







官网文档:https://docs.spring.io/spring-data/redis/docs/current/reference/html/
一、前言
当需要执行大批量的写入或者查询时,使用 redis 一条条命令的执行性能肯定没有一次性执行完要好;假设执行完一条 redis 命令的网络耗时为 20ms,有 1 万条命令需要执行,算一下光发送这些命令的网络耗时就达到 200,000ms(200s),这是不能接受的,我们可以使用 RedisTemplate 提供的管道进行批量执行。
根据官网的描述:Redis 提供了对 pipelining 的支持,在向服务器发送多个命令时,无需等待每一条命令响应,然后在一个步骤中读取所有的响应。经过打包命令发送与返回,在一定程度上节省了网络io耗时。
二、Pipelining 介绍与使用
我们使用 Spring 的RedisTemplate 来执行管道操作,RedisTemplate 提供了管道的方法,如下图:
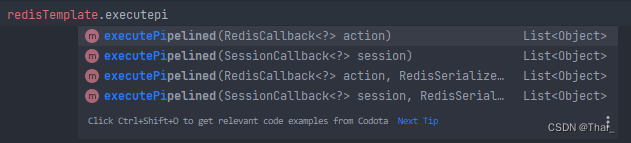
可以看到主要为 SessionCallback 与 RedisCallback,它们的区别主要为 API 的封装,RedisCallback 为原生的 api,SessionCallback 为 Spring 封装的 api。
下图为 SessionCallback 的方法:
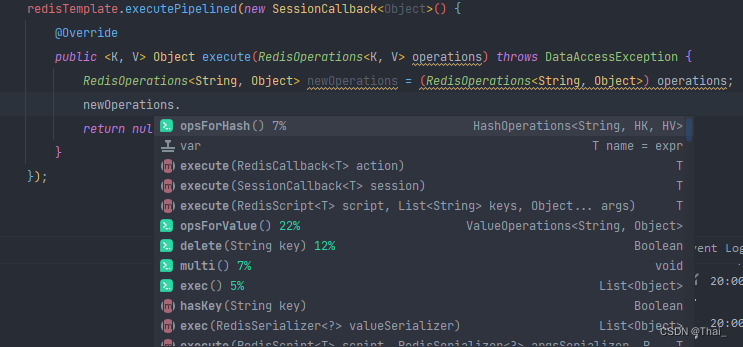
追踪源码可以知道入参 RedisOperations<K, V> operations 其实就是 RedisTemplate 本身,因此所有操作都是经过封装的 api
private Object executeSession(SessionCallback<?> session) {
return session.execute(this);
}
下图为 RedisConnection 的方法:
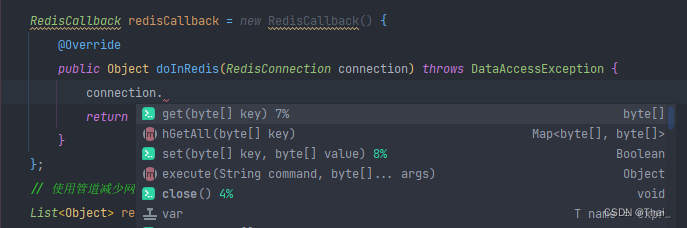
同样的,我们追踪源码可以知道入参为 RedisConnection
public <T> T execute(RedisCallback<T> action, boolean exposeConnection, boolean pipeline) {
// 略...
RedisConnectionFactory factory = getRequiredConnectionFactory();
RedisConnection conn = RedisConnectionUtils.getConnection(factory, enableTransactionSupport);
try {
boolean existingConnection = TransactionSynchronizationManager.hasResource(factory);
RedisConnection connToUse = preProcessConnection(conn, existingConnection);
boolean pipelineStatus = connToUse.isPipelined();
if (pipeline && !pipelineStatus) {
connToUse.openPipeline();
}
RedisConnection connToExpose = (exposeConnection ? connToUse : createRedisConnectionProxy(connToUse));
// 入参为 connection
T result = action.doInRe 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









