







专栏介绍:本栏目为 “2021秋季中国科学院大学胡玥老师的自然语言处理” 课程记录,不仅仅是课程笔记噢~ 如果感兴趣的话,就和我一起入门NLP吧🥰
1.语言模型基本概念
语言模型的基本思想:
- 句子S=w1,w2,…,wn 的概率 p(S) 刻画句子的合理性
对语句合理性的判断:
- 规则法:判断是否合乎语法、语义(语言学定性分析)
- 统计法: 通过可能性(概率)的大小来判断(数学定量计算)
语言模型结构:

说明:
- wi 可以是字、词、短语或词类等等,称为统计基元。通常以“词”代之。
- wi 的概率由 w1, …, wi-1 决定,由特定的一组w1, …, wi-1 构成的一个序列,称为 wi 的历史(history)。
原始定义存在的问题:
- 第 i ( i >1 ) 个统计基元,基元历史的个数为 i-1,如基元(如词汇表)有 L 个,i 基元就有 L的i-1次方 种不同的历史情况,模型有L的i次方个自由参数。(参数实在是太多了,不切实际)
问题解决方法:
- 马尔科夫方法:假设任意一个词 wi出现的概率只与它前面的w(i-1) 有关,问题得以简化

为什么叫二元模型呢?这里要继续介绍n-gram
- n-gram 模型:假设一个词的出现概率只与它前面的n-1个词相关,距离大于等于n的上文词会被忽略
- 比如:
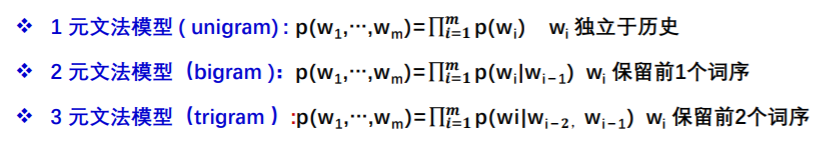
- 理论上N 越大越好,但再高阶模型也无法覆盖所有的语言现象。
- N 越大,需要估计的参数越多。
- tri-gram(3-gram)用的最多。
- four-gram(4-gram)以上需要太多的参数,少用。
那么应该如何获得 n 元语法模型中的各概率值(参数)呢?
2.语言模型参数估计
- 任务:获得语言模型中所有词的条件概率(语言模型参数)
- 训练语料:语言模型对于训练文本的类型、主题和风格等都十分敏感。语料选择尽可能与应用领域一致,要求足够大,并要在训练前进行预处理。
- 参数学习方法:最大似然估计法
例题:
给定训练语料如下:如何 训练 2 元文法
“John read Moby Dick”
“Mary read a different book”
“She read a book by Cher”
第一步:预处理(给训练语料加上开始符合结束符号)
John read Moby Dick
Mary read a different book
She read a book by Cher
第二步:用最大似然估计求参数
其他参数不再赘述


在参数训练好之后就可以预测句子出现的概率了。
- 例题: 求句子 John read a book 的概率 ( 2元文法)
- 答案:p(John read a book)=p(John)×p(read|John)×p(a|read)×p(book|a)×p(|book)
如果需要求Cher read a book出现的概率呢?
因为p(read|Cher)的概率为0,因此连乘之后必然会得到该句子的概率为0,这是因为训练语料中,并不存在(Cher read),这种由于数据缺乏而引起的零概率问题需要通过数据平滑来解决。
3.参数的数据平滑
数据平滑的基本思想:
- 调整最大似然估计的概率值,使零概率增值,使非零概率下调,“劫富济贫”,消除零概率,改进模型的整体正确率。
基本目标:
- 测试样本的语言模型困惑度越小越好。
基本约束:
- n元条件概率之和为1
数据平滑方法:
- 加1法(Additive smoothing ): 每一种情况出现的次数加1
- 减值法/折扣法 (Discounting)
- 删除插值法
加1法例子:

- 分子+1
- 分母+词汇总量
4.语言模型性能评价
主要有两种评价方法:
- 实用方法:
- 通过查看该模型在实际应用(如拼写检查、机器翻译)中的表现来评价,优点是直观、实用,缺点是缺乏针对性、不够客观。
- 理论方法:
- 用模型的 迷惑度/困惑度/混乱度(preplexity)衡量。其基本思想是能给测试集赋予较高概率值(低困惑度)的语言模型较好
困惑度定义:

5.语言模型应用
例一:
- 给定拼音串:ta shi yan jiu sheng wu de
- 列出所有可能的汉字串
例二:
- 已知若干个词,预测下一个词
- 如,联想输入法:基于 n-gram 的智能狂拼、微软拼音输入法等


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











