







1.协同过滤算法
协同过滤,即Collaborative Filtering,简称CF。
协同过滤是在海量数据中挖掘出小部分与你品味类似的用户,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的东西组织成一个排序的目录推荐给你。所以就有两个核心问题:①如何确定一个用户是否与你有相似的品味②如何将邻居们的喜好组织成一个排序目录。
关于协同过滤的一个最经典的例子就是看电影,有时候不知道哪一部电影是我们喜欢的或者评分比较高的,那么通常的做法就是问问周围的朋友,看看最近有什么好的电影推荐。在问的时候,都习惯于问跟自己口味差不多的朋友,这就是协同过滤的核心思想。
协同过滤算法的出现标志着推荐系统的产生,协同过滤算法包括基于用户和基于物品的协同过滤算法。
2.协同算法分类
(1)协同过滤算法按照数据使用,可以分为:
①基于用户(UserCF);
②基于商品(ItemCF);
③基于模型(ModelCF)。
(2)按照模型,又可以分为:
①最近邻模型:基于距离的协同过滤算法;
②Latent Factor Mode(SVD):基于矩阵分解的模型;
③Graph:图模型,社会网络图模型。
3. 协同过滤的核心
要实现协同过滤,需要进行如下几个步骤
①收集用户偏好
②找到相似的用户或者物品
③计算并推荐
(1)收集用户偏好
从用户的行为和偏好中发现规律,并基于此进行推荐,所以如何收集用户的偏好信息成为系统推荐效果最基础的决定因素。用户有很多种方式向系统提供自己的偏好信息,比如:评分,投票,转发,保存书签,购买,点击流,页面停留时间等等。
以上的用户行为都是通用的,在实际推荐引擎设计中可以自己多添加一些特定的用户行为,并用它们表示用户对物品的喜好程度。通常情况下,在一个推荐系统中,用户行为都会多于一种,那么组合这些不同的用户行为的方式基本上有如下两种:
①将不同的行为分组
一般可以分为查看和购买,然后基于不同的用户行为,计算不同用户或者物品的相似度。类似与当当网或者亚马逊给出的“购买了该书的人还购买了”,“查看了该书的人还查看了”等等。
②不同行为产生的用户喜好对它们进行加权
对不同行为产生的用户喜好进行加权,然后求出用户对物品的总体喜好。
当我们收集好用户的行为数据后,还要对数据进行预处理,最核心的工作就是减噪和归一化。
①减噪:因为用户数据在使用过程中可能存在大量噪音和误操作,所以需要过滤掉这些噪音。
②归一化:不同行为数据的取值相差可能很好,例如用户的查看数据肯定比购买数据大得多。通过归一化,才能使数据更加准确。
通过上述步骤的处理,就得到了一张二维表,其中一维是用户列表,另一维是商品列表,值是用户对商品的喜
好。还是以电影推荐为例,如下表
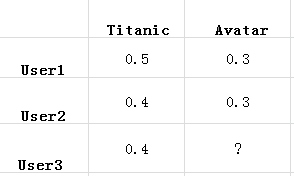
(2)找到相似的用户或物品
对用户的行为分析得到用户的喜好后,可以根据用户的喜好计算相似用户和物品,然后可以基于相似用户或物品进行推荐。这就是协同过滤中的两个分支了,基于用户的和基于物品的协同过滤。
关于相似度的计算有很多种方法,比如常用的余弦夹角,欧几里德距离度量,皮尔逊相关系数等等。而如果采
用欧几里德度量,那么可以用如下公式来表示相似度
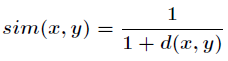
在计算用户之间的相似度时,是将一个用户对所有物品的偏好作为一个向量,而在计算物品之间的相似度时,是将所有用户对某个物品的偏好作为一个向量。求出相似度后,接下来可以求相似邻居了。
(3)计算并推荐
在上面,我们求出了相邻用户和相邻物品,接下来就应该进行推荐了。当然从这一步开始,分为两方面,分别
是基于用户的协同过滤和基于物品的协同过滤。我会分别介绍它们的原理
①基于用户的协同过滤算法
在上面求相似邻居的时候,通常是求出TOP K邻居,然后根据邻居的相似度权重以及它们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表进行推荐。
②基于物品的协同过滤算法
跟上述的基于用户的协同过滤算法类似,但它从物品本身,而不是用户角度。比如喜欢物品A的用户都喜欢物品C,那么可以知道物品A与物品C的相似度很高,而用户C喜欢物品A,那么可以推断出用户C也可能喜欢物品C。如下图
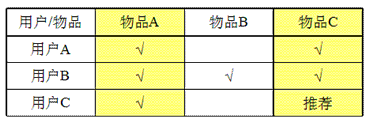
上面的相似度权重有时候需要加入惩罚因子,举个例子,在日常生活中,我们每个人购买卫生纸的的频率比较高,但是不能说明这些用户的兴趣点相似,但是如果它们都买了照相机,那么就可以大致推出它们都是摄影爱好者。所以像卫生纸这样的物品在计算时,相似度权重需要加上惩罚因子或者干脆直接去掉这类数据。
4.适用场景
对于一个在线网站,用户的数量往往超过物品的数量,同时物品数据相对稳定,因此计算物品的相似度不但计算量小,同时不必频繁更新。但是这种情况只适用于电子商务类型的网站,像新闻类,博客等这类网站的系统推荐,情况往往是相反的,物品数量是海量的,而且频繁更新。所以从算法复杂度角度来说,两种算法各有优势。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









