







Sqlalchemy 使用 query.count() 统计数量
问题背景
后台管理系统后台在对接管理端时,管理端某个页面展示中,需要调后台接口获取数据展示并做分页处理,请求时发现请求接口响应平均耗时4~5s。后台数据量并不大,20W 的数据量,联表查询有索引的情况下,理论上不至于耗时这么久。
问题查因
代码示例
trade_db = SessionMixin()
trade_db.factory = trade_factory
start = 0 # 起始参数
count = 100 # 获取数据条数
with trade_db.make_session() as session:
query = session.query(Instruction).join(
Order, Order.instructionId.__eq__(Instruction.instructionId)
).join(
SubAccount, SubAccount.subAccountId.__eq__(Instruction.subAccountId)
).join(
Account, Account.accountId.__eq__(SubAccount.accountId)
)
# 取数据返回
result = query.order_by(desc(Instruction.instructionId)).offset(start).limit(count).all()
# 返回数据总量,给前端做分页展示
start_time = time.time()
total = query.count()
end_time = time.time()
cost = end_time - start_time
logger.debug(f'ins total is {total}, cost {cost}s')
这里代码片段分别做了两次查询,一次是获取前端展示数据,一次是获取数据总量。
当 query.count()调用时,查看日志输出的原始 sql 语句如下:
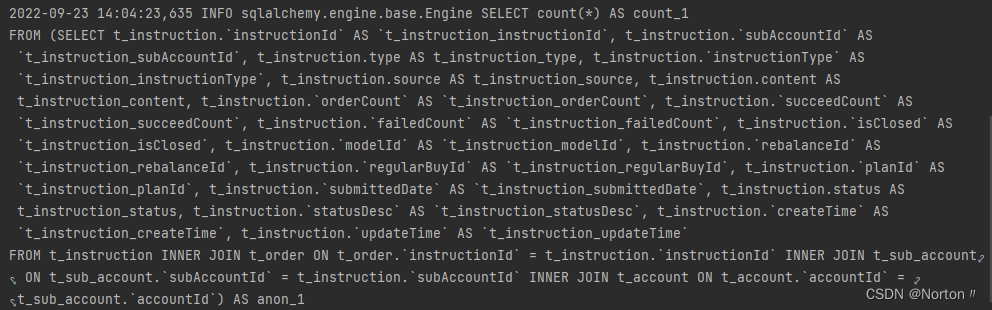
这里使用到了子查询,anon_1 子表为临时表。
查阅官方文档
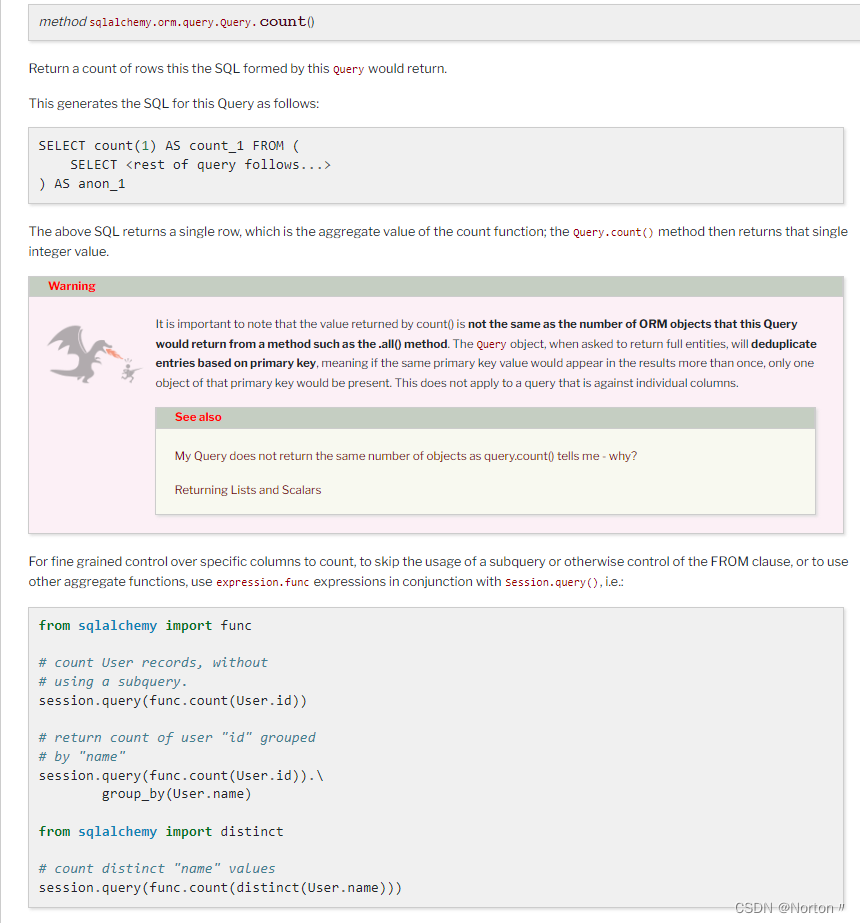
官方文档有特别说明,使用 func.count() 的方式即不使用子表查询。
解决方案
根据官方文档,使用 func.count() 的方式查询数据总数,注意使用 scalar() 获取 int 返回值。
trade_db = SessionMixin()
trade_db.factory = trade_factory
start = 0 # 起始参数
count = 100 # 获取数据条数
with trade_db.make_session() as session:
query = session.query(Instruction).join(
Order, Order.instructionId.__eq__(Instruction.instructionId)
).join(
SubAccount, SubAccount.subAccountId.__eq__(Instruction.subAccountId)
).join(
Account, Account.accountId.__eq__(SubAccount.accountId)
)
# 取数据返回
result = query.order_by(desc(Instruction.instructionId)).offset(start).limit(count).all()
# 返回数据总量,给前端做分页展示
# start_time = time.time()
# total = query.count()
# end_time = time.time()
# cost = end_time - start_time
# logger.debug(f'ins total is {total}, cost {cost}s')
with trade_db.make_session() as session:
start_time = time.time()
total = session.query(func.count(Instruction.instructionId)).join(
Order, Order.instructionId.__eq__(Instruction.instructionId)
).join(
SubAccount, SubAccount.subAccountId.__eq__(Instruction.subAccountId)
).join(
Account, Account.accountId.__eq__(SubAccount.accountId)
).scalar()
end_time = time.time()
cost = end_time - start_time
logger.debug(f'ins total is {total}, cost {cost}s')
问题总结
sqlalchemy 打开调试模式时,可以在日志中查看 orm 执行的原始 sql 语句, query.count() 方法被用于确定返回的结果集中有多少行,sqlalchemy 先是取出符合条件的所有行集合,作为一个子表(临时表),然后再通过 SELECT count(*) 来统计有多少行。这样会遍历整个结果集,当数据量大时,耗时剧增。若单纯统计数量则应该使用 func.count(Instruction.instructionId) 通过统计主键来查询总数,相当于直接 SELECT count(*) ,这样可以避免使用子查询。














 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









