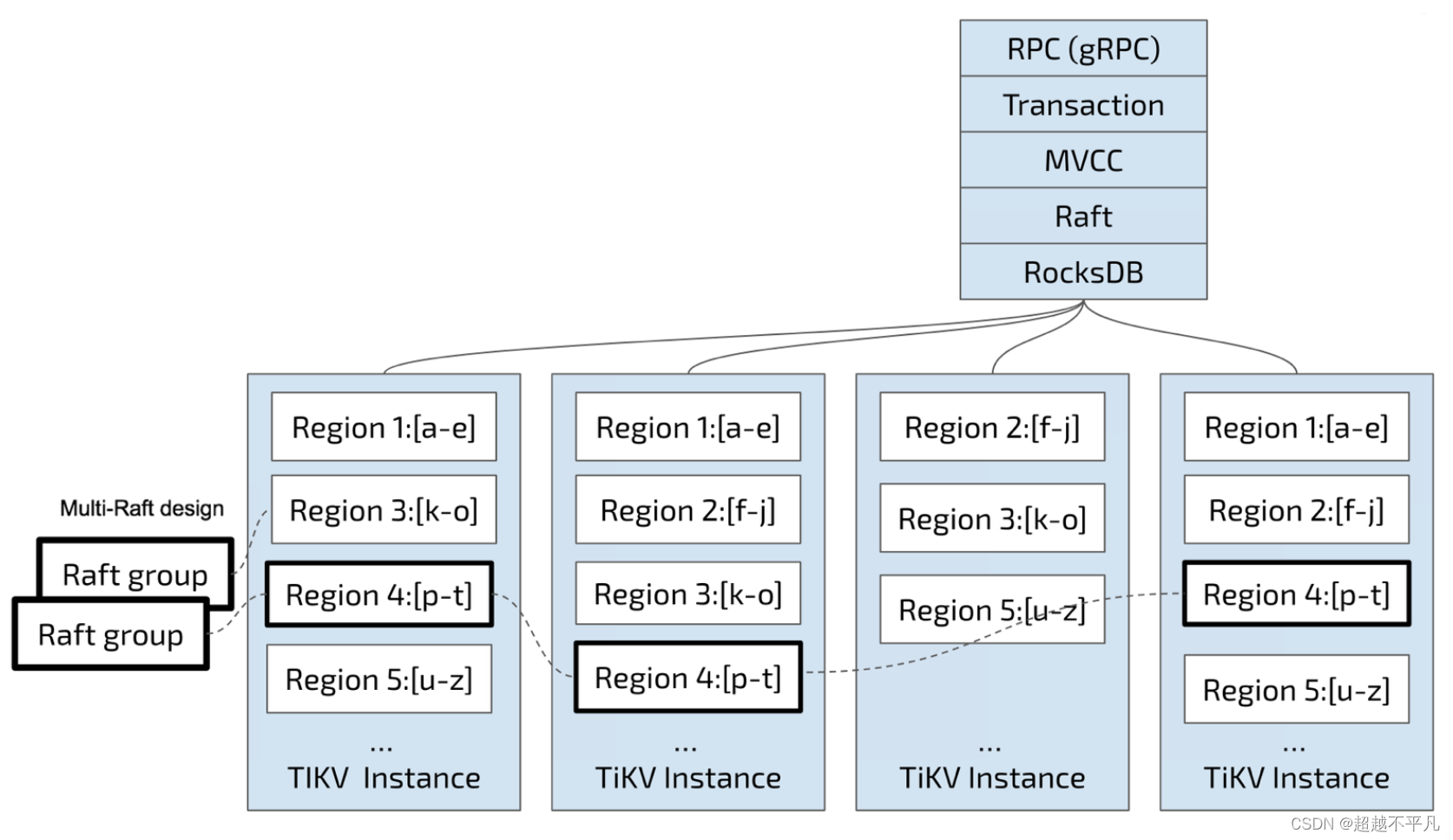
与传统的整节点备份不同,TiKV 参考了 Spanner 设计了 multi-raft-group 的副本机制。将数据按照 key 的范围划分成大致相等的切片(region),每一个切片会有多个副本(默认3个),其中一个副本是 leader,提供读写服务。TiKV 通过 PD 对这些 Region 以及副本进行调度,以保证数据和读写负载都均匀的分散在各个 TiKV 上,这样的设计保证了整个集群资源的充分利用并且可以随着机器数量的增加水平扩展。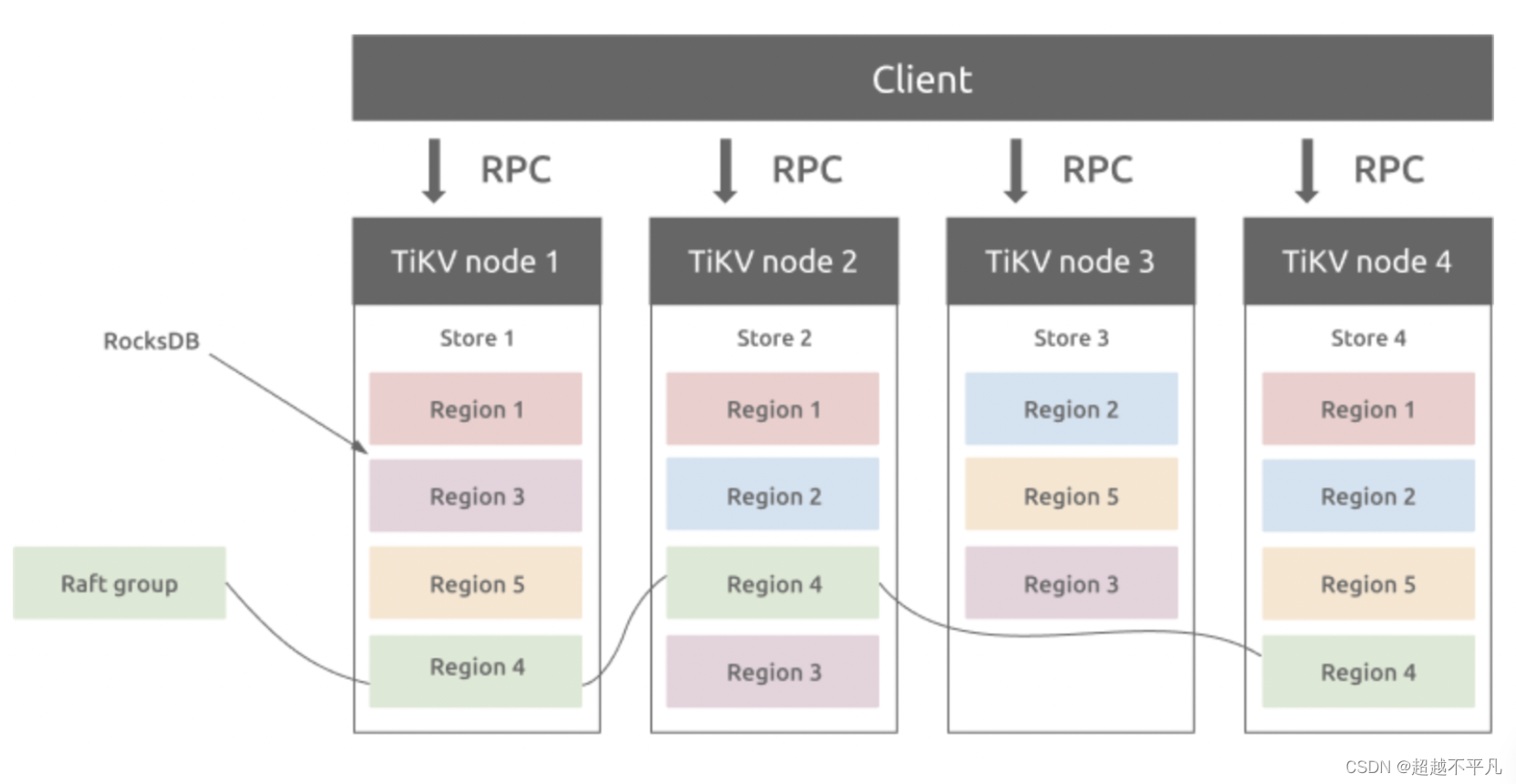
任何持久化的存储引擎,数据终归要保存在磁盘上,TiKV 也不例外。但是 TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。
二、RocksDB
TiKV 为何选择 RocksDB 来存储数据呢?
这个选择的原因是开发一个单机存储引擎工作量很大,特别是要做一个高性能的单机引擎,需要做各种细致的优化,而 RocksDB 是由 Facebook 开源的一个非常优秀的单机 KV 存储引擎,可以满足 TiKV 对单机引擎的各种要求。这里可以简单的认为 RocksDB 是一个单机的持久化 Key-Value Map。
RocksDB 是由 Facebook 基于 LevelDB 开发的一款提供键值存储与读写功能的 LSM-tree 架构引擎。用户写入的键值对会先写入磁盘上的 WAL(Write Ahead Log),然后再写入内存中的跳表。LSM-tree 由于将用户的随机修改(插入)转化为对 WAL 的顺序写,因此具有比 B 树类存储引擎更高的写吞吐。
内存中的数据达到一定阈值后,会刷到磁盘上生成 SST 文件(Sorted String Table),SST 又分为多层(默认最多6层),每一层的数据达到一定阈值后会挑选一部分 SST 合并到下一层,每一层的数据是下一层的10倍(因此 90% 的数据存储在最后一层)。 
操作流程如下:
- 新写入的数据首先被写入 memtable,而非直接写入磁盘。这种设计极大地减少了磁盘 I/O,降低了写入延迟,尤其适合需要频繁写入和快速响应的应用场景。
- memtable 有固定的内存容量限制,由参数 write_buffer_size 控制。当 memtable 的大小接近或达到这一限制时,RocksDB 会触发以下动作:
- 转换为 Immutable Memtable:当前 memtable 被标记为不可变(Immutable),新的写入操作会被导向到一个新的 memtable。
- Flush 到 SSTable:后台线程将 Immutable Memtable 中的数据序列化并写入磁盘,形成一个 SSTable(Sorted String Table),这是一个持久化的、经过排序的键值对集合。
- WAL 更新:在 memtable 数据写入磁盘的过程中,RocksDB 会维护 Write Ahead Log (WAL, 也称预写日志),确保即使在崩溃或意外关机的情况下,尚未持久化的 memtable 数据也能通过回放 WAL 重建。
- RocksDB 支持多列族(Column Family),每个列族都有自己独立的 memtable。这意味着不同的数据集可以有不同的存储配置和访问模式,进一步提升了存储灵活性和查询效率。
三、TiKV 与 RocksDB 架构
RocksDB作为TiKV的核心存储引擎,用于存储Raft日志以及用户数据。每个TiKV实例中有两个RocksDB,一个用于存储Raft日志(通常被称为 raftdb),另一个用于存储用户数据以及MVCC信息(通常被称为 kvdb)。

为什么需要两个 RocksDB呢?
在 TiKV 中,使用两个 RocksDB 实例对应的是其内部的存储结构设计。具体来说,TiKV 将数据分为两部分存储:KV 数据(键值对数据)和 Raft Log 数据,分别使用两个独立的 RocksDB 实例进行管理。这种设计的目的是为了清晰分离不同性质的数据,并针对性地进行优化,确保系统的高效运行。
将二者分离的主要目的如下:
- 隔离负载:不同类型的操作,有不同的性能要求和访问模式,分开存储可以避免互相干扰,提高整体系统的稳定性和效率。
- 精细化管理:针对各自的特点进行定制化的配置和优化,如调整压缩算法、缓存策略、自如放大控制等,以适应各自的工作负载。
- 简化故障恢复:在节点故障或数据迁移时,可以独立地处理 KV 数据和 Raft Log,简化恢复流程,提高恢复速度。
3.1 用户数据保存
上面提到 RocksDB 支持多列族(Column Family),TiKV 使用 RocksDB 保存数据时使用了四个列族,分别是:raft、lock、default和write。
Raft 列族:用于存储各个 Region 的元信息。仅占极少空间,可以无需关注。
lock 列族:用于存储悲观事务的悲观锁以及分布式事务的一阶段 Prewrite 锁。当用户的事务提交之后,lock Column Family 中对应的数据会很快删除掉,因此大部分情况下,lock Column Family 中的数据也很少。如果 lock Column Family 中数据大量增加,说明有大量事务等待提交,系统出现了故障或 bug。
write 列族:用于存储用户真实写入的数据以及 MVCC 信息,当用户写入了一行数据时,如果改行长度小于 255 字节,那么会被存储 write 列中,否则的话该行会被存入 default 列中。由于 TiDB 的非 unique 索引存储的 value 为空,unique 索引存储的 value 为主键索引,因此二级索引只会占用 write Column Family 的空间。
default 列族:用于存储超过 255 字节长度的数据。
3.2 TiKV 中 Region
为了实现存储的水平扩展,数据将被分散在多台机器上。对于一个 KV 系统,将数据分散在多台机器上有两种比较典型的方案:
- Hash:按照 Key 做 Hash,根据 hash 值选择对应的存储节点
- Range:按照 Key 分 Range,某一段连续的 Key 都保存在一个存储节点上
TiKV 选择了第二种方式,将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,将每一段叫做一个 Region,可以用[StartKey, EndKey)这样一个左闭右开区间来描述。每个Region 中保存的数据量默认维持在 96MiB(可通过配置修改)。
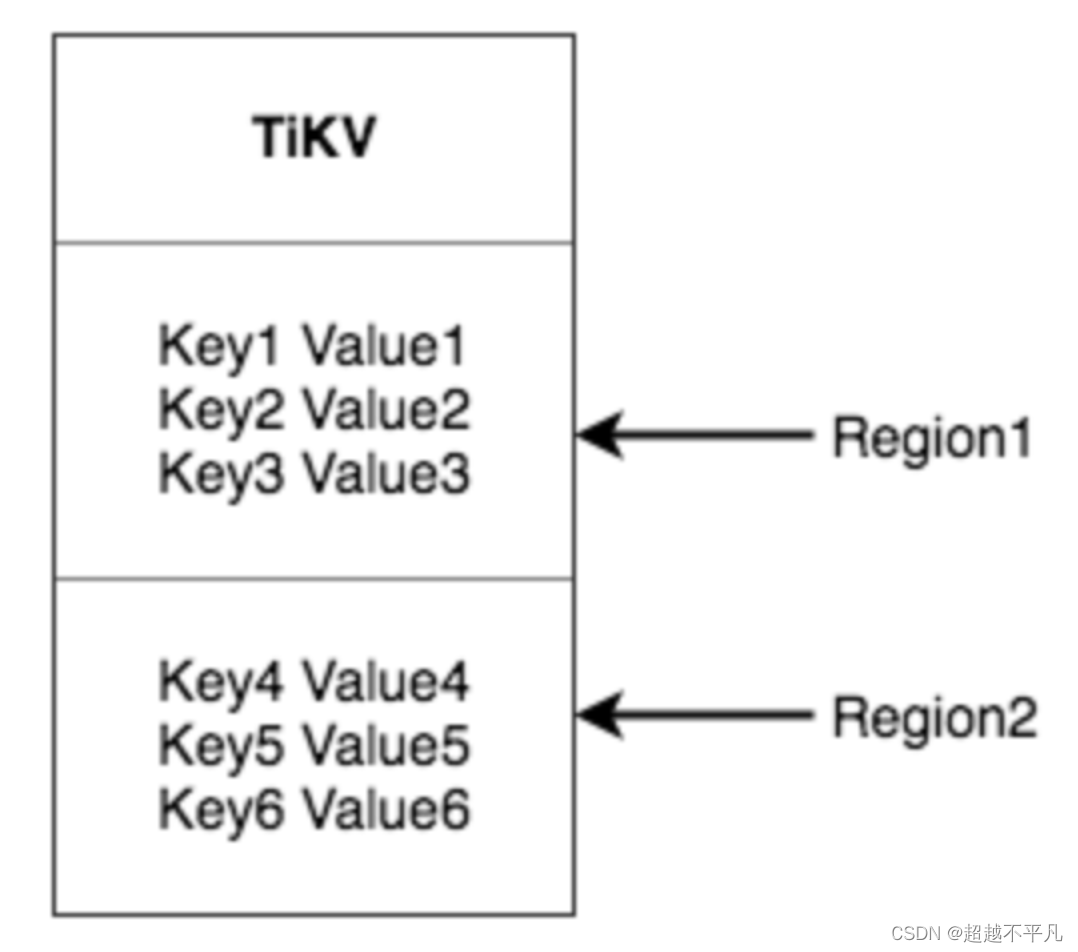
数据按照 Key 切分成很多 Region,每个 Region 的数据只会保存在一个节点上面(暂不考虑多副本)。TiDB 系统会有一个组件 (PD) 来负责将 Region 尽可能均匀的散布在集群中所有的节点上,这样一方面实现了存储容量的水平扩展(增加新的节点后,会自动将其他节点上的 Region 调度过来),另一方面也实现了负载均衡(不会出现某个节点有很多数据,其他节点上没什么数据的情况)。同时为了保证上层客户端能够访问所需要的数据,系统中也会有一个组件 (PD) 记录 Region 在节点上面的分布情况,也就是通过任意一个 Key 就能查询到这个 Key 在哪个 Region 中,以及这个 Region 目前在哪个节点上(即 Key 的位置路由信息)。
TiKV 是以 Region 为单位做数据的复制,也就是一个 Region 的数据会保存多个副本,TiKV 将每一个副本叫做一个 Replica。Replica 之间是通过 Raft 来保持数据的一致,一个 Region 的多个 Replica 会保存在不同的节点上,构成一个 Raft Group。其中一个 Replica 会作为这个 Group 的 Leader,其他的 Replica 作为 Follower。默认情况下,所有的读和写都是通过 Leader 进行,读操作在 Leader 上即可完成,而写操作再由 Leader 复制给 Follower。
以 Region 为单位做数据的分散和复制,TiKV 就成为了一个分布式的具备一定容灾能力的 KeyValue 系统,不用再担心数据存不下,或者是磁盘故障丢失数据的问题。
往期经典推荐
深入浅出 TiDB MVCC:揭秘分布式数据库中的多版本并发控制-CSDN博客
MySQL文件系统解密:binlog、redolog与undolog如何守护数据安全与一致性_mysqlbin 解密-CSDN博客
















 1129
1129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











