







这里写目录标题
1. 前言
好久没有用Java进行数据抓取操作了,之前还是在2018年那个夏天,不过这次又遇到相同的需求了,所以就把整个过程记录下来,以后遇到了同样的情况就比较好操作。内容绝对干货,包括如何解析,如何爬取,如何解决遇到的问题。
获取网页HTML信息
我这里就是简单的http请求,所以就用Java库自带的HttpURLConnection类进行请求操作。具体操作如下
public static String getWebPageInfoByWebUrl(String webURL) throws Exception{
URL url = new URL(webURL);
System.out.println("webURL = " + webURL);
HttpURLConnection httpURLConnection = (HttpURLConnection) url.openConnection() ;
httpURLConnection.setRequestMethod("GET");
BufferedReader reader = new BufferedReader(new InputStreamReader(httpURLConnection.getInputStream()));
String line;
StringBuilder response = new StringBuilder();
while (true){
line = reader.readLine();
if (line == null || line.equals("null")){
break;
} else {
response.append(line);
}
}
reader.close();
return String.valueOf(response);
}
上面这个方法根据传入的url,返回获得的html页面信息。这里比较简单,没传什么header,proxy之类的,就简简单单抓个数据,如果有需要可自行添加。
使用Xpath解析HTML
回忆了很多解析方式,像什么xpath,javascript,regex,好像之前就xpath解析用的是比较多一点的。
然后接下来就是xpath解析,为了方便获取xpath表达式,直接从chrome商店下载一个 XPath Helper 插件。
XPath 咋使用呀
1-> 打开一个新选项卡并导航到任何网页。
2-> 按Ctrl-Shift-X(或在OS X上按Command-Shift-X),或单击工具栏中的XPath Helper按钮,打开XPath Helper控制台。
3-> 当鼠标移到页面上的元素上时,按住Shift键。查询框将不断更新,以显示针对鼠标指针下方元素的XPath查询,结果框将显示当前查询的结果。
4.-> 如果需要,可以直接在控制台中编辑XPath查询。结果框将立即反映您的更改。
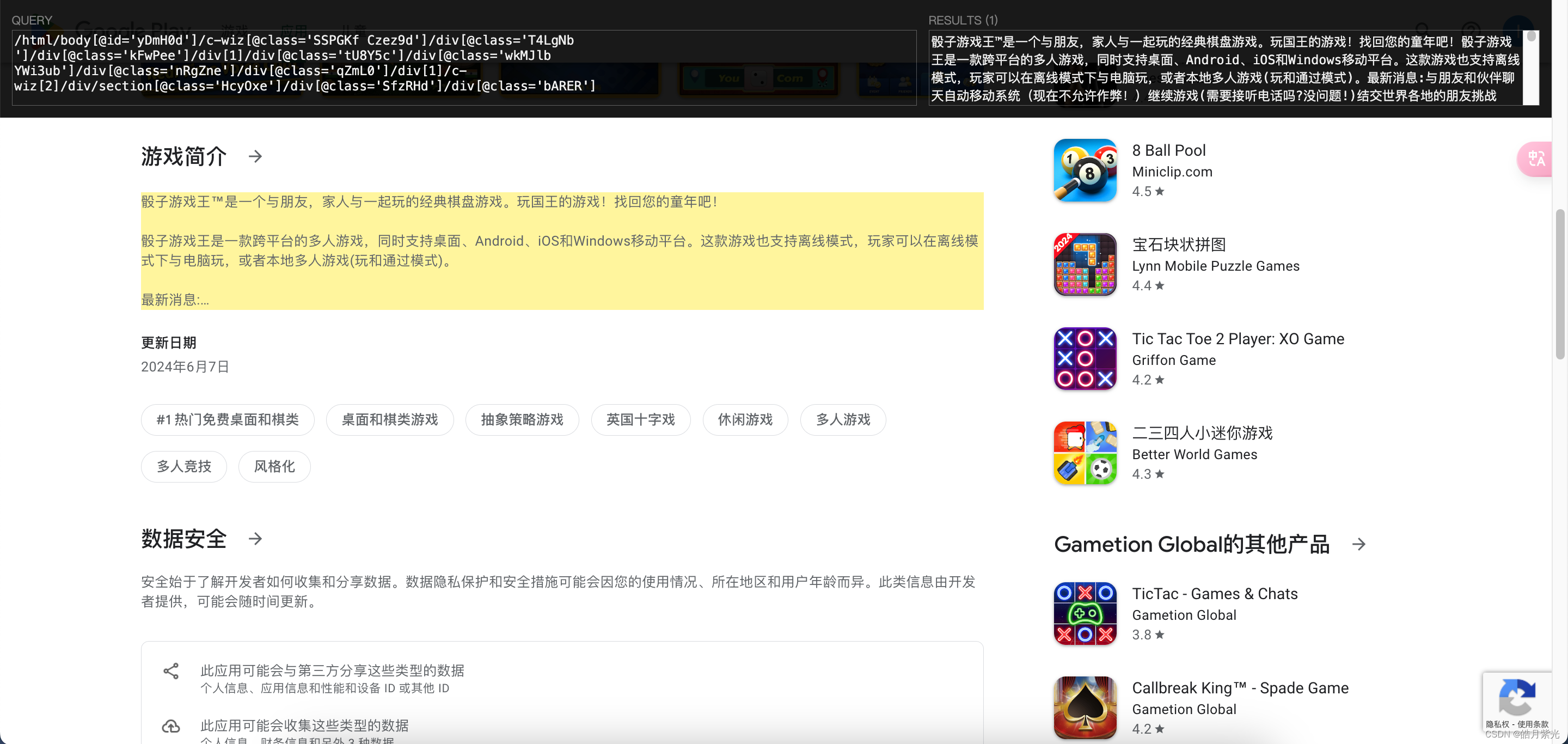
2. 开始实战
1. 获取googlePlay的各个游戏的链接
链接这个东西用Xpath直接选页面大概率是选不到的,我们直接先选中一个游戏,然后打开浏览器的控制台,看页面源码,一眼就可以看到我们需要的游戏链接地址,然后我们需要获得所有的游戏地址,就通过XPath Helper工具慢慢调试到我们想要的结果,最后可以看到当表达式为: //a[@class=‘Si6A0c Gy4nib’]/@href , 我们可以可以拿到我们的链接列表。
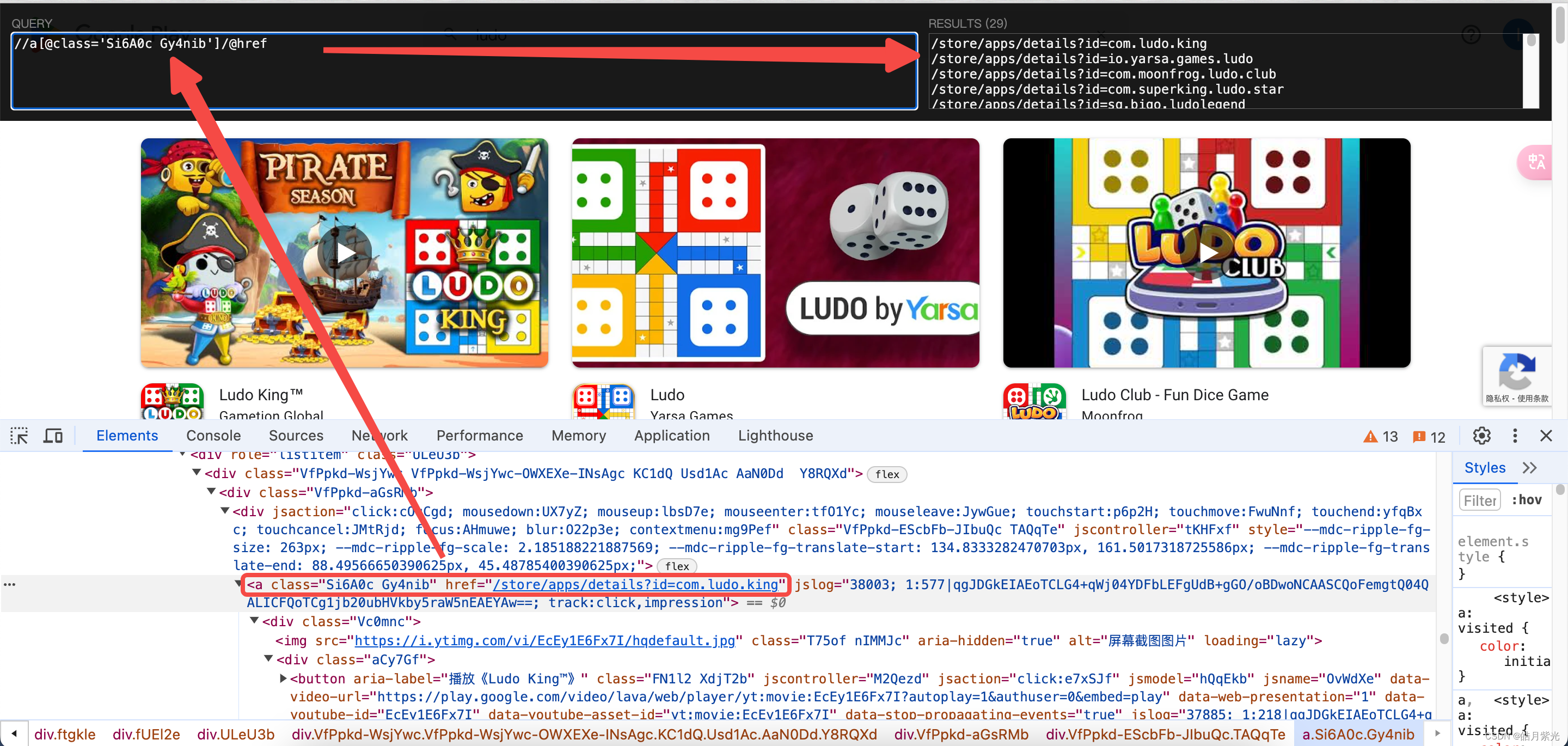
Java代码
import org.apache.commons.text.StringEscapeUtils;
import org.htmlcleaner.HtmlCleaner;
import org.htmlcleaner.TagNode;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class HttpRequestUtil2 {
public static void main(String[] args) throws Exception {
// 获取googlePlay搜索结果游戏链接地址
List<String> gameUrlList = getGameUrlList();
}
/**
* 获取游戏网址列表
* @return {@link List }<{@link String }>
*/
private static List<String> getGameUrlList() throws Exception {
// 获取googlePlay搜索结果网页信息
String searchURL = "https://play.google.com/store/search?q=ludo&c=apps&hl=zh";
String content = getWebPageInfoByWebUrl(searchURL);
// 做一下网页处理 这样可以确保是 html页面
content = content.replaceAll("<script [\\s|\\S]*? </scritp>", "");
if (!content.startsWith("<?xml version=\"1.0\" encoding=\"UTF-8\"?>")) {
content = "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n" + content;
}
TagNode clean = new HtmlCleaner().clean(content);
String expression = "//a[@class='Si6A0c Gy4nib']/@href";
Object[] objects = clean.evaluateXPath(expression);
List<String> gameUrlList = new ArrayList<>(objects.length);
for (Object objectTag : objects){
String tagNodeHtmlString = getTagNodeHtmlString(objectTag);
gameUrlList.add(tagNodeHtmlString);
System.out.println(tagNodeHtmlString);
}
return gameUrlList;
}
/**
* 通过 Web URL 获取网页信息
* @param URL 网址
* @return {@link String }
*/
private static String getWebPageInfoByWebUrl(String URL) throws Exception{
HttpURLConnection httpURLConnection = (HttpURLConnection) new URL(URL).openConnection();
httpURLConnection.setRequestMethod("GET");
BufferedReader reader = new BufferedReader(new InputStreamReader(httpURLConnection.getInputStream()));
String line;
StringBuilder response = new StringBuilder() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









