







线性回归模型预测好坏,评判标准主要观察回归直线与各观测点的接近程度(即直线的拟合优度)。但是如何量化它们之间的接近程度呢?可使用以下常用统计量进行衡量。各统计量分解如下:
- SST总平方和

- SSR回归平方和

- SSE残差平方和

回归平方和是回归值与均值的离差平方和,可以看做由于自变量 的变化引起的
的变化引起的 的变化(即受的影响);
的变化(即受的影响);
残差平方和(或称误差平方和)是真实值与回归值的离差平方和,它是除了对的线性影响之外的其他因素引起的的变化部分,是不能由回归直线来解释的的变差部分(即
受其他因素的影响,如对的非线性影响、测量误差等)。残差平方和描述了真实值与预测值之间的差异程度。
三个平方和的关系为:
总平方和(SST)= 回归平方和(SSR)+ 残差平方和(SSE)
- 判定系数

判定系数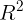 是对估计的回归方程拟合优度的度量。(即测度了回归直线对观测数据的拟合程度)
是对估计的回归方程拟合优度的度量。(即测度了回归直线对观测数据的拟合程度)
- 若所有观测点都落在回归直线上,残差平方和SSE=0,则=1,拟合是完全的;
- 如果的变化与无关,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5078
5078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









