







一般来说,我们对磁盘的read和write最后都会走到kernel里的submit_bio函数,也就是把io请求变成一个个的bio(bio的介绍看这里),bio是linux内核里文件系统层和block层之间沟通的数据结构(有点像sk_buffer之于网络),(我们通常说的io调度就是在block层上面完成的)
内核把inode读到内存时,磁盘里这个inode表里记录了这个inode的数据位于磁盘的哪些blocks,当然这些block在硬盘中可能不连续存放,例如要读出一个inode的32KB的内容,但这些block的分布在4个不连续的位置(b1…b2…b3b4b5b6…b7b8),那readpages会将每一段连续的blocks转化成一个bio结构,每个bio结构都记录它里面的blocks在磁盘里的位置以及这些blocks要填到page cache的哪些位置。例如这里就是要生成4个bio对象。那么在一次读过程中,即使一个block大小是1KB,但由于它和其他blocks不连续,那也要单独生成一个bio


到了block层以后,一般是先做generic_make_request把bio变成request,怎么个变法?如果几个bio要读写的区域是连续的,就攒成一个request(一个request下挂多个连续bio,就是通常说的“合并bio请求”);如果这个bio跟其它bio都连不上,那它自己就创建一个新的request,把自己挂到这个request下。合并bio请求也是有限度的,如果这些连续bio的访问区域加起来超过了一定的大小(在/sys/block/xxx/queue/max_sectors_kb里设置),那么就不能再合并成一个request了。

合并后的request会放入每个device对应的queue(一个机械硬盘即使有多个分区,也只有一个queue)里,之后,磁盘设备驱动程序通过调用peek_request从queue里取出request,进行下一步的处理。
设备驱动程序要做的事情就是从request_queue里面取出请求,然后操作硬件设备,逐个去执行这些请求。
这里就涉及 队列深度 queue_depth (一次可以传送到磁盘设备的请求(request)的数量)队列深度由硬件决定,一次能并行处理的请求数(只讨论sata),SATAII 的NQC(本地命令队列的英文缩写,简单来说就是把请求按照磁头轨道方向做排序)技术最多可以对32个请求进行排序 ,因此系统下sata盘最大的队列深度是32.(sas 最大256 ,和协议有关)
![]()
另一个内核参数 最大队列数,是再内核层,往内存中写bio的最大数量,越大占用内存越多。能更加多的合并读写操作,速度变慢,但能读写更加多的量,如果队列深度不大,会导致等待时间过长
![]()
IO调度器是内核提供给设备驱动程序的一组方法。用与不用、使用怎样的方法,选择权在于设备驱动程序。看这里驱动
之所以要把多个bio合并成一个request,是因为机械硬盘在顺序读写时吞吐最大。如果我们换成SSD盘,合并这事儿就没那么必要了,这一点是可选的,在实现设备驱动时,厂商可以选择从kernel的queue里取request,也可以选择自己实现queue的make_request_fn方法,直接拿文件系统层传过来的bio来进行处理(
ramdisk、还有很多SSD设备的firmware就是这么做的)。io调度策略来选择是否会合并。

既然bio有bio_vec结构指向多个page,那么为什么不干脆把多个bio合并成一个bio呢?何必要多一个request数据结构那么麻烦?
涛哥答曰:每个bio有自己的end_io回调,一个bio结束,就会做自己对应的收尾工作,如果你合并成一个bio了,就丧失了这种灵活性。
bio 代表一个IO 请求
request 是bio 提交给IO调度器产生的数据,一个request 中放着顺序排列的bio
request_queue代表着一个物理设备,顺序的放着request
block和page
文件系统里的管理单元是block,内存管理是以page为单位,而内核中读写磁盘是通过page cache的,所以就要了解bio是怎么将page和block对应起来的。例如,如果格式化文件系统时指定一个block是4K,那一个block就对应一个page,而如果一个block大小是1K,那一个page就对应4个block,那每次读磁盘就只能每次最小读4个block的大小。
sector(扇区)是硬件读写的最小操作单元,例如如果一个sector是512字节,而格式化文件系统时指定一个block是1K,那文件系统层面只能每次两个sector一起操作。block是文件系统格式化时确定的,sector是由你的硬盘决定的。但是如果你的block越大,那么你的空间浪费可能就会越大(内部碎片,一个文件的末尾占的block的空闲部分)
http://www.ningoo.net/html/2011/all_things_about_flashcache_1.html
buffer_head 顾名思义,在内核层对块设备的IO请求是以块为单位的。buffer_head是一个块在内存中的元数据信息。b_data指向该块数据的实际地址。b_this_page则将通过一page中的块连接起来。以前版本的buffer_head是fs到block device的io请求单元,现在已经改为bio了。
struct buffer_head {
unsigned long b_state;
struct buffer_head *b_this_page;
char *b_data;
sector_t blocknr;
struct block_device *b_bdev;
bh_end_io_t *b_end_io;
...
};
bio
bio封装了一次实际的块设备io请求。这是块设备io请求的基本单位。bi_vcnt表示bio_vec的数目。
struct bio {
sector_t bi_sector;
struct bio *bi_next;
struct block_device *bi_bdev;
unsigned short bi_vcnt;
unsigned short bi_idx;
struct bio_vec *bi_io_vec;
...
};bio_vec表示一次bio涉及到的数据片段(segment),由所在内存页地址,长度,偏移地址等定位。一次bio一般包含多个segment。
request
块设备层IO等待请求(pending I/O request)。内核中的bio请求在经过io调度排序后进入块设备层,会尝试合并到已有的requst。bio结构中的bi_next将队列中的bio请求串成一个队列。bio/biotail域指向队列的首尾。
request_queue
request_queue维护块设备层IO请求队列,队列中包含多个request。request_queue同时定义了处理队列的函数接口,不同的设备注册时需要实现这些IO处理接口。
submit_bio
submit_bio函数会调用generic_make_request执行实际的bio请求。generic_make_request则循环处理bio链表,针对每个bio调用内联函数__generic_make_request来做处理。__generic_make_request则最终调用request_queue中的make_request_fn处理函数处理实际的IO请求。
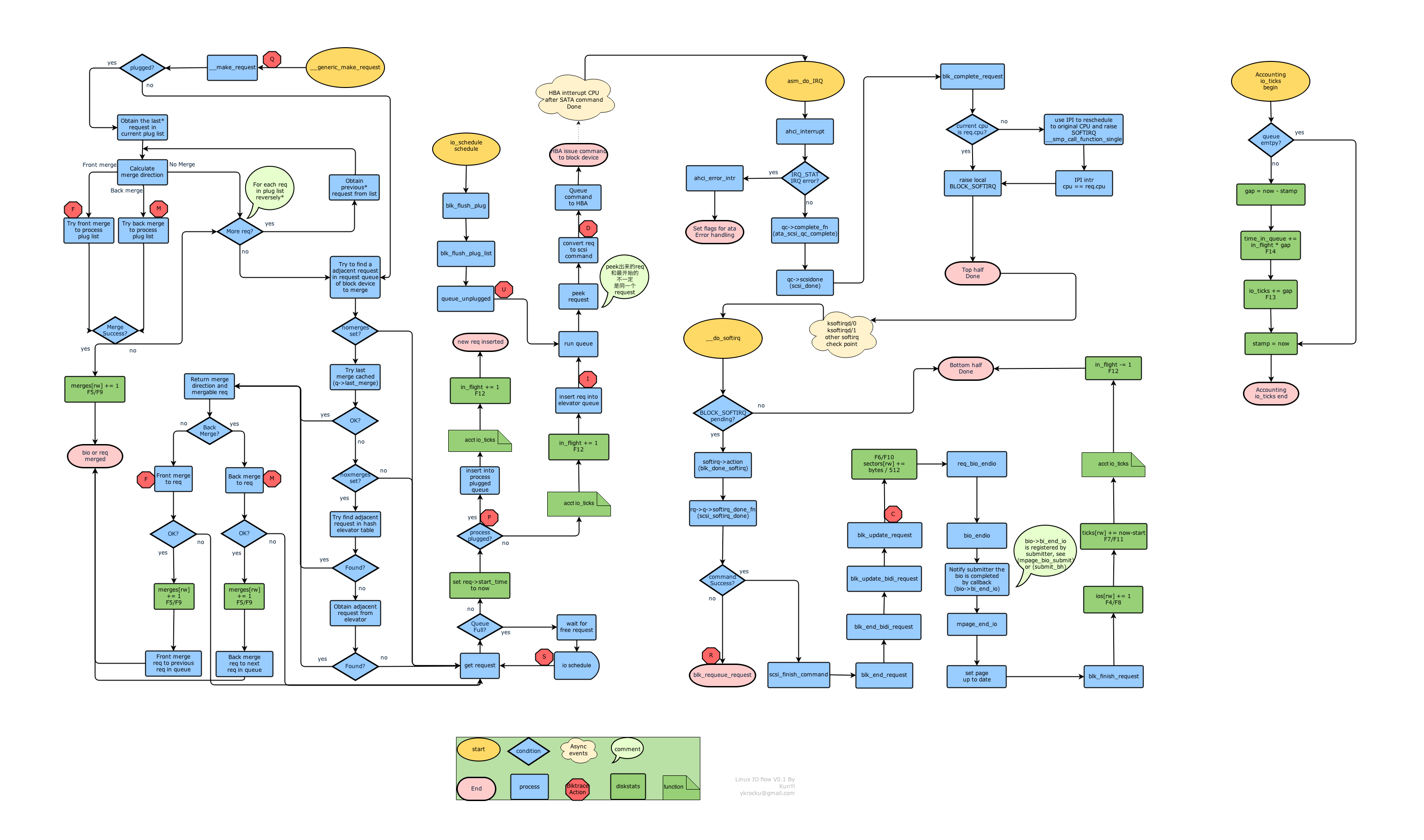
下图是Linux内核通用块设备层IO请求处理的完整流程,
http://ykrocku.github.io/images/LinuxBlockIO.png
一次写io过程
https://blog.csdn.net/zwjyyy1203/article/details/89706610
234步骤简单如下:
内核先找到一个空闲的 inode(例如是131074 )
内核把文件信息记录到其中
该文件需要存储在三个磁盘块,内核找到了三个空闲块block:300、500、800
将内核缓冲区的第一块数据复制到300,下一块复制到500,以此类推
文件内容按顺序 300、500、800存放,内核在 inode 上的磁盘分布区记录了上述块列表
新的文件名abc。linux如何在当前的目录中记录这个文件?内核将入口( 131074,abc)添加到目录文件,文件名和 inode 之间的对应关系将文件名和文件的内容及属性连接起来
















 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}