







第二章:线性表
线性表的定义和特点
由n(n>=0)个数据特性相同的 元素构成的有限序列称为线性表。
线性表中元素的个数n(n>=0)定义为线性表的长度,n = 0时称为空表
对于非空的线性表或线性结构,其特点是
- 存在唯一的一个被称作“第一个”的数据元素。
- 存在唯一的一个被称作“最后一个”的数据元素
- 除第一个之外,结构中的每个数据元素均只有一个前驱
- 除最后一个之外,结构中的每一个数据元素均只有一个后继。
线性表的类型定义
线性表的抽象定义:
注:a<sub>i</sub>表示i是a的下标
ADT List{
数据对象:D={a<sub>i</sub>|a<sub>i</sub>∈ElemSet,i = 1, 2, ... , n , n ≥ 0}
数据关系:R = {<a<sub>i-1</sub>,a<sub>i</sub>>, a∈D, i = 2, ..., n}
基本操作:
InitList(&L);
操作结果:构造一个空的线性表L。
DestoryList(&L)
初始条件:线性表L已存在。
操作结果:销毁线性表L。
ClearList(&L)
初始条件:线性表已存在。
操作结果:将L重置为空表。
ListEmpty(L)
初始条件:线性表已存在。
操作结果:若L为空,则返回TRUE,否则返回FALSE;
ListLength(L)
初始条件:线性表已存在。
操作结果:返回L中数据元素的个数。
GetElem(L, i, &e)
初始条件:线性表已存在,且1 ≤ i ≤ ListLength(L)
操作结果:用e返回L中第i个数据元素的值。
LocateElen(L, e)
初始条件:线性表已存在。
操作结果:返回L中第一个值与e相同的元素在L中的文职。若不存在,则返回0
PriorElem(L, cur_e, &pre_e)
初始条件:线性表已存在。
操作结果:若cur_e是L的数据元素,且不是第一个,则用pre_e返回其前驱,否则pre_e无定义
NextElem(L, cur_e, &next_e)
pre_e
操作结果:若cur_e是L的数据元素且不是最后一个,则用next_e返回其后继,否则next_e无定义
ListInsert(&L, i, e)
初始条件:线性表已存在。
操作结果:在L中第i个位置之前插入新的数据元素e,L的长度加1
ListDelete(&L, i)
初始条件:线性表L已存在且非空。
操作结果:删除L的第i个位置之前插入新的数据元素e,L的长度减1
TraverseList(L)
初始条件:线性表已存在。
操作结果:对线性表L进行遍历,在遍历过程中对L的每一个节点访问一次。
}
线性表的顺序存储表示
线性表的顺序表示指的是用一组地址连续的存储单元依次存储线性表的数据元素,这种表示也称作线性表的顺序存储结构或存储影响,称这种存储结构的线性表为顺序表。其特点是:逻辑上相邻的数据元素,其物理次序也是相邻的。
假设线性表的每个元素需占用l个存储单元,则线性表中第i +1个数据元素的存储位置LOC(ai+1)和第i个数据元素的存储位置LOC(ai)之间满足下列关系
L O C ( a i + 1 ) = L O C ( a i ) + l LOC(a_{i+1}) = LOC(a_i) + l LOC(ai+1)=LOC(ai)+l
线性表的第i个元素ai 的存储位置为:
L O C ( a i ) = L O C ( a i ) + ( i − 1 ) × l LOC(a_i) = LOC(a_i) + (i -1) × l LOC(ai)=LOC(ai)+(i−1)×l
只要确定了存储线性表的起始位置,线性表中任意数据元素都可随机存取,所以线性表是一种随机存取的存储结构
#define MAXSIZE 100
typedef struct
{
ElemType *elem; // 存储空间的长度
int length; // 当前长度
}SqList; // 顺序表的结构类型为SqList
(1)数组空间通过初始化动态分配得到,初始化完成后,数组指针elem指示顺序表的基地址,数组空间大小为MAXSIZE。
(2)元素类型定义中的ElemType数据类型时为了描述统一而自定的,在实际应用中,用户可根据实际需要定义表中数据元素的数据类型,既可以时基本数据类型如:int、float、char等,也可以是构造数据类型,如struct结构体类型。
(3)length表示顺序表中当前数据元素的个数。因为C语言数组的下标是从0开始的,而位置序号是从1开始的,所以要注意区分元素的位置需要和该元素在数组中的下标位置之间的对应关系,数据元素a1、a2、… 、an依次存放在数组elem[0]、elem[1]、… 、elem[length - 1]中。
实例
(1) 用顺序表存储稀疏多项式,定义如下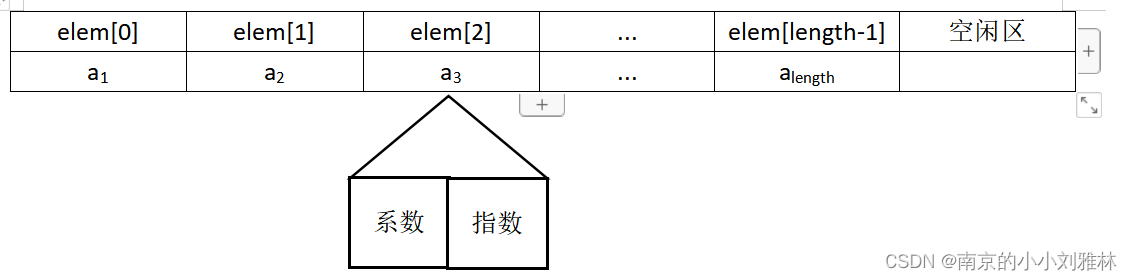
#define MAXSIZE 100 // 多项式可能达到的最大长度
typedef struct // 多项式非零项定义
{
float coef; // 系数
int expn; // 指数
}Polynomial;
typedef struct
{
Ploynomial *elem; // 存储空间的基地址
int length; // 多项式中当前项的个数
}SqList; // 多项式的顺序存储结构为SqList
(2) 用顺序表存储图书数据,定义如下
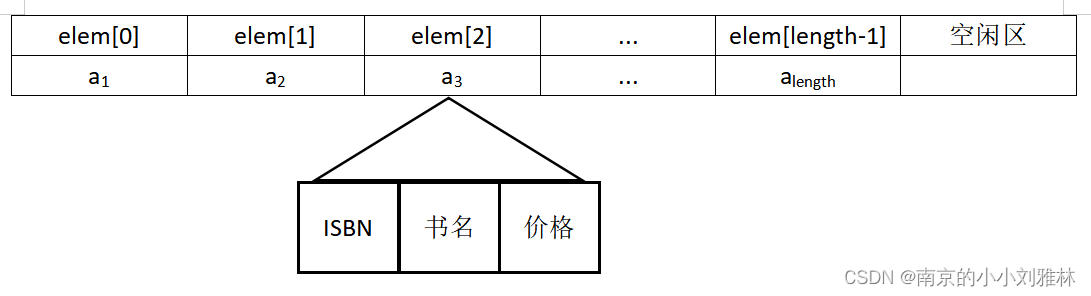
#define MAXSIZE 10000
typedef struct
{
char no[20]; // 图书IBSN
char name[50]; // 图书名字
float price; // 图书价格
}Book;
typedef struct
{
Book *elem; // 存储空间的基地址
int length; // 图书表中当前图书的个数
}SqList; // 图书表的顺序存储结构 类型为SqList
上述定义后,可以通过变量定义语句
SqList L;
将L定义为SqList类型的变量,便可以利用L.elem[i-1]访问变种位置序号为i的图书记录。
顺序表中基本操作的实现
- 初始化
顺序表的初始化操作就是构造一个空的顺序表。- 算法步骤
- 为顺序表
L动态分配一个预定义大小的数组空间,使elem指向这段空间的基地址。 - 将表当前表长度设为
0。
- 为顺序表
- 算法描述
Status InitList(SqList &L) { // 构造一个空的顺序表L L.elem = new ElemType[MAXSIZE]; // 为顺序表分配一个大小为MAXSIZE的数组空间 if(!L.elem) exit(OVERFLOW); // 存储分配失败退出 L.length = 0; // 空表长度为0 return OK; }
- 算法步骤
- 取值
取值操作是根据制定的位置序号i,获取瞬息表中第i个数据元素的值。
由于顺序存储结构具有随机存取的特点,可以直接通过数组下标定位得到,elem[i-1]单元存储第i个元素。- 算法步骤
- 判断制定的位置序号
i是否合理(1≤i≤L.length),若不合理,则返回ERROR - 若
i值合理,则将第i个数据元素L.length赋给参数e,通过e返回第i个数据元素的传值。
- 判断制定的位置序号
- 算法描述
Status GetElem(SqList L, int i, ElemType &e) { if(i < 1 || i > L.length) return ERROR; // 判断i是否合理,若不合理,返回ERROR e = L.elem[i-1]; // elem[i - 1]单元存储第i个数据元素 return OK; } - 算法分析
显然,顺序表取值算法的时间复杂度为O(1)
- 算法步骤
- 查找
查找操作是根据制定的元素值e,查找顺序表中第1个与e想等的元素 。若查找成功,则返该元素在表中位置序号;若查找失败,则返回0- 算法步骤
- 从第一个元素起,依次和
e相比较,若找到与e相等的元素L.elem[i],则查找成功,返回该元素的序号i+1 - 若查遍整个顺序表都没有找到,则查找失败,返回
0
- 从第一个元素起,依次和
- 算法描述
int LocateElem(SqList L, ElemType e) { // 在顺序表L中查找值为e的数据元素,返回其序号 for(i = 0; i < L.length; i++) if(L.elem[i] == e) return i + 1; // 查找成功,返回序号i+1 return 0; // 查找失败,返回0 } - 算法分析
在查找时,为确定元素在顺序表中的位置,需和给定值进行比较的数据元素个数的期望值称为查算法在查找成功时的平均查找长度。
假设pi是查找第i个元素的概率,Ci为找到表中其关键字与给定值相等的第i记录时磨合给定值已进行过比较的关键字的个数,则在长度为n的线性表中,查找成功时平均查找长度为
A S L = ∑ i = 1 n P i C i ASL = \sum_{i=1}^n P_i C_i ASL=i=1∑nPiCi
Ci取决于所差元素在表中位置,一般情况下Ci等于i
假设每一个元素的查找概率相等,即
p i = 1 / n p_i = 1/n pi=1/n
则公式可以化简为
A S L = 1 n ∑ i = 1 n i = n + 1 2 ASL = \frac{1}{n} \sum_{i=1}^n i = \frac{n+1}{2} ASL=n1i=1∑ni=2<
- 算法步骤
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 919
919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









