







1.Introduction
作者认为attention机制在当前的图像描述encoder/decoder框架中广泛使用,其中在每个时间步生成编码矢量的加权平均值以指导描述的解码过程。但是,解码器几乎不了解相关向量和给定attention查询之间的关系或关联程度如何,这可能会使解码器给出错误的结果。在本论文中,作者提出了一个“Attention on Attention”(AoA)模块,该模块扩展了常规的注意力机制,以确定注意力结果和查询结果的相关性。AoA首先使用注意力结果和当前的上下文生成一个“信息向量(information vector)”和一个“注意力门(attention gate)”,然后通过对它们进行逐元素乘法来增加另外一个注意力,最终获得“关注信息”,即预期的有用知识。我们将AoA应用于描述模型的编码器和解码器中,将其命名为AoA Network(AoANet)。实验表明,AoANet的性能优于以前发布的所有方法。
2.网络框架介绍
下图展示了“Attention on Attention”(AoA)模块,AoA使用注意力结果和注意力查询生成信息向量和注意力门,并通过将门应用于信息来添加另一个注意并获得关注信息。
将AoA应用于编码器和解码器,以组成AoANet,在编码器中,AoA有助于更好地建模图像中不同对象之间的关系,在解码器中,AoA过滤掉无关的注意力结果,仅保留有用的结果,下面进行详细分析该框架。
2.1 Attention on Attention
2.2 AoANet for Image Captioning
作者基于编码器/解码器框架(下图)构建图像描述模型AoANet,其中编码器和解码器都与AoA模块结合在一起。
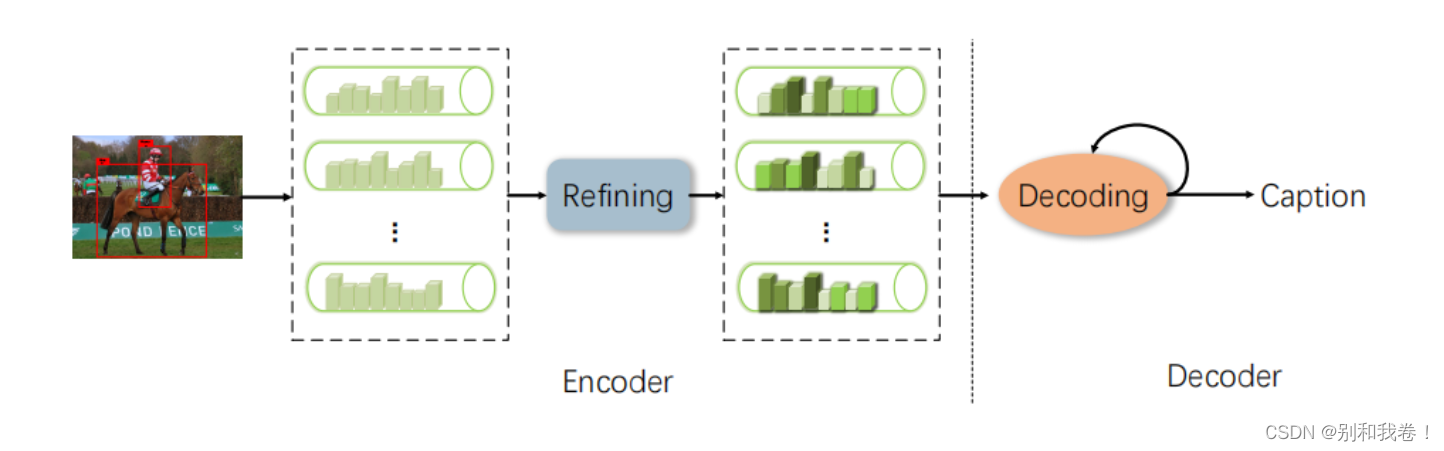
1.Encoder with AoA
对于图像,我们首先使用基于CNN或R-CNN的网络提取一组特征向量A={a1,a2,a3.....ak},其中ai∈RD,(D是每个向量的维度),k是A中的向量数。我们没有直接将这些向量输送给解码器,而是构建了一个包含AoA模块的网络,以优化它们的表示,如下图所示。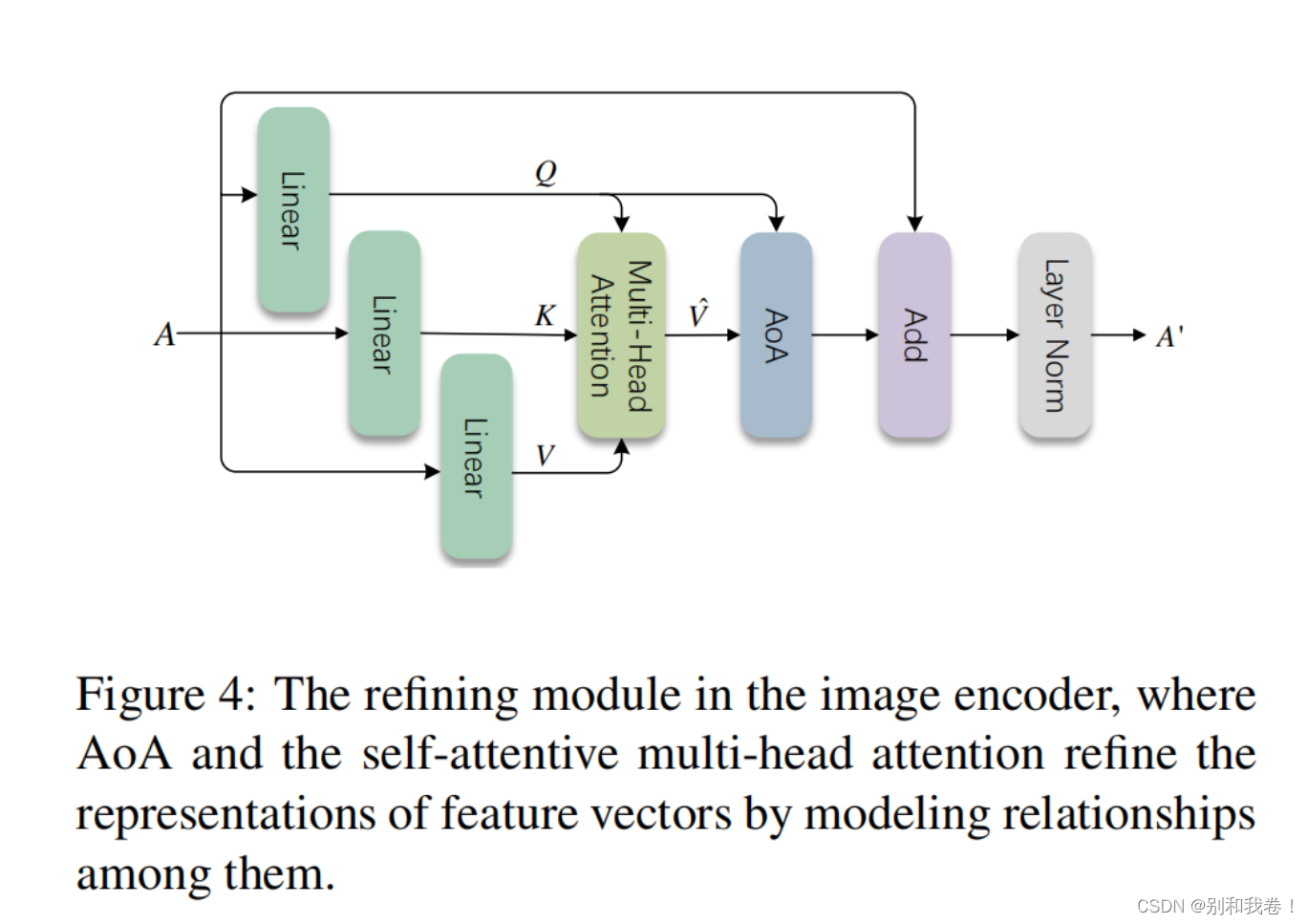
编码器的AOA模块,成为AOAe,采用多头注意函数,其中Q,K和V,是特征向量A的三个单独的先行投影。AOA模块之后的是残差连接和层规范化。
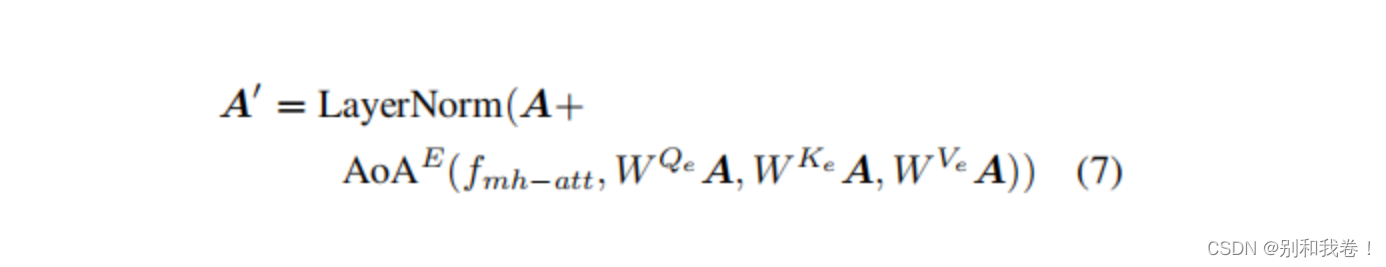

在这个优化模块中,自注意多头注意模块(self-attentive muti-head attention module)在图像中的对象之间寻找相互作用,并使用AoA来衡量它们之间的关联程度。优化后,更新特征向量。优化模块不会更改A的尺寸,因此可以堆叠N次(本文中N=6)。
注意,优化模块采用与Transformer编码器不同的结构,因为前者前馈层被丢弃,而我们前馈层是可选择丢弃的,作出这一改变的原因有以下两个:1)增加前馈层以提供非线性表示,这也是通过应用AoA实现的;2)丢弃前馈层不会改变AoANet的性能,但会简化操作。
2.Decoder with AoA
解码器(如下图所示)使用优化的特征向量 A 来生成描述 y 序列。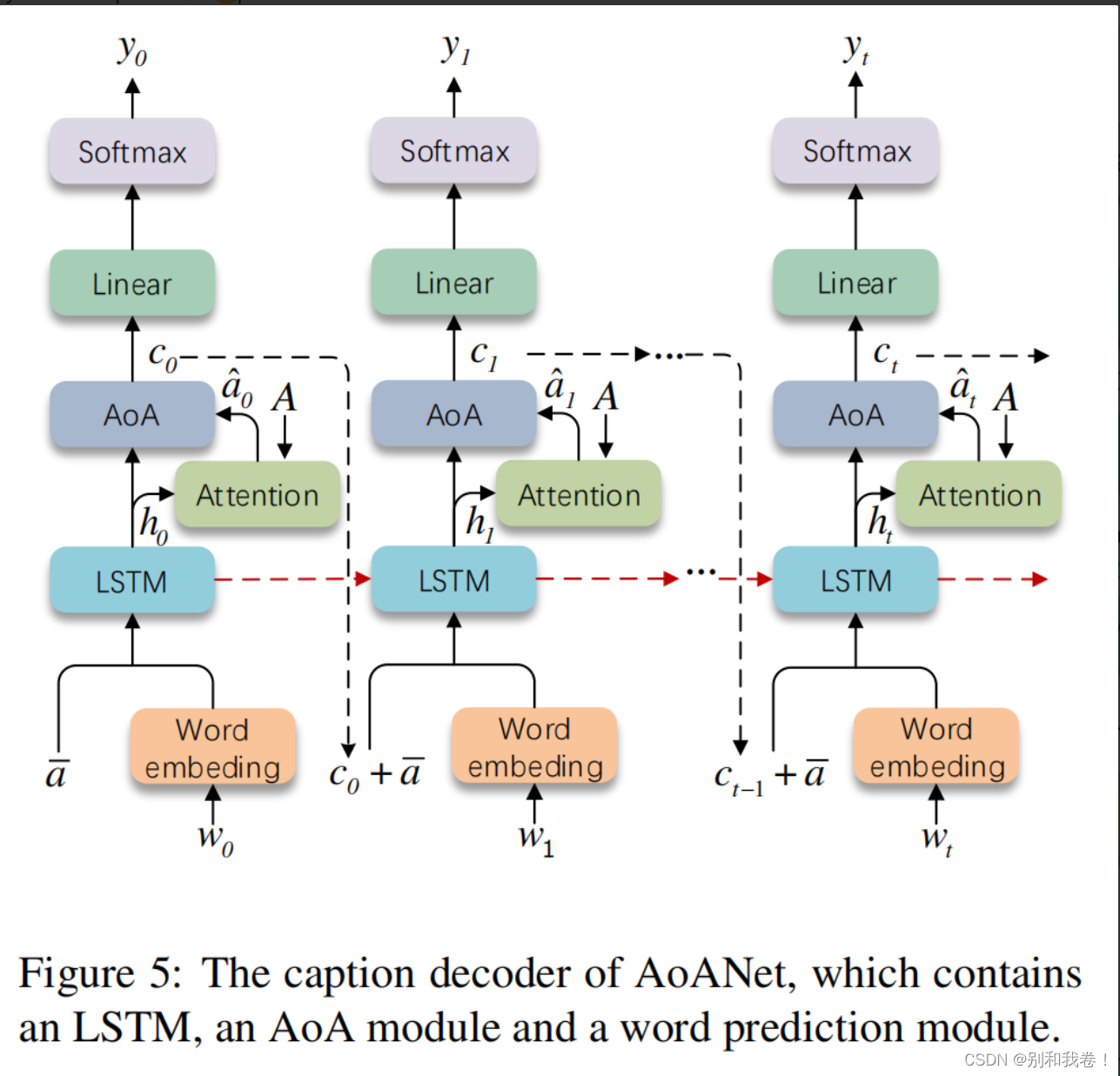
我们对上下文向量 Ct 建模,以计算词汇表上的条件概率:
其中Wp是学习的权重参数,|sigma|是词汇表大小。
上下文向量Ct保存了解码状态和新获取的信息,这些信息是由关注的特征向量 a hat t 和LSTM的输出ht 生成的,其中 a hat t是来自注意模块的关注结果,该模块可以具有一个或多个头。
解码器中的LSTM对描述解码过程进行建模。它的输入包括当前时间步的输入词的嵌入,以及一个视觉向量
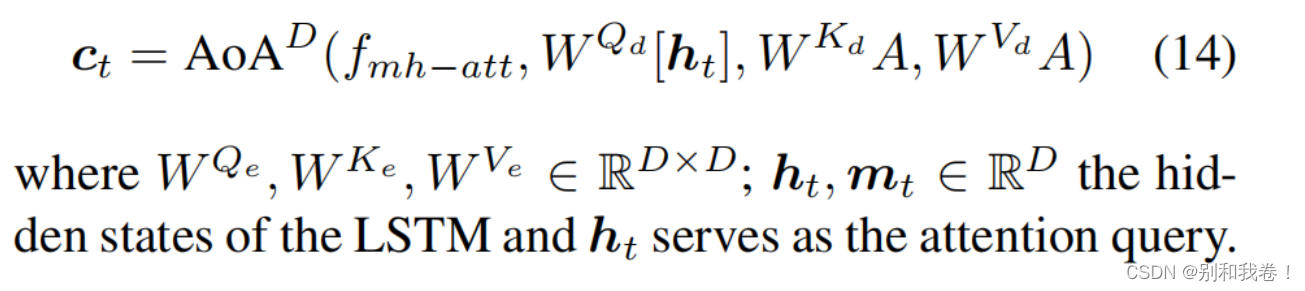




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











