







 这篇博客主要探讨了使用强化学习进行视觉对象检测的方法,基于PASCAL VOC 2012数据集。论文详细介绍了训练过程,包括action=done和action=fixation的决策机制,以及预期奖励函数和梯度。网络结构通过不断迭代和观察区域历史来优化检测。最后,提到了作者后续在2018年的相关工作。
这篇博客主要探讨了使用强化学习进行视觉对象检测的方法,基于PASCAL VOC 2012数据集。论文详细介绍了训练过程,包括action=done和action=fixation的决策机制,以及预期奖励函数和梯度。网络结构通过不断迭代和观察区域历史来优化检测。最后,提到了作者后续在2018年的相关工作。
1. 数据集
PASCAL VOC 2012
2. 网络
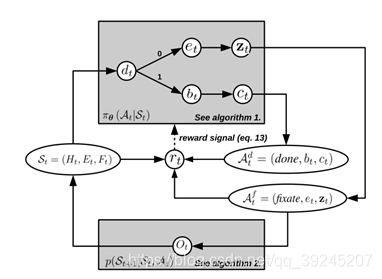
检测整体流程如图。从当前检测区域的状态描述St开始,分类器会对当前状态进行评估并给出终止信号。如果终止信号0,则选取新的evidence region(et)并以et为参考输出下一步需要执行的动作,并观察执行效果得到新的状态。如果终止信号为1,说明当前区域包含有需要检测的目标,此时将依据信度最高的窗口执行选定bounding box的动作。并退出迭代。
2.1 训练
刚开始的时候,由选择区域生成region——25000个,然后用CPMC方法产生region proposal,经过Conv layer。

其中, Ht+1=Ht∪{ Ot}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









