










1.Kafka原理
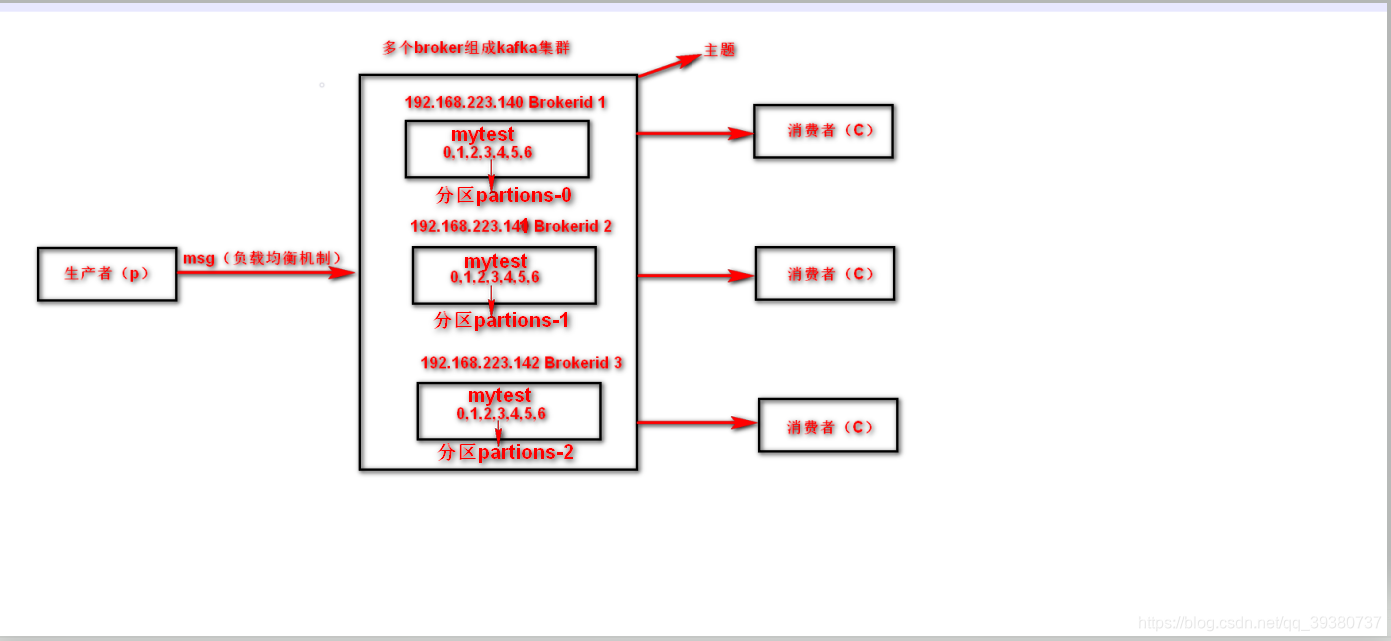
1. brokers有多个broker组成,broker是指Kafka服务器(192.168.223.140就是其中的一个broker),上面三台Kafka服务器组成了Kafka集群
2. broker.id代表集群中broker的唯一性,不能重复
3. partions主题分区数。kafka通过分区策略,将不同的分区分配在一个集群中的broker上,一般会分散在不同的broker上,当只有一个broker时,所有的分区就只分配到该Broker上。消息会通过负载均衡发布到不同的分区上,消费者会监测偏移量来获取哪个分区有新数据,从而从该分区上拉取消息数据。分区数越多,在一定程度上会提升消息处理的吞吐量,因为kafka是基于文件进行读写,因此也需要打开更多的文件句柄,也会增加一定的性能开销。如果分区过多,那么日志分段也会很多,写的时候由于是批量写,其实就会变成随机写了,随机 I/O 这个时候对性能影响很大。所以一般来说 Kafka 不能有太多的 Partition。
4.topics主题。topics可以看作是整个集群的容器,topic看作是里面其中一个小容器,然后这些topic容器组成了topics容器。所有操作都在一个单独的topic里面操作,可以看成像docker一样
5.创建主题
bin/kafka-topics.sh --create --zookeeper 192.168.223.142:2181 --replication-factor 1 --partitions 3 --topic mytest
5.1replication-factor:用来设置主题的副本数。每个主题可以有多个副本,副本位于集群中不同的broker上,也就是说副本的数量不能超过broker的数量,否则创建主题时会失败。
replication-factor 设置为2时,代表主题的副本数为2,如下图所示,0,1,2里面有192.168.223.140,192.168.223.141,192.168.223.142单个总的数量都为2,比如2挂掉,0,1,里面也保存了整个集群信息,通过去重,得到了整个集群信息(192.168.223.140,192.168.223.141,192.168.223.142 )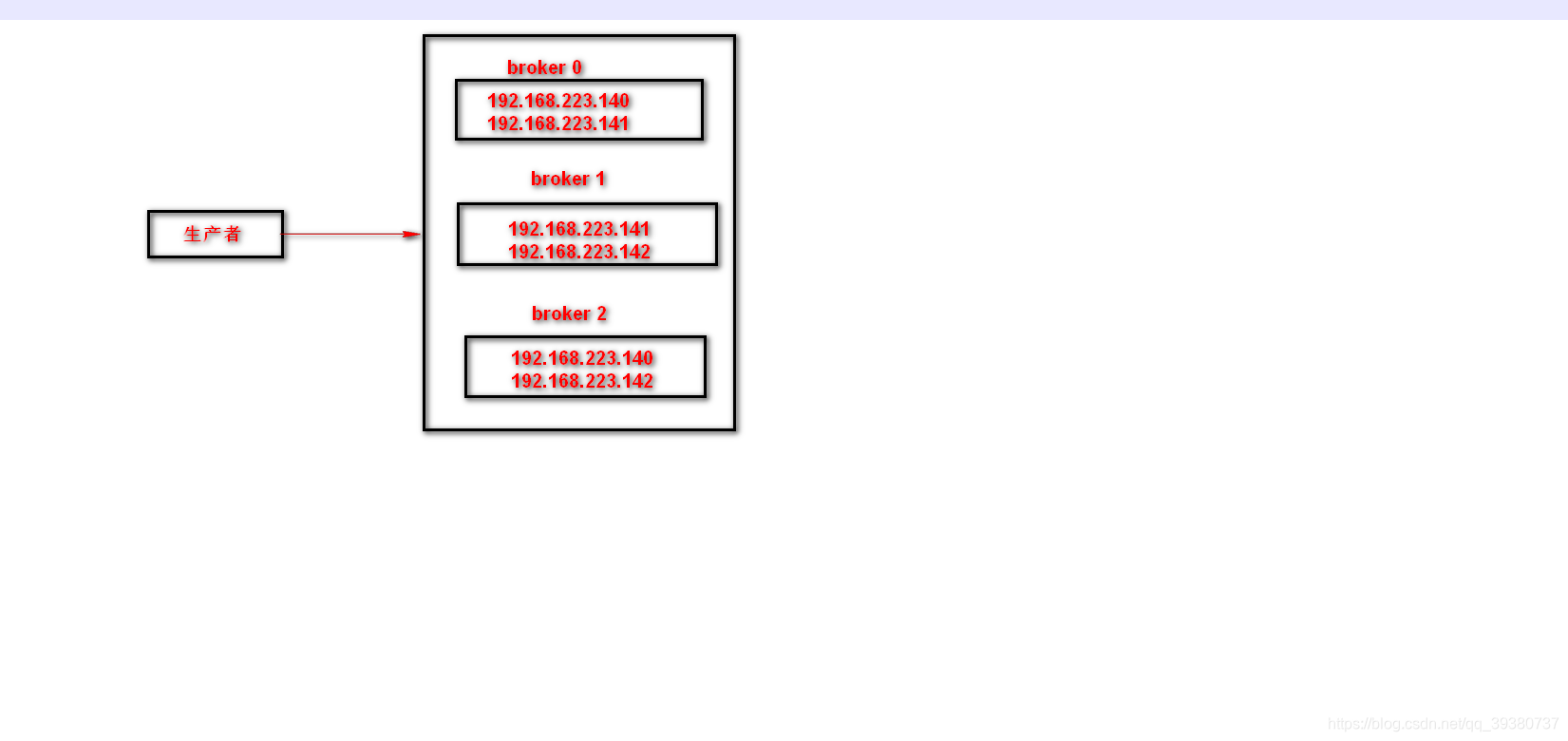
5.2partitions主题分区数为3,默认是采用轮训算法,也就是mytest主题,均匀分区在(192.168.223.140,192.168.223.141,192.168.223.142 )上面,SpringBoot整合Kafka的时候会验证这一点
6.Zookeeper角度理解Kafka原理
任意连接其中一个zookeeper节点,主题mytest三个分区,test一个分区

上图看到,topics下面管理着所有主题,包括mytest、test、test1等等,mytest被均匀分区成了(0,1,2),对应分区下面存储相关信息,test只有1个分区0。
2.SpringBoot整合Kafka
2.1 导入依赖
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2.2 相关配置
# kafka
spring:
kafka:
# kafka服务器地址(可以多个)
bootstrap-servers: 192.168.223.140:9092,192.168.223.141:9092,192.168.223.142:9092
consumer:
# 指定一个默认的组名
group-id: kafka2
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
# 服务器地址
bootstrap-servers: 192.168.223.140:9092,192.168.223.141:9092,192.168.223.142:9092
2.3 代码实现
@RestController
@SpringBootApplication
public class KafkaController {
/**
* 注入kafkaTemplate
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息的方法
*
* @param key
* 推送数据的key
* @param data
* 推送数据的data
*/
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("mytest", key, data);
}
// test 主题 1 my_test 3
@RequestMapping("/kafka")
public String testKafka() {
int iMax = 10;
for (int i = 1; i < iMax; i++) {
send("key" + i, "value" + i);
}
return "success";
}
public static void main(String[] args) {
SpringApplication.run(KafkaController.class, args);
}
/**
* 消费者使用日志打印消息
*/
@KafkaListener(topics = "mytest")
public void receive(ConsumerRecord<?, ?> consumer) {
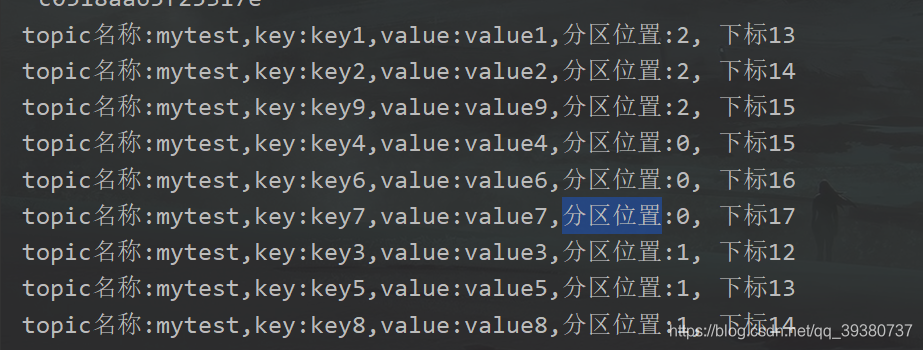
System.out.println("topic名称:" + consumer.topic() + ",key:" + consumer.key() + ",value:" + consumer.value() +",分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset());
}
}
2.4 验证输出














 1285
1285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









