






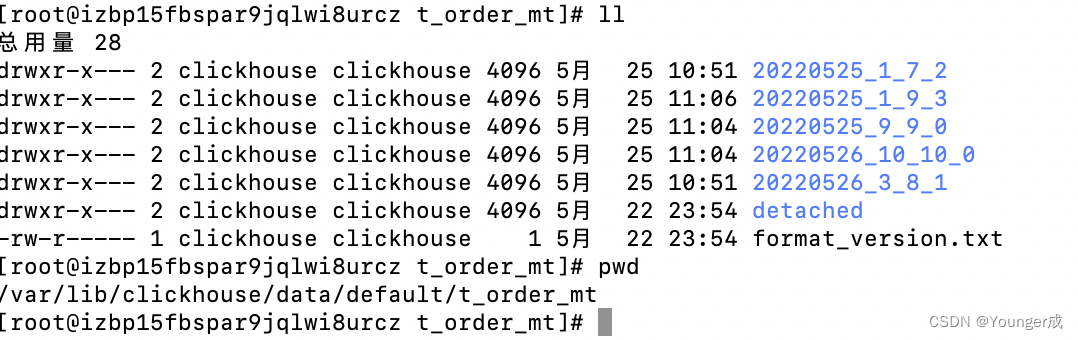
1、表引擎存储位置:/var/lib/clickhouse/data

建表语句存储位置:/var/lib/clickhouse/metadata

2、表引擎的使用
注意:引擎名称驼峰式
TinyLog:
列文件形式保存、不支持索引、没有并发控制、一般保存少量的数据
使用场景:测试环境
create table t_tinylog(id String,name String) engine=TinyLog; Memory:
Memory:
内存引擎,基于内存特点:快、缺点:重启宕机时数据消失。简单查询上达到最大速率(超过10 GB /秒),因为没有磁盘读取,不需要解压缩或反序列化数据。
使用场景:测试环境
MergeTree
ClickHouse中最强大的表引擎MergeTree(合并树)以及该系列的其他引擎,支持索引和分区
创建表:(order by是必须字段,参考官方文档api)
CREATE TABLE t_order_mt (
id UInt32,
sku_id String,
total_amount DECIMAL ( 16, 2 ),
create_time Datetime
) ENGINE = MergeTree ( ) PARTITION BY toYYYYMMDD ( create_time ) PRIMARY KEY id
ORDER BY
( id, sku_id );partition by分区(可选,如果不填吗,默认使用一个分区)
作用:降低扫描的范围、优化查询速度
在该引擎中没有唯一id,查询数据结果的时候,只有用原生连接工具才能看到分区效果,第三方客户端无法看到分区效果
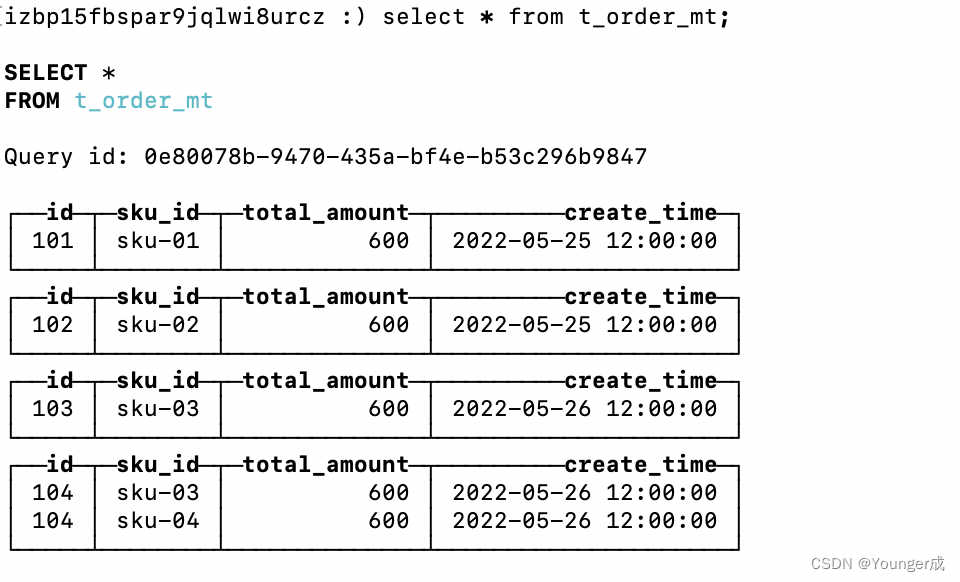
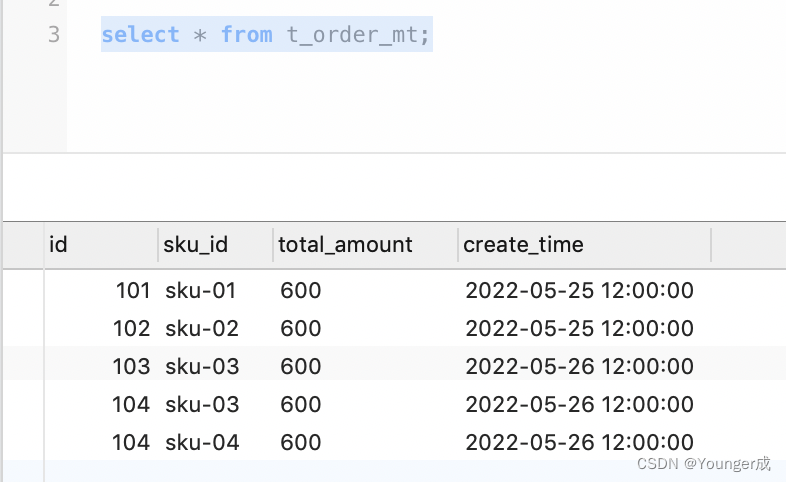
数据存储的位置:
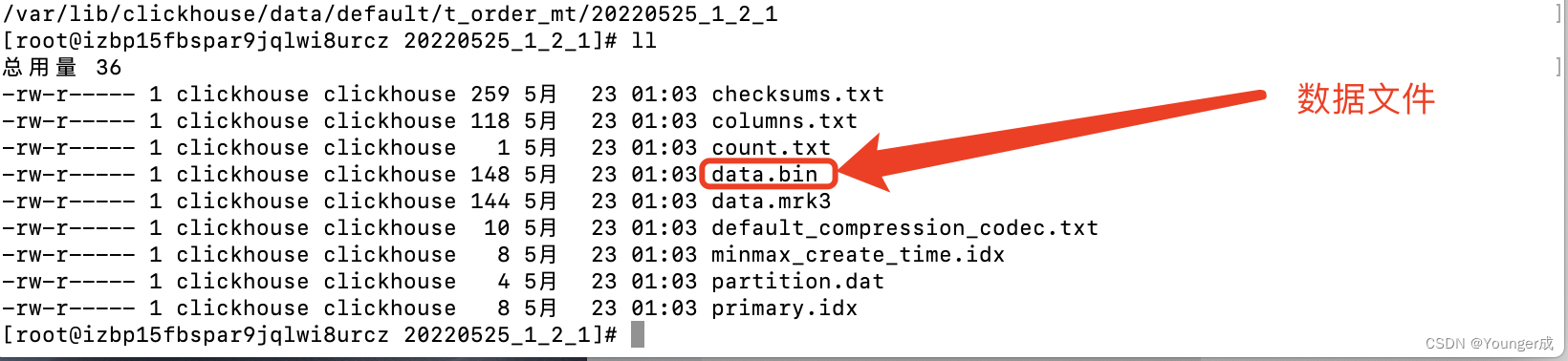
bin文件:数据文件
mrk文件:标记文件
标记文件再idx索引文件和bin数据文件之间起到了桥梁作用
以mrk2结尾的文件,表示该v 表启用了自适应索引间隔
primary.idx文件:主键索引文件,用于加快查询效率
minmax_create_time.idx:分区键的最大最小值
checksums.txt:校验文件,用于校验各个文件的正确性,存放各个文件的size以及hash值
数据写入和分区合并
任何一个批次都会产生一个临时分区,不会纳入已有的分区。
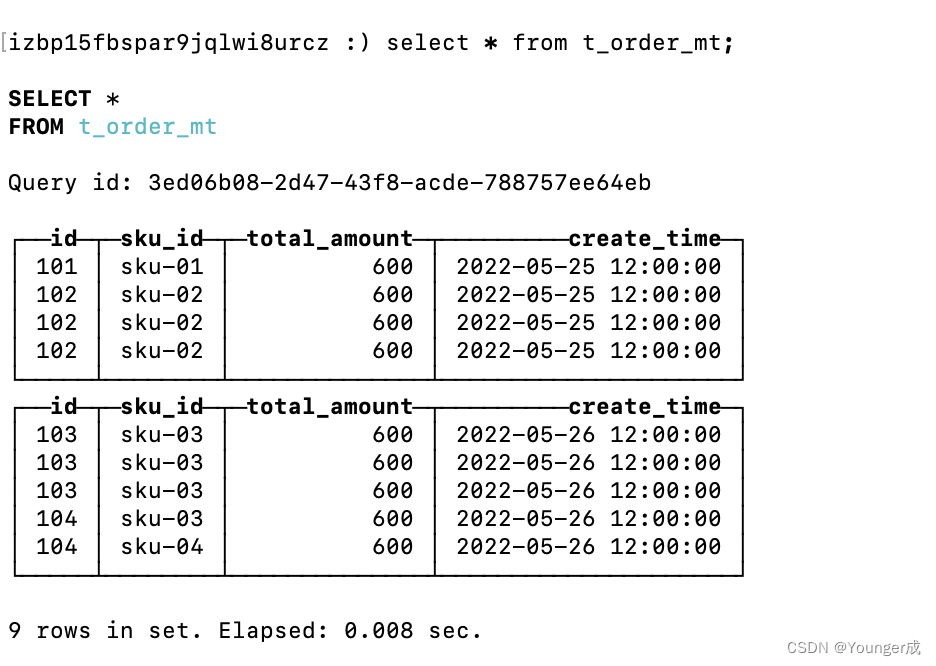
自动合并分区:写入后的某个时刻(大概10-15分钟),clickhouse会自动执行合并操作(也可以手动通过optimize执行)把临时分区的数据,合并到已有分区
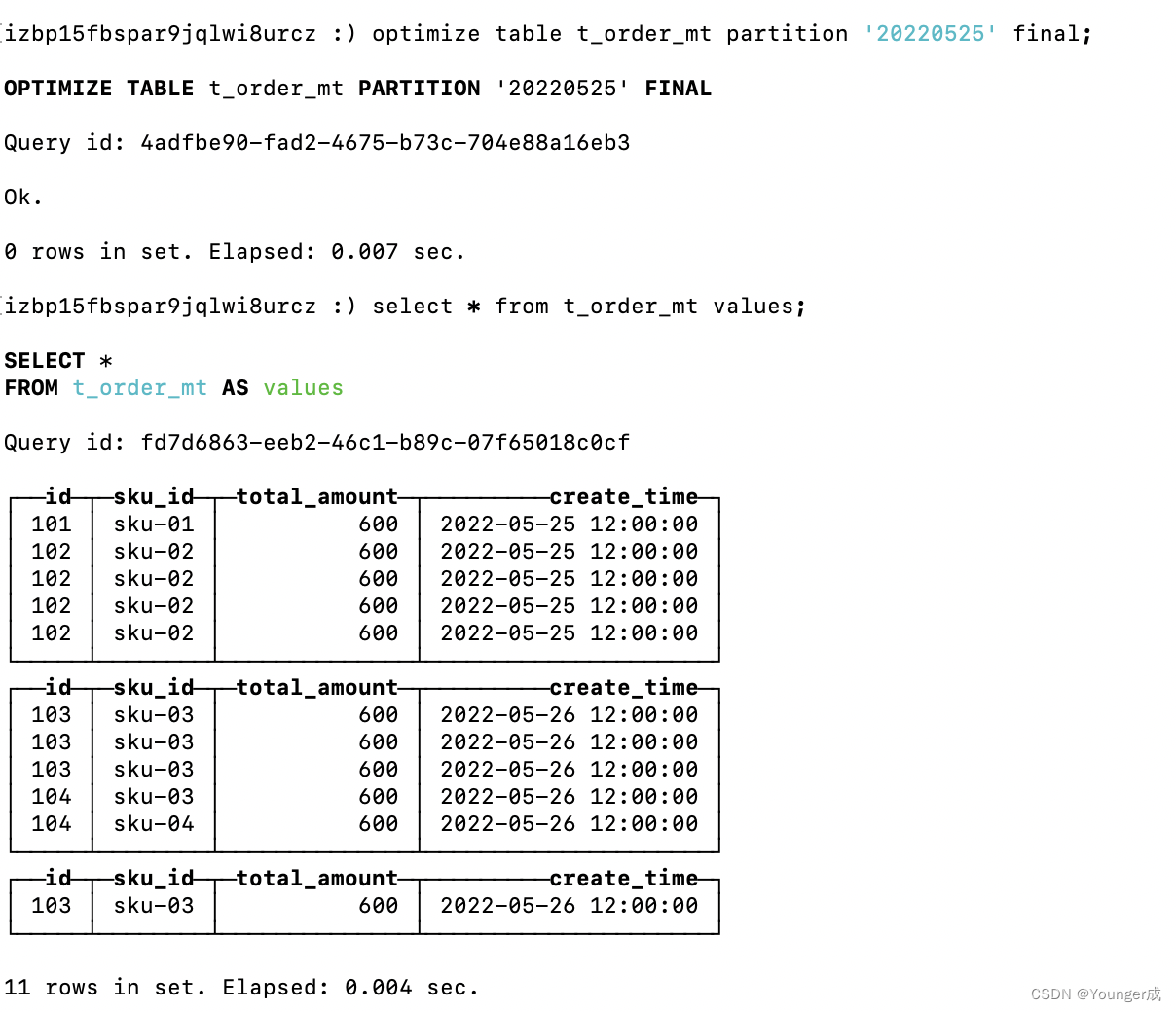
手动合并分区:optimize table t_order_mt final;
效果如下:
只针对某个分区进行合并:optimize table t_order_mt partition '20220525' final;















 4163
4163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









